DeepSeek 遭美国攻击宕机,手把手教你本地部署,手机也支持!
▎本地部署模型的优势
数据安全与隐私
敏感数据无需上传至第三方云端,避免泄露风险,符合金融、医疗等行业的严格合规要求。
自主控制与定制化
可根据业务需求灵活调整模型参数、优化算法,或集成私有数据微调模型,适配特定场景。
低延迟与高性能
本地部署减少网络传输延迟,结合硬件优化(如 GPU 加速),提升实时处理效率。
成本可控性
长期运营中,大规模调用场景下本地资源成本可能低于云端按需付费模式,尤其适合高频使用企业。
离线可用性
不依赖外部网络,保障业务连续性,适合网络环境受限或对稳定性要求高的场景。
合规与审计
满足数据主权法规(如 GDPR),完整保留数据操作日志,便于内部审计与监管审查。
▎手把手部署指南(附避坑指南)
Python 环境部署
安装最新版推理加速库(关键!)
pip install deepseek-r1-toolkit --extra-index-url https://repo.deepseek.com/pypi/
from deepseek_r1 import ChatEngine
# 自动检测硬件配置(显存<24GB会自动切换CPU优化模式)
engine = ChatEngine(model_size="32B")
# 开启思维链可视化
response = engine.chat(
"某数加5等于12,这个数的平方是多少?",
show_reasoning=True
)
print(response.answer) # 输出:49
print(response.reasoning) # 查看完整推导过程
Ollama 本地部署
-
安装Ollama 官方版:【 点击前往 】
-
安装 Chrome 浏览器插件 Web UI 控制端【 点击安装 】
安装命令
1.5B Qwen DeepSeek R1
ollama run deepseek-r1:1.5b
7B Qwen DeepSeek R1
ollama run deepseek-r1:7b
8B Llama DeepSeek R1
ollama run deepseek-r1:8b
14B Qwen DeepSeek R1
ollama run deepseek-r1:14b
32B Qwen DeepSeek R1
ollama run deepseek-r1:32b
70B Llama DeepSeek R1
ollama run deepseek-r1:70b
2. 更多模型下载
DeepSeek-R1
| 模型 | 总参数 | 已激活参数 | 上下文长度 | 下载 |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128 千 | HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128 千 | HuggingFace |
DeepSeek-R1-Zero 和 DeepSeek-R1 基于 DeepSeek-V3-Base 进行训练。有关模型架构的更多详细信息,请参阅 DeepSeek-V3 存储库。
DeepSeek-R1-Distill 模型
| 模型 | 基础模型 | 下载 |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | HuggingFace |
DeepSeek-R1-Distill 模型基于开源模型进行了微调,使用了 DeepSeek-R1 生成的样本。我们对其配置和分词器进行了轻微更改。请使用我们的设置来运行这些模型。
手机本地部署
iPhone
App Store 搜索 fullmoon 可以本地直接部署大模型



Android
下载安装 MNN 应用内搜索 DeepSeek 即可看到 7 B 和 1.5 B 模型
夸克网盘下载
百度网盘下载
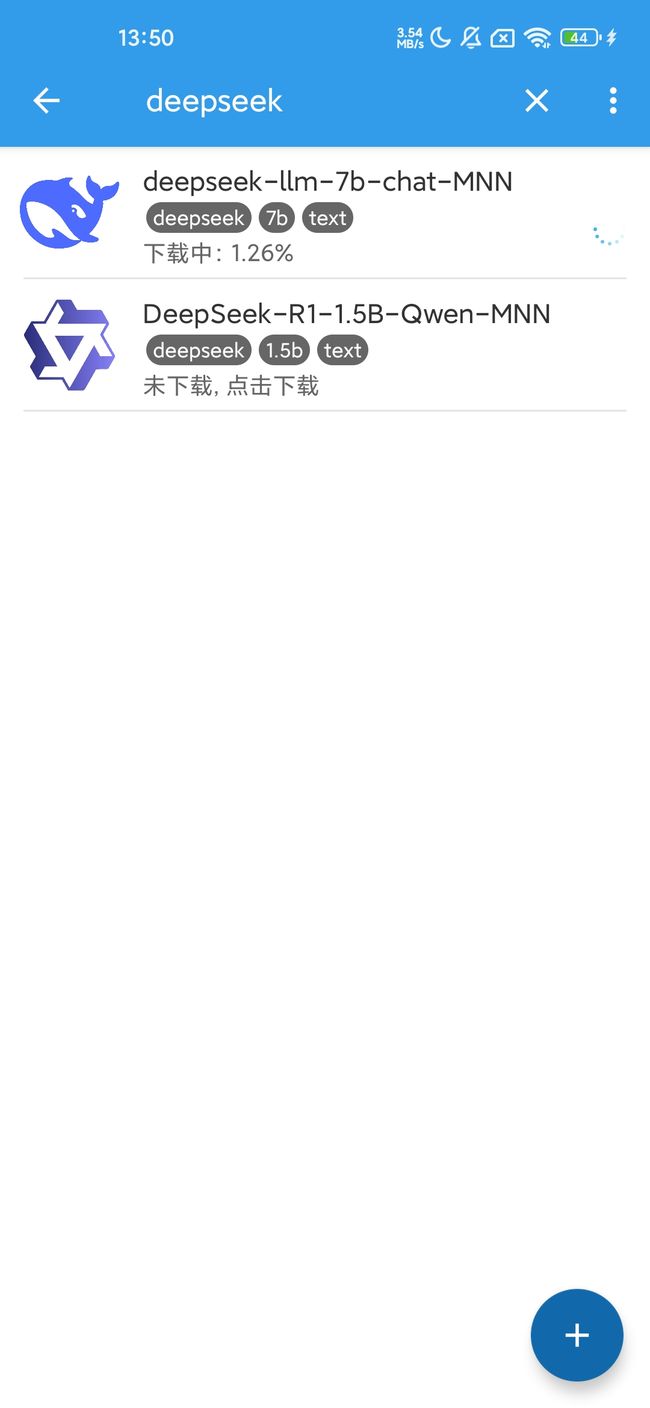

手机实测可以运行 DeepSeek-R1 7B、1.5B 模型,Prefill: 7.18 tokens/s Decode: 3.62 tokens/s
高级部署方案
| 场景 | 推荐方案 | 硬件要求 | 性能指标 |
|---|---|---|---|
| 学术研究 | HuggingFace 原版 | 2*A100(80G) | 原生 PyTorch 支持 |
| 生产环境 | vLLM 加速版 | 4*RTX4090 | 1500 tokens / 秒 |
| 国产硬件 | 昇腾适配版 | Atlas 800 | 华为 CANN 加速 |
| 移动端 | TensorRT 优化 | Jetson AGX | 8GB 内存即可运行 |
避坑提示:
-
首次加载 70B 模型需预留 150GB 存储空间(建议使用阿里云 OSS 加速)
-
使用 --load-8bit 参数可降低 50% 显存占用(精度损失 < 2%)
-
遇到 CUDA 内存不足时,开启分块推理模式:
engine.set_config(chunk_size=512, overlap_rate=0.2)
更多更详细的科技咨询,可以关注我的公众号【GeekClub 极客】,解锁「AI + 效率」终极指南
每天 1 分钟,获取:
⭐ 硬核科技拆解(小白也能懂的顶尖论文解读)
⭐ 效率工具链测评(自动生成 PPT / 智能周报 / 文献速读)
⭐ 科技趋势雷达(Web4.0 / 量子计算 / 神经拟态芯片前沿追踪)
⭐ 程序员专属福利(GitHub 趋势库 / LeetCode 智能题解)
点击【关注】让科技真正赋能你的每一分钟!