Python链家网二手房房源数据采集爬虫
1 写在前面:
HELLO 今天给同学们分享一款项目《链家网二手房数据爬虫》,这个项目主要是基于Python语言的lxml 库的xpath路径解析解析获取的,并结合了多线程并发爬取,速度和异常都做了很好处理。
数据爬取的字段详细有:'标题', '关注', '小区', '位置', '城市', '房屋类型', '面积', '单价', '总价', '介绍', '详情网址', '图片',数据爬取后我写了两种的储存方式,一个是Csv数据集保存和一个数据库MySQL保存,并且我已经给代码都做了注释说明,同学们很好容易理解。
项目所涉及的模块技术主要是:request,pandas,lxml,threading,csv。
PS:这个代码我是以西安这座城市为例的,同学们只需要修改代码的关键字修改指定你们需要爬取的城市名称即可!
2 目标网站分析
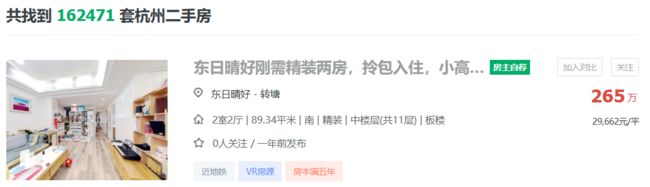
本次我们爬取的是链家网的二手房房源数据,我们先来登录该网站确实我们需要采集收集的数据,可以发现确定可以采集的字段有'标题', '关注', '小区', '位置', '城市', '房屋类型', '面积', '单价', '总价', '介绍', '详情网址', 以及'封面图片',
接着我们打开F12或者鼠标右键点击检查

发现在 ul标签下的li便是对应我们的每一个房源的对象,我们继续打卡li标签,开始定位每一个具体元素的文本或者a链接,例如我们写在获取房源的标题,

可以发现该标题是存在a标签下的文本里面,这边容易获取啦,只需要定位到a标签位置在使用text()方法即可获取,完整来说就是先获取ui标签的每一个li内容:
li_List = tree.xpath("//*[@class='sellListContent']/li")
然后便可以在该相对位置获取标题文本内容:
title = li.xpath('./div/div/a/text()')[0],其他文本的获取也是同理,接下来我再简单讲解说明一下如何获取图片的url链接,

使用定位定位到该图片的html位置,发现其在属性为lj-lazy的img标签下,详细形式为属性为data-original的值,我们便可以使用代码 li.xpath('./a/img/@data-original')[0] 层层递进获取a标签下的img标签的data-original的值即可。
其余的字段我就不做过多赘述啦,获取的内容基本是一样的流程和方法,有一点需要说明的是,链家网的二手房的采集在超过5个页面(150)条数据便会遇到阻止,解决该问题的手段有很多可以使用selenium库自动化测试,也可以使用最直接的Cookie来解决,如下:
如何获取找到自己浏览器的Cookie,这个也很简单,我也说明一下吧,在网络(network)选择XHR
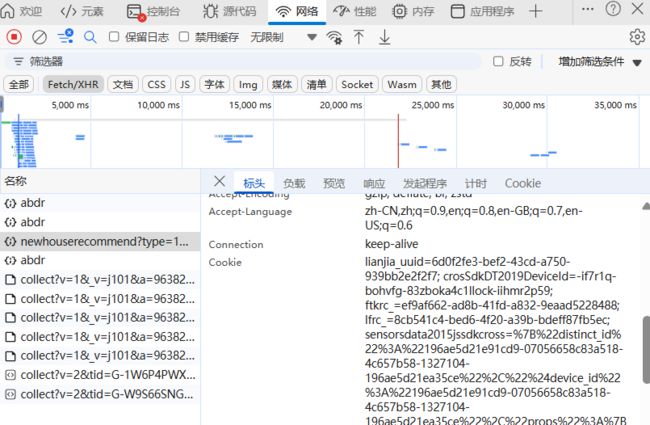
到此 这个项目的简单流程便结束了,至于储存到Csv和MySQL数据库,这个我就不多说了,接下来我把完整代码直接粘贴下面,需要的同学可以拿走。
3 完整代码:
import requests
import threading
import pandas as pd
from lxml import etree
import csv
from datetime import datetime
import pymysql
cnx = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="secondhouse_xian"
)
cursor = cnx.cursor()
# 全部信息列表
count = []
city = '西安'
# CSV文件名(带时间戳)
filename = f'{city}.csv'
# 生成1-10页url
def url_creat():
url = 'https://xa.lianjia.com/ershoufang/pg{}/'
return [url.format(i) for i in range(1, 51)]
# CSV存储函数
def save_to_csv(data):
# 定义CSV表头
headers = ['标题', '关注', '小区', '位置', '城市', '房屋类型', '面积', '单价', '总价', '介绍', '详情网址', '图片']
# 首次写入时创建文件并写入表头
with open(filename, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=headers)
if f.tell() == 0:
writer.writeheader()
writer.writerow(data)
# 页面解析
def url_parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0',
'Cookie':'lianjia_uuid=6d0f2fe3-bef2-43cd-a750-939bb2e2f2f7; select_city=330100; lianjia_ssid=1807dc6c-353e-4e7c-a4a6-caaae625f69d; '
'crosSdkDT2019DeviceId=-if7r1q-bohvfg-83zboka4c1llock-iihmr2p59; login_ucid=2000000456398621; '
'lianjia_token=2.00142d0bba43fa714b0580228b73f70576; lianjia_token_secure=2.00142d0bba43fa714b0580228b73f70576; '
'security_ticket=UgAs85ty1j+KdeDNa49PrErJN6hc68OmqtitvxeskqSNS6hdJJ2PBLT0Bh62YyMhnstpwUB/x7a3/9fvfcAjhPMF8c1id9nGUCwZ1GgRxjwWsijqvaEobK0A2AHw6QdsLDuHKa9YmDuzfWDIjmgE7QDLVHyv81Ff4eM9apx1eV4=; '
'ftkrc_=ef9af662-ad8b-41fd-a832-9eaad5228488; lfrc_=8cb541c4-bed6-4f20-a39b-bdeff87fb5ec; '
'Hm_lvt_46bf127ac9b856df503ec2dbf942b67e=1746682060; HMACCOUNT=36F711E17DDBF3F9;'
' _qzjc=1; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZDY2ODNiZTlmMjJlMDUxMDA2ZDU4NTg2NjJlOTA2NjY5MzU3Zjc5ODRlYjFiNWJiOWI2NDFmYjMyOTBkYTc2ZmY0MzdlNzNmNzNkZDlmYWU1Mjk1ZThkN2UzZmNkMGQ1MTkyYmIyNTI4YzY1NjNmYzNjMGJkOTA2ZWNkYzBmZGJlOGYxM2NkODA5MWQ1YjZlZWJlZjQ2ZWMzMjgwZmMxNDUwMjIyNDA4NjA4YjU2MzliYmYyMDkwNGI4NmIyODMzNTg0ZWYwYzAyYzVlZjQzMzQ5YTQ4NjM0N2Y0YmIxM2VmNTVlOGUzNDU0NWQ2NTc3NDY5MmUzMTMxODAwNDcyOFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJjMzU0MWE0OVwifSIsInIiOiJodHRwczovL2h6LmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvcGcxLyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9; _jzqa=1.3628376045562550000.1746682061.1746682061.1746682061.1; '
'_jzqc=1; _jzqx=1.1746682061.1746682061.1.jzqsr=clogin%2Elianjia%2Ecom|jzqct=/.-; _jzqckmp=1; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22196ae5d21e91cd9-07056658c83a518-4c657b58-1327104-196ae5d21ea35ce%22%2C%22%24device_id%22%3A%22196ae5d21e91cd9-07056658c83a518-4c657b58-1327104-196ae5d21ea35ce%22%2C%22props%22%3A%7B%7D%7D; _ga=GA1.2.1014061828.1746682072; '
'_gid=GA1.2.288150949.1746682072; _gat=1; _gat_past=1; _gat_global=1; _gat_new_global=1; _gat_dianpu_agent=1; '
'_ga_W9S66SNGYB=GS2.2.s1746682072$o1$g0$t1746682072$j0$l0$h0; _ga_1W6P4PWXJV=GS2.2.s1746682072$o1$g0$t1746682072$j0$l0$h0; '
'_qzja=1.1120861123.1746682060329.1746682060329.1746682060329.1746682060329.1746682085924.0.0.0.2.1; _qzjb=1.1746682060329.2.0.0.0; '
'_qzjto=2.1.0; _jzqb=1.2.10.1746682061.1; Hm_lpvt_46bf127ac9b856df503ec2dbf942b67e=1746682086'
}
try:
response = requests.get(url=url, headers=headers, timeout=10)
response.encoding = 'utf-8'
tree = etree.HTML(response.text)
li_List = tree.xpath("//*[@class='sellListContent']/li")
lock = threading.RLock()
with lock:
for li in li_List:
# 数据提取部分保持不变
title = li.xpath('./div/div/a/text()')[0]
link = li.xpath('./div/div/a/@href')[0]
attention = li.xpath('./div/div/text()')[0].split('人')[0]
# 位置
postion = li.xpath('./div/div[2]/div/a/text()')[0] + li.xpath('./div/div[2]/div/a[2]/text()')[0]
# 类型
types = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[0]
# 面积
area = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[1]
# 房屋信息
info = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[2:-1]
info = ''.join(info)
# 总价
count_price = li.xpath('.//div/div[6]/div/span/text()')[0]
# 单价
angle_price = li.xpath('.//div/div[6]/div[2]/span/text()')[0]
# 图片链接
pic_link = li.xpath('./a/img/@data-original')[0]
dic = {
'标题': title,
'关注': attention,
'小区': postion.split(' ')[0],
'位置': postion.split(' ')[1],
'城市': city,
'房屋类型': types,
'面积': area,
"单价": angle_price,
'总价': count_price,
'介绍': info,
"详情网址": link,
'图片': pic_link
}
print(dic)
# 实时保存到CSV
save_to_csv(dic)
count.append(dic)
except Exception as e:
print(f"Error processing {url}: {str(e)}")
def run():
links = url_creat()
threads = []
# 创建并启动线程
for url in links:
t = threading.Thread(target=url_parse, args=(url,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
# 可选:将所有数据再次保存为完整CSV(防止漏存)
pd.DataFrame(count).to_csv(filename, index=False, encoding='utf-8-sig')
print(f"数据已保存至 {filename},共爬取 {len(count)} 条记录")
def csv_to_mysql_simple(csv_file):
"""极简版CSV数据入库"""
with open(csv_file, 'r', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
# 批量插入SQL模板
sql = """INSERT INTO House(title, attention, community, location, city, house_type, area, unit_price, total_price, description, detail_url, image_url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""
# 遍历每一行数据
for row in reader:
try:
cursor.execute(sql, (
row['标题'],
int(row['关注']), # 转换为整数
row['小区'],
row['位置'],
row['城市'],
row['房屋类型'],
row['面积'],
row['单价'],
row['总价'],
row['介绍'],
row['详情网址'],
row['图片']
))
cnx.commit() # 提交事务
except Exception as e:
print(f"插入失败: {row['标题']},错误原因: {str(e)}")
cnx.rollback() # 回滚当前事务
print("数据导入完成!")
if __name__ == '__main__':
run() # 注释该行会只讲爬取的csv文件存储在mysql数据库
csv_to_mysql_simple('西安.csv') # 注释改行会只执行爬取数据到csv文件