自己动手写CPU
说明:本文根据《自动动手写CPU》一书,整理输出,对自己是一个学习记录,也分享给大家一同进步。
1,理论篇
1.计算机组成:处理器,输入输出,存储器
2.高级编程语言->汇编指令->计算机可识别的0.1编码
3.计算机架构分为复杂指令集(CISC)和精简指令集(RISC)
区别是CISC每条指定对应的0,1编码串长度不一,而RISC每条指令对应的0,1编码串长度是固定的。
4.架构分类
4.1 x86:Intel 处理器,大多用在个人计算机,通常使用小端。
4.2 ARP:ARM公司,主要用在嵌入式,移动终端,默认是小端模式,但它是支持大端模式
4.3 SPARC:sun公司,主要用在高性能服务器,大端字节序
4.4 POWER:IBM公司,RISC指令集,IBM的服务器,工作站,现在叫PowerPC,大端字节序
4.5 MIPS:MIPS公司,国内龙芯采用,本书采用MIPS,大端字节序
5,MIPS32基本数据类型b:1bit,Byte:8bit,half word:16bit,word:32bit,Double Word:34bit,float和double
6,寄存器
/$0zero总是为0
$1at留作汇编器生成一些合成指令
$2、$3v0、v1用来存放子程序返回值
$4$7a0a3调用子程序时,使用这4个寄存器传输前4个非浮点参数
$8$15t0t7临时寄存器,子程序使用时可以不用存储和恢复
$16$23s0s7子程序寄存器变量,改变这些寄存器值的子程序必须存储旧的值并在退出前恢复,对调用程序来说值不变
$24、$25t8、t9临时寄存器,子程序使用时可以不用存储和恢复$26、 27 27 27k0、$k1由异常处理程序使用
28 或 28或 28或gpgp全局指针
29 或 29或 29或spsp堆栈指针
30 或 30或 30或fps8/fp子程序可以用来作堆栈帧指针$31ra存放子程序返回地址
7,指令集
逻辑指令:and、andi、or、ori、xor、xori、nor、lui实现逻辑与、或、异或、或非等运算。
位移指令:sll、sllv、sra、srav、srl、srlv实现逻辑左移、右移、算术右移等运算
移动指令:movn、movz、mfhi、mthi、mflo、mtlo,用于通用寄存器之间的数据移动
算术指令:add、addi、addiu、addu、sub、subu、clo、clz、slt、slti、sltiu、sltu、mul、mult、multu、madd、maddu、msub、msubu、div、divu,实现了加法、减法、比较、乘法、乘累加、除法等运算。
转移指令:jr、jalr、j、jal、b、bal、beq、bgez、bgezal、bgtz、blez、bltz、bltzal、bne,其中既有无条件转移,也有条件转移,用于程序转移到另一个地方执行。
存储指令:lb、lbu、lh、lhu、ll、lw、lwl、lwr、sb、sc、sh、sw、swl、swr,以“l”开始的都是加载指令,以“s”开始的都是存储指令,这些指令用于从存储器中读取数据,或者向存储器中保存数据。
可编程逻辑器件与Verilog HDL
运算符
算术运算符,逻辑运算符,关系运算符,等式运算符,缩位运算符,移位运算符,条件运算符和拼接运算符。

其中根据编译语言不同,大部分都是语言语法,这里省略。
2基础篇章
五级整数流水线:取指,译码,执行,访存,回写。
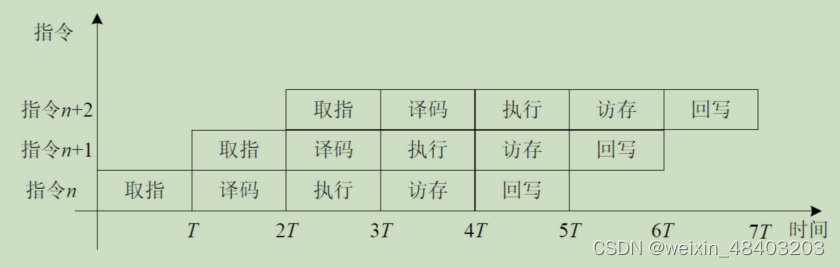
取指阶段:从指令存储器读出指令,同时确定下一条指令地址
译码阶段:对指令进行译码,从通用寄存器读出要使用的寄存器的值
执行阶段:按照译码阶段给出的操作数,运算类型,进行运算,给出运算结果
访存阶段:访问数据存储器或者将执行结果向下传递到回写阶段
回写阶段:将运算结果保存到目标寄存器
1流水线数据相关
1,流水线中经常有一些被称为相关的情况发生,它使得指令序列中下一条指令无法按照设计的时钟周期进行,回降低流水线性能
结构相关:指令执行过程中的,硬件资源冲突,例如指令和数据都共享一个存储器,某个时钟周期,流水线纪要完成指令对存储器的数据访问,又要完成后续的取指令操作,这样就发送存储器访问冲突
数据相关:流水线的几条指令依赖前面指令的执行,数据相关分为:RAW(Read After Write),WAR(Write After Read),WAW(Write After Write)。
控制相关:流水线的分支指令需要改写PC的指令造成的冲突。
说明:对于数据相关,OpenMIPS的流水线只有回写阶段才写寄存器,因为不存在WAW相关,又因为只能在流水线译码阶段读寄存器,回写阶段写寄存器,所以不存在WAR,因此只存在RWA。
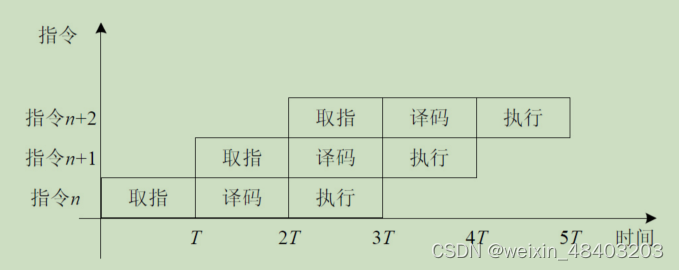
对于RWA有三种情况:相邻指令,相邻1条指令,相邻2条指令存在数据相关(这里解释下相邻指令指的是,相差一个时钟周期,上一条指令在译码阶段,下一条指令开始取指了,将得到不正确的值,其他两条以此类推,如下图)
 解决办法:1,插入暂停周期,上图取指后,暂停两个周期再译码
解决办法:1,插入暂停周期,上图取指后,暂停两个周期再译码
2,编译器检测相关后,可以改变部分指令的执行顺序,比如将译码顺序改到最后
3,数据前推,将计算结果直接送到其他指令需要处,不再回写寄存器,直接推给其他指令需要处
2 指令部分
lt (less than) 小于
le (less than or equal to) 小于等于
eq (equal to) 等于
ne (not equal to) 不等于
ge (greater than or equal to)大于等于
gt (greater than) 大于
————————————————
2.1 逻辑指令
and :逻辑与运算,指令adn rd,rs,rt,指令作用rd <- rs AND rt。将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值进行逻辑“与”运算,运算结果保存到地址为rd的通用寄存器中。
or:逻辑或运算,指令or rd, rs, rt,指令作用rd <- rs OR rt。将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值进行逻辑“或”运算,结果保存到地址rd的通用寄存器中
xor:逻辑异或,指令xor rd,rs,rt,指令作用rd <- rs XOR rt。 rd,rs,rt参数同上。
andi:与立即数逻辑与运算,指令andi rt, rs, immediate,指令作用rt <- rs AND zero_extended(immediate),将地址为rs的通用寄存器的值与指令中立即数进行零扩展后的值进行逻辑“与”运算,运算结果保存到地址为rt的通用寄存器中。
xori:与立即数逻辑异或,指令作用为:rt <- rs XOR zero_extended(immediate)
lui:指令lui rt, immediate。指令作用rt <- immediate || 016,将指令中的16bit立即数保存到地址为rt的通用寄存器的高16位。另外,地址为rt的通用寄存器的低16位使用0填充。
sll:逻辑左移,指令sll rd, rt, sa,指令作用为:rd <- rt << sa (logic),将地址为rt的通用寄存器的值向左移sa位,空出来的位置使用0填充,结果保存到地址为rd的通用寄存器中。
srl:算术右移,指令srl rd, rt, sa。指令作用rd <- rt >> sa (logic)
sra:逻辑左移,指令sra rd, rt, sa,指令作用rd <- rt >> sa (arithmetic),将地址为rt的通用寄存器的值向右移sa位,空出来的位置使用rt[31]的值填充,结果保存到地址为rd的通用寄存器中。
sllv:逻辑右移,指令sllv rd, rt, rs。指令作用rd <- rt << rs[4:0](logic),将地址为rt的通用寄存器的值向左移位,空出来的位置使用0填充,结果保存到地址为rd的通用寄存器中。移位位数由地址为rs的寄存器值的第0~4bit确定。
srav:算术右移,指令srav rd, rt, rs,指令作用为:rd <- rt >> rs[4:0](arithmetic),将地址为rt的通用寄存器的值向右移位,空出来的位置使用rt[31]填充,结果保存到地址为rd的通用寄存器中。移位位数由地址为rs的寄存器值的第0~4bit确定。
nop、ssnop和逻辑左移指令sll等价,是空指令。
and指令的译码过程
译码流程
and指令译码需要设置的三方面内容如下(or、xor、nor指令的译码过程可以参考and指令)。
(1)要读取的寄存器情况:and指令需要读取rs、rt寄存器的值,所以设置reg1_read_o、reg2_read_o为1。默认通过Regfile模块读端口1读取的寄存器地址reg1_addr_o的值是指令的第21~25bit,正是and指令中的rs,默认通过Regfile模块读端口2读取的寄存器地址reg2_addr_o的值是指令的第16~20bit,正是and指令中的rt。
(2)要执行的运算:and指令要进行的是逻辑“与”操作,所以设置alusel_o为EXE_RES_LOGIC,设置aluop_o为EXE_AND_OP。
(3)要写入的目的寄存器:and指令需要将结果写入目的寄存器,所以设置wreg_o为WriteEnable,设置wd_o为要写入的目的寄存器地址,默认是指令字的第11~15bit,正是and指令中rd的位置。
2.2 移动操作指令
movn:指令movn rd, rs, rt。指令作用if rt ≠0 then rd <- rs
movz:指令movz rd, rs, rt,指令作用if rt = 0 then rd <- rs
mfhi:指令mfhi rd。指令作用rd<-hi ,hi,lo都是特殊寄存器
mflo:指令mflo rd,指令作用rd<-lo
mthi:指令mthi rs。指令作用hi<- rs.
mtlo:指令mtlo rs。指令作用lo <- rs
2.3 算术操作指令
add:加法运算,指令add rd, rs, rt,指令作用rd <- rs + rt
addu:加法运算,指令addu rd, rs, rt,指令作用rd <- rs + rt,addu和add的区别是add会进行溢出检查,溢出后不保存结果
sub:减法运算,指令sub rd, rs, rt指令作用rd <- rs - rt,同样的剑法运算溢出,不保存结果
subu:减法运算,指令subu rd, rs, rt,指令作用rd <- rs - rt,subu和sub的区别是sub会进行溢出检查,溢出不保存结果
slt:比较运算,指令slt rd, rs, rt。指令作用rd <- (rs < rt),如果前者小于后者rd保存1,否则保存0.
sltu:比较运算,指令sltu rd, rs, rt,指令作用rd <- (rs < rt),slt和sltu的区别是sltu按照无符号数进行比较,slt按照有符号比较
addi:加法运算,指令addi rt, rs, immediate。指令作用rt <- rs + (sign_extended)immediate,加法溢出是异常,不保存结果
addiu:加法运算,指令addiu rt,rs,immediate。指令作用rt<-rs+(sign_extended)immediate,不进行溢出检查,总是将结果保存到目标寄存器
slti:比较运算,指令slti rt rs,immediate,指令作用rt <- (rs < (sign_extended)immediate)如果前者小于后者rt保存1,否则保存0
sltiu :比较运算,指令sltiu rt, rs, immediate,指令作用rt<- (rs < (sign_extended)immediate) sltiu按照无符号数进行比较,slti按照有符号比较
clz:计数运算,指令clz rd, rs。指令作用rd <- coun_leading_zeros rs,对地址为rs的通用寄存器的值,从其最高位开始向最低位方向检查,直到遇到值为“1”的位,将该位之前“0”的个数保存到地址为rd的通用寄存器中,如果地址为rs的通用寄存器的所有位都为0(即0x00000000),那么将32保存到地址为rd的通用寄存器中。
clo:计数运算,指令clo rd, rs。指令作用rd <- coun_leading_ones rs。对地址为rs的通用寄存器的值,从其最高位开始向最低位方向检查,直到遇到值为“0”的位,将该位之前“1”的个数保存到地址为rd的通用寄存器中,如果地址为rs的通用寄存器的所有位都为1(即0xFFFFFFFF),那么将32保存到地址为rd的通用寄存器中
mul:乘法运算,指令mul rd, rs, st,指令作用rd <- rs × rt
mult:乘法运算,指令mult rs, st,指令作用{hi, lo} <- rs × rt,将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值作为有符号数相乘,乘法结果的低32bit保存到LO寄存器中,高32bit保存到HI寄存器中。
multu:乘法运算,指令multu rs,st,指令作用{hi, lo} <- rs × rt。将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值作为无符号数相乘,乘法结果的低32bit保存到LO寄存器中,高32bit保存到HI寄存器中。与mult指令的区别在于:multu指令执行中将操作数作为无符号数进行运算。
madd:有符号乘累加运算,指令madd rs, rt,指令作用{HI, LO} <- {HI, LO} + rs × rt,将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值作为有符号数进行乘法运算,运算结果与{HI, LO}相加,相加的结果保存到{HI, LO}中。此处{HI, LO}表示HI、LO寄存器连接形成的64位数,HI是高32位,LO是低32位。
maddu:无符号乘累加运算,指令maddu rs, rt。指令作用{HI, LO} <- {HI, LO} + rs × rt
msub:有符号乘累减运算,指令msub rs, rt,指令作用{HI, LO} <- {HI, LO} - rs × rt将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值作为有符号数进行乘法运算。然后使用{HI, LO}减去乘法结果,相减的结果保存到{HI, LO}中。
msubu:无符号乘累减运算,指令msubu rs, rt,指令作用{HI, LO} <- {HI, LO} - rs × rt
说明:这里需要注意的是累乘加减运算采用两个时钟周期运算,第一个时钟周期进行乘法运算,第二个时钟周期乘法结果与HI,LO寄存器进行加减法
div:有符号除法,指令div rs,rt。指令作用{HI, LO} <- rs / rt 将地址为rs的通用寄存器的值,与地址为rt的通用寄存器的值,作为有符号数进行除法运算,将商保存到寄存器LO,余数保存到寄存器HI。
divu:无符号除法,指令divu rs,rt,指令作用{HI, LO} <- rs / rt
2.4 转移指令
beq: 指令beq rs, rt, offset。指令作用if rs = rt then branch,将地址为rs的通用寄存器的值与地址为rt的通用寄存器的值进行比较,如果相等,那么发生转移。所有分支指令的第0~15bit存储的都是offset,如果发生转移,那么将offset左移2位,并符号扩展至32位,然后与延迟槽指令的地址相加,加法的结果就是转移目的地址,从该地址取指令。
转移目标地址 = (signed_extend)( offset || ‘00’ ) + (pc+4)
b:指令b offset,表示无条件转移,b指令可以认为是beq指令的特殊情况,当beq指令的rs、rt都等于0时,即为b指令
bgtz:指令bgtz rs, offset,if rs > 0 then branch,如果地址为rs的通用寄存器的值大于零,那么发生转移。
blez:指令blez rs, offset。指令作用 if rs ≤ 0 then branch
bne:指令bne rs, rt, offset,指令作用 if rs ≠ rt then branch
bltz:指令bltz rs, offset,指令作用 if rs < 0 then branch 如果地址为rs的通用寄存器的值小于0,那么发生转移
bltzal:指令ltzal rs, offset,指令作用 if rs < 0 then branch 如果地址为rs的通用寄存器的值小于0,那么发生转移,并且将转移指令后面第2条指令的地址作为返回地址,保存到通用寄存器$31。
bgez :指令bgez rs, offset,指令作用 if rs ≥ 0 then branch
bgezal:指令begzal rs, offset,指令作用 if rs ≥ 0 then branch 如果地址为rs的通用寄存器的值大于等于0,那么发生转移,并且将转移指令后面第2条指令的地址作为返回地址,保存到通用寄存器$31。
bal: 指令 bal offset,指令作用 无条件转移,并且将转移指令后面第2条指令的地址作为返回地址,保存到通用寄存器$31
2.5 加载存储指令
lb:字节加载指令,指令lb rt, offset(base),指令作用,从内存中指定的加载地址处,读取一个字节,然后符号扩展至32位,保存到地址为rt的通用寄存器中。
lbu:无符号字节加载指令。指令 lbu rt, offset(base)。 指令作用从内存中指定的加载地址处,读取一个字节,然后无符号扩展至32位,保存到地址为rt的通用寄存器中
lh:半字节加载指令。指令lh rt, offset(base)。指令作用从内存中指定的加载地址处,读取一个半字,然后符号扩展至32位,保存到地址为rt的通用寄存器中。该指令有地址对齐要求,要求加载地址的最低位为0
lhu: 无符号半字加载指令,指令lhu rt, offset(base),指令作用 从内存中指定的加载地址处,读取一个半字,然后无符号扩展至32位,保存到地址为rt的通用寄存器中。该指令有地址对齐要求,要求加载地址的最低位为0。
lw :字加载指令 ,指令lw rt, offset(base),指令作用 从内存中指定的加载地址处,读取一个字,保存到地址为rt的通用寄存器中。该指令有地址对齐要求,要求加载地址的最低两位为00。
sb:字节存储指令,指令sb rt, offset(base),指令作用将地址为rt的通用寄存器的最低字节存储到内存中的指定地址。
sh:半字节存储指令,指令sh rt, offset(base),指令作用,将地址为rt的通用寄存器的最低两个字节存储到内存中的指定地址。该指令有地址对齐要求,要求计算出来的存储地址的最低位为0。
sw:字存储指令,指令sw rt, offset(base),指令作用 将地址为rt的通用寄存器的值存储到内存中的指定地址。该指令有地址对齐要求,要求计算出来的存储地址的最低两位为00。
lwr:非对齐加载指令,向左加载,指令lwl rt, offset(base),指令作用,从内存中指定的加载地址处,加载一个字的最高有效部分。lwl指令对加载地址没有要求,从而允许地址非对齐加载,这是与前面介绍的lh、lhu、lw指令的不同之处。在大端模式、小端模式下,lwl指令的效果不同。 加载地址loadaddr = signed_extended(offset) + GPR[base],n = loadaddr[1:0]loadaddr_align = loadaddr – n例如:假设计算出来的加载地址是5,lwl指令要从地址5加载数据,那么loadaddr就等于5,n等于1,loadaddr_align等于4。lwl指令的作用是从地址为loadaddr_align处加载一个字,也就是4个字节,然后将这个字的最低4-n个字节保存到地址为rt的通用寄存器的高位,并且保持低位不变。继续上例,此时loadaddr_align为4,所以从地址4处加载一个字,对应的是地址为4、5、6、7的字节,因为n等于1,所以将加载到的字的最低3个字节保存到地址rt的通用寄存器的高3个字节。
lwr:非对齐加载指令,向右加载。指令lwr rt, offset(base),指令作用 ,和lwl相反
swl:非对齐存储指令,向左存储,指令 swl rt, offset(base),指令作用 将地址为rt的通用寄存器的高位部分 存储到内存中指定的地址处,存储地址的最后两位确定了要存储rt通用寄存器的哪几个字节。
swr:非对齐存储指令,向右存储。指令 swr rt, offset(base),指令作用 将地址为rt的通用寄存器的低位部分
存储到内存中指定的地址处,存储地址的最后两位确定了要存储rt通用寄存器的哪几个字节

3 协处理器访问指令
协处理器通常标识处理器的一个可选部件,赋值处理指令集的某个扩展,MIPS32结构的协处理器 CP0系统控制 CP1 FPU CP2 特定实现CP3 FPU 本文没有浮点运算,所以不实现CP1,CP3,CP2是特定实现,以下只介绍CP0

处理异常情况
tep:指令teq rs, rt,指令作用if GPR[rs] = GPR[rt] then trap 将地址为rs的通用寄存器的值,与地址为rt的通用寄存器的值进行比较,如果两者相等,那么引发自陷异常。
tge: 指令 tge rs, rt 指令作用 if GPR[rs] ≥ GPR[rt] then trap
tgeu:指令 tgeu rs, rt,指令作用 if GPR[rs] ≥ GPR[rt] then trap
tlt :指令 tlt rs, rt,指令作用 if GPR[rs] < GPR[rt] then trap
tltu:指令tltu rs, rt。指令作用 if GPR[rs] < GPR[rt] then trap
tne:指令 tne rs, rt,指令作用 if GPR[rs] ≠ GPR[rt] then trap
teqi:指令 teqi rs, immediate,指令作用 if GPR[rs] = sign_extended(immediate) then trap
tgei :指令tgei rs, immediate。if GPR[rs] ≥ sign_extended(immediate) then trap,将地址为rs的通用寄存器的值,与指令中16位立即数符号扩展至32位后的值作为有符号数进行比较,如果前者大于等于后者,那么引发自陷异常。
tgeiu:指令tgeiu rs, immediate。指令作用 if GPR[rs] ≥ sign_extended(immediate) then trap
tlti:指令tlti rs, immediate。指令作用 if GPR[rs] < sign_extended(immediate) then trap
tltiu:指令 tltiu rs, immediate。指令作用 if GPR[rs] < sign_extended(immediate) then trap
tnei: 指令tnei rs, immediate。指令作用if GPR[rs] ≠ sign_extended(immediate) then trap


软件要运行需要操作系统
操作系统分为
1,嵌入式操作系统
2,实时操作系统
后续讲专门出一章讲述操作系统