Python编程:从基础到进阶实践指南
本文还有配套的精品资源,点击获取 
简介:本文旨在总结Python学习过程中的关键知识点,覆盖基础语法、数据结构、函数、模块化编程、面向对象编程、错误与异常处理、文件操作等方面。文章深入探讨了Python的基础知识和高级特性,包括但不限于自定义函数的灵活运用、标准库模块的使用、面向对象编程的核心概念,以及文件持久化操作。同时,文章还可能涉及源码阅读技巧、开发工具的使用,以及在实际项目中的应用,如系统接口模块的分析与编程。通过学习这些内容,读者可以提升Python编程技能,并有效地解决现实世界问题。 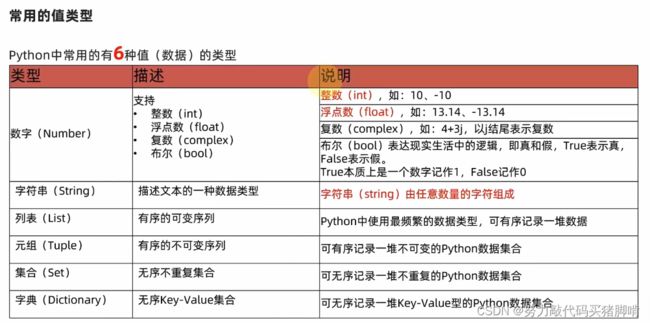
1. Python基础语法介绍与实战
简介
Python是一种优雅且功能强大的编程语言,它以简洁明了的语法和强大的库支持著称。在本章中,我们将介绍Python的基本语法,并通过实际的案例来加深理解。
1.1 Python的特点
Python的设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进来定义代码块,而不是使用大括号或关键字)。这种设计让Python非常适合初学者学习。除此之外,Python强大的标准库以及丰富的第三方库,使得它能够胜任从简单的脚本编写到复杂的科学计算。
1.2 语法基础
Python的基础语法包括变量声明、基本数据类型、控制流语句(如if-else,for循环,while循环)以及函数的定义。例如,变量无需显式声明类型即可直接赋值使用:
name = "World"
print("Hello, " + name)
上述代码中,“Hello, World”将在控制台输出。Python的输出函数print会将字符串与变量连接。
1.3 实战演练
为了更好地掌握Python基础语法,我们来一个简单的实战演练——编写一个程序,该程序能够接收用户输入并打印出一个问候语。代码如下:
# 获取用户输入
user_input = input("Please enter your name: ")
# 输出问候语
print(f"Hello, {user_input}!")
在这个例子中,我们使用了Python的 input 函数来接收用户输入,并利用格式化字符串(f-string)来将变量值嵌入字符串中输出。
小结
通过本章的学习,您已经对Python的基本语法有了一个初步的了解。下一章我们将深入探讨Python内置的数据结构,并通过实战案例来演示它们的实际应用。
2. 数据结构应用与实战
数据结构是计算机存储、组织数据的方式,它决定了数据的访问效率以及数据处理的速度。Python提供了丰富的数据结构,如列表、字典、集合和元组,它们各有特点,适用于不同的应用场景。本章节将深入探讨Python的内置数据类型以及如何高效使用它们。
2.1 Python内置数据类型详解
2.1.1 数字类型及其操作
在Python中,数字类型包括整型(int)、浮点型(float)和复数(complex)。整型用于表示整数,浮点型用于表示带有小数点的数字,而复数则用于科学计算和工程领域。
Python对数字的操作非常直观,支持加、减、乘、除以及乘方等运算。例如,以下代码展示了这些基本的数字操作:
# 定义两个整数
a = 10
b = 3
# 整数的加减乘除
print(a + b) # 输出: 13
print(a - b) # 输出: 7
print(a * b) # 输出: 30
print(a / b) # 输出: 3.***
print(a // b) # 输出: 3
print(a % b) # 输出: 1
print(a ** b) # 输出: 1000
# 定义一个浮点数
c = 2.5
# 浮点数的乘方
print(c ** 2) # 输出: 6.25
Python的浮点数采用的是双精度浮点数表示方式,遵循IEEE 754标准。需要注意的是,由于浮点数的表示不是完全精确的,所以在涉及浮点数的比较时需要特别小心。
2.1.2 字符串与编码处理
字符串是Python中的一个重要类型,它用于表示文本信息。Python 3中的字符串默认是Unicode类型,它包含了几乎所有的字符编码,并且支持中文等多字节字符。
字符串可以通过单引号 ' ' 、双引号 " " 或三引号 ''' ''' 和 """ """ 定义。字符串是不可变的序列类型,这意味着一旦创建了字符串,就不能更改其内容,但可以将新的字符串赋值给变量名。
字符串的常用操作包括拼接、重复、分割、查找和替换等,以下代码演示了这些操作:
# 定义字符串
s = 'Hello, World!'
# 字符串拼接
s = 'Hello' + ', World!'
# 字符串重复
s = 'Python' * 3
# 字符串分割
parts = s.split(',')
# 字符串查找
index = s.find('Python')
# 字符串替换
s = s.replace('Python', 'Java')
# 字符串编码转换
utf8_encoded = s.encode('utf-8')
utf8_decoded = utf8_encoded.decode('utf-8')
字符串的编码处理通常涉及编码和解码,尤其是在处理来自外部的数据源(如文件、网络等)时。Python 3默认使用UTF-8编码,但是在处理老旧的系统和数据时,可能需要使用其他编码,如GBK、ISO-8859-1等。
2.1.3 列表、元组与集合的操作和应用
列表(list)、元组(tuple)和集合(set)是Python中的三种可迭代的数据结构。它们都可以存储一系列元素,并支持迭代访问。
列表是一种有序的集合,可以包含任意类型的元素,并且可以修改,即它是可变的。列表的操作包括添加、删除、排序等。
# 创建列表
fruits = ['apple', 'banana', 'cherry']
# 列表添加元素
fruits.append('date')
# 列表删除元素
fruits.remove('banana')
# 列表排序
fruits.sort()
元组与列表类似,但是元组一旦创建就不能修改,是不可变的。元组通常用于保护数据不被修改。
# 创建元组
numbers = (1, 2, 3)
# 元组不能被修改
# numbers.append(4) # 这将引发TypeError
集合是一个无序的不重复元素集,可以用于成员资格检查和消除重复元素。
# 创建集合
unique_numbers = {1, 2, 3, 2}
# 集合操作
unique_numbers.add(4)
unique_numbers.remove(1)
这些内置的数据结构在实际应用中非常灵活,它们不仅可以单独使用,还可以组合使用以解决更复杂的问题。
2.2 数据结构的高级应用
2.2.1 字典与数据映射技巧
字典(dict)是一种映射类型的数据结构,它存储键值对,每个键值对都映射到对方。字典是可变的,且无序。字典的关键字必须是不可变类型,并且是唯一的。
# 创建字典
person = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# 字典中查找、添加和删除元素
print(person['name']) # 输出: Alice
person['email'] = '***'
del person['city']
字典的高级应用主要体现在如何高效地进行数据映射。例如,可以使用字典来模拟数据库中的表结构,或者用于实现复杂的配置管理。
2.2.2 高级数据结构:栈、队列与堆
栈、队列和堆是数据结构中的高级概念,它们在算法和编程中应用广泛。
- 栈是一种后进先出(LIFO)的数据结构,适合实现递归算法和回溯算法。
- 队列是一种先进先出(FIFO)的数据结构,用于实现任务调度和缓存机制。
- 堆是一种特殊的完全二叉树,通常用于实现优先队列。
Python中的 collections 模块提供了 deque 类,它是双端队列的实现,可以高效地实现栈和队列操作。Python没有内置的堆实现,但是可以使用 heapq 模块来创建堆。
from collections import deque
# 创建栈
stack = deque()
stack.append(1)
stack.append(2)
print(stack.pop()) # 输出: 2
# 创建队列
queue = deque()
queue.append(1)
queue.append(2)
print(queue.popleft()) # 输出: 1
2.2.3 数据结构在实际问题中的应用案例
数据结构的选择对程序的效率至关重要。例如,在实现搜索引擎时,需要使用哈希表(字典)来快速映射查询与数据。在处理网络请求时,队列被用来管理待处理的任务,保证了请求处理的顺序性。在数据库系统中,B树和B+树结构被用来管理大量数据,提供了高效的查找和插入操作。
选择合适的数据结构可以使问题的解决过程更加高效。在实际开发中,开发者应根据问题的特点和需求,结合数据结构的特点,设计出最优的数据结构组合和使用方案。
3. 函数定义与高级用法
3.1 函数的定义与作用域
3.1.1 函数的创建和调用机制
函数是组织好的,可重复使用的,用来实现单一或相关联功能的代码段。在Python中,函数定义使用关键字 def ,后接函数名和圆括号 () ,且必须以冒号 : 结尾,接下来是函数体,每行语句前面至少有一个空格缩进。
下面是一个简单的函数定义和调用示例:
def greet(name):
# 这里是一个缩进的代码块
greeting = "Hello, " + name + "!"
print(greeting)
# 调用函数
greet("Alice")
在本例中, greet 函数接收一个参数 name ,然后使用这个参数构建一个问候语,并通过 print 函数将其输出。
3.1.2 变量作用域与命名空间
Python的变量作用域由LEGB规则定义,代表Local(局部)、Enclosing(嵌套)、Global(全局)、Built-in(内置)这四种作用域。变量在定义它的作用域内可以被访问,而在它之外的则不能直接访问,除非通过特定的手段。
当访问一个变量时,Python会按照LEGB顺序在这些作用域中查找,这个查找过程是动态的。
3.1.3 实际应用
在创建函数时,理解作用域的重要性在于管理变量的生命周期和避免命名冲突。在实际应用中,特别是在复杂的应用程序中,合理使用作用域可以有效避免错误和不必要的依赖。
3.2 函数的高级特性
3.2.1 参数默认值与可变参数
函数的参数可以有默认值,也可以是可变的,允许你在调用函数时传入任意数量的参数。
def greet(name, times=1): # 默认值
print((name + "! ") * times)
greet("Alice") # 输出: Alice!
def greet_all(*names): # 可变参数
for name in names:
print("Hello, " + name + "!")
greet_all("Alice", "Bob") # 输出: Hello, Alice! Hello, Bob!
在这些示例中, greet 函数使用了一个默认参数,而 greet_all 函数则展示了如何接收任意数量的参数。
3.2.2 闭包和装饰器的原理与应用
闭包是一个函数和声明该函数的词法环境的组合。装饰器是一种设计模式,它允许用户在不修改原函数代码的前提下增加新的功能。
以下是一个闭包和装饰器的例子:
def make_multiplier(x):
def multiplier(y):
return x * y
return multiplier
double = make_multiplier(2)
print(double(5)) # 输出: 10
def decorator(func):
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
@decorator
def greet(name):
print("Hello, " + name + "!")
greet("Alice")
3.2.3 生成器表达式和迭代器的使用
生成器表达式是一种更加高效且内存友好的方式来处理数据序列,因为它们只在迭代过程中生成所需的值。而迭代器允许我们遍历容器(如列表)。
以下是一个生成器表达式和迭代器使用的例子:
# 生成器表达式
numbers = (x for x in range(10))
for number in numbers:
print(number)
# 迭代器
iterable = iter([1, 2, 3])
print(next(iterable)) # 输出: 1
这些高级特性在Python编程中非常有用,能够帮助编写出更高效、更优雅的代码。它们对于代码的模块化和重用特别重要,也是需要熟练掌握的内容。
4. 模块化编程技巧
4.1 模块与包的概念
4.1.1 模块的导入与重载
在Python中,模块是包含Python定义和语句的文件。使用模块可以让代码重用,并且可以组织代码为可管理的部分。导入模块是利用已存在的模块功能的一种简便方法,通常使用import语句。
import math
# 使用模块中的函数
result = math.sqrt(16)
print("Square root of 16 is", result)
在上述代码中,我们导入了math模块,并使用了它的sqrt函数来计算16的平方根。当一个模块被导入后,Python会执行该模块内的顶层语句。如果需要重载模块(重新启动模块内的代码),可以使用importlib模块:
import importlib
importlib.reload(math) # 重载math模块
在Python 3.4及以上版本中,可以通过importlib模块的reload函数来重新导入已有的模块,这在模块开发中非常有用,因为可以实时查看对模块所做的更改。
4.1.2 包的结构和命名约定
Python的包是一种管理命名空间的方式,可以使用文件系统中的目录来表示。一个包通常包含一个__init__.py文件,该文件可以为空,也可以包含初始化包所需的代码。
包结构示例如下:
sound/ # sound是顶级包名
__init__.py # 初始化sound包
effects/ # effects是sound包下的子包
__init__.py # 初始化effects子包
echo.py # 实现echo效果的模块
surround.py # 实现surround效果的模块
formats/ # formats是另一个子包
__init__.py
wavread.py # 读取WAV文件的模块
wavwrite.py # 写入WAV文件的模块
aiffread.py # 读取AIFF文件的模块
aiffwrite.py # 写入AIFF文件的模块
在命名包和模块时,应当避免与Python标准库中的包和模块名字冲突。同时,为了可读性和可移植性,推荐使用全小写字母来命名模块和包。
4.2 模块化编程实践
4.2.1 编写可复用模块的方法
编写一个可复用的模块首先需要明确模块功能单一化的原则。一个模块应该只做一件事情,并且做得好。例如,如果你正在编写一个模块来处理日期和时间,你不会在这个模块中放入任何处理字符串的函数,因为这违背了单一功能原则。
# date_utils.py
from datetime import datetime
def is_leap_year(year):
"""判断是否为闰年"""
return year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
def days_in_month(year, month):
"""返回指定年月的天数"""
if month == 2:
return 29 if is_leap_year(year) else 28
return (30, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31)[month - 1]
# 使用模块中的函数
print("February has 29 days?", date_utils.is_leap_year(2020))
print("April has", date_utils.days_in_month(2021, 4), "days")
在上面的例子中,我们创建了一个名为 date_utils.py 的模块,包含两个函数,分别用于判断闰年和获取某年某月的天数。这样的模块容易在不同的项目中复用。
4.2.2 构建Python包的步骤与技巧
构建Python包需要一个包含 __init__.py 的目录结构,然后你就可以像使用标准库模块一样使用你自己的包了。创建包的步骤可以分为:
- 创建包目录结构。
- 在包目录中添加
__init__.py文件,使其成为一个Python包。 - 添加模块文件到包目录中。
- 在包的
__init__.py中导入模块,或者编写代码使得模块被其他包或模块导入时自动执行。 - 打包你的模块或包,使用
setuptools等工具进行分发。
示例:
假设我们有一个名为 my_package 的包,其目录结构如下:
my_package/
__init__.py
module1.py
module2.py
我们可以在 __init__.py 文件中导入模块或者定义一些包级别的变量和函数。
4.2.3 使用虚拟环境进行模块管理
虚拟环境是一种隔离的Python运行环境,它允许你为每个项目创建独立的环境。这意味着,你可以为每个项目安装不同版本的库,并且不影响其他项目。
使用虚拟环境的步骤如下:
- 使用
venv模块创建新的虚拟环境:
python3 -m venv myenv
- 激活虚拟环境:
在Windows上:
myenv\Scripts\activate
在Unix或MacOS上:
source myenv/bin/activate
- 安装包到虚拟环境:
pip install
- 使用完虚拟环境后,可以通过以下命令退出:
deactivate
通过这种方式,我们可以确保我们的开发环境被精确地控制和隔离,避免了不同项目之间的依赖冲突。
5. 面向对象编程核心概念
面向对象编程(OOP)是当今主流的编程范式之一,它能够帮助开发者创建具有高度模块化和可复用性的代码。本章将深入探讨类和对象的基础概念以及面向对象编程的高级特性。
5.1 类与对象的基本概念
5.1.1 类的定义和实例化
在Python中,类是通过关键字 class 来定义的。一个类可以包含属性(数据)和方法(行为)。实例化一个类就是创建一个该类的对象。
class Car:
def __init__(self, model, color):
self.model = model
self.color = color
def drive(self):
print(f"This {self.color} {self.model} car is driving.")
# 创建Car类的一个实例
my_car = Car("Toyota", "blue")
以上代码创建了一个 Car 类,并定义了 model 和 color 属性以及一个 drive 方法。然后我们实例化了这个类并创建了一个名为 my_car 的对象。
5.1.2 属性和方法的封装
封装是面向对象编程的核心概念之一,它允许我们将数据和操作数据的方法捆绑在一起。在Python中,我们通常使用私有属性和方法来实现封装,以防止外部直接访问类的内部状态。
class BankAccount:
def __init__(self, owner, balance=0):
self.__owner = owner
self.__balance = balance
def deposit(self, amount):
if amount > 0:
self.__balance += amount
return True
return False
def get_balance(self):
return self.__balance
def get_owner(self):
return self.__owner
account = BankAccount("John Doe", 1000)
print(account.get_balance())
在这个例子中, BankAccount 类有两个私有属性: __owner 和 __balance 。我们通过公共方法 get_balance 和 get_owner 来获取这些属性的值,而不能直接访问它们。
5.2 面向对象的高级特性
5.2.1 继承、多态与抽象类
继承允许一个类继承另一个类的属性和方法,增强了代码的复用性。多态是指允许不同类的对象对同一消息做出响应的能力。抽象类是一种不能被实例化的类,它用于定义一系列子类需要实现的方法。
from abc import ABC, abstractmethod
class Vehicle(ABC):
@abstractmethod
def start(self):
pass
class Car(Vehicle):
def start(self):
print("Car is starting.")
class Motorcycle(Vehicle):
def start(self):
print("Motorcycle is starting.")
car = Car()
motorcycle = Motorcycle()
for vehicle in (car, motorcycle):
vehicle.start()
在这个例子中, Vehicle 是一个抽象基类,它定义了一个抽象方法 start 。 Car 和 Motorcycle 类继承自 Vehicle 并实现了 start 方法。在运行时,不同的对象表现出多态的行为。
5.2.2 静态方法和类方法的使用
静态方法是在类中定义的方法,它不属于任何特定的实例。类方法则是通过一个描述符来调用,它需要一个类作为第一个参数(通常是 cls )。
class MathUtils:
@staticmethod
def add(x, y):
return x + y
@classmethod
def multiply(cls, x, y):
return cls(x * y)
result = MathUtils.add(10, 5) # Static method call
product = MathUtils.multiply(10, 5) # Class method call
print(result) # Output: 15
print(product) # Output: 50
在这个例子中, add 是一个静态方法,它可以像普通函数一样被调用,不需要创建类的实例。 multiply 是一个类方法,它使用 cls 参数来执行操作。
5.2.3 面向对象设计原则简介
面向对象设计原则是一组规则和准则,用于编写结构良好、可维护和可扩展的面向对象程序。其中最著名的四个原则是:单一职责、开闭原则、里氏替换和接口隔离。
- 单一职责原则:一个类应该只有一个引起变化的原因。
- 开闭原则:软件实体应当对扩展开放,对修改关闭。
- 里氏替换原则:子类对象可以在程序中替换其基类对象。
- 接口隔离原则:不应该强迫客户依赖于它们不用的方法。
理解这些原则并应用到实际编程中,是提升编程能力的关键步骤。
通过本章内容的介绍,我们不仅理解了面向对象编程的基础,还学习了它的高级特性。面向对象编程是一个深奥但非常强大的范式,它为我们解决复杂问题提供了有力的工具。在实际开发中,合理地应用这些面向对象的原则和特性,将能显著提高代码的可读性、可维护性和可扩展性。
本文还有配套的精品资源,点击获取
简介:本文旨在总结Python学习过程中的关键知识点,覆盖基础语法、数据结构、函数、模块化编程、面向对象编程、错误与异常处理、文件操作等方面。文章深入探讨了Python的基础知识和高级特性,包括但不限于自定义函数的灵活运用、标准库模块的使用、面向对象编程的核心概念,以及文件持久化操作。同时,文章还可能涉及源码阅读技巧、开发工具的使用,以及在实际项目中的应用,如系统接口模块的分析与编程。通过学习这些内容,读者可以提升Python编程技能,并有效地解决现实世界问题。
本文还有配套的精品资源,点击获取