C++中数学相关知识与例题(初级)
目录
- 一、大小
- 二、最小公倍数&最大公约数
- 加减乘除
-
- 高精加
- 高精减
- 高精乘
- 高精减
- 进制
- 中位数
- 质数
- 开根
- 数列
-
- 前缀和
- 最值(最大值)
- 斐波那契数列
-
- 偏序集概念+Dilworth定理
一、大小
关于几个数的大小,我们怎么比较它们的大小呢?
int a ,b;
cin>>a>>b;
if(a>=b) cout<<a;
else cout<<b;
最简单的,使用条件语句。
当然还可以这样
#include三目运算符
基本形式 : <表达式1> ? <表达式2> : <表达式3>
很容易理解:看表达式1是否为真,如果为真,执行表达式2,否则执行表达式3.
或者这样
int a,b;
cin>>a>>b;
int maxx=max(a,b);
int minn=min(a,b);
在此基础上,你可以玩出花来了
二、最小公倍数&最大公约数
最小公倍数的定义:
几个数公有的倍数叫做这几个数的公倍数,其中最小的一个叫做这几个数的最小公倍数。
例如,4 的倍数有 4、8、12、16、20、24…,6 的倍数有 6、12、18、24、30…,12、24 等是 4 和 6 的公倍数,其中 12 是 4 和 6 的最小公倍数。
最大公约数的定义:
最大公约数,也称最大公因数,指两个或多个整数共有约数中最大的一个。例如,12 和 18,12 的约数有 1、2、3、4、6、12,18 的约数有 1、2、3、6、9、18,它们的公约数有 1、2、3、6,其中最大的是 6,所以 12 和 18 的最大公约数是 6。
关于求最大公约数我们一般使用辗转相除法即可,即用较大数除以较小数,再用出现的余数(第一余数)去除除数,再用出现的余数(第二余数)去除第一余数,如此反复,直到最后余数是 0 为止。此时的除数就是最大公约数。例如求 102 和 68 的最大公约数,102÷68 = 1……34,68÷34 = 2……0,所以 34 就是 102 和 68 的最大公约数。
至于最小公倍数,两数相乘再除以最大公约数即可。
定义很容易理解,直接上代码
#include除外我们还可以这样
#include加减乘除
这个很基础:
#include但是我们要知道,数据类型是有长度的,如果一个数据有10000位,我们就算使用unsighed long long也无济于事,这时候就轮到**高精度**登场了
使用之前我们要先知道代替数据类型,即如何存储数据——答案就是使用数组存储
接下来是读入高精度
void read(int a[]){
intlen,i;
string s;
cin>>s;
len=s.length();
memset(a,0,sizeof(a));
for(int i=1;i<=len;i++) a[i]=s[len-i]-'0';
a[0]=len;
}
接下来就是正菜了:
高精加
高精减
高精乘
高精减
进制
进制定义:
指进位制,是人们规定的一种进位方式表示某一位置上的数,运算时是逢X进一位。 比如十进制是逢十进一,二进制是逢二进一,八进制是逢八进一
取十进制转化为二进制为例:将某个十进制数除2得到的整数部分保留,作为第二次除2时的被除数,得到的余数依次记下,重复上述步骤,直到整数部分为0就结束,将所有得到的余数最终**逆序输出**,则为该十进制对应的二进制数。其他进制转化类似
#include中位数
定义:
中位数(Median)又称中值,对于有限的数集,可以通过把所有观察值
高低排序后找出正中间的一个作为中位数。如果观察值有偶数个,
通常取最中间的两个数值的平均数作为中位数。
中位数可以代表样本与分布的性质,以及补充平均数的不足
例题:[洛谷-中位数](https://www.luogu.com.cn/problem/P1168)题目描述:给定一个长度为 NN 的非负整数序列 AA,对于前奇数项求中位数。
我们可以使用STL来进行计算
vector q; //定义一个int类型的一维数组,数组名称q;
常用函数:
- q.size() //返回vector的实际长度
- q.empty() //判断是否为空,是则返回true,没有空返回false
- q.front() //返回vector的第一个元素
- q.back() //返回vector的最后一个元素
- q.push_back(x); //将元素x插入到vector的最后面
- q.pop_back() //删除vector的最后一个元素,没有返回值
- q.insert(pos,x) //在vector中pos位置插入一个元素x
- lower_bound(q.begin(),q.end(),x) //查找第一个大于或者等于x的位置
- upper_bound(q.begin(),q.end(),x) //查找第一个大于x的位置
代码演示
#include质数
定义:
又称“素数”,该数只有1和该数本身两个正因数
质数常见性质与内容:
1.质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数的数称为质数。
2.互质指的是除了1,没有其他的公因子。
3.素数p的欧拉函数为p-1,且两个素数之间的非素数的欧拉函数的值小于第一个素数的欧拉函数的值。
4.唯一分解定理:任一大于1的自然数,要么本身是质数,要么可以分解为几个质数之积,且这种分解是唯一的。
5.若n为正整数,在 n*n到 (n+1)*(n+1) 之间至少有一个质数。
6.若n为大于或等于2的正整数,在n到 n!之间至少有一个质数。
7.若质数p为不超过n( n>=4)的最大质数,则 p>(n/2) 。
8.所有大于10的质数中,个位数只有1,3,7,9。
9.对于任意的整型N,分解质因数得到N= P1^x1 * P2^x2* …… * Pn^xn,则N的因子个数M为 M=(x1+1) * (x2+1) * …… *(xn+1)。
10.n的欧拉函数为ans,那么1~n/2内与n互质的数为ans/2,因为gcd(n,m)=gcd(n,(n-m))。
11.素数定理:不超过 x 的素数的个数近似为x / In(x)
首先,我们要知道如何判断一个数是不是质数
#include此外还有优化版的:
#include在平常练题中,经常需要我们构建一个素数表(打标)
我们可以根据质数的一些性质得到一些质数
//欧拉筛
#include 开根
谈起开根号,我们可以直接使用一个函数:
double x;
cin>>x;
cout<此外,牛顿为我们提供了一种方法,我们称之为**“牛顿迭代方程”**
推荐链接如下
[牛顿迭代法](https://blog.csdn.net/melonyzzZ/article/details/127655972?spm=1001.2014.3001.5506)简言之:
这是一种用迭代求方程近似根的方法,思路就是不断取切线,用线性方程的根逼近非线性方程 f(x) = 0 的根。
比如我们要求a的平方根,就是 求二次方程 f(x) = x^2 - a = 0(a >= 0)的根,其中f(x)的导数 f'(x) = 2x,利用牛顿迭代公式,则有: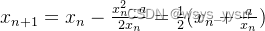
代码如下:
#include数列
前缀和
求和一般有:数组前n项求和,区间求和。
一般情况下我们用一个数组加一个for循环,利用前缀和的知识即可
#include或者这样
#include然而当数据量非常大时,我们就需要采用另一种方式:线段树。
在这里我们需要了解:线段树是一种二叉树,并不是完全二叉树。对于每个父亲节点的编号 i,他的两个儿子的编号分别是 2*i 和 2*i+1。同时因为二进制位左移一位代表着数值 ×2,而如果左移完之后再或上 1,由于左移完之后最后一位二进制位上一定会是 0 ,所以 ∣1 等价于 +1 。
#include最值(最大值)
## 最长上升子序列
#include斐波那契数列
Fibonacci 数列满足,
//矩阵快速幂+斐波那契数列
#include偏序集概念+Dilworth定理
Dilworth 定理
对于任意有限偏序集,其最大反链中元素的数目必等于最小链划分中链的数目。此定理的对偶形式亦真。
补充一下对链和反链的定义:
设 C 是偏序集的一个子集,如果 C 中元素互相可比,那么称 C 是链;如果 C 中元素互相不可比,则称 C 是反链。
可以视为链对应到哈斯图上就是一条从下至上的 “链”(有向路径)。
未完待续