条件生成对抗网络(CGAN)概念解析与用法实例:生成以假乱真的特定数字图像
目录
1. 前言
2. CGAN原理
2.1 条件信息的嵌入
2.2 生成器和判别器
2.3 损失函数
3. CGAN的实例:生成以假乱真的特定数字图像
3.1 导入必要的库
3.2 定义超参数
3.3 加载数据集
3.4 定义生成器
3.5 定义判别器
3.6 初始化生成器和判别器
3.7 定义优化器和损失函数
3.8 训练过程
3.9 生成图像
3.10 完整代码
4. 总结
1. 前言
生成对抗网络(GAN)自2014年被提出以来,就成为了深度学习领域的研究热点。GAN通过生成器和判别器的对抗训练,能够生成逼真的数据样本。然而,GAN生成的数据往往是无条件的,无法满足特定的需求。为了克服这一局限性,条件生成对抗网络(CGAN,Conditional Generative Adversarial Network)应运而生。CGAN通过引入条件信息,使得生成的数据能够符合特定的条件或属性。在本文中,我们将深入探讨CGAN的原理,并通过一个完整的Pytorch实现来展示其应用。
2. CGAN原理
CGAN的核心思想是在生成器和判别器中引入条件信息,以指导生成过程。这种条件信息可以是类别标签、文本描述等。通过这种方式,CGAN能够生成符合特定条件的数据样本。
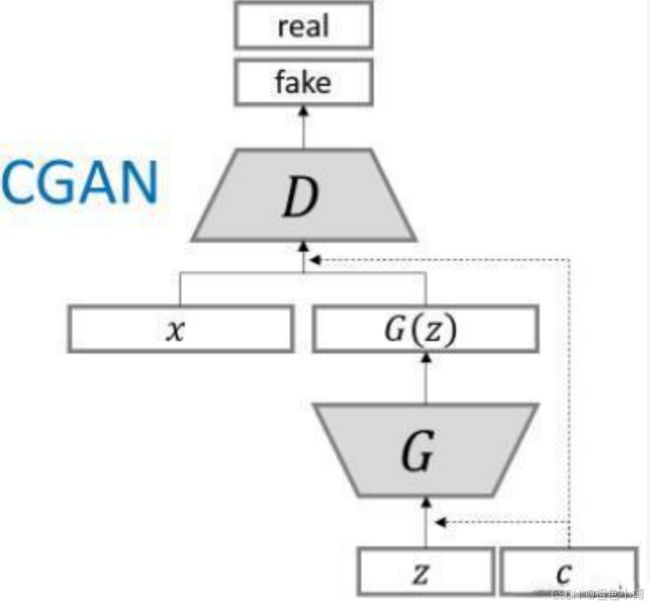
2.1 条件信息的嵌入
在CGAN中,条件信息被嵌入到生成器和判别器的输入中。对于生成器,条件信息与随机噪声一起作为输入,指导生成器生成符合特定条件的数据。对于判别器,条件信息与输入数据一起作为输入,帮助判别器判断数据是否真实且符合特定条件。
2.2 生成器和判别器
生成器的目标是生成尽可能接近真实数据的假数据,而判别器的任务是区分输入的数据是来自真实数据集还是生成器生成的假数据。在CGAN中,生成器和判别器都接收条件信息作为输入,从而能够根据条件进行生成和判断。
2.3 损失函数
CGAN的损失函数通常包括两部分:生成器的损失函数和判别器的损失函数。生成器的损失函数是判别器对其生成数据的输出值,而判别器的损失函数是交叉熵损失函数,用来衡量其区分真实数据和假数据的能力。
3. CGAN的实例:生成以假乱真的特定数字图像
接下来,我们将通过一个完整的Pytorch实现来展示CGAN的应用。我们将使用MNIST数据集来训练一个CGAN模型,使其能够生成特定数字的图像。
3.1 导入必要的库
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import matplotlib.pyplot as plt
import argparse
import numpy as np3.2 定义超参数
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)你可以在命令行运行以下命令来改变其参数:
python script.py --n_epochs 100 --lr 0.001-
opt.n_epochs的值将是 100。 -
opt.lr的值将是 0.001。 -
其他参数将使用默认值。
3.3 加载数据集
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./data/",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)-
opt.img_size: 指定目标图像的尺寸。-
如果
opt.img_size是一个整数(如 32),则图像会被调整为(32, 32)的尺寸。 -
如果
opt.img_size是一个元组(如(32, 64)),则图像会被调整为(32, 64)的尺寸。
-
3.4 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
img_shape = (opt.channels, opt.img_size, opt.img_size)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
gen_input = torch.cat((self.label_emb(labels.long()), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return imgnn.Embedding 是一个用于将离散的类别标签转换为连续向量的模块。它接受两个参数:
-
num_embeddings: 嵌入的总数(即类别数)。 -
embedding_dim: 每个嵌入向量的维度。 -
nn.Embedding(opt.n_classes, opt.n_classes)是一个嵌入层,用于将类别标签转换为嵌入向量。嵌入层的权重在训练过程中会不断更新,以学习到最优的类别表示。
torch.cat
-
作用: 将两个张量沿着指定的维度拼接在一起。
-
参数:
-
第一个参数是一个包含两个张量的元组:
(self.label_emb(labels.long()), noise)。 -
第二个参数是拼接的维度,
-1表示沿着最后一个维度拼接。
-
3.5 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels.long())), -1)
validity = self.model(d_in)
return validity3.6 初始化生成器和判别器
generator = Generator()
discriminator = Discriminator()3.7 定义优化器和损失函数
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
adversarial_loss = torch.nn.MSELoss()3.8 训练过程
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
valid = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
z = torch.randn(batch_size, opt.latent_dim)
gen_labels = torch.randint(0, opt.n_classes, (batch_size,))
optimizer_D.zero_grad()
gen_imgs = generator(z, gen_labels)
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
validity_real = discriminator(imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
optimizer_G.zero_grad()
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)在 Python 中,元组(tuple)是一种不可变的数据结构,用于存储多个元素。元组的定义通常使用括号 (),并且元素之间用逗号分隔。如果元组只有一个元素,需要在元素后面加一个逗号,否则括号会被解释为普通的括号而不是元组。
torch.randint
-
作用: 生成一个包含随机整数的张量。
-
参数:
-
0: 随机整数的下界(包含)。 -
opt.n_classes: 随机整数的上界(不包含)。 -
(batch_size,): 生成的张量的形状。
-
3.9 生成图像
generator.eval() # 设置为评估模式
# 生成随机噪声和标签
z = torch.randn(1, opt.latent_dim)
labels = torch.randint(0, opt.n_classes, (1,))
with torch.no_grad():
gen_imgs = generator(z, labels).detach().numpy()
plt.imshow(gen_imgs[0,0], cmap='gray')
plt.show()3.10 完整代码
完整代码如下方便调试:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import matplotlib.pyplot as plt
import argparse
import numpy as np
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./data/",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
self.img_shape = (opt.channels, opt.img_size, opt.img_size)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(self.img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
gen_input = torch.cat((self.label_emb(labels.long()), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *self.img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.img_shape = (opt.channels, opt.img_size, opt.img_size)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(self.img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels.long())), -1)
validity = self.model(d_in)
return validity
generator = Generator()
discriminator = Discriminator()
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
adversarial_loss = torch.nn.MSELoss()
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
valid = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
z = torch.randn(batch_size, opt.latent_dim)
gen_labels = torch.randint(0, opt.n_classes, (batch_size,))
optimizer_D.zero_grad()
gen_imgs = generator(z, gen_labels)
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
validity_real = discriminator(imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
optimizer_G.zero_grad()
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
if i%50==0:
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
generator.eval() # 设置为评估模式
# 生成随机噪声和标签
z = torch.randn(1, opt.latent_dim)
labels = torch.randint(0, opt.n_classes, (1,))
with torch.no_grad():
gen_imgs = generator(z, labels).detach().numpy()
plt.imshow(gen_imgs[0,0], cmap='gray')
plt.show()4. 总结
通过本文的介绍,我们深入了解了条件生成对抗网络(CGAN)的原理,并通过一个完整的Pytorch实现展示了其应用。CGAN通过引入条件信息,使得生成的数据能够符合特定的条件或属性。这种特性使得CGAN在图像生成、图像到图像的翻译等任务中表现出色。希望本文能够帮助读者更好地理解和应用CGAN。我是橙色小博,关注我,一起在人工智能领域学习进步!