一杯咖啡的时间学习大模型(LLM):LLaMA解读之旋转编码RoPE(含代码实现)
文章目录
-
- 一、LLaMA的核心改进全景
- 二、旋转位置编码(RoPE)
-
- 2.1 改进动机
- 2.2 数学原理
- 2.3 源码实现
一、LLaMA的核心改进全景
Meta开源的LLaMA模型凭借其卓越的性能表现成为大模型发展的重要里程碑。相较于标准Transformer架构,LLaMA主要在以下几个方面进行了关键改进:
- 位置编码升级:采用旋转位置编码(Rotary Position Embedding, RoPE)
- 归一化革新:对每个 Transformer 子层的输入进行归一化(Pre-normalization)而非传统Transformer结构中对输出进行归一化(Post - normalization),并使用RMS-Norm替代传统LayerNorm。
- 激活函数优化:引入 SwiGLU 激活函数取代 ReLU 非线性函数,以提高性能。
- 注意力优化(LLaMA 2):引入分组查询注意力(Grouped Query Attention)
这些改进显著提升了模型的计算效率和长文本处理能力,今天我们来学习一下旋转位置编码(Rotary Position Embedding, RoPE)。
其余部件的学习链接持续更新中,欢迎关注:
二、旋转位置编码(RoPE)
2.1 改进动机
首先来谈谈 Embedding 的作用。Embedding 在自然语言处理(NLP)等任务中扮演着关键角色,它本质上是一种将离散的符号(比如单词)映射到连续向量空间的技术。对于文本来说,单词经过 Embedding 后会被表示为一个低维向量,这些向量能够捕捉单词的语义信息。例如,具有相似语义的单词(如 “big” 和 “large”)在向量空间中的距离会比较近,这样模型就能利用这些向量更好地理解文本的语义。同时,Embedding 还为后续的模型运算提供了合适的数据形式,使得模型可以对这些向量进行诸如加法、乘法等数学运算,以完成对文本信息的提取和处理。
传统Transformer使用绝对位置编码存在长度外推困难,而RoPE通过旋转矩阵将相对位置信息编码到注意力计算中,实现了更好的长度外推性。
我们通过两个具体场景来观察RoPE的特点:
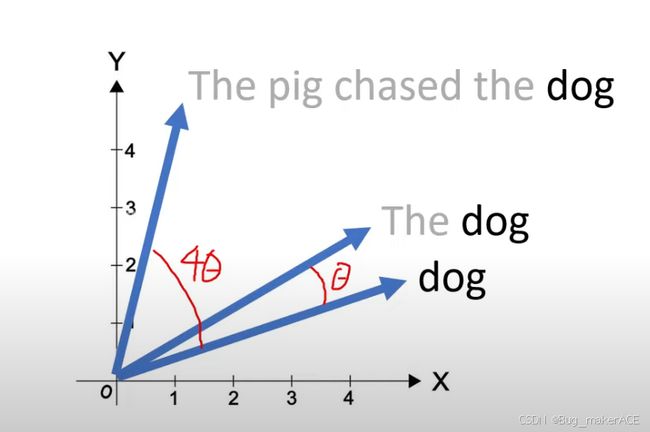
假设我们用一个二维词向量来表示单词dog,为了表示出现在不同位置的dog,可以将该词向量旋转不同的角度来添加位置信息,同时不受句子长度的干扰——无论The dog后面是十个单词还是一百个单词,因为dog还是在该句话的第二个位置,故词向量不会改变。

在第二张图片中,呈现了以 “The pig chased the dog” 以及 “Once upon a time, the pig chased the dog” 这两句文本为示例,结合直角坐标系中分别代表 “pig” 和 “dog” 的黄色与蓝色向量。
传统的 Embedding 方法,通常只是单纯地为每个词分配一个固定的向量表示,它无法有效地反映出词与词之间的相对位置信息。例如在上述文本中,对于 “pig” 和 “dog”,传统方法只是分别赋予它们独立的向量,并不考虑它们在句子中的先后顺序以及相互之间的位置关系。
而 RoPE则有很大不同。在图中能看到代表 “pig” 和 “dog” 的向量有着不同的角度。RoPE 可以通过旋转角度来获取相对位置信息。它依据词在序列中的位置,对词向量进行旋转操作。不同的位置对应着不同的旋转角度,像 “pig” 和 “dog” 因在句子中的位置有别,其对应的向量会旋转到不同角度。这样一来,模型就能通过这些角度差异,感知到词与词之间的相对位置,进而更好地理解文本的语义和结构,比如理解 “pig” 是动作 “chased” 的发出者,“dog” 是承受者这种位置带来的语义关系。
但是我们同样注意到,即使两句话中“pig”和“dog”的绝对位置不同,但是这两个名词的相对位置是一样的,因此在这两句话中,两个词向量之间的角度也是一样的。
2.2 数学原理
由于整个推理比较复杂,这里只做简单介绍,推荐几个学习资料(由易到难):
- Rotary Positional Embeddings: Combining Absolute and Relative
- 通俗易懂-大模型的关键技术之一:旋转位置编码rope
- RoPE作者(苏剑林)的博客:Transformer升级之路:2、博采众长的旋转式位置编码
给定位置m的查询向量q和位置n的键向量k,旋转操作定义为:
q m T k n = ( R θ , m q ) T ( R θ , n k ) = q T R θ , n − m T k \begin{aligned} q_m^T k_n & = (R_{\theta,m}q)^T(R_{\theta,n}k) \\ & = q^T R_{\theta,n-m}^T k \end{aligned} qmTkn=(Rθ,mq)T(Rθ,nk)=qTRθ,n−mTk
其中,其中, m m m 和 n n n 为位置索引,取值范围是 0 0 0 到序列长度(seq_len)。 q m q_m qm 表示位置为 m m m 的查询向量,其形式为 q m = { q 0 , q 1 , … , q d − 1 } q_m = \{q_0, q_1, \ldots, q_{d - 1}\} qm={q0,q1,…,qd−1},这里 d d d 是头维度(head_dim); k n k_n kn 表示位置为 n n n 的键向量,形式与 q m q_m qm 类似, k n = { k 0 , k 1 , … , k d − 1 } k_n = \{k_0, k_1, \ldots, k_{d - 1}\} kn={k0,k1,…,kd−1},同样 d d d 为头维度(head_dim)。
旋转矩阵R通过角度θ控制旋转速度,同时由于内积满足线性叠加性,因此对于任意偶数维的RoPE,我们都可以将其表示为二维情形的拼接:
R m = ( cos m θ 0 − sin m θ 0 0 0 ⋯ 0 0 sin m θ 0 cos m θ 0 0 0 ⋯ 0 0 0 0 cos m θ 1 − sin m θ 1 ⋯ 0 0 0 0 sin m θ 1 cos m θ 1 ⋯ 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 0 ⋯ cos m θ d / 2 − 1 − sin m θ d / 2 − 1 0 0 0 0 ⋯ sin m θ d / 2 − 1 cos m θ d / 2 − 1 ) R_{m} = \begin{pmatrix} \cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2 - 1} & -\sin m\theta_{d/2 - 1} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2 - 1} & \cos m\theta_{d/2 - 1} \end{pmatrix} Rm= cosmθ0sinmθ000⋮00−sinmθ0cosmθ000⋮0000cosmθ1sinmθ1⋮0000−sinmθ1cosmθ1⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2−1sinmθd/2−10000⋮−sinmθd/2−1cosmθd/2−1
但是,因为旋转矩阵比较稀疏,直接做矩阵乘法太浪费算力了。因此,我们会将之优化成下面的形式(以 R θ , m q R_{\theta,m}q Rθ,mq为例):
( q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 ) ⊗ ( cos m θ 0 cos m θ 0 cos m θ 1 cos m θ 1 ⋮ cos m θ d / 2 − 1 cos m θ d / 2 − 1 ) + ( − q 1 q 0 − q 3 q 2 ⋮ − q d − 1 q d − 2 ) ⊗ ( sin m θ 0 sin m θ 0 sin m θ 1 sin m θ 1 ⋮ sin m θ d / 2 − 1 sin m θ d / 2 − 1 ) = ∑ i = 0 d / 2 − 1 ( ( q 2 i q 2 i + 1 ) ⊗ ( cos m θ i cos m θ i ) + ( − q 2 i + 1 q 2 i ) ⊗ ( sin m θ i sin m θ i ) ) = ∑ i = 0 d / 2 − 1 ( q 2 i cos m θ i + q 2 i + 1 cos m θ i − q 2 i + 1 sin m θ i + q 2 i sin m θ i ) \begin{aligned} & \left(\begin{array}{c}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{array}\right) \otimes\left(\begin{array}{c}\cos m \theta_0 \\ \cos m \theta_0 \\ \cos m \theta_1 \\ \cos m \theta_1 \\ \vdots \\ \cos m \theta_{d / 2-1} \\ \cos m \theta_{d / 2-1}\end{array}\right)+\left(\begin{array}{c}-q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2}\end{array}\right) \otimes\left(\begin{array}{c}\sin m \theta_0 \\ \sin m \theta_0 \\ \sin m \theta_1 \\ \sin m \theta_1 \\ \vdots \\ \sin m \theta_{d / 2-1} \\ \sin m \theta_{d / 2-1}\end{array}\right) \\ = & \sum_{i=0}^{d / 2-1}\left(\binom{q_{2 i}}{q_{2 i+1}} \otimes\binom{\cos m \theta_i}{\cos m \theta_i}+\binom{-q_{2 i+1}}{q_{2 i}} \otimes\binom{\sin m \theta_i}{\sin m \theta_i}\right) \\ = & \sum_{i=0}^{d / 2-1}\left(q_{2 i} \cos m \theta_i+q_{2 i+1} \cos m \theta_i-q_{2 i+1} \sin m \theta_i+q_{2 i} \sin m \theta_i\right) \end{aligned} == q0q1q2q3⋮qd−2qd−1 ⊗ cosmθ0cosmθ0cosmθ1cosmθ1⋮cosmθd/2−1cosmθd/2−1 + −q1q0−q3q2⋮−qd−1qd−2 ⊗ sinmθ0sinmθ0sinmθ1sinmθ1⋮sinmθd/2−1sinmθd/2−1 i=0∑d/2−1((q2i+1q2i)⊗(cosmθicosmθi)+(q2i−q2i+1)⊗(sinmθisinmθi))i=0∑d/2−1(q2icosmθi+q2i+1cosmθi−q2i+1sinmθi+q2isinmθi)
其中⊗是逐位对应相乘,从这个实现也可以看到,RoPE可以视为是乘性位置编码的变体。
2.3 源码实现
下面是RoPE的Python代码实现,使用PyTorch框架:
def rotate_half(x):
"""
将输入张量的最后一个维度分成两部分,并交换它们的位置,同时对前半部分取负。
参数:
x (torch.Tensor): 输入的张量,形状可以是任意的,但最后一个维度的长度必须是偶数。
返回:
torch.Tensor: 经过旋转操作后的张量,形状与输入张量相同。
"""
# 获取输入张量x最后一个维度的一半长度
half_length = x.shape[-1] // 2
# 提取张量x最后一个维度的前半部分
x1 = x[..., :half_length]
# 提取张量x最后一个维度的后半部分
x2 = x[..., half_length:]
# 将后半部分取负,然后与前半部分在最后一个维度上拼接起来
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, freqs):
"""
对查询(query)和键(key)张量应用旋转位置编码。
参数:
q (torch.Tensor): 查询张量,通常形状为 [batch_size, seq_len, num_heads, head_dim]。
k (torch.Tensor): 键张量,通常形状为 [batch_size, seq_len, num_heads, head_dim]。
freqs (torch.Tensor): 旋转频率张量,形状为 [seq_len, head_dim]。
返回:
tuple: 包含经过旋转位置编码后的查询和键张量的元组,形状与输入的q和k相同。
"""
# 计算查询张量q应用旋转位置编码后的结果
# q * freqs.cos() 是查询张量与旋转频率的余弦值逐元素相乘
# rotate_half(q) * freqs.sin() 是将查询张量旋转后与旋转频率的正弦值逐元素相乘
# 两者相加得到最终的查询嵌入
freqs = freqs.repeat_interleave(2, dim=-1)
q_embed = (q * freqs.cos()) + (rotate_half(q) * freqs.sin())
# 计算键张量k应用旋转位置编码后的结果
# 原理与查询张量的计算相同
k_embed = (k * freqs.cos()) + (rotate_half(k) * freqs.sin())
# 返回经过旋转位置编码后的查询和键张量
return q_embed, k_embed
可能很多人看到rotate_half方法的时候会有疑惑:为什么代码中维度的前一半取正后一半取负,而不是像公式那样一正一负交替——这是因为向量维度无序,无需严格两两组合旋转。正弦和余弦函数本质都是周期波动函数,仅相位不同。RoPE 的旋转位置编码旨在用周期波动为不同位置元素赋予独特编码。理论上,特定位置用正弦还是余弦波不重要,关键是波动有周期性,且各位置编码唯一。采用前一半取正、后一半取负的方式,既能满足周期性和编码唯一性要求,又简化计算,契合代码实现对效率和简洁性的需求,是兼顾理论与实践的有效策略。
代码中的 freqs 变量指旋转频率,它是根据位置和维度信息计算得到的。具体来说,对于位置 m m m 和维度 d d d ,旋转频率 θ d \theta_d θd 通常预先定义,然后根据位置 m m m 计算出在该位置上各维度对应的旋转角度 m θ d 。 m \theta_{d 。} mθd。 一般 θ d = 1000 0 − 2 ( d / / 2 ) d model \theta_d=10000^{-\frac{2(d / / 2)}{d_{\text {model }}}} θd=10000−dmodel 2(d//2) ,其中 d model d_{\text {model }} dmodel 指的模型维度,在场景下与head_dim等价。以下是计算 freqs 的方法:
def precompute_freqs_cis(dim, end, theta=10000.0):
"""
预先计算旋转频率的复数形式。
参数:
dim (int): 模型的维度。
end (int): 序列的最大长度。
theta (float): 旋转频率的基础参数,默认为 10000.0。
返回:
torch.Tensor: 旋转频率的复数形式,形状为 [end, dim // 2]。
"""
# 计算每个维度对应的 theta 值
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 创建位置索引
t = torch.arange(end, device=freqs.device)
# 计算每个位置和维度组合的旋转角度
freqs = torch.outer(t, freqs).float()
# 将旋转角度转换为复数形式
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
print(freqs_cis.shape)
return freqs_cis # [1, seq_len, 1, head_dim]
最后给出旋转编码RoPE运行调试的完整代码:
import torch
def rotate_half(x):
"""
将输入张量的最后一个维度分成两部分,并交换它们的位置,同时对前半部分取负。
参数:
x (torch.Tensor): 输入的张量,形状可以是任意的,但最后一个维度的长度必须是偶数。
返回:
torch.Tensor: 经过旋转操作后的张量,形状与输入张量相同。
"""
# 获取输入张量x最后一个维度的一半长度
half_length = x.shape[-1] // 2
# 提取张量x最后一个维度的前半部分
x1 = x[..., :half_length]
# 提取张量x最后一个维度的后半部分
x2 = x[..., half_length:]
# 将后半部分取负,然后与前半部分在最后一个维度上拼接起来
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, freqs):
"""
对查询(query)和键(key)张量应用旋转位置编码。
参数:
q (torch.Tensor): 查询张量,通常形状为 [batch_size, seq_len, num_heads, head_dim]。
k (torch.Tensor): 键张量,通常形状为 [batch_size, seq_len, num_heads, head_dim]。
freqs (torch.Tensor): 旋转频率张量,形状为 [seq_len, head_dim]。
返回:
tuple: 包含经过旋转位置编码后的查询和键张量的元组,形状与输入的q和k相同。
"""
# 计算查询张量q应用旋转位置编码后的结果
# q * freqs.cos() 是查询张量与旋转频率的余弦值逐元素相乘
# rotate_half(q) * freqs.sin() 是将查询张量旋转后与旋转频率的正弦值逐元素相乘
# 两者相加得到最终的查询嵌入
freqs = freqs.repeat_interleave(2, dim=-1)
q_embed = (q * freqs.cos()) + (rotate_half(q) * freqs.sin())
# 计算键张量k应用旋转位置编码后的结果
# 原理与查询张量的计算相同
k_embed = (k * freqs.cos()) + (rotate_half(k) * freqs.sin())
# 返回经过旋转位置编码后的查询和键张量
return q_embed, k_embed
def precompute_freqs_cis(dim, end, theta=10000.0):
"""
预先计算旋转频率的复数形式。
参数:
dim (int): 模型的维度。
end (int): 序列的最大长度。
theta (float): 旋转频率的基础参数,默认为 10000.0。
返回:
torch.Tensor: 旋转频率的复数形式,形状为 [end, dim // 2]。
"""
# 计算每个维度对应的 theta 值
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 创建位置索引
t = torch.arange(end, device=freqs.device)
# 计算每个位置和维度组合的旋转角度
freqs = torch.outer(t, freqs).float()
# 将旋转角度转换为复数形式
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
print(freqs_cis.shape)
return freqs_cis # [1, seq_len, 1, head_dim]
# 示例使用
if __name__ == "__main__":
# 假设模型维度为 512,序列最大长度为 1024
dim = 512
end = 1024
# 假设查询和键的形状
batch_size = 2
seq_len = 128
num_heads = 8
head_dim = dim // num_heads
# 预先计算旋转频率
freqs_cis = precompute_freqs_cis(head_dim, end)
q = torch.randn(batch_size, seq_len, num_heads, head_dim)
k = torch.randn(batch_size, seq_len, num_heads, head_dim)
# 提取当前序列长度对应的旋转频率
freqs = freqs_cis[:seq_len].unsqueeze(0).unsqueeze(2)
print(freqs.shape)
# 应用旋转位置编码
q_embed, k_embed = apply_rotary_pos_emb(q, k, freqs)
print("Encoded query shape:", q_embed.shape)
print("Encoded key shape:", k_embed.shape)