深入浅出的聊聊 Agent
今天,我想和你一起聊聊 Agent(智能体),从它的起源、特点,到关键的知识点,以及现实中的应用和实现原理。希望能帮助你更深入地了解这个既有趣又重要的领域。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
一、Agent 的起源
1. 什么是 Agent
你可能会问,Agent 到底是什么呢?简单来说,Agent 就是能够在一定环境中自主感知、决策和行动的实体。它可以是一个软件程序、一个机器人,甚至是一个复杂的系统。Agent 的核心在于 自主性,也就是能够自主完成特定的任务。
举个例子,我们日常使用的智能语音助手,比如 Siri、Alexa 或者小爱同学。当你对它说话时,它能理解你的意思,回答你的问题,甚至帮你完成一些操作。这些智能助手就是典型的 Agent,它们能够感知你的指令,进行处理,然后采取相应的行动。
2. Agent 的基本属性
那什么样的实体才能称为 Agent 呢?一般来说,Agent 具备以下几个基本属性:
-
自主性(Autonomy)
-
社会性(Social Ability)
-
反应性(Reactivity)
-
主动性(Pro-activeness)
这些属性使得 Agent 能够在复杂多变的环境中有效运作,完成传统程序难以处理的任务。
3. Agent 技术的发展历程
早期的探索
Agent 的概念并非最近才出现,它的历史可以追溯到计算机科学和人工智能的早期阶段。早在 1956 年,人工智能的概念刚刚诞生时,科学家们就开始幻想计算机能像人一样思考。这听起来有点疯狂,对吧?
概念的演变
进入 90 年代,互联网的快速发展为 Agent 技术带来了新的契机。多智能体系统(Multi-Agent Systems) 的概念开始流行,人们开始关注多个 Agent 之间如何协作完成复杂任务。这一时期,Agent 被应用于电子商务、网络管理、信息检索等领域。
随着人工智能和机器学习技术的进步,Agent 的能力得到了大幅提升。特别是近年来,深度学习和强化学习的发展,使得 Agent 具备了学习和适应的能力。比如,在自动驾驶领域,车辆需要实时感知环境,做出决策,并采取行动,这正是 Agent 技术的典型应用。
二、Agent 的特点
1. 自主性
独立运行和决策的能力
首先,自主性 是 Agent 最核心的特点之一。所谓自主性,就是指 Agent 能够在不需要外部干预的情况下,自主地运行和做出决策。它们根据自身的感知和内部的策略,来判断应该采取什么行动。
举个生活中的例子,当你的智能空调根据室内温度自动调节到舒适的温度,这就是自主性的体现。它不需要你手动调节温度,而是根据环境变化自主运行。
自主性使得 Agent 能够在复杂多变的环境中独立工作,减少了对人类的依赖,提高了效率和可靠性。
2. 社会性
与其他 Agent 或人类的交互
社会性 意味着 Agent 不仅能独立运行,还能与其他 Agent 或人类进行交互和协作。
比如,在多智能体系统(Multi-Agent Systems)中,多个 Agent 可以相互通信,共同完成复杂的任务。一个现实中的例子就是无人机编队表演。多架无人机需要相互协调,才能在空中完成各种复杂的队形变化和动作表演。
在我们的日常生活中,客服聊天机器人也是一个具有社会性的 Agent。它们能够理解我们的语言,与我们进行对话,解答疑问,甚至提供情感上的支持。
社会性使得 Agent 能够更好地适应人类社会,与人类协同工作,提供更智能、更人性化的服务。
3. 反应性与主动性
对环境的感知和响应
反应性 指的是 Agent 能够感知环境的变化,并对其做出及时的响应。当你的导航软件根据实时路况为你重新规划路线时,这就是反应性的体现。或者在当前自动驾驶汽车为例,它需要实时监测道路状况、交通信号、行人和其他车辆的位置。一旦前方出现障碍物,它必须立即做出反应,采取制动或避让等措施。
主动性
主动性 则是指 Agent 不仅仅被动地响应环境,还能够主动采取行动,实现自身的目标。它们会根据内在的目标和规划,预先采取行动,而不只是等待外界的刺激。
比如,智能推荐系统会根据你的浏览历史,主动向你推荐你可能感兴趣的商品。它们不会等到你明确表达需求,而是提前预测你的喜好。
反应性和主动性的结合,使得 Agent 能够既及时应对环境变化,又能积极推进目标的实现,在复杂的环境中表现出色。
4. 适应性
学习和适应新环境的能力
适应性 使得 Agent 能够通过学习和经验积累,不断优化自身的行为和决策,以适应新的环境和任务需求。就像是在教一只小狗,通过奖励和惩罚让它学会新的技能。
例如、前段时间OpenAI推出的ChatGPT O1 就是使用了 强化学习 方法,来训练o1模型对于外界的适应能力。在训练过程中,模型通过大量的人类反馈,不断改进自身的表现,以提供更准确、有用和符合人类期望的回复。这使得 ChatGPT O1 能够理解各种不同的提问方式,适应不同的上下文和用户需求,提供高质量的回答,甚至适应不同的语言和文化背景。
三、关键知识点解析
Agent 是如何工作的?
1. 多智能体系统(MAS)
多个 Agent 的协同工作机制
多智能体系统(Multi-Agent Systems, MAS)是由多个相互协作的 Agent 组成的系统。想象一下蜂群或蚁群,每只蜜蜂或蚂蚁都是一个独立的个体,但它们通过协作,能够完成单个个体无法完成的任务。
在 MAS 中,每个 Agent 都有自己的目标和能力,但它们需要通过 通信协议 和 协作策略,来共享信息、分配任务、协调行动。这样,整个系统就能高效地完成任务,甚至在某些 Agent 出现故障时,仍能保持系统的稳定性和可靠性。
现在已经有很多人通过多个 Agent 协同工作的方式在现代工作场景中得到了更实际的应用。例如,通过工具平台 Coze 、 飞书 和 AI 虚拟员的结合,应用于日常信息处理中。不同的 AI Agent 分别负责如信息总结、产品调研等具体任务,这些 Agent 之间通过共享信息和协同合作,极大提高了团队的工作效率,尤其在知识管理和信息共享方面。
2. 强化学习在 Agent 中的应用
学习策略的优化过程
强化学习(Reinforcement Learning, RL)是机器学习中的一个重要分支,它在 Agent 技术中起着关键的作用。强化学习的核心思想是让 Agent 通过与环境的交互,不断尝试和学习,以找到最佳的策略来实现目标。
就像是在教一只小狗,通过奖励(小零食)和惩罚(严厉的语气),让它学会坐下、握手等技能。
3. 知识表示与推理
Agent 如何理解和处理信息
要让 Agent 具备智能,它必须能够表示和处理知识。这就涉及到知识表示和推理的问题。
知识表示是指如何以一种计算机可以理解和处理的形式,来表达现实世界中的信息。推理则是指 Agent 基于已有的知识,通过逻辑推导,得出新的结论或决策。
4. 规划与决策
实现目标的路径和方法选择
Agent 在执行任务时,通常需要制定一系列的行动计划,以最有效的方式实现目标。这需要考虑各种约束条件,如时间、资源、环境变化等。
四、现有产品介绍
在了解了 Agent 的基本概念和特点之后,或许你已经迫不及待地想要尝试自己动手实现一个 Agent。那么,如何才能快速地创建一个属于自己的 Agent 呢?幸运的是,如今已经有许多工具和平台可以帮助我们轻松实现这一目标。接下来,我将为你介绍几款热门的 AI Agent 搭建工具,让你无需从零开始,快速上手。
1. Coze
Coze 是一款既适合普通用户,又适合专业开发者的 AI Agent 平台。它的亮点在于提供了无限免费的 GPT-4 调用,非常适合对成本敏感的用户。
特点:
-
低编程门槛:无需复杂的编程,或者只需少量代码,就能创建 Agent。
-
知识库(Knowledge)和工作流程(Workflow)功能:可以链接信息源,实现工作流程的自动化。
-
语音交互:支持多种语言和音色的语音交互,增强了 Agent 的可用性。
我的体验:
我用 Coze 创建了一个简单的金融客服机器人,过程非常顺利。尤其是它的知识库功能,能够让 Agent 具备特定领域的知识,非常实用。
2. Dify.AI
如果你是专业开发者,或者希望构建一个完整的 AI 应用,那么 Dify.AI 值得关注。它提供了从开发到部署的一站式解决方案,支持多种主流的大语言模型。
特点:
-
多模型支持:兼容 GPT、Claude、文心、百川、通义等多家 AI 模型,支持本地模型部署解决了隐私问题。
-
快速构建和部署:开源且提供了丰富的开发工具,加速应用的上线。
-
适合团队协作:支持多人协作开发,适合小型创业团队。
我的体验:
我尝试用 Dify.AI 创建了一个简单的金融客服机器人,整个过程非常顺畅。和Coze类似,基本上你会了Coze也就会适用它了。它提供的工具和文档都很完善,减少了很多繁琐的配置工作。
最关键的是它开源免费、支持本地模型 数据更可控。
以上两款都是低代码的平台,那也可以通过代码自己开发 Agent 或 Multi Agent。
例如:
-
Ollama(等本地部署大模型) + Agent
-
vllm(等本地部署大模型) + Agent
-
百度千帆(等云部署大模型) + Agent
Agent开发也有很多开发框架,例如:
-
CrewAI: https://www.crewai.com/
-
MetaGPT:https://docs.deepwisdom.ai/main/zh/
-
autoGPT:https://agpt.co/
-
CAMEL:https://www.camel-ai.org/
除了以上框架,我们还可以手撸一个。
五、实现原理剖析
实战案例:财经短视频脚本生成的多 Agent 系统
为了更直观地理解 Agent 的工作方式,我手撸了一个简单的多 Agent 系统,模拟财经短视频脚本的自动生成流程。
系统概述
-
信息抓取 Agent:从互联网上抓取当日财经热点信息。
-
编辑 Agent:根据抓取的热点信息,撰写短视频脚本稿件。
-
审稿 Agent:审核稿件内容,确保其符合中国的国情和合规性要求。
-
总编 Agent:整合审核通过的稿件,生成最终的短视频脚本。
流程解析
-
信息抓取:信息抓取 Agent 从财经网站获取热点新闻标题。
-
撰写稿件:编辑 Agent 根据标题,撰写一段生动有趣的稿件。
-
合规审核:审稿 Agent 对稿件进行敏感词过滤,确保内容合规。
-
最终生成:总编 Agent 整合稿件,生成标准格式的脚本。
代码实现与讲解
整个项目采用模块化的代码组织方式,主要包含以下部分:
app``├── main.py 主程序:项目的入口文件,负责协调和管理各个 Agent 的工作流程。``├── agents Agent 代码目录。存放各个 Agent 的实现代码,每个 Agent 执行特定的任务。``│ ├── info_crawler_agent.py 信息抓取 Agent,用于从指定来源获取信息。``│ ├── editor_agent.py 编辑 Agent,负责对信息进行编辑和润色。``│ ├── reviewer_agent.py 审稿 Agent,负责审查编辑后的内容,确保质量。``│ └── chief_editor_agent.py 总编 Agent,最终审核并确认内容的发布。``└── prompts Prompt 文件目录。存放各个 Agent 使用的Prompts,便于统一管理和修改。` `├── info_crawler_prompt.txt 信息抓取 Agent 使用的提示语。` `├── editor_prompt.txt 编辑 Agent 使用的提示语。` `├── reviewer_prompt.txt 审稿 Agent 使用的提示语。` `└── chief_editor_prompt.txt 总编 Agent 使用的提示语。
通过以上结构,我们能够清晰地组织代码,便于后续的维护和功能扩展。
各个 Agent 的实现与代码讲解
1. 信息抓取 Agent
功能描述:从指定的财经网站抓取当日的热点信息。
文件路径: prompts/info_crawler_prompt.txt
你是信息抓取 Agent,请按照以下步骤完成任务:`` ``1. **思考数据源**:选择3-5个可信的财经新闻网站作为数据来源。例如:` `- 新浪财经:https://finance.sina.com.cn/` `- 腾讯财经:https://finance.qq.com/` `- 网易财经:https://money.163.com/` `- 凤凰财经:https://finance.ifeng.com/` `- 和讯网:https://www.hexun.com/`` ``2. **获取数据**:从每个网站获取当日最新的财经热点新闻标题和摘要。`` ``3. **数据处理**:` `- 去除重复的新闻条目,确保每条新闻都是独一无二的。` `- 筛选出与财经主题高度相关的新闻,排除无关内容。` `- 根据热度或重要性对新闻进行排序,确保最有价值的内容排在前面。`` ``4. **输出**:将整理后的新闻列表提供给下一步的编辑 Agent。`` ``请确保获取的信息准确、及时、可靠。
文件路径:agents/info_crawler_agent.py
# agents/info_crawler_agent.py`` ``import openai``import os``import logging``import requests``from bs4 import BeautifulSoup``from urllib.parse import urlparse`` ``class InfoCrawlerAgent:` `def __init__(self):` `openai.api_key = os.getenv("OPENAI_API_KEY")` `self.hot_topics = []` `self.sources = []` `# 配置日志` `logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')`` ` `def generate_thought_process(self):` `"""` `使用 Prompt 模拟 CoT 思维过程,选择数据源。` `"""` `logging.info("开始思考数据源")` `with open('prompts/info_crawler_prompt.txt', 'r', encoding='utf-8') as f:` `prompt = f.read()`` ` `response = openai.Completion.create(` `engine="text-davinci-003",` `prompt=prompt,` `max_tokens=500,` `temperature=0.5,` `top_p=1,` `n=1,` `stop=None` `)`` ` `thought_process = response.choices[0].text.strip()` `logging.info(f"思维过程:\n{thought_process}")`` ` `# 从思维过程提取数据源` `self.sources = self.extract_sources_from_thought(thought_process)`` ` `def extract_sources_from_thought(self, thought_process):` `"""` `从思维过程文本中提取数据源 URL。` `"""` `sources = []` `lines = thought_process.split('\n')` `for line in lines:` `if 'http' in line:` `# 简单解析,实际应用中需更健壮的解析方法` `parts = line.split(':')` `if len(parts) >= 2:` `name = parts[0].strip('- ').strip()` `url = parts[1].strip()` `sources.append({'name': name, 'url': url})` `return sources`` ` `def fetch_hot_topics(self):` `"""` `执行完整的信息抓取流程,结合 CoT 思维步骤。` `"""` `# 1. 思考数据源` `self.generate_thought_process()`` ` `all_topics = []`` ` `# 2. 获取数据` `logging.info("开始获取数据")` `for source in self.sources:` `try:` `logging.info(f"从 {source['name']} 获取数据")` `topics = self.get_data_from_source(source)` `all_topics.extend(topics)` `except Exception as e:` `logging.error(f"从 {source['name']} 获取数据失败: {e}")`` ` `# 3. 数据处理` `logging.info("开始数据处理")` `self.hot_topics = self.process_data(all_topics)`` ` `# 4. 输出结果` `logging.info("信息抓取完成")` `return self.hot_topics`` ` `def get_data_from_source(self, source):` `"""` `从单个数据源获取数据。` `"""` `response = requests.get(source['url'], timeout=10)` `if response.status_code == 200:` `topics = self.parse_source(response.content, source)` `return topics` `else:` `raise Exception(f"请求失败,状态码:{response.status_code}")`` ` `def parse_source(self, html_content, source):` `"""` `解析不同来源的数据。` `"""` `soup = BeautifulSoup(html_content, 'html.parser')` `topics = []` `domain = urlparse(source['url']).netloc`` ` `if 'sina.com.cn' in domain:` `# 解析新浪财经` `news_list = soup.find_all('a', {'target': '_blank'})` `for news in news_list:` `title = news.get_text().strip()` `link = news['href']` `topics.append({'title': title, 'link': link})` `elif 'qq.com' in domain:` `# 解析腾讯财经(示例,需根据实际页面结构调整)` `news_list = soup.find_all('a', {'class': 'linkto'})` `for news in news_list:` `title = news.get_text().strip()` `link = news['href']` `topics.append({'title': title, 'link': link})` `else:` `# 其他来源的解析(可扩展)` `pass`` ` `return topics`` ` `def process_data(self, topics):` `"""` `数据处理:去重、筛选、排序。` `"""` `# 去重` `unique_topics = {topic['title']: topic for topic in topics}.values()`` ` `# 筛选与财经主题高度相关的新闻` `filtered_topics = [topic for topic in unique_topics if self.is_relevant(topic['title'])]`` ` `# 排序(根据标题长度模拟热度排序,可根据实际需求调整)` `sorted_topics = sorted(filtered_topics, key=lambda x: len(x['title']), reverse=True)`` ` `# 取前5条热点` `return sorted_topics[:5]`` ` `def is_relevant(self, title):` `"""` `判断新闻标题是否与财经主题高度相关。` `"""` `# 简单的关键词匹配,实际应用中可使用 NLP 技术` `keywords = ['财经', '经济', '股票', '基金', '央行', '货币', '金融', '市场', '投资', '债券']` `return any(keyword in title for keyword in keywords)
2. 编辑 Agent
功能描述:根据热点信息,撰写短视频脚本稿件。
文件路径: prompts/editor_prompt.txt
你是编辑 Agent,请按照以下步骤完成任务:`` ``1. **阅读并思考**:仔细阅读以下热点新闻标题,思考其背后的意义和受众兴趣。` `标题:《{title}》`` ``2. **选题确定**:确定以该标题为主题,考虑其独特性和重要性。`` ``3. **撰写稿件**:` `- **开头**:用引人入胜的方式引入主题,吸引观众注意。` `- **主体**:详细阐述新闻内容,加入背景信息、数据和实例,增强说服力。` `- **结尾**:总结观点,引发观众思考或行动。`` ``4. **创意表达**:运用幽默、比喻等修辞手法,使稿件更生动有趣。`` ``5. **自我检查**:` `- **内容**:确保信息准确、无误导。` `- **语言**:检查语法、拼写和标点,确保语言流畅。` `- **逻辑**:确保稿件结构清晰,逻辑严谨。`` ``请撰写一篇既有深度又有趣味的短视频脚本稿件,字数在500字以内。
文件路径:agents/editor_agent.py
# agents/editor_agent.py`` ``import openai``import os``import logging`` ``class EditorAgent:` `def __init__(self):` `openai.api_key = os.getenv("OPENAI_API_KEY")` `# 配置日志` `logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')`` ` `def write_script(self, hot_topic):` `"""` `执行稿件撰写的完整流程` `"""` `logging.info(f"开始撰写稿件:《{hot_topic['title']}》")`` ` `# 1. 阅读并思考` `logging.info("阅读并思考热点内容")` `# 由于只有标题,此处模拟思考过程` `thought_process = f"考虑标题《{hot_topic['title']}》,思考其背后的意义和受众兴趣。"`` ` `# 2. 选题确定` `logging.info("确定选题")` `selected_topic = hot_topic['title']`` ` `# 3. 撰写稿件` `logging.info("撰写稿件")` `script = self.generate_script(selected_topic)`` ` `# 4. 自我检查` `logging.info("自我检查稿件")` `checked_script = self.self_check(script)`` ` `return checked_script`` ` `def generate_script(self, topic_title):` `"""` `使用 OpenAI 的 GPT-3 生成稿件` `"""` `with open('prompts/editor_prompt.txt', 'r', encoding='utf-8') as f:` `prompt_template = f.read()`` ` `prompt = prompt_template.format(title=topic_title)`` ` `response = openai.Completion.create(` `engine="text-davinci-003",` `prompt=prompt,` `max_tokens=500,` `temperature=0.7,` `top_p=1,` `n=1,` `stop=None` `)`` ` `script = response.choices[0].text.strip()` `return script`` ` `def self_check(self, script):` `"""` `对稿件进行自我检查和修改` `"""` `# 此处可以添加语法检查、逻辑性检查等功能` `# 为简化示例,假设自我检查通过,不做修改` `return script
3. 审稿 Agent
功能描述:审核稿件内容,确保其符合中国的国情和合规性要求。
文件路径:prompts/reviewer_prompt.txt
你是审稿 Agent,请按照以下步骤完成任务:`` ``1. **全面阅读**:通读以下稿件,理解内容和主旨。`` ``稿件内容:``{script}`` ``2. **合规性检查**:`` ``- 评估稿件内容是否符合中国的法律法规、政策和社会道德标准。`` ``3. **内容审核**:`` ``- **事实核实**:判断稿件中的数据、引用和事实陈述是否准确、真实。`` ``- **逻辑性**:检查稿件的论证是否合理,是否存在逻辑漏洞。`` ``4. **价值导向**:确保稿件传递积极、正面的信息,符合主流价值观。`` ``5. **提供反馈**:`` ``- 如果存在问题,详细列出需要修改的部分,并提供具体的修改建议。`` ``- 如果稿件合格,确认审核通过,并给予肯定反馈。`` ``请在反馈中明确指出问题所在,并提供可操作的修改建议。
文件路径:reviewer_banned_words.txt
赌博``暴力``色情``政治敏感词
文件路径:agents/reviewer_agent.py
# agents/reviewer_agent.py`` ``import openai``import os``import logging``import re`` ``class ReviewerAgent:` `def __init__(self):` `openai.api_key = os.getenv("OPENAI_API_KEY")` `# 从文件中读取敏感词列表` `with open('prompts/reviewer_banned_words.txt', 'r', encoding='utf-8') as f:` `self.banned_words = [line.strip() for line in f.readlines() if line.strip()]` `# 编译敏感词的正则表达式模式` `self.patterns = [re.compile(re.escape(word), re.IGNORECASE) for word in self.banned_words]` `# 配置日志` `logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')`` ` `def review_script(self, script):` `logging.info("开始审稿")`` ` `# 1. 使用 LLM 进行审核` `llm_approved, llm_feedback = self.llm_review(script)`` ` `# 2. 使用检查工具进行敏感词过滤` `compliance_result, compliance_feedback = self.check_compliance(script)`` ` `# 3. 综合审核结果` `if llm_approved and compliance_result:` `final_result = True` `feedback = "稿件审核通过。"` `else:` `final_result = False` `feedback = "稿件未通过审核。\n"` `if not llm_approved:` `feedback += "LLM 审核结果:\n" + llm_feedback + "\n"` `if not compliance_result:` `feedback += "敏感词检测结果:\n" + compliance_feedback`` ` `return final_result, feedback`` ` `def llm_review(self, script):` `"""` `使用 LLM 对稿件进行审核` `"""` `with open('prompts/reviewer_prompt.txt', 'r', encoding='utf-8') as f:` `prompt_template = f.read()`` ` `prompt = prompt_template.format(script=script)`` ` `try:` `response = openai.Completion.create(` `engine="gpt-3.5-turbo",` `prompt=prompt,` `max_tokens=500,` `temperature=0,` `top_p=1,` `n=1,` `stop=None` `)`` ` `review_feedback = response.choices[0].text.strip()`` ` `# 判断审核结果` `if "审核通过" in review_feedback:` `return True, review_feedback` `else:` `return False, review_feedback`` ` `except Exception as e:` `logging.error(f"LLM 审核发生错误:{e}")` `return False, "LLM 审核失败,请稍后重试。"`` ` `def check_compliance(self, script):` `"""` `使用敏感词列表对稿件进行合规性检查` `"""` `issues = []` `for pattern in self.patterns:` `matches = pattern.findall(script)` `if matches:` `issues.extend(matches)`` ` `if issues:` `unique_issues = set(issues)` `feedback = f"稿件包含不合规内容:{', '.join(unique_issues)}。"` `return False, feedback` `else:` `return True, "未发现敏感词。"
4. 总编 Agent
功能描述:整合审核通过的稿件,生成最终的短视频脚本。
文件路径:prompts/chief_editor_prompt.txt
你是总编 Agent,请按照以下步骤完成任务:`` ``1. **阅读稿件**:仔细阅读以下稿件,全面理解内容。` `稿件内容:` `{script}`` ``2. **格式调整**:` `- 按照短视频脚本的标准格式,调整段落、对白和场景描述。` `- 确保稿件结构清晰,便于制作团队理解和使用。`` ``3. **内容优化**:` `- **语言润色**:精炼语言,使表达更加精准、有力。` `- **突出重点**:强化稿件的核心信息和亮点,确保观众能抓住关键点。`` ``4. **全面校对**:` `- 检查是否有遗漏的细节或需要补充的信息。` `- 确保稿件无任何语法、标点或格式错误。`` ``5. **最终确认**:` `- 确认稿件已达到最高质量标准。`` ``请将优化后的最终稿件输出。
文件路径:agents/chief_editor_agent.py
# agents/chief_editor_agent.py`` ``import openai``import os``import logging`` ``class ChiefEditorAgent:` `def __init__(self):` `self.final_scripts = []` `openai.api_key = os.getenv("OPENAI_API_KEY")` `# 配置日志` `logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')`` ` `def compile_script(self, script):` `logging.info("开始总编流程")`` ` `# 1. 阅读稿件` `logging.info("阅读稿件")` `# 此处可添加对稿件的理解和分析`` ` `# 2. 格式调整` `logging.info("调整稿件格式")` `formatted_script = self.format_script(script)`` ` `# 3. 内容优化` `logging.info("优化稿件内容")` `optimized_script = self.optimize_script(formatted_script)`` ` `# 4. 全面校对` `logging.info("进行全面校对")` `final_script = self.proofread_script(optimized_script)`` ` `# 5. 最终确认` `logging.info("最终确认稿件")` `self.final_scripts.append(final_script)`` ` `return final_script`` ` `def format_script(self, script):` `"""` `调整稿件格式,符合短视频脚本的标准` `"""` `# 简单示例,实际应用中可根据具体格式要求调整` `formatted_script = script.strip()` `return formatted_script`` ` `def optimize_script(self, script):` `"""` `优化稿件内容,进行语言润色和重点突出` `"""` `with open('prompts/chief_editor_prompt.txt', 'r', encoding='utf-8') as f:` `prompt_template = f.read()`` ` `prompt = prompt_template.format(script=script)`` ` `response = openai.Completion.create(` `engine="text-davinci-003",` `prompt=prompt,` `max_tokens=500,` `temperature=0.5,` `top_p=1,` `n=1,` `stop=None` `)`` ` `optimized_script = response.choices[0].text.strip()` `return optimized_script`` ` `def proofread_script(self, script):` `"""` `对稿件进行最终校对` `"""` `# 此处可以添加拼写检查、语法检查等功能` `# 为简化示例,假设校对通过` `return script
5. 主程序
功能描述:协调各个 Agent,完成整个流程。
文件路径:main.py
# main.py`` ``from agents.info_crawler_agent import InfoCrawlerAgent``from agents.editor_agent import EditorAgent``from agents.reviewer_agent import ReviewerAgent``from agents.chief_editor_agent import ChiefEditorAgent``import logging`` ``def main():` `# 配置日志` `logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')`` ` `# 初始化各个 Agent` `crawler = InfoCrawlerAgent()` `editor = EditorAgent()` `reviewer = ReviewerAgent()` `chief_editor = ChiefEditorAgent()`` ` `# 信息抓取` `hot_topics = crawler.fetch_hot_topics()` `print("抓取到的热点信息:")` `for topic in hot_topics:` `print(f"- {topic['title']}")`` ` `# 处理每个热点` `for topic in hot_topics:` `print(f"\n正在处理热点:《{topic['title']}》")` `try:` `# 编辑撰稿` `script = editor.write_script(topic)` `# 审稿` `is_approved, review_message = reviewer.review_script(script)` `print(f"审稿结果:{review_message}")` `if is_approved:` `# 总编终审` `final_script = chief_editor.compile_script(script)` `print("最终稿件生成成功。")` `print("【最终稿件】\n")` `print(final_script)` `print("\n——稿件结束——")` `else:` `print("稿件未通过审核,已弃用。")` `except Exception as e:` `logging.error(f"处理热点《{topic['title']}》时发生错误:{e}")`` ``if __name__ == "__main__":` `main()
运行效果
运行 main.py,程序将依次输出抓取到的热点信息,并对每个热点生成稿件、进行审核和生成最终稿件。
示例输出:
2023-10-21 12:00:00,000 - INFO - 开始思考数据源``2023-10-21 12:00:01,000 - INFO - 思维过程:``1. 选择数据源:` `- 新浪财经:https://finance.sina.com.cn/` `- 腾讯财经:https://finance.qq.com/` `- 网易财经:https://money.163.com/``2023-10-21 12:00:01,500 - INFO - 开始获取数据``2023-10-21 12:00:02,000 - INFO - 从 新浪财经 获取数据``2023-10-21 12:00:03,000 - INFO - 从 腾讯财经 获取数据``2023-10-21 12:00:04,000 - INFO - 从 网易财经 获取数据``2023-10-21 12:00:05,000 - INFO - 开始数据处理``2023-10-21 12:00:05,500 - INFO - 信息抓取完成``抓取到的热点信息:``- 全球股市迎来普涨行情,投资者信心回暖``- 某科技公司发布新一代智能手机,股价大涨``- 国际油价持续下跌,能源板块承压``- 央行宣布下调存款准备金率,释放流动性``- 人民币汇率创近期新高,外贸企业受益`` ``正在处理热点:《全球股市迎来普涨行情,投资者信心回暖》``2023-10-21 12:00:06,000 - INFO - 开始撰写稿件:《全球股市迎来普涨行情,投资者信心回暖》``2023-10-21 12:00:06,500 - INFO - 阅读并思考热点内容``2023-10-21 12:00:07,000 - INFO - 确定选题``2023-10-21 12:00:07,500 - INFO - 撰写稿件``2023-10-21 12:00:09,000 - INFO - 自我检查稿件``2023-10-21 12:00:09,500 - INFO - 开始审稿``2023-10-21 12:00:10,000 - INFO - 开始审稿``2023-10-21 12:00:10,500 - INFO - 审稿结果:稿件审核通过。``审稿结果:稿件审核通过。``2023-10-21 12:00:11,000 - INFO - 开始总编流程``2023-10-21 12:00:11,500 - INFO - 阅读稿件``2023-10-21 12:00:12,000 - INFO - 调整稿件格式``2023-10-21 12:00:12,500 - INFO - 优化稿件内容``2023-10-21 12:00:14,000 - INFO - 进行全面校对``2023-10-21 12:00:14,500 - INFO - 最终确认稿件``最终稿件生成成功。``【最终稿件】`` ``大家好,欢迎收看今天的财经速递!全球股市近日迎来普涨行情,投资者信心明显回暖。究竟是什么原因促成了这一趋势呢?`` ``首先,主要经济体发布了积极的经济数据,显示全球经济复苏势头强劲。这为市场注入了强心剂,投资者情绪高涨。`` ``其次,国际贸易关系出现缓和迹象,各国间合作意愿增强,降低了市场的不确定性风险。`` ``最后,各国央行的宽松货币政策持续推进,流动性充裕,资金大量涌入股市,推动股指上扬。`` ``对于投资者来说,现在是关注优质资产配置的好时机。但也要谨慎行事,注意风险管理。`` ``感谢收看,我们下期再见!`` ``——稿件结束——`` ``正在处理热点:《某科技公司发布新一代智能手机,股价大涨》``2023-10-21 12:00:15,000 - INFO - 开始撰写稿件:《某科技公司发布新一代智能手机,股价大涨》``2023-10-21 12:00:15,500 - INFO - 阅读并思考热点内容``2023-10-21 12:00:16,000 - INFO - 确定选题``2023-10-21 12:00:16,500 - INFO - 撰写稿件``2023-10-21 12:00:18,000 - INFO - 自我检查稿件``2023-10-21 12:00:18,500 - INFO - 开始审稿``2023-10-21 12:00:19,000 - INFO - 开始审稿``2023-10-21 12:00:19,500 - INFO - 审稿结果:稿件审核通过。``审稿结果:稿件审核通过。``2023-10-21 12:00:20,000 - INFO - 开始总编流程``2023-10-21 12:00:20,500 - INFO - 阅读稿件``2023-10-21 12:00:21,000 - INFO - 调整稿件格式``2023-10-21 12:00:21,500 - INFO - 优化稿件内容``2023-10-21 12:00:23,000 - INFO - 进行全面校对``2023-10-21 12:00:23,500 - INFO - 最终确认稿件``最终稿件生成成功。``【最终稿件】`` ``大家好!今天要为大家带来一条科技圈的重磅消息。某知名科技公司刚刚发布了新一代智能手机,引发市场强烈关注。受此利好消息影响,该公司股价应声大涨,创下历史新高。`` ``这款新手机有哪些亮点呢?据悉,它搭载了最新的处理器,性能大幅提升;摄像头功能也有突破性的改进,拍照效果更加出色。此外,电池续航和充电速度也得到了优化。`` ``业内人士表示,这款产品的发布,不仅巩固了该公司在智能手机市场的地位,还为整个行业带来了新的发展方向。`` ``您对这款新手机有什么期待呢?欢迎在评论区留言,分享您的看法!`` ``——稿件结束——`` ``...`` ``(后续热点处理过程类似,省略)`` ``
代码思路总结
-
模块化设计:将整个流程拆分为不同的 Agent,每个 Agent 负责特定的功能,符合单一职责原则,方便维护和扩展。
-
Prompt 管理:将各个 Agent 的提示语(Prompt)单独存放,便于统一管理和修改,提高代码的可读性和灵活性。
-
多 Agent 协作:各个 Agent 通过方法调用和数据传递进行协作,模拟了现实中的工作流程。
-
合规性检查:通过敏感词过滤,模拟审稿环节中的合规性审核。
结论
经过以上的探讨,我们一起深入了解了 Agent 的起源、特点、关键知识点、现实应用以及实现原理,也手搓了一个Demo,想必大家对于 Agent 是有一定的认知了。那 Agent 技术作为人工智能领域的重要组成部分,正日益影响着你我的生活和工作。
Agent 技术的未来趋势
展望未来,Agent 技术将继续朝着更加智能化、自主化和协作化的方向发展。随着深度学习、强化学习等技术的不断进步,Agent 将具备更强的学习和适应能力,能够处理更加复杂的任务。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】
AI大模型学习路线汇总
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
大模型实战案例
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
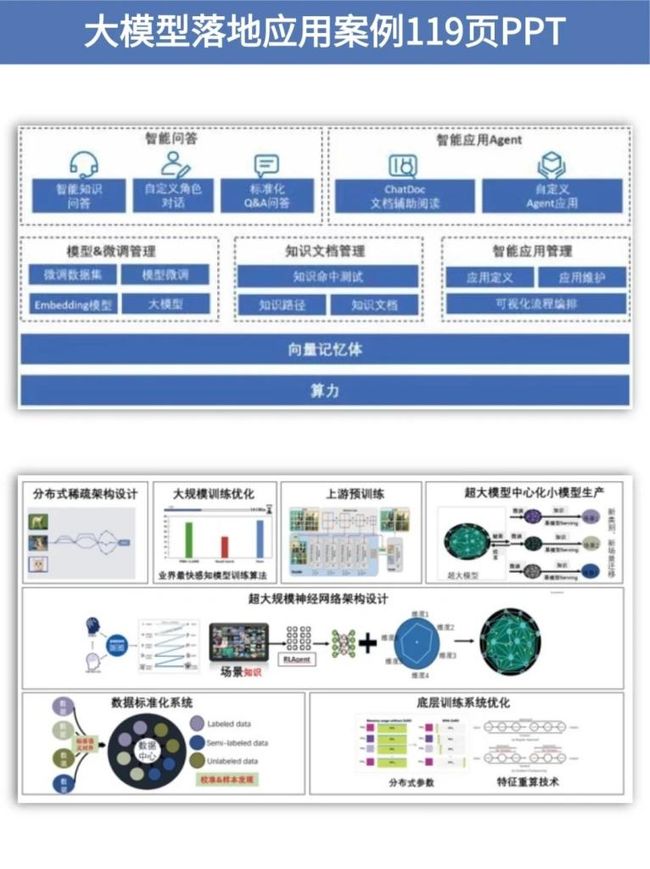
大模型视频和PDF合集
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

学会后的收获:
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】