The Vertica Analytic Database:C-Store 7 Years Later笔记
1、设计目标
Vertica数据库可以说是7年之后的C-Store,在2012年发表的这样一篇论文,描述了现在基于C-Store的一部分改进,当然,Vertica借鉴了很多C-Store的思想,但并非完全是C-Store。由于Vertica也是分析型数据库,所以数据设计的目标也是重读不重写或者说是重分析轻事务(Vertica was explicitly designed for analytic workloads rather than for transactional workloads)。那么什么是事务压力,什么是分析压力呢。
- Transactional:事务压力主要来自于每秒的事务并发量可能有上千,并且这些事务涉及少量的元组。通常是删除某些元组,增加某些元组,或者修改某一列上的某一个值。
- Analytic:分析压力并不在于多数的事务并发,分析压力主要在于每一个事务所涉及的元组数很多,可能是一张表中的大部分元组。
既然Vertica数据库应用场景在于分析,所以主要压力来源于查询,那么列式数据库相对于传统的行式数据库而言,在事务上控制相对难,但是在查询和分析上有天然的优势。
2、数据模型
这一部分Vertica的设计和C-Store基本一致,在数据模型上,同样是projection和segment,Vertica同样是分布式数据库,在数据分布上,以Segment为单位,至于怎样划分Segement,Vertica采用Hash某一个属性值得方式进行划分。
另外在压缩方面,也和C-Store大同小异。压缩方式有六种:
- Auto:系统基于存储内容自动选择最优的编码方式
- RLE:通过一个简单的键值对(值和值出现的次数)来替换一个连续的序列
- Delta Value:记录增量数据。
- Block Dictionary:字典压缩
- Compressed Delta Range:通过记录和上一条记录的差异来存储数据
- Compressed Common Delta:对所有的增量数据建立字典。
3、查询执行
这一块儿是Vertica相对于C-Store改进的地方,查询执行的主要目的在于解析SQL语句,转变为数据库内部可以执行的执行方案。那么针对这一目的,Vertica设计了查询执行这一模块。
3.1 物理运算符
计划的执行是通过Execution Engine(EE)进行的,在EE内部,实现了7种物理运算符:
- Scan:从一个projection里面读出数据。
- GroupBy:对数据进行group和agg操作,在这一块儿有基于hash的不同算法,具体用哪一种算法取决于需要多高的效率,多大的内存以及运算符是否需要提供独立的组别。
- Join:实现了关系与关系之间的join操作,包括INNER,LEFT OURTER,RIGHT OUTER,FULL OUTER,SEMI以及ANTI joins
- ExprEval:对一个表达式进行计算
- Sort:对数据进行排序
- Analytic:计算SQL-99中的聚合运算方面的操作(max,avg,sum等等)
- Send/Recv:从一个节点发送元组到另一个节点或者是接收从另外一个节点发送过来的元组。
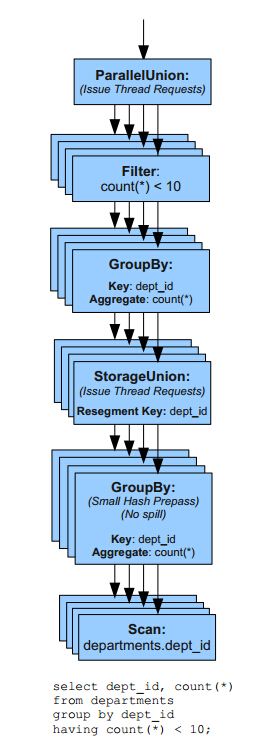
6.2 查询优化
在C-Store中,有最小化的查询优化模块,只提供了很简单的查询优化操作,join的操作顺序呢完全是随机的。这一块儿是Vertica相比于C-Store改进最大的地方,Vertica在查询优化方面经历了三个阶段:StarOpt,StarifiedOpt,以及V2Opt。
但是论文里面仅仅只是对这三个阶段进行了介绍,并没有说明实现的具体思路是什么。所以很可惜,毕竟是HP的商业数据库,所以这一块儿只能有一个大概的思想和思路。