基于Diffusion Model的数据增强方法应用——毕业设计 其三
文章目录
- 题目简介
- 前言
- Stable Diffusion
-
- Latent diffusion
-
- 自动编码器(VAE)
- U-Net
- Text-Encoder
- Stable Diffusion的推理过程
- 从零开始配置实验环境
-
- IDE
- Anaconda
- CUDA和CuDNN
-
- CuDNN
- Stable Diffusion的本地部署
- 运行测试
- 总结
题目简介
笔者个人的毕业设计课题如下:
简介:使用预训练的Diffusion Model图像生成模型生成图像,将这些生成的图像作为扩充训练集加入到2D目标检测器、2D图像分类器的训练过程。深度学习是数据驱动的,随着数据量的扩充,能够提高检测器、分类器的鲁棒性、准确性。
建议的baseline:
分类:ResNet
检测:YOLO
可以看到,给的题目难度还是比较轻松的;本次毕设的全过程会以周为单位采用博客的形式记录下来。
前言
由于个人原因,这周还是没法使用实验室的卡;但是不要紧,手边有一台刚组的机子,配的12G的4070ti,用来跑一个扩散模型还是没什么问题的。
另一方面需要考虑的是,基于Diffusion Model这个原理的模型有很多,具体要使用哪一个来完成本次毕业设计呢?笔者第一时间想到的是发表在去年CVPR上的Stable Diffusion,很多人熟悉的AI绘画去年的大火,和这个模型是脱不开关系的。
上图所示为Stable Diffusion的官网
一方面,在扩散模型的理论应用上,最出名又最新的就是Stable Model;另一方面,免费开源,且模型设计亲民,甚至可以在消费级显卡上运行(虽然该模型一般需求显存10G以上),这些都让它一下带火了AI绘画,反而很多人可能并不了解这个模型背后的扩散模型的理论。不过从各方面考虑,在本次毕业设计选择该模型都是个不错的选择。
Stable Diffusion
Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。
官方网站:https://stability.ai/blog/stable-diffusion-public-release
不回答为什么进不去,或者打不开的问题
Stable Diffusion是一种机器学习模型,它经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如生成图像。
扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵。这会使进程变慢,并消耗大量内存。主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时。
Latent diffusion通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本。所以Stable Diffusion引入了Latent diffusion的方式来解决这一问题计算代价昂贵的问题。
Latent diffusion
自动编码器(VAE)
自动编码器(VAE)由两个主要部分组成:编码器和解码器。编码器将把图像转换成低维的潜在表示形式,该表示形式将作为下一个组件U_Net的输入。解码器将做相反的事情,它将把潜在的表示转换回图像。
在Latent diffusion训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。而在推理过程中,VAE解码器将把潜信号转换回图像。
U-Net
U-Net也包括编码器和解码器两部分,两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像,解码器将低分辨率解码回高分辨率图像。

为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样的ResNet和解码器的上采样ResNet之间添加了捷径的连接。
在Stable Diffusion的U-Net中添加了交叉注意层对文本嵌入的输出进行调节。交叉注意层被添加到U-Net的编码器和解码器ResNet块之间。
Text-Encoder
文本编码器将把输入文字提示转换为U-Net可以理解的嵌入空间,这是一个简单的基于transformer的编码器,它将标记序列映射到潜在文本嵌入序列。
Stable Diffusion的推理过程
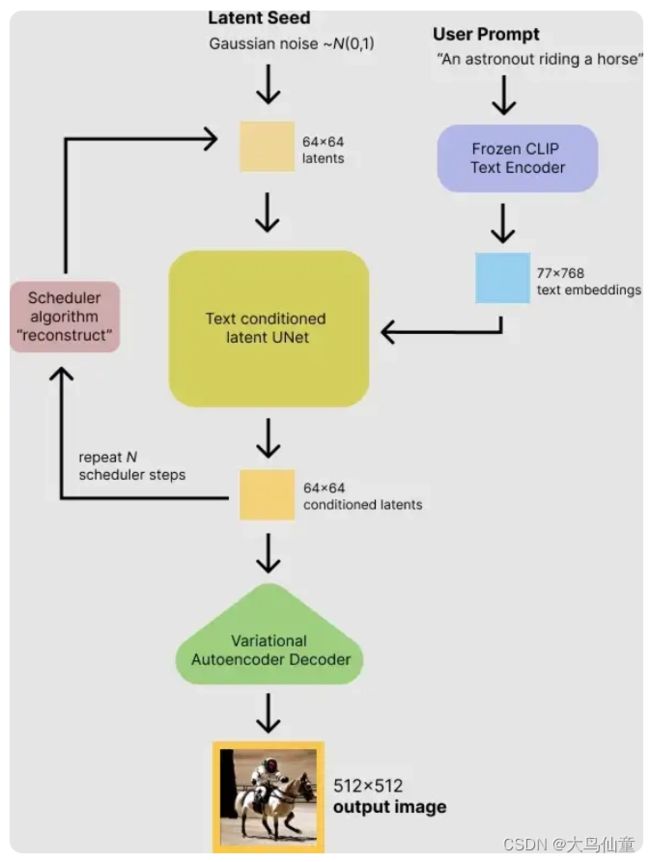
首先,模型将潜在空间的随机种子和文本提示同时作为输入。然后使用潜在空间的种子生成大小为64×64的随机潜在图像表示,通过CLIP的文本编码器将输入的文本提示转换为大小为77×768的文本嵌入。
然后,使用U-Net 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声的残差,用于通过scheduler 程序算法计算去噪的潜在图像表示。 scheduler 算法根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示。
许多不同的scheduler 算法可以用于这个计算,每一个都有它的优点和缺点。对于Stable Diffusion,建议使用以下其中之一:
PNDM scheduler (默认)
DDIM scheduler
K-LMS scheduler
去噪过程重复约50次,这样可以逐步检索更好的潜在图像表示。一旦完成,潜在图像表示就会由变分自编码器的解码器部分进行解码。
从零开始配置实验环境
因为这次用的是新组的机子,所以正好可以演示一下怎么从头开始配置各项环境到运行;为了方便大多数人的使用习惯,这里使用WIN而非Linux。
IDE
这部分可以自行安装,pycharm或者VScode都是不错的选择
Anaconda
什么是Anconda?Anaconda是开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。
官网:https://www.anaconda.com/
安装过程可以自行查找 这里不做赘述
需要注意的是,在安装过程中可以选择Add Anaconda3 to the system PATH选项,自动添加环境变量
如果选不了的话,也可以自己手动添加,过程很简单,具体可以自行百度
CUDA和CuDNN
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用GPU的处理能力,可大幅提升计算性能
CuDNN (NVIDIA CUDA 深度神经网络库) 是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。
全球的深度学习研究人员和框架开发者都依赖CuDNN 来实现高性能 GPU 加速。借助 CuDNN,研究人员和开发者可以专注于训练神经网络及开发软件应用,而不必花时间进行低层级的 GPU 性能调整。
CuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MxNet、PaddlePaddle、PyTorch 和 TensorFlow。我们接下来就需要用到Pytorch深度学习框架。
为了进行这一步,我们首先要确认你的电脑可以支持的最高CUDA版本和显存(虽然后者一般都知道)
在控制台输入代码 nvidia–smi
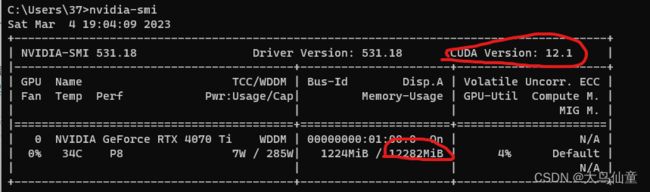
如上图所示,笔者的4070ti最高支持12.1的CUDA,并且有12G显存
英伟达CUDA官网:https://developer.nvidia.com/cuda-toolkit-archive
接下来要涉及CUDA版本的选择,自行去官网查看版本和驱动对应关系;
简单来说,驱动版本应该高于cuda需求版本
笔者这里以11.7为例

注意上面的选择

安装完成
CuDNN
英伟达CuDNN网站:https://developer.nvidia.com/rdp/cudnn-archive#a-collapse860-118
这里要提一句,CuDNN在官方的网站下载的话,是需要注册用户的。
如果嫌麻烦或者是网络原因的话,可以去第三方网站和论坛下载镜像资源,注意和CUDA的版本对应

注意不要下载成linux的

注意CuDNN是CUDA的补充库,所以不是安装包的形式,而是直接拖到CUDA路径覆盖的补丁安装形式
下面进行验证是否安装完成

打开如上图所示路径
打开CMD后,拖入 deviceQuery.exe 和 bandwidthTest.exe
如果出现下图中的Result = PASS 则证明安装完成


Stable Diffusion的本地部署
github地址:https://github.com/CompVis/stable-diffusion
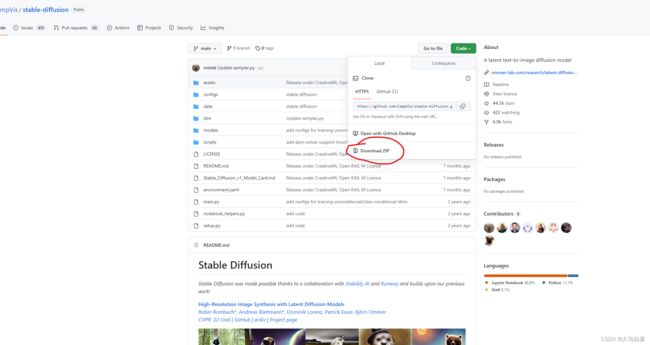
克隆到本地
接下来要安装对应环境,这里建议使用虚拟环境
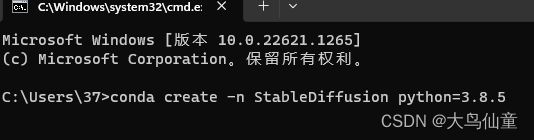
环境名可以自定义,python版本建议用官方环境的3.8.5
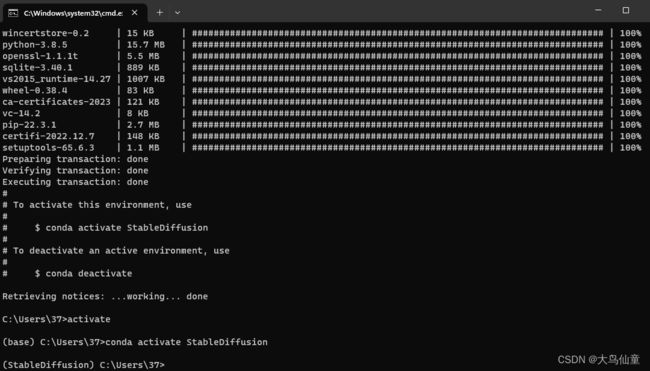
验证虚拟环境安装完成
打开克隆的代码仓,找到其中的环境需求单

这里一般存在两种安装方式
直接在控制台对该文件一键安装,和按照版本号分开单独安装。
这里的可以按照自己需求来操作,笔者选择后者。

numpy安装完毕
关于pytorch部分,可以直接命令行安装(高概率因为网络原因各种报错)
或者直接离线下载
https://download.pytorch.org/whl/torch_stable.html
但是需要自己去下面的官方网站查好版本号对应关系
https://github.com/pytorch/vision/blob/main/README.rst

在存放目录处点击红线旁空白区域,输入cmd(在指定目录打开控制台)

本地安装

安装完成

验证安装(忽视中间的拼写错误)
剩下的安装和numpy一样
也可以用如下语句一次性安装(大多不会出现网络或者版本错误)
pip install albumentations diffusers opencv-python pudb invisible-watermark imageio imageio-ffmpeg pytorch-lightning omegaconf test-tube streamlit einops torch-fidelity transformers torchmetrics kornia
接下来切换到代码目录
并把另外两个项目克隆到本地项目新建的src工作目录中
记得在在目录下打开控制台(上面有写)或者手动切换目录
同时还需要下载权重
https://link.csdn.net/?target=https%3A%2F%2Fhuggingface.co%2FCompVis
在项目目录models/ldm下手动创建stable-diffusion-v1文件夹,用来存放下载好的权重文件,即需要把下载文件夹里的sd-v1-4.ckpt文件改名为model.ckpt,然后粘贴到手动创建的stable-diffusion-v1文件夹下即可。
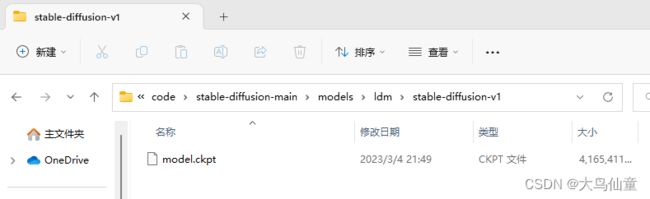
理论上到这里为止,所有的环境准备工作完毕
注:这里可能会遇到各种环境依赖的报错,是正常的;建议可以把报错的函数和接口名去Github仓查讨论区,600+的讨论基本上都有涉及到了。
https://github.com/CompVis/stable-diffusion/issues/162
这里贴一个我遇到问题找到的讨论
运行测试

生成samurai in the war的文字到图片模块
开始跑的时候随意截了一张图,可以看到效果还是可以的。
GPU也是直接吃满,意料之中就是了
注意:这里的demo是跑的text2img;本次毕业设计实际上还是会采用图片生成图片这种性能更好的模式!!!
总结
本周完成了扩散模型部分的内容实验,从搭建环境到随意跑个DEMO;现在整个毕业设计的各个零件已经完全准备好了,接下来需要做的事情就在于组合起来对比效果了
这里还是要吐槽一句,其实模型搭建部分遇到挺多问题的,官方给的依赖文档实际上不太行,得自己在Github的讨论区看洋兄弟是怎么解决这个问题的,还好模型热度大,什么稀奇古怪的报错都能找到同病相怜的兄弟。