eBPF 科普第一弹| 初识 eBPF,你应该知道的知识

“
eBPF 作为一颗在基础软件领域冉冉上升的新星,可谓前途大好,越来越多的基于 eBPF 的应用如雨后春笋般蓬勃涌现,这是 eBPF 展现出的惊人力量。本文就将带着大家了解 eBPF。
11月,「DaoCloud 道客」正式加入了 eBPF 基金会 ,是继 8 月 12 日创始成员 Facebook、Google、Isovalent、Microsoft 和 Netflix 之后,第一家正式获准加入的中国公司。

01
什么是 eBPF
与 eBPF 基金会?
简单来说,eBPF 是 Linux 内核中一个非常灵活与高效的类虚拟机 (virtual machine-like) 组件, 能够在许多内核 hook 点安全地执行字节码 (bytecode)。很多内核子系统都已经使用了 BPF,例如常见的网络、跟踪与安全。
eBPF 基金会 (https://ebpf.io) 是一个为 eBPF 技术而创建的非盈利性组织,隶属于 Linux 基金会,其意在推动 eBPF 更好地发展,使其得到更加广泛的运用。eBPF 基金会每年都会举办 eBPF 峰会,来自社会和各个企业的 eBPF 爱好、技术专家齐聚一堂,深度交流 eBPF 技术热点,分享创新成果。当前,eBPF 技术得到了企业的广泛应用。
eBPF 技术给云原生和现代化应用带来了一些全新的解决方案和巨大的技术红利,包括可观的性能提升、CPU 开销降低。「DaoCloud 道客」作为国内云原生平台的头部供应商,非常重视 eBPF 技术给 Linux 社区、kubernetes 社区带来的技术革命。
02
eBPF
如何变化演进?

此图展示在过去的 Linux 内核版本中,引入的几个 eBPF 代表性能力,截止 Linux5.14 内核版本,已经拥有了 32 种 eBPF 程序类型。
eBPF 的全称是 extended Berkeley Packet Filter,eBPF 技术的前身称为 BPF (Berkeley Packet Filter),或者 cBPF (classic BPF),在 1992 年 Steven McCanne 和 Van Jacobson 的一篇论文 《The BSD Packet Filter: A New Architecture for User-level Packet Capture》 中被第一次被提及。
最初的 Berkeley Packet Filter (BPF) 是为捕捉和过滤符合特定规则的网络包而设计的,过滤器为运行在基于寄存器的虚拟机上的程序。
在内核中运行用户指定的程序被证明是一种有用的设计,但最初 BPF 设计中的一些特性却并没有得到很好的支持。例如,虚拟机的指令集架构 (ISA) 相对落后,现在处理器已经使用 64 位的寄存器,并为多核系统引入了新的指令,如原子指令 XADD。BPF 提供的一小部分 RISC 指令已经无法在现有的处理器上使用。
因此 Alexei Starovoitov 在 eBPF 的设计中介绍了如何利用现代硬件,使 eBPF 虚拟机更接近当代处理器,eBPF 指令更接近硬件的 ISA,便于提升性能。其中最大的变动之一是使用了 64 位的寄存器,并将寄存器的数量从 2 提升到了 10 个。现代架构使用的寄存器远远大于 10 个,这样就可以像本机硬件一样将参数通过 eBPF 虚拟机寄存器传递给对应的函数。
03
eBPF
可以做什么?
一个 eBPF 程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的 eBPF 程序。鉴于它的起源,eBPF 特别适合编写网络程序,将该网络程序附加到网络 socket,进行流量过滤、流量分类以及执行网络分类器的动作。eBPF 程序甚至可以修改一个已建链的网络 socket 的配置。XDP 工程会在网络栈的底层运行 eBPF 程序,高性能地处理接收到的报文。从下图可以看到 eBPF 支持的功能:

eBPF 对调试内核和执行性能分析也具有很大的帮助,程序可以附加到跟踪点、kprobes 和 perf 事件。因为 eBPF 可以访问内核数据结构,开发者可以在不编译内核的前提下编写并测试代码。对于工作繁忙的工程师,通过该方式可以方便地调试一个在线运行的系统。此外,还可以通过静态定义的追踪点调试用户空间的程序 (即 BCC 调试用户程序,如 Mysql)。
使用 eBPF 可以发挥其两大优势:快速和安全。为了更好地使用 eBPF,最好是全方位了解它是如何工作的。
04
eBPF
如何进行工作?
eBPF 程序是在内核中被事件触发的。在一些特定的指令被执行时,这些事件会在 hook 处被捕获。Hook 被触发就会执行 eBPF 程序,对数据进行捕获和操作。接下来将系统介绍 eBPF 是如何工作的,你将了解到校验器流程、系统调用以及后续工作中所涉及到的程序类型、数据结构和辅助函数等内容。
内核的 eBPF 校验器
在内核中运行用户空间的代码可能会存在安全和稳定性风险。因此,在加载 eBPF 程序前需要进行大量校验。
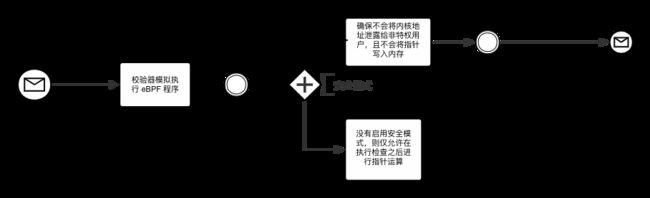
校验器流程图
首先通过对程序控制流的深度优先搜索保证 eBPF 能够正常结束,不会因为任何循环导致内核锁定。严禁使用无法到达的指令;任何包含无法到达的指令的程序都会导致加载失败。
第二个阶段涉及使用校验器模拟执行 eBPF 程序 (每次执行一个指令)。在每次指令执行前后都需要校验虚拟机的状态,保证寄存器和栈的状态都是有效的。严禁越界 (代码) 跳跃,以及访问越界数据。
校验器不会检查程序的每条路径,它能够知道程序的当前状态是否是已经检查过的程序的子集。由于前面的所有路径都必须是有效的 (否则程序会加载失败),当前的路径也必须是有效的,因此允许验证器“修剪”当前分支并跳过其模拟阶段。
校验器有一个 "安全模式",禁止指针运算。当一个没有 CAP_SYS_ADMIN 特权的用户加载 eBPF 程序时会启用安全模式,确保不会将内核地址泄露给非特权用户,且不会将指针写入内存。如果没有启用安全模式,则仅允许在执行检查之后进行指针运算。例如,所有的指针访问时都会检查类型,对齐和边界冲突。
无法读取包含未初始化内容的寄存器,尝试读取这类寄存器中的内容将导致加载失败。R0-R5 的寄存器内容在函数调用期间被标记未不可读状态,可以通过存储一个特殊值来测试任何对未初始化寄存器的读取行为;对于读取堆栈上的变量的行为也进行了类似的检查,确保没有指令会写入只读的帧指针寄存器。
最后,校验器会使用 eBPF 程序类型来限制可以从 eBPF 程序调用哪些内核函数,以及访问哪些数据结构。例如,一些程序类型可以直接访问网络报文。
bpf () 系统调用
使用 bpf() 系统调用和 BPF_PROG_LOAD 命令加载程序。该系统调用的原型为:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
BPF_PROG_LOAD 加载的命令可以用于创建和修改 eBPF maps,maps 是普通的 key/value 数据结构,用于在 eBPF 程序和内核空间或用户空间之间通信。其他命令允许将 eBPF 程序附加到一个控制组目录或 socket 文件描述符上,迭代所有的 maps 和程序,以及将 eBPF 对象固定到文件,这样在加载 eBPF 程序的进程结束后不会被销毁 (后者由 tc 分类器 / 操作代码使用,因此可以将 eBPF 程序持久化,而不需要加载的进程保持活动状态)。完整的命令可以参考 bpf() 帮助文档。
虽然可能存在很多不同的命令,但大体可以分为以下几类:与 eBPF 程序交互的命令、与 eBPF maps 交互的命令,或同时与程序和 maps 交互的命令(统称为对象)。
eBPF 程序类型的作用
使用 BPF_PROG_LOAD 加载的程序类型确定了四件事:
-
附加程序的位置;
-
验证器允许调用的内核辅助函数;
-
是否可以直接访问网络数据报文;
-
传递给程序的第一个参数对象的类型。
实际上,程序类型本质上定义了一个 API。创建新的程序类型甚至纯粹是为了区分不同的可调用函数列表 (例如,BPF_PROG_TYPE_CGROUP_SKB 和BPF_PROG_TYPE_SOCKET_FILTER)。
随着新程序类型的增加,内核开发人员也会发现需要添加新的数据结构。
eBPF 数据结构
eBPF 使用的主要的数据结构是 eBPF map,这是一个通用的数据结构,用于在内核或内核和用户空间传递数据。其名称 "map" 也意味着数据的存储和检索需要用到 key。
使用 bpf() 系统调用创建和管理 map。当成功创建一个 map 后,会返回与该 map 关联的文件描述符。关闭相应的文件描述符的同时会销毁 map。每个 map 定义了四个值:类型,元素最大数目,数值的字节大小,以及 key 的字节大小。eBPF 提供了不同的 map 类型,不同类型的 map 提供了不同的特性。
以下将会列举一下常见的类型:
BPF_MAP_TYPE_HASH : a hash table「哈希表」
BPF_MAP_TYPE_ARRAY : an array map, optimized for fast lookup speeds, often used for counters「数组映射,已针对快速查找速度进行优化,通常用于计数器」
BPF_MAP_TYPE_PROG_ARRAY : an array of file descriptors corresponding to eBPF programs; used to implement jump tables and sub-programs to handle specific packet protocols「对应 eBPF 程序的文件描述符数组;用于实现跳转表和子程序处理特定的数据包协议」
BPF_MAP_TYPE_PERCPU_ARRAY : a per-CPU array, used to implement histograms of latency「每个 CPU 的阵列,用于实现延迟的直方图」
BPF_MAP_TYPE_PERF_EVENT_ARRAY : stores pointers to struct perf_event, used to read and store perf event counters「存储指向 struct perf_event 的指针,用于读取和存储 perf 事件计数器」
BPF_MAP_TYPE_CGROUP_ARRAY : stores pointers to control groups「存储指向控制组的指针」
BPF_MAP_TYPE_PERCPU_HASH : a per-CPU hash table「每个 CPU 的哈希表」
BPF_MAP_TYPE_LRU_HASH : a hash table that only retains the most recently used items「仅保留最近使用项目的哈希表」
BPF_MAP_TYPE_LRU_PERCPU_HASH : a per-CPU hash table that only retains the most recently used items「每个 CPU 的哈希表,仅保留最近使用的项目」
BPF_MAP_TYPE_LPM_TRIE : a longest-prefix match trie, good for matching IP addresses to a range「最长前缀匹配数,适用于将 IP 地址匹配到某个范围」
BPF_MAP_TYPE_STACK_TRACE : stores stack traces「存储堆栈跟踪」
BPF_MAP_TYPE_ARRAY_OF_MAPS : a map-in-map data structure「map-in-map 数据结构」
BPF_MAP_TYPE_HASH_OF_MAPS : a map-in-map data structure「map-in-map 数据结构」
BPF_MAP_TYPE_DEVICE_MAP : for storing and looking up network device references「用于存储和查找网络设备引用」
BPF_MAP_TYPE_SOCKET_MA : stores and looks up sockets and allows socket redirection with BPF helper functions「存储和查找套接字,并允许使用 BPF 辅助函数进行套接字重定向」
所有的 map 都可以通过 eBPF 或在用户空间的程序中使用 bpf_map_lookup_elem() 和 bpf_map_update_elem() 函数进行访问。某些map类型,如 socket map,会使用其他执行特殊任务的 eBPF 辅助函数。
eBPF 的更多细节可以参见官方帮助文档
eBPF 辅助函数
eBPF 程序被触发时,会调用辅助函数。这些特别的函数让 eBPF 能够有访问内存的丰富功能。
可以参考官方帮助文档查看 libbpf 库提供的辅助函数。
官方文档给出了现有的 eBPF 辅助函数。更多的实例可以参见内核源码的 samples/bpf/ 和 tools/testing/selftests/bpf/ 目录。
05
eBPF
相关开源项目
使用了 eBPF 的开源项目有近百项,其中包括了如下一些耳熟能详的项目:
Cilium
kubernetes 平台上一个完全基于 eBPF 实现数据转发的 CNI 网络插件。
https://github.com/cilium/cilium
Bcc
提供了一个基于 python 的 eBPF 编程框架
https://github.com/iovisor/bcc
Bpftrace
提供了基于 eBPF 的 Linux 内核观测工具
https://github.com/iovisor/bpftrace
Falco
kubernetes 平台上的一个安全监控项目
https://github.com/falcosecurity/falco
Katran
一个实现四层负载均衡转发的项目
https://github.com/facebookincubator/katran
本文作为 eBPF 系列的第一篇科普,简单的介绍了 eBPF。eBPF 这项技术是无法简单地用言语来表达出它的魅力,只有切身体验后,才能明白这项技术的神奇。
eBPF 代表了操作系统和微服务交付的未来, 是「DaoCloud 道客」产品中重要的构成元素,「DaoCloud 道客」已把 eBPF技术融入了自己的网络转发、网络安全、安全观测、平台和应用监测等相关的产品和未来规划中,为打造开放的云原生操作系统夯实基础。「DaoCloud 道客」看好 eBPF 技术的未来发展,其将为云原生底层架构和现代化应用持续带来更多的技术红利。在加入 eBPF 基金会后,「DaoCloud 道客」将以新的身份,继续深度参与到 eBPF 的发展中来,为 eBPF 未来路线图的规划和愿景实现贡献更多力量。
原文出处:
https://lwn.net/Articles/740157/
The BSD Packet Filter: A New Architecture for User-level Packet Capture:
https://www.tcpdump.org/papers/bpf-usenix93.pdf
eBPF 的设计:
https://lwn.net/Articles/599755/
XDP 工程:
https://www.iovisor.org/technology/xdp
bpf() 帮助文档:
https://man7.org/linux/man-pages/man2/bpf.2.html
官方帮助文档:
https://man7.org/linux/man-pages/man2/bpf.2.html
当然您也可以加入我们的企业微信交流群和我们交流互动:
