Pytorch关于CIFAR-10测试
下载 CIFAR-10数据集:
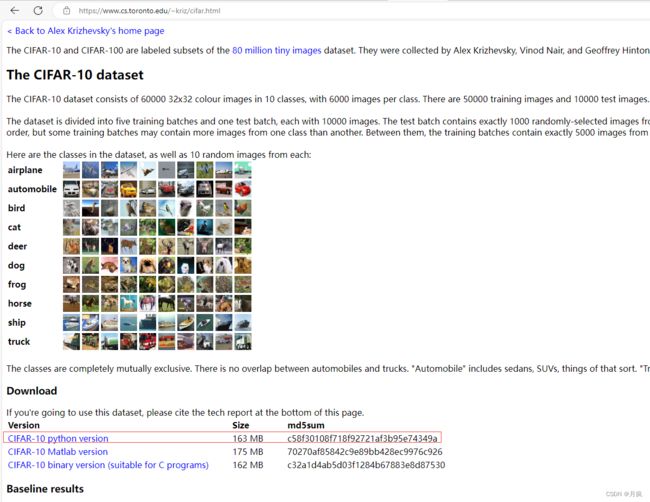
官网:https://www.cs.toronto.edu/~kriz/cifar.html
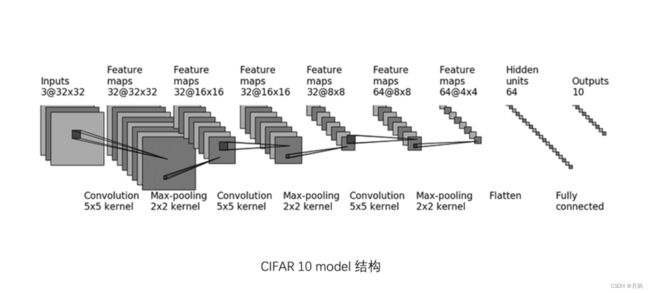
CIFAR-10的网络结构:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
#定义网络结构
class Model(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(3,32,5,stride=1,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
return x
model = Model()
print(model)
input = torch.ones((64,3,32,32))
print(input.shape)
output = model(input)
print(output.shape)
早起模型和现在比较:和上面的是等价的
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
#步长的计算方法:
# 例:一个尺寸 a*a 的特征图,经过 b*b 的卷积层,步幅(stride)=c,填充(padding)=d,请计算出输出的特征图尺寸?
# 特征图的尺寸=(a-b+2d)/c+1
#定义模型结构
class Model(nn.Module):
def __init__(self) -> None:
super().__init__() # 初始化父类属性
# self.conv1 = Conv2d(in_channels=3, out_channels=32,
# kernel_size=5, padding=2)
# self.maxpool1 = MaxPool2d(kernel_size=2)
# self.conv2 = Conv2d(in_channels=32,out_channels=32,
# kernel_size=5, padding=2)
# self.maxpool2 = MaxPool2d(kernel_size=2)
# self.conv3 = Conv2d(in_channels=32, out_channels=64,
# kernel_size=5, padding=2)
# self.maxpool3 = MaxPool2d(kernel_size=2)
# self.flatten = Flatten() # 展平为1维向量,torch.reshape()一样效果
# # 若是想检验1024是否正确,可以先写前面的层,看样例的输出大小,即可得到1024
# self.linear1 = Linear(in_features=1024, out_features=64)
# self.linear2 = Linear(in_features=64, out_features=10)
# sequential可以替代前面备注掉的代码段
self.model1 = Sequential(
Conv2d(3, 32, 5, stride=1, padding=2), #输入3张图片,也就是三通道,生成32张,卷积核5*5,不常是1,padding是2
MaxPool2d(2), #对输出进行池化2*2
Conv2d(32, 32, 5, padding=2), #输入32张,输出32张,卷积核是5*5,padding是2
MaxPool2d(2), #池化2*2
Conv2d(32, 64, 5, padding=2), #输入是32,输出是64,卷积核是5*5,padding是5*5
MaxPool2d(2), #池化2*2
Flatten(), #扁平化
Linear(1024, 64), #全连接输入1024,输出64
Linear(64, 10) #输入64,输出10(表示10个分类)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
#代替以上代码段
x = self.model1(x) #将x传入模型,进行前向网络
return x
model = Model() # 创建一个实例
print(model) # 打印模型结构
# 测试模型样例(也可以测试各层的输出是否正确)
input = torch.ones((64, 3, 32, 32)) #输入64张图片,3通道,32*32
print(input.shape) # torch.Size([64, 3, 32, 32])
output = model(input) #模型的输出
print(output.shape) # torch.Size([64, 10]),batch_size=64,10个参数
writer = SummaryWriter("./logs_seq") # 创建一个实例
writer.add_graph(model, input) # 显示模型结构
writer.close()
# tensorboard命令:tensorboard --logdir=logs_seq --port=6007
'''
torch.nn.functional.conv2d 和 torch.nn.Conv2d的区别?
nn.Conv2d是一个类,而F.conv2d()是一个函数,而nn.Conv2d的forward()函数实现是用F.conv2d()实现的(在Module类里的__call__实现了forward()函数的调用,所以当实例化nn.Conv2d类时,forward()函数也被执行了,详细可阅读torch源码),所以两者功能并无区别,那么为什么要有这样的两种实现方式同时存在呢?
原因其实在于,为了兼顾灵活性和便利性。
在建图过程中,往往有两种层,一种如全连接层,卷积层等,当中有Variable,另一种如Pooling层,Relu层等,当中没有Variable。
如果所有的层都用nn.functional来定义,那么所有的Variable,如weights,bias等,都需要用户来手动定义,非常不方便。
而如果所有的层都换成nn来定义,那么即便是简单的计算都需要建类来做,而这些可以用更为简单的函数来代替的。
所以在定义网络的时候,如果层内有Variable,那么用nn定义,反之,则用nn.functional定义。
'''
本地加载数据:
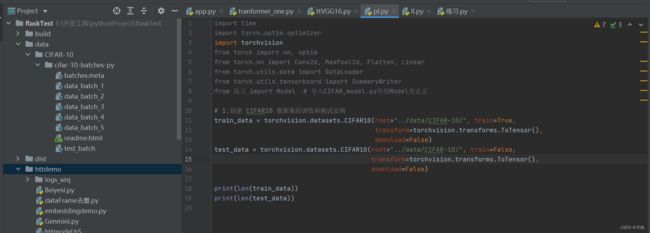

CPU下训练:
import time
import torch.optim.optimizer
import torchvision
from torch import nn, optim
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from 练习 import Model # 导入CIFAR_model.py里的Model类定义
# 1.创建 CIFAR10 数据集的训练和测试实例
#实现本地加载
train_data = torchvision.datasets.CIFAR10(root="../data/CIFAR-10/", train=True,
transform=torchvision.transforms.ToTensor(),
download=False)
test_data = torchvision.datasets.CIFAR10(root="../data/CIFAR-10/", train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
# 2.利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 3.搭建神经网络:CIFAR-10
model = Model() # 创建实例
# 4.损失函数
loss = nn.CrossEntropyLoss()
# 5.优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), learning_rate)
# 6.设置训练网络的一些参数
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 10 # 训练的轮数
for i in range(epoch):
print(f"--------第{i}轮训练开始--------")
# 训练步骤开始
model.train() # 模型进入训练模式
for data in train_dataloader: #获取图片和对应的标签
imgs, targets = data
outputs = model(imgs) #模型输入图片
result_loss = loss(outputs, targets) # 计算每个参数对应的损失
# 优化器优化模型
optimizer.zero_grad() # 每个参数对应的梯度清零
result_loss.backward() # 反向传播,计算每个参数对应的梯度
optimizer.step() # 每个参数根据上一步得到的梯度进行优化
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time() # 结束时间
print(f"训练次数:{total_train_step},Loss:{result_loss.item()}")
# 测试步骤开始(每轮训练好、但不进行优化的模型)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
total_test_loss = 0 #计算总的梯度损失
total_accuracy = 0 #将准确度加起来,计算平均准确度
with torch.no_grad(): # 不需要计算梯度,直接将数据放入网络进行测试
for data in test_dataloader:
imgs, targets = data
outputs = model(imgs)
result_loss = loss(outputs, targets)
total_test_loss += result_loss # 损失累加
# 计算标签正确数(取得在 1 方向,概率最大的索引,即得标签输出值;对比标签输出值与目标值+求和:True=1,False=0)
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的正确率:{total_accuracy / len(test_data)}")
total_test_step += 1
torch.save(model, f"CIFAR_model_{i}.pth")
print("模型已保存!")
添加GPU测试:
GPU版本a:网络模型、数据(输入、标签)、损失函数添加 .cuda()。
搭建神经网络:CIFAR-10模型
model = Model() # 创建实例
if torch.cuda.is_available(): # GPU是否可用
print("使用GPU训练")
model = model.cuda() # GPU(非必须重赋值)
# model.cuda() # 与上一句效果一样,不用重赋值
损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available(): # GPU是否可用
loss_fn = loss_fn.cuda() # GPU(非必须重赋值)
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # GPU是否可用
imgs = imgs.cuda() # GPU(必须重赋值)
targets = targets.cuda() # GPU(必须重赋值)
outputs = model(imgs)
with torch.no_grad(): # 不进行优化的
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available(): # GPU是否可用
imgs = imgs.cuda() # GPU(必须重赋值)
targets = targets.cuda() # GPU(必须重赋值)
outputs = model(imgs)
GPU版本b:网络模型、数据(输入、标签)、损失函数添加.to(device)。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 定义训练的设备GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # ”cuda:0“ 等效 ”cuda“
print(device)
搭建神经网络:CIFAR-10模型
model = Model() # 创建实例
model = model.to(device) # GPU(非必须重赋值)
# model.to(device) # 与上一句效果一样,不用重赋值
损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) # GPU(非必须重赋值)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device) # GPU
targets = targets.to(device) # GPU
outputs = model(imgs)
with torch.no_grad(): # 不进行优化的
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device) # GPU
targets = targets.to(device) # GPU
outputs = model(imgs)
加载模型进行预测结果:
import torch
import torchvision
from PIL import Image
from CIFAR_model import Model # 导入CIFAR_model.py里的Model类定义
image_path = "./boss.png"
image = Image.open(image_path) # 加载3通道的图片数据,3阶张量
print(image) #
# 将图片 Resize(缩放) 到32x32尺寸,适合模型输入,最后在转化为Tensor实例
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
# 转化为4阶张量(模型网络的输入要求张量的阶数为4)
image = torch.reshape(image, (1, 3, 32, 32))
print(image.shape) # torch.Size([1, 3, 32, 32])
# -----------------1.测试方式a(常用,CPU上测试)-----------------
print("\nCPU上测试:")
# 加载训练好的模型
# 采用GPU训练的模型,要想在CPU上测试,必须映射到CPU上(或者模型不用映射到CPU上,而图片映射到GPU上)
model = torch.load("CIFAR_model_9.pth", map_location=torch.device("cpu"))
# print(model)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
with torch.no_grad(): # 有利于节约内存和性能
output = model(image)
print(output)
print(output.argmax(1)) # 方向1最大值的索引值
# -----------------2.测试方式b(GPU上测试)-----------------
print("\nGPU上测试:")
# 加载训练好的模型
model = torch.load("CIFAR_model_9.pth")
# print(model)
model.eval() # 模型进入测试模式(仅针对有Dropout,BatchNorm层的网络结构)
with torch.no_grad(): # 有利于节约内存和性能
# 将图片放到GPU上运行(采用GPU训练的模型,图片应该放到GPU上)
output = model(image.cuda())
# output = model(image.to("cuda:0")) # 等效于上一句
print(output)
print(output.argmax(1)) # 方向1最大值的索引值