机器学习入门--LSTM原理与实践
LSTM模型
长短期记忆网络(Long Short-Term Memory,LSTM)是一种常用的循环神经网络(RNN)变体,特别擅长处理长序列数据和捕捉长期依赖关系。本文将介绍LSTM模型的数学原理、代码实现和实验结果,并使用pytorch和sklearn的数据集进行验证。
数学原理
遗忘门(Forget Gate)
遗忘门的作用是决定前一时间步的细胞状态中哪些信息需要被遗忘。具体计算公式为:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
其中, W f W_f Wf表示遗忘门权重矩阵, h t − 1 h_{t-1} ht−1表示前一时间步的隐藏状态, x t x_t xt是当前时间步的输入, b f b_f bf是遗忘门的偏置向量, σ \sigma σ表示sigmoid函数。
输入门 (Input Gate)
输入门的作用是决定当前时间步的输入中哪些信息将被加入到细胞状态中。具体计算公式为:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
其中, W i W_i Wi 表示输入门的权重矩阵, h t − 1 h_{t-1} ht−1表示前一时间步的隐藏状态, x t x_t xt表示当前时间步的输入, b i b_i bi是输入门的偏置向量, σ \sigma σ是sigmoid函数。
更新单元 (Candidate Cell State)
更新单元计算出一个候选的单元状态,用于更新当前时间步的单元状态。具体计算公式为:
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_{t} = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
其中, W C W_C WC是更新单元的权重矩阵, h t − 1 h_{t-1} ht−1是前一时间步的隐藏状态, x t x_t xt表示当前时间步输入, b C b_C bC是更新单元偏置向量。
细胞状态更新(Cell State Update)
通过遗忘门、输入门和更新单元的计算结果,可以更新当前时间步的细胞状态。具体计算公式为:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t = f_t * C_{t-1} + i_t * \tilde{C}_t Ct=ft∗Ct−1+it∗C~t
其中, f t f_t ft是遗忘门的输出, C t − 1 C_{t-1} Ct−1是前一时间步的单元状态, i t i_t it是输入门的输出, C ~ t \tilde{C}_t C~t是更新单元的输出。
输出门(Output Gate)
输出门的作用是决定当前时间步的隐藏状态。具体计算公式为:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
其中, W o W_o Wo是输出门的权重矩阵, h t − 1 h_{t-1} ht−1是前一时间步的隐藏状态, x t x_t xt 表示当前时间步输入, b o b_o bo 是输出门偏置向量。
隐藏状态更新(Hidden State Update)
通过输出门和细胞状态计算出当前时间步的隐藏状态。具体计算公式为:
h t = o t ∗ tanh ( C t ) h_t = o_t * \tanh(C_t) ht=ot∗tanh(Ct)
其中, o t o_t ot是输出门的输出, C t C_t Ct代表当前时间步的单元状态。
代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 加载数据集并进行标准化
data = load_boston()
X = data.data
y = data.target
scaler = StandardScaler()
X = scaler.fit_transform(X)
y = y.reshape(-1, 1)
# 转换为张量
X = torch.tensor(X, dtype=torch.float32).unsqueeze(1)
y = torch.tensor(y, dtype=torch.float32)
# 定义LSTM模型
class LSTMNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMNet, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
input_size = X.shape[2]
hidden_size = 32
output_size = 1
model = LSTMNet(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10000
loss_list = []
for epoch in range(num_epochs):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
loss_list.append(loss.item())
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 可视化损失曲线
plt.plot(range(100), loss_list)
plt.xlabel('num_epochs')
plt.ylabel('loss of LSTM Training')
plt.show()
# 预测新数据
new_data_point = X[0].reshape(1, 1, -1)
prediction = model(new_data_point)
print(f'Predicted value: {prediction.item()}')
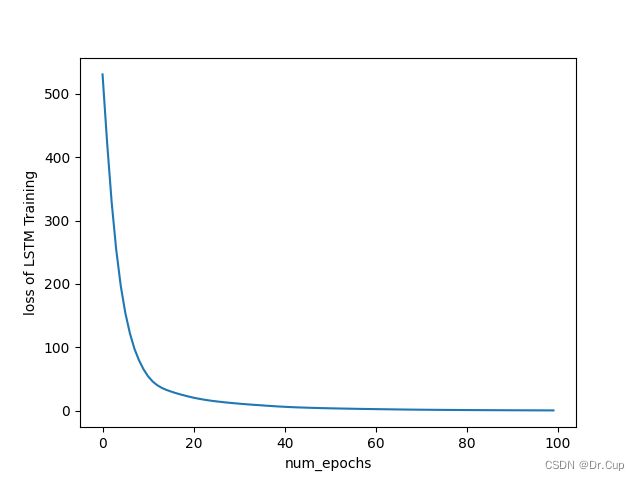
上述代码中,我们首先加载并标准化波士顿房价数据集,然后定义了一个包含LSTM层和全连接层的LSTMNet模型。通过使用均方误差作为损失函数和Adam优化器进行训练,我们展示了如何训练和预测LSTM模型。最后,通过matplotlib库绘制了损失曲线(如下图所示),并对新数据点进行了预测。
总结
LSTM作为一种强大的循环神经网络模型,在处理长序列数据和捕捉长期依赖关系方面表现出色。通过本文的介绍和实验,我们深入探讨了LSTM的数学原理、代码实现和应用实例。通过使用pytorch和sklearn的数据集进行实验,我们验证了LSTM模型在房价预测任务中的有效性和性能优势。希望本文能帮助读者更好地理解和应用LSTM模型。