go redis
go redis
快速入门
安装:
go get github.com/redis/go-redis/v9
然后创建客户端:
package main
import "github.com/redis/go-redis/v9"
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "47.109.87.142:6379",
Password: "wb12345678", // no password set
DB: 0, // use default DB
})
}
新建了一个redis客户端,然后这个结构体包含了连接到目标redis服务器的配置。
Addr就是要连接的服务器地址
Password就是密码
DB: 0:指定要连接的 Redis 数据库的编号。Redis 支持多个数据库,编号从 0 开始。在这个例子中,使用的是默认数据库 0。
入门案例
package main
import (
"context"
"fmt"
"github.com/redis/go-redis/v9"
)
var rdb *redis.Client
func init() {
rdb = redis.NewClient(&redis.Options{
Addr: "47.109.87.142:6379",
Password: "wb12345678", // no password set
DB: 0, // use default DB
})
}
func main() {
ctx := context.Background()
err := rdb.Set(ctx, "goredistestkey", "goredistestvalue", 0).Err()
if err != nil {
panic(err)
}
value, err1 := rdb.Get(ctx, "goredistestkey").Result()
if err1 != nil {
panic(err1)
}
fmt.Println(value)
result, err := rdb.Do(ctx, "get", "goredistestkey").Result()
if err != nil {
panic(err)
}
fmt.Println("do:", result.(string))
}
我在这里面的难点主要就是context。
context 提供了一种控制并发操作的方式。当多个 Goroutine 协同工作时,context 可以用来发送取消信号(当某个操作被取消时)或者设置最大执行时间(超时)。在这个案例中,context 被用来传递给 Redis 操作,以便在需要时控制这些操作。
context.Background() 创建了一个空的 context,它不包含任何数据,也没有取消信号或截止时间。它通常用于初始化,或者在你不需要使用特定 context 特性时。
就是说如果设置了一个带超时作用的context,在操作redis时,会进行超时处理。
这里我也举一个带超时处理的例子:
package main
import (
"context"
"fmt"
"time"
"github.com/redis/go-redis/v9"
)
func main() {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
// 创建一个带有超时的 context
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel() // 确保在操作完成后取消 context
// 使用带超时的 context 执行 SET 命令
err := rdb.Set(ctx, "key", "value", 0).Err()
if err != nil {
fmt.Println("Error:", err)
return
}
// 使用同一个 context 执行 GET 命令
value, err := rdb.Get(ctx, "key").Result()
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println("Value:", value)
}
这里就创建了一个超时处理的上下文。如果Set或Get操作在这5秒内没完成,那么操作就会被取消。还有关于这个context,超时后会自动取消。
总的来说这个上下文的作用非常的好。
还有rdb.Do,这个方法非常的好,这直接就是操作redis的命令,写了自动会进行拼接,你可以理解逗号就是空格。
还有一个问题,关于调用的函数的返回值
rdb.Set() 的返回值类型:func (c *Client) Set(ctx context.Context, key string, value interface{}, expiration time.Duration) StatusCmd
返回值StatusCmd 类型,这是一个指向 StatusCmd 结构的指针,其中包含了操作的结果。StatusCmd 是 go-redis 库定义的一个类型,用于表示没有直接返回值的 Redis 命令的执行状态(如 SET 命令)。
如何处理:
通常会调用 Err() 方法来检查命令是否执行成功。Err() 方法返回一个 error 类型,如果操作成功完成,则返回 nil;否则,返回错误信息。
err := rdb.Set(ctx, "key", "value", 0).Err()
if err != nil {
panic(err)
}
rdb.Get() 的返回值类型
rdb.Get() 方法用于从 Redis 中获取一个键的值。它的原型大致如下:
func (c *Client) Get(ctx context.Context, key string) *StringCmd
返回值:*StringCmd 类型。这是一个指向 StringCmd 结构的指针,其中包含了操作的结果。StringCmd 是 go-redis 库定义的一个类型,用于表示返回字符串结果的 Redis 命令的执行状态(如 GET 命令)。
如何处理:你可以调用 Result() 方法来获取命令的执行结果和可能出现的错误。Result() 方法返回两个值:一个字符串和一个 error。如果操作成功,字符串变量将包含键的值,而 error 变量将是 nil;如果操作失败(如键不存在),error 变量将包含错误信息。
这里可以总结一下,有结果的一般处理都是用result,没有结果的,一般处理都是用Err()
value, err := rdb.Get(ctx, "key").Result()
if err != nil {
panic(err)
}
fmt.Println("Value:", value)
数据类型
接下来的学习就是对这些数据类型怎么来操作。快速过一下
其实我个人觉得你观察这些方法,这个和redis里面的命令可以说一模一样。把这些方法过一下就懂了。
String类型
1.Set
err := rdb.Set(ctx, "gorediskey", "goredisvalue", 0).Err()
if err != nil {
panic(err)
}
2.get
value, err := rdb.Get(ctx, "gorediskey").Result()
if err != nil {
panic(err)
}
fmt.Println("gorediskey", value)
3.GetSet
设置一个key的值,并返回这个key的旧值
oldVal, err := rdb.GetSet(ctx, "gorediskey", "new value").Result()
if err != nil {
panic(err)
}
// 打印key的旧值
fmt.Println("key", oldVal)
4.SetNX
如果key不存在,则设置这个key的值
如果key存在就不会设置。
err := rdb.SetNX(ctx, "key1", "value", 0).Err()
if err != nil {
panic(err)
}
5批量查询key的值
vals, err := rdb.MGet(ctx, "key1", "key2", "key3").Result()
if err != nil {
panic(err)
}
fmt.Println(vals)
看代码就是查询多个key
会以列表的形式返回value1,value2,value3.
6. MSet
批量设置key的值
err := rdb.MSet(ctx, "key1", "value1", "key2", "value2", "key3", "value3").Err()
if err != nil {
panic(err)
}
代码也很明显,就是实现多设置。
7.Incr,IncrBy
针对一个key的数值进行递增操作
// 每次调用那指定的key的value就会+1
val, err := rdb.Incr(ctx, "key").Result()
if err != nil {
panic(err)
}
fmt.Println("最新值", val)
// IncrBy函数,可以指定每次递增多少
valBy, err := rdb.IncrBy(ctx, "key", 2).Result()
if err != nil {
panic(err)
}
fmt.Println("最新值", valBy)
// IncrByFloat函数,可以指定每次递增多少,跟IncrBy的区别是累加的是浮点数
valFloat, err := rdb.IncrByFloat(ctx, "key1", 2.2).Result()
if err != nil {
panic(err)
}
fmt.Println("最新值", valFloat)
有个注意点,如果本身这个键就不存在,那么会默认创建,赋默认值为0。
显然这个代码可以看到是有执行结果的。所以返回.Result()。
8.Decr,DecrBy
同理有自增就会有自减。
和上面一样如果本身这个键就不存在,那么会默认创建,赋默认值为0。那么这里自减之后就是变-1.
// Decr函数每次减一
val, err := rdb.Decr(ctx, "key").Result()
if err != nil {
panic(err)
}
fmt.Println("最新值", val)
// DecrBy函数,可以指定每次递减多少
valBy, err := rdb.DecrBy(ctx, "key", 2).Result()
if err != nil {
panic(err)
}
fmt.Println("最新值", valBy)
9. Del
删除key操作,支持批量删除
// 删除key
rdb.Del(ctx, "key")
// 删除多个key, Del函数支持删除多个key
err := rdb.Del(ctx, "key1", "key2", "key3").Err()
if err != nil {
panic(err)
}
10. Expire
rdb.Expire(ctx, "key", 3*time.Second)
过期了这个键就没了
也可以这样实现过期时间
rdb.Set(ctx,“key”,“value”,时间)
0就是永久。
HSET
我个人感觉学这个不要和redis命令割裂开,仔细看其实就是redis命令。
关于hash的操作都是H开头
1. HSet
根据key和field字段设置,field字段的值
// user_1 是hash key,username 是字段名, zhangsan是字段值
err := rdb.HSet(ctx,"user_1", "username", "zhangsan").Err()
if err != nil {
panic(err)
}
这个hash key说白了就是hash表的名字。后面那俩一个key一个value。
这个结合redis命令就是表名,然后key,然后对应的value。
2.HGet
根据key和field字段,查询field字段的值
// user_1 是hash key,username是字段名
username, err := rdb.HGet(ctx,"user_1", "username").Result()
if err != nil {
panic(err)
}
fmt.Println(username)
这个想想redis命令那也是非常清楚。通过key拿value。
3.HGetAll
根据key查询所有字段和值
// 一次性返回key=user_1的所有hash字段和值
data, err := rdb.HGetAll(ctx,"user_1").Result()
if err != nil {
panic(err)
}
// data是一个map类型,这里使用使用循环迭代输出
for field, val := range data {
fmt.Println(field,val)
}
注意返回值是data,data是map,所以这里可以循环迭代进行输出结果。
4. HIncrBy
根据key和field字段,累加字段的数值。
说白了就是自增
// 累加count字段的值,一次性累加2, user_1为hash key
count, err := rdb.HIncrBy(ctx,"user_1", "count", 2).Result()
if err != nil {
panic(err)
}
fmt.Println(count)
可以看出这个和redis命令还是十分的类似。
5. HKeys
根据key返回所有字段名
// keys是一个string数组
keys, err := rdb.HKeys(ctx,"user_1").Result()
if err != nil {
panic(err)
}
fmt.Println(keys)
说白了就是返回所有的key。结果用一个string数组装起来。
6. HLen
根据key,查询hash的字段数量
size, err := rdb.HLen(ctx,"user_1").Result()
if err != nil {
panic(err)
}
fmt.Println(size)
就是查有多少个key。
7.HMGet
根据key和多个字段名,批量查询多个hash字段值
// HMGet支持多个field字段名,意思是一次返回多个字段值
vals, err := rdb.HMGet(ctx,"user_1","username", "count").Result()
if err != nil {
panic(err)
}
// vals是一个数组
fmt.Println(vals)
就是查多个key的value。结果用一个数组装起来。就不用一个一个的查。
相当于批量查询
8. HMSet
根据key和多个字段名和字段值,批量设置hash字段值
// 初始化hash数据的多个字段值
data := make(map[string]interface{})
data["id"] = 1
data["username"] = "lisi"
// 一次性保存多个hash字段值
err := rdb.HMSet(ctx,"key", data).Err()
if err != nil {
panic(err)
}
这里就显得稍微灵活了很多,直接先用一个map设置好了之后再给他传进去映射修改。
9. HSetNX
如果field字段不存在,则设置hash字段值
这个就是如果不存在那就设置一个。
如果存在了那么设置就会不成功。
err := rdb.HSetNX(ctx,"key", "id", 100).Err()
if err != nil {
panic(err)
}
10. HDel
根据key和字段名,删除hash字段,支持批量删除hash字段
// 删除一个字段id
rdb.HDel(ctx,"key", "id")
// 删除多个字段
rdb.HDel(ctx,"key", "id", "username")
11. HExists
检测hash字段名是否存在
// 检测id字段是否存在
exist,err := rdb.HExists(ctx,"key", "id").Result()
if err != nil {
panic(err)
}
fmt.Println(exist)
LIST
关于列表的操作都是L开头
1. LPush
从列表左边插入数据
// 插入一个数据
rdb.LPush(ctx,"key", "data1")
// LPush支持一次插入任意个数据
err := rdb.LPush(ctx,"key", 1,2,3,4,5).Err()
if err != nil {
panic(err)
}
如果本身没有key这个列表,也是会自动创建
2. LPushX
跟LPush的区别是,仅当列表存在的时候才插入数据,用法完全一样。
err := rdb.LPushX(ctx, "key", "sss").Err()
if err != nil {
panic(err)
}
3. RPop
从列表的右边删除第一个数据,并返回删除的数据
val, err := rdb.RPop(ctx,"key").Result()
if err != nil {
panic(err)
}
fmt.Println(val)
4. RPush
从列表右边插入数据
// 插入一个数据
rdb.RPush(ctx,"key", "data1")
// 支持一次插入任意个数据
err := rdb.RPush(ctx,"key", 1,2,3,4,5).Err()
if err != nil {
panic(err)
}
5. RPushX
和L的没区别
err := rdb.RPushX(ctx,"key", "right_x").Err()
if err != nil {
panic(err)
}
6. LPop
从列表左边删除第一个数据,并返回删除的数据
val, err := rdb.LPop(ctx,"key").Result()
if err != nil {
panic(err)
}
fmt.Println(val)
7. LLen
返回列表的大小
val, err := rdb.LLen(ctx,"key").Result()
if err != nil {
panic(err)
}
fmt.Println(val)
8. LRange
返回列表的一个范围内的数据,也可以返回全部数据,LRANGE是前闭后闭的。
// 返回从0开始到-1位置之间的数据,意思就是返回全部数据
vals, err := rdb.LRange(ctx,"key",0,-1).Result()
if err != nil {
panic(err)
}
fmt.Println(vals)
9. LRem
删除列表中的数据
这里面介绍了几种删除方法。
// 从列表左边开始,删除100, 如果出现重复元素,仅删除1次,也就是删除第一个
dels, err := rdb.LRem(ctx,"key",1,100).Result()
if err != nil {
panic(err)
}
// 如果存在多个100,则从列表左边开始删除2个100
rdb.LRem(ctx,"key",2,100)
// 如果存在多个100,则从列表右边开始删除2个100
// 第二个参数负数表示从右边开始删除几个等于100的元素
rdb.LRem(ctx,"key",-2,100)
// 如果存在多个100,第二个参数为0,表示删除所有元素等于100的数据
rdb.LRem(ctx,"key",0,100)
总结:第三个参数是正的就是从左边开始删除。如果是负的就是从右边开始删除
第四个参数是你要删的value值。
第二个参数就是列表名。
如果列表中不存在你要删除的元素,那么会返回0,表示没有元素被删除,并不会报错。
如果你删除2个,但是实际上只有一个,那么也是只会删除1个。并不会发生报错。
10. LIndex
根据索引坐标,查询列表中的数据
// 列表索引从0开始计算,这里返回第6个元素
val, err := rdb.LIndex(ctx,"key",5).Result()
if err != nil {
panic(err)
}
fmt.Println(val)
11. LInsert
在指定值的前后插入数据
// 在列表中5的前面插入4
// before是之前的意思
err := rdb.LInsert(ctx,"key","before", 5, 4).Err()
if err != nil {
panic(err)
}
// 在列表中 zhangsan 元素的前面插入 欢迎你
rdb.LInsert(ctx,"key","before", "zhangsan", "欢迎你")
// 在列表中 zhangsan 元素的后面插入 2022
rdb.LInsert(ctx,"key","after", "zhangsan", "2022")
总结:这是基于元素值进行插入,好处就是还可以指定在前后插入,但是坏处是这个方法显然有一些弊端,在对于列表中有重复元素的情况下,它会默认匹配遇到的第一个元素,然后在这个元素进行操作。比如1,1。如果你想操作后面这个1,那么这个方法就没用。如果要实现这个,那么没用现成的函数,只能通过程序逻辑进行处理。
SET 集合
做这些操作之前首先你要了解集合的性质。
关于集合的操作都是S开头
1. SAdd
添加集合元素
// 添加100到集合中
err := rdb.SAdd(ctx,"key",100).Err()
if err != nil {
panic(err)
}
// 将100,200,300添加到集合中
rdb.SAdd(ctx,"key",100, 200, 300)
你可以一次加一个,也可以一次加多个
注意:千万别以为集合中元素是什么100,200,300或者300,200,100,对于集合来说是无序的,顺序确定不了
就算你添加了重复的元素,那也会进行自动的去重操作。
2. SCard
获取集合元素个数
size, err := rdb.SCard(ctx,"key").Result()
if err != nil {
panic(err)
}
fmt.Println(size)
3. SIsMember
判断元素是否在集合中
// 检测100是否包含在集合中
ok, _ := rdb.SIsMember(ctx,"key", 100).Result()
if ok {
fmt.Println("集合包含指定元素")
}
4.SMembers
获取集合中所有的元素
es, _ := rdb.SMembers(ctx,"key").Result()
// 返回的es是string数组
fmt.Println(es)
- SRem
删除集合元素
// 删除集合中的元素100
rdb.SRem(ctx, "key", 100)
// 删除集合中的元素200和300
rdb.SRem(ctx, "key", 200, 300)
可以单个删,也可以批量删。
6. SPop,SPopN
随机返回集合中的元素(因为无序性),并且删除返回的元素
// 随机返回集合中的一个元素,并且删除这个元素
val, _ := rdb.SPop(ctx,"key").Result()
fmt.Println(val)
// 随机返回集合中的5个元素,并且删除这些元素
vals, _ := rdb.SPopN(ctx,"key", 5).Result()
fmt.Println(vals)
sorted set 有序集合也叫ZSET
一定先掌握有序集合有什么性质。
有序集合的每个元素都会关联一个浮点类型的分数。然后按照这个分数来对集合中的元素进行从小到大排序。有序集合的成员是唯一的,但是分数是可以重复的。当多个成员有相同的分数时,它们会根据成员的二进制顺序进行排序,这是一个字典序。
所有的操作都是N开头的。
1. ZAdd
添加一个或者多个元素到集合,如果元素已经存在则更新分数
// 添加一个集合元素到集合中, 这个元素的分数是2.5,元素名是zhangsan
err := rdb.ZAdd(ctx, "key", &redis.Z{Score: 2.5, Member: "zhangsan"}).Err()
if err != nil {
panic(err)
}
注意看添加是按结构体添加redis.Z,然后里面有两个成员,一个就是score,一个就是key,是按这样的方式来进行添加。
2. ZCard
返回集合元素个数
size, err := rdb.ZCard(ctx,"key").Result()
if err != nil {
panic(err)
}
fmt.Println(size)
3. ZCount
统计某个分数范围内的元素个数
注意里面的参数都是分数范围,然后用的字符串表示
// 返回: 1<=分数<=5 的元素个数, 注意:"1", "5"两个参数是字符串
size, err := rdb.ZCount(ctx,"key", "1","5").Result()
if err != nil {
panic(err)
}
fmt.Println(size)
// 返回: 1<分数<=5 的元素个数
// 说明:默认第二,第三个参数是大于等于和小于等于的关系。
// 如果加上( 则表示大于或者小于,相当于去掉了等于关系。
size, err := rdb.ZCount(ctx,"key", "(1","5").Result()
4. ZIncrBy
增加元素的分数
// 给元素zhangsan,加上2分
rdb.ZIncrBy(ctx,"key", 2,"zhangsan")
5. ZRange,ZRevRange
返回集合中某个索引范围的元素,根据分数从小到大排序
// 返回从0到-1位置的集合元素, 元素按分数从小到大排序
// 0到-1代表则返回全部数据
vals, err := rdb.ZRange(ctx,"key", 0,-1).Result()
if err != nil {
panic(err)
}
for _, val := range vals {
fmt.Println(val)
}
返回的结果由于有多个,所以肯定返回的是切片。
ZRevRange用法跟ZRange一样,区别是ZRevRange的结果是按分数从大到小排序。
6. ZRangeByScore
根据分数范围返回集合元素,元素根据分数从小到大排序,支持分页
// 初始化查询条件, Offset和Count用于分页
op := redis.ZRangeBy{
Min:"2", // 最小分数
Max:"10", // 最大分数
Offset:0, // 类似sql的limit, 表示开始偏移量
Count:5, // 一次返回多少数据
}
vals, err := rdb.ZRangeByScore(ctx,"key", &op).Result()
if err != nil {
panic(err)
}
for _, val := range vals {
fmt.Println(val)
}
总结:
这个op是个结构体,你可以把这个结构体理解为对ZRangeByScore函数的配置信息,然后传进去就行了。
配置中制定了分数范围,和偏移量,还有一次返回多少数据。返回的值肯定就是个切片,所以要遍历取结果。
7. ZRevRangeByScore
用法类似ZRangeByScore,区别是元素根据分数从大到小排序。
8. ZRangeByScoreWithScores
用法跟ZRangeByScore一样,区别是除了返回集合元素,同时也返回元素对应的分数
// 初始化查询条件, Offset和Count用于分页
op := redis.ZRangeBy{
Min:"2", // 最小分数
Max:"10", // 最大分数
Offset:0, // 类似sql的limit, 表示开始偏移量
Count:5, // 一次返回多少数据
}
vals, err := rdb.ZRangeByScoreWithScores(ctx,"key", &op).Result()
if err != nil {
panic(err)
}
for _, val := range vals {
fmt.Println(val.Member) // 集合元素
fmt.Println(val.Score) // 分数
}
这个op还是结构体,还是用来做配置信息的。
然后这里返回值用了结构体切片。这样才方便返回两个值,我们直接访问它的元素就可以轻松达到目的。
9. ZRem
删除集合元素
// 删除集合中的元素zhangsan
rdb.ZRem(ctx,"key", "zhangsan")
// 删除集合中的元素zhangsan和zhangsan1
// 支持一次删除多个元素
rdb.ZRem(ctx,"key", "zhangsan", "zhangsan1")
可以删一个,也可以批量删。根据key来删。
10. ZRemRangeByRank
根据索引范围删除元素(对于SET来说没用索引这种概念,但是对于sorted set是有的,由于根据分数进行排序,所以它的位置是可以确定下来的。)从低到高的顺序进行删除。
// 集合元素按分数排序,从最低分到高分,删除第0个元素到第5个元素。
// 这里相当于删除最低分的几个元素
rdb.ZRemRangeByRank(ctx,"key", 0, 5)
// 位置参数写成负数,代表从高分开始删除。
// 这个例子,删除最高分数的两个元素,-1代表最高分数的位置,-2第二高分,以此类推。
rdb.ZRemRangeByRank(ctx,"key", -1, -2)
11.ZRemRangeByScore
根据分数范围删除元素
// 删除范围: 2<=分数<=5 的元素
rdb.ZRemRangeByScore(ctx,"key", "2", "5")
// 删除范围: 2<=分数<5 的元素
rdb.ZRemRangeByScore(ctx,"key", "2", "(5")
(这个符号代表不要等于。
12. ZScore
查询元素对应的分数
// 查询集合元素zhangsan的分数
score, _ := rdb.ZScore(ctx,"key", "zhangsan").Result()
fmt.Println(score)
根据key查score
13. ZRank
根据元素名,查询集合元素在集合中的排名,从0开始算,集合元素按分数从小到大排序。
rk, _ := rdb.ZRank(ctx,"key", "zhangsan").Result()
fmt.Println(rk)
发布订阅
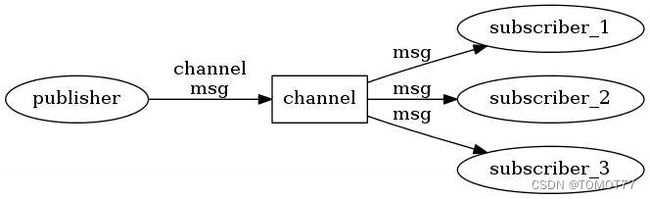
结构就长这样:
publisher把消息发到channel里,然后订阅者都可以同时从channel里收到消息。
简单来说,一堆人订阅,一个人发送。
代码就两部分:某个客户端作为发布,剩下一堆客户端作为订阅。
- Subscribe订阅
// 订阅channel1这个channel
sub := rdb.Subscribe(ctx, "channel1")
// sub.Channel() 返回go channel,可以循环读取redis服务器发过来的消息
for msg := range sub.Channel() {
// 打印收到的消息
fmt.Println(msg.Channel)
fmt.Println(msg.Payload)
}
//或者
for {
msg, err := sub.ReceiveMessage(ctx)
if err != nil {
panic(err)
}
fmt.Println(msg.Channel, msg.Payload)
}
如何使用 go-redis 库实现 Redis 的发布/订阅模型中的订阅部分。代码中展示了两种不同的方法来接收和处理从 Redis 频道(channel)发来的消息。
订阅频道
首先,使用 rdb.Subscribe(ctx, “channel1”) 订阅了名为 “channel1” 的频道。这个调用返回了一个 *PubSub 类型的对象 sub,这个对象允许你监听并接收频道上的消息。
接收消息的两种方式
1. 使用 sub.Channel() 接收消息
sub.Channel() 返回一个 Go 的通道(channel),你可以使用 range 循环从中读取消息。每当 channel1 上有新消息发布时,这个 Go 通道就会接收到一个消息对象。根据channel的知识,当没有数据过来的时候就会在这里阻塞。
消息对象 msg 包含多个字段,其中 msg.Channel 表示消息来源的频道名称,msg.Payload 表示消息的内容。
这种方法通过 Go 的通道机制异步接收和处理消息,适用于需要持续监听消息的场景。
2. 使用 sub.ReceiveMessage() 循环接收消息
另一种方式是使用 sub.ReceiveMessage(ctx) 在一个无限循环中接收消息。这个方法在每次调用时阻塞等待直到新消息到达,然后返回该消息。当 ReceiveMessage(ctx) 方法中使用 context.Context 参数时,这个 ctx 允许你控制 ReceiveMessage 调用的行为。 所以这种阻塞就是这样实现的。
类似地,返回的消息对象 msg 包含消息来源的频道 msg.Channel 和消息内容 msg.Payload。
如果在接收消息时发生错误(如连接中断),ReceiveMessage(ctx) 会返回一个错误,此示例中通过 panic(err) 来处理这种错误情况。
这种方法适合于需要显式控制消息接收时机和错误处理的场景。
2.publisher
将消息发送到指定的channel
// 将"message"消息发送到channel1这个通道上
rdb.Publish(ctx,"channel1","message")
这里注意你是要在另一个客户端上去作为publisher
3. PSubscribe
用法跟Subscribe一样,区别是PSubscribe订阅通道(channel)支持模式匹配。
PSubscribe (模式订阅)和 Subscribe (普通订阅)都用于订阅频道以接收消息,但它们之间有一个关键区别:
Subscribe
Subscribe 用于订阅一个或多个具体的频道。
当你订阅了一个频道后,只有发送到这个特定频道的消息会被接收。
使用 Subscribe 时,你需要明确知道你感兴趣的频道名称。
PSubscribe
PSubscribe 允许你使用模式匹配来订阅频道。
你可以订阅匹配特定模式的所有频道。例如,使用 news. 可以订阅所有以 news. 开头的频道。*
这意味着你不需要知道所有具体的频道名称。只要频道名称匹配指定的模式,发送到这些频道的消息都会被接收。
模式匹配
模式匹配是指使用特定的模式(pattern)来匹配一系列的字符串。在 Redis 的 PSubscribe 中,模式可以包含以下特殊字符:
- 匹配零个或多个字符。例如,news.* 可以匹配 news.sports、news.weather 等。
? 匹配任何单个字符。例如,news.? 可以匹配 news.1、news.a 等,但不会匹配 news.11。
[ ] 匹配括号内的任何一个字符。例如,news.[ab] 可以匹配 news.a 或 news.b。
模式匹配示例:
假设你想要订阅所有与新闻相关的频道,但新闻频道有多个不同的分类,如 news.sports、news.weather、news.politics 等,而你希望通过一个订阅操作就能接收到所有这些分类的消息,这时候就可以使用 PSubscribe:
// 使用 PSubscribe 订阅所有以 "news." 开头的频道
sub := rdb.PSubscribe(ctx, "news.*")
// 然后,像处理 Subscribe 的消息一样处理接收到的消息
for msg := range sub.Channel() {
fmt.Println(msg.Channel, msg.Payload)
}
总结:
通过使用 PSubscribe 和模式匹配,你可以灵活地订阅多个频道,而不需要为每个频道单独设置订阅,这在处理类别繁多且动态变化的消息时非常有用。
4. Unsubscribe
取消订阅
// 订阅channel1这个channel
sub := rdb.Subscribe(ctx,"channel1")
// 取消订阅
sub.Unsubscribe(ctx,"channel1")
5. PubSubNumSub
查询指定的channel有多少个订阅者。
// 查询channel_1通道的订阅者数量
chs, _ := rdb.PubSubNumSub(ctx, "channel_1").Result()
for ch, count := range chs {
fmt.Println(ch) // channel名字
fmt.Println(count) // channel的订阅者数量
}
PubSubNumSub 方法:这个方法用于查询一个或多个频道的订阅者数量。它是 Redis 提供的 PUBSUB NUMSUB 命令的封装,允许你检查特定频道当前有多少个活跃订阅者。
查询操作:rdb.PubSubNumSub(ctx, “channel_1”).Result() 调用请求 Redis 服务器返回名为 “channel_1” 的频道的订阅者数量。这个方法返回两个值:一个映射(map)和一个错误对象。 映射的键是频道名,值是对应的订阅者数量。
错误处理:在这段示例代码中,错误处理被忽略(_ 用来接收错误返回值,表示不处理错误)。在实际应用中,应该检查并适当处理这个错误,以确保程序的健壮性。
遍历和打印结果:通过 for ch, count := range chs 循环遍历返回的映射(map),其中 ch 是频道名,count 是该频道的订阅者数量。循环体内打印每个频道的名称和订阅者数量。
上面这个例子只是查询一个频道的。
如果我想查询多个频道:
chs, _ := rdb.PubSubNumSub(ctx, "channel_1", "channel_2", "channel_3").Result()
事务处理
注意redis里的事务和mysql里面的是不一样的。
redis支持事务,可以在一次请求中执行多个命令,redis中的事务主要通过MUTIL和EXEC两个命名实现,MUTIL用于开启事务,开启之后所有的命令都会被放入到一个队列中。最后通过EXEC来执行所有的命令。
Redis中的事务和mysql里的事务不一样,关系型数据库中事务一般是一个原子操作,要么全部执行成功,要么全部执行失败。而在Redis中事务不能保证所有的命令都会执行成功。它的执行结果取决于事务中的命令。
但是Redis可以保证三点:
1.在发送EXEC命令之前,所有的命令都会被放入一个队列中缓存起来。不会立即执行
2.在收到EXEC命令之后,事务开始执行。事务中任何一个命令执行失败,其他命令仍然会执行。不会因为某一个命令失败而全部失败。
3.在事务执行过程中,其他客户端提交的命令请求不会被穿插到事务的执行命令序列中
1. TxPipeline
以Pipeline的方式操作事务
// 开启一个TxPipeline事务
pipe := rdb.TxPipeline()
// 执行事务操作,可以通过pipe读写redis
incr := pipe.Incr(ctx,"tx_pipeline_counter")
pipe.Expire(ctx,"tx_pipeline_counter", time.Hour)
// 上面代码等同于执行下面redis命令
//
// MULTI
// INCR pipeline_counter
// EXPIRE pipeline_counts 3600
// EXEC
// 通过Exec函数提交redis事务
_, err := pipe.Exec(ctx)
// 提交事务后,我们可以查询事务操作的结果
// 前面执行Incr函数,在没有执行exec函数之前,实际上还没开始运行。
fmt.Println(incr.Val(), err)
go-redis 客户端库通过**事务管道(TxPipeline)**执行 Redis 事务。
解读:
开启事务管道
TxPipeline:首先,通过调用 rdb.TxPipeline() 开启一个新的事务管道。这个管道允许你将多个命令打包在一起,作为一个事务一次性提交给 Redis 执行。这是一种优化技术,可以减少网络往返次数,提高命令执行效率。
执行事务操作
Incr 和 Expire:接着,在事务管道中添加了两个操作:一个 INCR 操作和一个 EXPIRE 操作。pipe.Incr(ctx, “tx_pipeline_counter”) 会递增键 “tx_pipeline_counter” 的值,而 pipe.Expire(ctx, “tx_pipeline_counter”, time.Hour) 设置这个键的过期时间为一小时。
提交事务
Exec:通过 pipe.Exec(ctx) 提交事务。这个调用实际上将管道中的所有命令发送到 Redis 服务器并执行。它相当于 Redis 的 MULTI … EXEC 命令序列,其中 MULTI 开始一个事务,接着是一系列命令,最后 EXEC 提交事务。
查询事务操作结果
incr.Val():在事务提交后,可以通过之前定义的命令结果变量(如 incr)来查询操作的结果。在这个例子中,incr.Val() 返回 INCR 操作后的计数值。
Redis 事务确保了一系列命令被连续执行,不会被其他命令打断,提供了一种原子性。但是,如果事务中的命令因为运行时错误而失败,不会导致整个事务被回滚,事务中的其他命令仍然会被执行。这与传统数据库系统中的事务行为是不同的,后者通常在任何命令失败时回滚整个事务。
TxPipeline 提供的是一种将多个命令打包在一起原子性执行的能力,而不是传统数据库事务中的“全部成功或全部失败”的原子性。这意味着在 Redis 事务中,某些命令可能执行成功,而某些命令因为运行时错误而失败,这并不会影响其他命令的执行。
2. watch
redis乐观锁支持,可以通过watch监听一些Key, 如果这些key的值没有被其他人改变的话,才可以提交事务
ctx := context.Background()
// 定义一个回调函数,用于处理事务逻辑
fn := func(tx *redis.Tx) error {
// 先查询下当前watch监听的key的值
v, err := tx.Get(ctx, "key").Int()
if err != nil && err != redis.Nil {
return err
}
// 这里可以处理业务
v++
// 如果key的值没有改变的话,Pipelined函数才会调用成功
_, err = tx.Pipelined(ctx, func(pipe redis.Pipeliner) error {
// 在这里给key设置最新值
pipe.Set(ctx, "key", v, 0)
return nil
})
return err
}
// 使用Watch监听一些Key, 同时绑定一个回调函数fn, 监听Key后的逻辑写在fn这个回调函数里面
// 如果想监听多个key,可以这么写:client.Watch(ctx,fn, "key1", "key2", "key3")
rdb.Watch(ctx, fn, "key")
解读:
中使用 go-redis 库实现 Redis 的乐观锁机制。乐观锁是一种在数据库管理中用来处理并发控制的机制。与悲观锁不同,乐观锁允许多个事务同时进行,直到事务的最终提交阶段才检查数据是否发生了冲突。
乐观锁的工作原理
乐观锁通常通过版本号或是对数据的检查(在 Redis 中是通过 WATCH 命令实现) 来确认在事务执行期间数据是否被其他事务修改过:
如果数据在读取后未被其他事务修改,则当前事务可以成功提交。
如果数据被修改,则当前事务会回滚,通常需要重试事务。
解读代码
在 go-redis 库中,tx redis.Tx 表示的是一个事务的上下文*,它是一个指向 redis.Tx 类型的指针。redis.Tx 类型提供了一组方法,允许你在事务中执行 Redis 命令。这个事务上下文 tx 是在使用 WATCH 命令监听一个或多个 key 之后,用于执行一系列依赖于这些 key 的操作的环境
当你调用 rdb.Watch(ctx, fn, “key”) 时,fn 是一个回调函数,该函数接受一个 redis.Tx 类型的参数 tx。在这个回调函数内部,你可以使用 tx 来执行想要在事务中运行的命令*。通过这种方式,go-redis 库使得在一个事务中执行多个依赖于被 WATCH 命令监听的 key 的操作变得可能。
redis.Tx 类型的用途:
执行事务命令:在 fn 回调函数中,你可以通过 tx 执行如 GET、SET、INCR 等 Redis 命令。这些命令会被收集起来,直到调用 EXEC 命令时一起执行。
示例中 tx.Pipelined 方法的作用:
提交事务操作:在示例中,tx.Pipelined(ctx, func(pipe redis.Pipeliner) error { … }) 是在事务上下文中使用管道(pipeline)来执行一系列命令。 这里的 pipe 实际上是 tx 的一个接口,允许你把多个命令添加到事务中。当你调用 pipe.Set 等方法时,这些命令会被缓存起来,直到调用 pipe.Exec 提交事务。
在整个 WATCH-事务流程中,redis.Tx 扮演的是一个管理事务命令、控制事务执行流程的角色。它让事务中的命令执行变得灵活,同时提供了乐观锁的能力,确保了事务的原子性和一致性。
乐观锁:通过在执行事务之前使用 WATCH 命令,你可以为事务实现乐观锁。如果在事务执行期间任何被 WATCH 的 key 被修改,事务将会被取消(EXEC 命令返回错误)。
使用 Watch 监听 Key:rdb.Watch(ctx, fn, “key”) 这行代码使用 Watch 命令对 “key” 进行监听。如果 “key” 在执行事务的过程中被修改,那么事务将不会被执行。
定义事务逻辑 :事务的具体逻辑被定义在 fn 回调函数中。首先,使用 tx.Get(ctx, “key”).Int() 查询监听的 key 的当前值。
业务处理:对值 v 进行业务逻辑处理(在这个例子中是简单的自增操作)。
使用 Pipelined 提交更改:tx.Pipelined(ctx, func(pipe redis.Pipeliner) error { … }) 在事务管道中添加了设置 key 新值的操作。只有当 WATCH 的 key 在整个事务执行过程中未被外部修改时,这些更改才会被实际提交到数据库。
现在整体走一遍代码逻辑:
1. 设置上下文
ctx := context.Background()
这个就是个初始化操作,因为调用函数需要,所以就创建一个,暂时没啥用。
2. 定义事务逻辑
fn := func(tx *redis.Tx) error {
// 先查询下当前watch监听的key的值
v, err := tx.Get(ctx, "key").Int()
if err != nil && err != redis.Nil {
return err
}
// 这里可以处理业务
v++
// 如果key的值没有改变的话,Pipelined函数才会调用成功
_, err = tx.Pipelined(ctx, func(pipe redis.Pipeliner) error {
// 在这里给key设置最新值
pipe.Set(ctx, "key", v, 0)
return nil
})
return err
}
这段代码定义了一个回调函数 fn,该函数包含了要在事务中执行的操作。这个函数首先尝试获取 “key” 的当前值,然后对这个值进行递增,并尝试将新值写回 Redis。
查询当前值:使用 tx.Get(ctx, “key”).Int() 获取 “key” 的当前整数值。
递增值:对获取到的值 v 进行递增操作 (v++)。
写回新值:通过 tx.Pipelined 方法提交一个管道事务,其中只包含一个操作:将 “key” 的值设置为递增后的 v。
3. 监听 Key 并执行事务
rdb.Watch(ctx, fn, "key")
这行代码使用 Watch 方法监听 “key”。如果 “key” 在执行事务的过程中没有被其他命令修改,那么 fn 中定义的事务逻辑就会被执行。这实现了乐观锁的机制:只有当被监听的 key 没有发生变化时,事务中的命令才会被执行。
Go 中使用 go-redis 库实现带有乐观锁的 Redis 事务。通过监听一个 key,只有在这个 key 在事务执行过程中未被修改时,才执行事务中的操作(递增 key 的值)。这句话的意思是事务之外的如果对这个key进行了修改,那么事务中对这个key的操作就不会实现。这种方法适用于需要基于现有数据值进行更新且希望避免并发冲突的场景。
总结:
我个人觉得还是很简单的,只要熟悉Redis命令。