【论文精读】Latent Diffusion
摘要
Diffusion models(DMs)被证明在复杂自然场景的高分辨率图像合成能力优于以往的GAN或autoregressive (AR)transformer。作为基于似然的模型,其没有GAN的模式崩溃和训练不稳定问题,通过参数共享,其可以模拟自然图像的高度复杂分布;另外也不需要AR类模型庞大的参数量,但DM在像素级的训练推理仍然需要大量的计算量,故本文的重点在于在不损害DM性能的情况下减少计算量,以优化算法效率。
基于似然估计的模型的学习大致分为两个阶段:首先为感知压缩阶段,该阶段可以去除图像的高频细节,也能学习到少量的语义变化;随后生成模型会学习数据的语义和概念组成(语义压缩)。故本文目标是找到一个在感知上与数据空间等效但计算量更小的空间,并在其中训练用于高分辨率图像合成的DM。
故本文提出的方法在训练过程会分成两个不同的阶段:首先会训练一个自编码器,该编码器会提供了一个在感知上等效于数据空间的低维表示空间,随后在该潜空间中训练DM。该模型称为Latent Diffusion Models(LDM)。

上图显示了提出的模型在不同阶段的浅表示失真率和单维度语义信息量的权衡图,在感知压缩阶段,自编码器编码的浅表示具有高度的信息密度,同时保持了较低的图像失真率,保留了图像的整体结构。而在生成阶段,LDM对图像信息压缩率较小,故可以建模图像细节的能力,但同时失真率较高,会损失图像的整体结构信息,但这部分信息刚好可以由感知编码器弥补。故整体上,本文方法具备提取重建图像整体结构与细节信息的能力。
这种方法的优点在于,只需要训练一次通用自编码阶段,随后就可以将其重复用于多个DM任务,例如各种图生图和文生图任务。为了适配这些任务,本文设计了一个架构,将transformer连接到DM的UNet骨干网络,以实现任意类型的基于token的适配机制。整体改进有:

- 编码器会对数据进行压缩,且因为DM本身可以为数据提供极好的归纳偏差,故在该压缩空间中,DM仍然可以实现可靠和详细的数据重建(如上图,自编码器计算的潜空间只需进行4倍下采样就可以实现超越以往生成模型的性能),且可以有效地应用于百万像素图像的高分辨率合成
- 在多个任务(无条件图像合成、图像修复、超分辨率)和数据集上实现了最先进的性能,且显著降低了训练和推理的计算量
- 因为本文方法是分阶段训练的,故与以往同时训练自编码器和似然估计的方法相比,所提出方法不需要自编码器重建和似然估计生成能力的加权平衡。这确保了编码器的重建数据的可靠性,且降低了对潜空间的正则化要求
- 设计了一种基于交叉注意力的通用条件适配机制,实现了多模态训练。故本方法可以用来训练类别条件模型(Class-Conditional)、文本到图像和布局到图像的模型
框架
DM允许通过对相应的损失项进行欠采样来忽略感知上不相关的图像细节,但其仍然需要在像素空间进行函数评估,计算复杂度过高。为了降低DM高分辨率图像生成的计算复杂度,本文模型采用两阶段训练,第一阶段利用自编码学习一个在感知上等效于图像空间的潜空间,得到的浅表示为压缩后的图像高密度信息,随后在该潜空间中采用DM进行图像生成,该方法的优点如下:
- 通过避开高维图像空间,使DM计算效率提高
- 利用了从UNet架构中继承的DM的归纳偏差,保证其对图像空间结构信息的特征提取能力
- 获得的通用的自编码器压缩模型,其潜空间可用于训练多个生成模型,包括各种下游应用,如采用CLIP的文本生成或图像生成
Perceptual Image Compression
感知压缩模型为由感知损失和基于patch的对抗损失组合训练的自编码器,这确保了重建能通过局部真实性被限制在图像流形上,避免了仅仅依靠像素空间损失( L 1 L_1 L1或 L 2 L_2 L2损失)而导致的模糊性。
具体,给定图像 x ∈ R H × W × 3 x\in \Reals^{H \times W \times 3} x∈RH×W×3,编码器 E E E会将 x x x编码为潜表示 z = E ( x ) z=E(x) z=E(x),解码器 D D D再从潜表示中重建图像 x ^ = D ( z ) = D ( E ( x ) ) \hat x=D(z)=D(E(x)) x^=D(z)=D(E(x)),其中 z ∈ R h × w × c z∈\R^{h×w×c} z∈Rh×w×c。编码器通过因子 f = H / h = W / w f=H/h=W/w f=H/h=W/w对图像进行下采样,本文研究了不同的下采样因子 f = 2 m f=2^m f=2m, m ∈ N m∈ \N m∈N。
为了避免高方差潜空间,本文实验了两种不同类型的正则化方法。
- KL-reg:对学习到的潜表示添加轻微的KL惩罚,以使其符合标准正态分布,类似于VAE
- VQ-reg:在解码器内使用向量量化(vector quantization)层
该模型类似于VQGAN,但量化层被解码器吸收。潜表示 z = E ( x ) z=E(x) z=E(x)会进一步由后续的DM处理。
Latent Diffusion Models
Diffusion Models
DM是通过对正态分布变量逐步去噪来学习数据分布 p ( x ) p(x) p(x)的概率模型,相当于学习长度为 T T T的固定马尔可夫链的逆过程。可以解释为一个等权重的去噪自编码器序列 ϵ θ ( x t , t ) ; t = 1 … T \epsilon_\theta(x_t,t);t=1\dots T ϵθ(xt,t);t=1…T,其被训练以预测其输入 x t x_t xt的去噪变体,其中 x t x_t xt为输入 x x x加噪声的版本。 相应的目标可以简化为:
L D M = E x , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] L_{DM}=\mathbb{E}_{x,\epsilon\sim N(0,1),t}[||\epsilon-\epsilon_\theta(x_t,t)||^2_2] LDM=Ex,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22]
其中 t t t均匀采样自 { 1 , … , T } \{1,\dots ,T\} {1,…,T}。
Generative Modeling of Latent Representations
通过训练由 E E E和 D D D组成的感知压缩模型,可以获得一个有效的低维潜空间,其中图像的高频信号、难以察觉的细节被抽象掉了。与高维像素空间相比,这个空间更适合基于似然的生成模型,因为DM现在可以专注于数据中更重要的语义位,且在这个低维空间的计算效率比在像素空间中高得多。
利用由2D卷积层构建的UNet,重新加权的bound会进一步将目标集中在感知上最相关的比特上,故DM可以提供特定于图像的归纳偏差。结合浅表示与DM的学习目标,则有:
L L D M : = E E ( x ) , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( z t , t ) ∣ ∣ 2 2 ] L_{LDM}:=\mathbb{E}_{E(x),\epsilon\sim N(0,1),t}[||\epsilon-\epsilon_\theta(z_t,t)||^2_2] LLDM:=EE(x),ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t)∣∣22]
其中LDM的神经主干 ϵ θ ( ⋅ , t ) \epsilon_\theta(\cdot,t) ϵθ(⋅,t)为一个时间条件UNet, z t = E ( x t ) z_t=E(x_t) zt=E(xt),概率模型 p ( z ) p(z) p(z)的样本通过 D D D解码到图像空间。
Conditioning Mechanisms
DM能够建模形式为 p ( z ∣ y ) p(z|y) p(z∣y)的条件分布,结合上式则可以用条件去噪自编码器 ϵ θ ( z t , t , y ) \epsilon_\theta(z_t,t,y) ϵθ(zt,t,y)实现多模态训练,其中输入 y y y即为prompt隐编码,可以为文本,语义映射或图像等。
本文通过使用交叉注意机制增强UNet主干的方式,将DM转变为更灵活的条件图像生成器。为了编码各种模态(如语言prompt)的输入 y y y,引入一个特定领域的编码器 τ θ τ_θ τθ将 y y y投影为中间表示 τ θ ( y ) ∈ R M × d τ τ_θ(y)∈R^{M×dτ} τθ(y)∈RM×dτ,然后通过交叉注意将其映射到UNet的中间层,公式为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) ⋅ V Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Attention(Q,K,V)=softmax(\frac {QK^T} {\sqrt d})\cdot V \\ Q=W^{(i)}_Q\cdot \varphi_i(z_t),K=W^{(i)}_K\cdot \tau_\theta(y),V=W^{(i)}_V\cdot \tau_\theta(y) Attention(Q,K,V)=softmax(dQKT)⋅VQ=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)
其中 φ i ( z t ) ∈ R N × d e i \varphi_i(z_t)\in \R^{N \times d^i_e} φi(zt)∈RN×dei为实现了 ϵ θ \epsilon_\theta ϵθ的UNet的中间层(第 i i i层)表示, W V ( i ) ∈ R d × d ϵ i W^{(i)}_V \in \R^{d×d^i_{\epsilon}} WV(i)∈Rd×dϵi, W Q ( i ) , W K ( i ) ∈ R d × d τ W^{(i)}_Q ,W^{(i)}_K \in \R^{d×d_τ} WQ(i),WK(i)∈Rd×dτ为可学习的投影矩阵。模型的整体计算流程如下图。
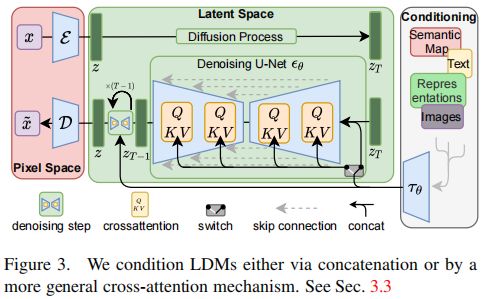
基于条件生成,学习目标进一步改进为条件LDM:
L L D M : = E E ( x ) , y , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( z t , t , τ θ ( y ) ) ∣ ∣ 2 2 ] L_{LDM}:=\mathbb{E}_{E(x),y,\epsilon\sim N(0,1),t}[||\epsilon-\epsilon_\theta(z_t,t,\tau_\theta(y))||^2_2] LLDM:=EE(x),y,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t,τθ(y))∣∣22]
其中 τ θ τ_θ τθ和 ϵ θ \epsilon_\theta ϵθ通过 L L D M L_{LDM} LLDM联合优化, τ θ τ_θ τθ可以由特定领域prompt的专家模型来参数化(如CLIP)。
实验
LDM为各种图像模态的基于diffusion的图像合成提供了灵活和易计算的方法,并采用下列实验验证。
On Perceptual Compression Tradeoffs
本节分析具有不同下采样因子 f ∈ { 1 , 2 , 4 , 8 , 16 , 32 } f∈ \{1,2,4,8,16,32 \} f∈{1,2,4,8,16,32}(简称为LDM-f,其中LDM-1对应于基于像素的dm)的LDM的行为。为了保证对比公平性,所有实验在单个NVIDIA A100上进行,并以相同的步数和相同的参数训练所有模型。
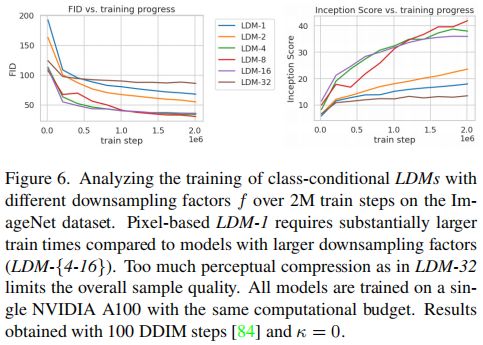
上图显示了在ImageNet数据集上,2M步的总训练阶段中类别条件LDM的生成的样本质量与训练进度的关系。观察到,较小的下采样因子LDM-{1,2}会导致模型训练进度缓慢,而过大的下采样因子LDM-{32}会导致训练阶段中生成图像的保真度停滞不前。分析得知,较小的下采样因子会导致大量的高频信息传入DM,而过高的下采样因子会导致大量的图像信息损失,从而限制了可实现的质量。在经过2M训练步骤后,基于像素的diffusion(LDM-1)和LDM-8之间的FID差距显著,证明LDM-{4-16}在计算效率和感知度之间可以取得很好的平衡。

上图比较了在CelebA-HQ和ImageNet上不同下采样因子f下训练的模型,模型使用DDIM采样器在不同降噪步数 { 10 , 20 , 50 , 100 , 200 } \{10,20,50,100,200\} {10,20,50,100,200}下的采样速度,并将其与FID分数进行了对比。观察到,LDM-{4-8}的表现优于具有不合适的下采样因子的模型,特别是与基于像素的LDM-1相比,不仅实现了更低的FID分数,同时也提高了样本吞吐量。综上所述,LDM-4和LDM-8提供了实现高质量生成结果的最佳条件。
Image Generation with Latent Diffusion
本节在CelebA-HQ、FFHQ、LSUN-Churches和-Bedrooms上分别使用 25 6 2 256^2 2562分辨率图像训练了多个无条件LDM,并使用FID和Precision-and-Recall评估生成的样本质量及其对数据流形的覆盖程度。

上表为实验结果。在CelebA-HQ上,LDM实现了最先进的FID为5.11,优于以前的基于似然的模型和GAN,还超过了单一阶段结构的LSGM。除了LSUN-Bedroom数据集,LDM再所有数据集上的表现都优于以往基于diffusion的方法。对于表现相近的ADM,LDM只使用了其一半的参数,所需的训练资源减少了4倍。此外,LDM在准确率和召回率方面也优于基于GAN的方法,从而证实了其基于模式覆盖的似然训练目标比对抗性方法的优势。

上图显示了在每个数据集上训练的LDM的定性结果。
Conditional Latent Diffusion
Transformer Encoders for LDMs
通过在LDM中引入基于交叉注意力的条件,为DM在以前未探索的各种条件模式打开了大门。

为了实验文本到图像的图像建模,本节在LAION-400M上训练了一个1.45B参数的KL正则化LDM,该LDM以语言prompt为条件,并使用BERT-tokenizer及transformer实现的 τ θ τ_θ τθ来计算通过多头交叉注意映射到UNet的隐编码。这种同时学习语言表征和视觉生成的组合产生了一个强大的多模态模型,其可以很好地概括复杂的、用户定义的文本prompt来生成图像,如上图。

为了进行定量分析,本节遵循先前的工作并在MS-COCO验证集上评估了模型文生图的性能。结果如上表,观察到,LDM改进了基于AR和GAN的模型。另外注意到,应用Classifier-Free Guidance的diffusion极大地提高了生成样本质量,故LDM-KL-8-G与以往最先进的AR和diffusion模型在文本到图像合成方面的性能不相上下,同时大大减少了参数量。

另外还在OpenImages上训练了基于语义布局(semantic layouts)的图像合成模型,并在COCO上进行了微调,结果如上图。

另外评估了在ImageNet中训练的 f ∈ { 4 , 8 } f∈\{ 4,8 \} f∈{4,8}的最佳类别条件模型,结果如上表。观察到,LDM-4优于目前最先进的diffusion模型ADM,同时显著减少了计算量和参数量。
Convolutional Sampling Beyond 25 6 2 256^2 2562
通过将空间对齐的条件信息和 ϵ θ \epsilon_\theta ϵθ的输入 z t z_t zt相连接,ldm可以作为高效的通用图像到图像的生成模型。本节用这种配置来训练语义合成、超分辨率和图像修复模型。

对于语义合成训练配置,使用与语义图配对的景观图,并将语义图的下采样版本与LDM-4模型计算的景观图的潜表示连接起来,然后在输入分辨率为 25 6 2 256^2 2562的情况下进行训练,当以卷积方式评估时可以生成高达百万像素的图像,如上图。利用这种方法,还可以应用超分辨率LDM变体和绘画LDM变体来生成 51 2 2 512^2 5122和 102 4 2 1024^2 10242之间的大图像。对于该应用,信噪比(由潜空间的尺度诱导)会显著影响生成结果。
上图为上述配置下生成的景观图。
结合无分类指导,使用文本条件的LDM-KL-8-G可以直接合成 > 25 6 2 > 256^2 >2562分辨率的图像,如上图。
Super-Resolution with Latent Diffusion
LDMs可以通过直接调节低分辨率的图像来有效地训练超分辨率任务。超分辨率实验遵循SR3,采用双三次插值退化将图像进行4倍下采样得到LR图,并按照SR3的数据处理管道在ImageNet上进行训练。采用在OpenImages(VQ-reg)上预训练的 { f = 4 } \{f=4\} {f=4}自编码器得到LR的浅表示,并连接低分辨率条件 y y y得到UNet的输入向量。

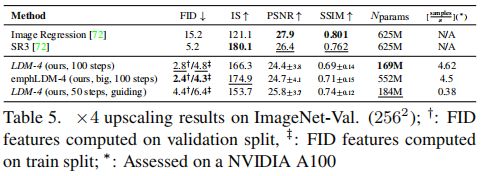
上图/表为实验的定性和定量结果。观察到,LDM-SR在FID指标下优于SR3,而SR3具有更好的IS,一个简单的Image Regression模型获得了最高的PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structural SIMilarity)分数,但是这些指标与人类的感知并不一致。

故还进行了一项用户研究,比较了pixel-baseline与LDM-SR,模型配置遵循SR3。实验会向人类受试者展示LR图及对应的两幅SR图像,并询问其偏好,上表的结果证实了LDM-SR的良好性能。
由于双三次退化过程不能很好地泛化到不遵循此预处理的图像,故本文还通过使用更多样化的退化方法训练了一个通用模型LDM-BSR。
Inpainting with Latent Diffusion
图像修复是用新内容填充图像的mask区域的任务,因为图像的某些部分要么被破坏了,要么是为了替换图像中现有的但不需要的内容。本文评估了此任务上有条件LDM图像生成的通用方法与以往最先进的方法的性能,评估遵循LaMa协议,其引入了一种依赖于快速傅里叶卷积的架构。
实验分析了第一阶段编码器不同设计选择的效果。具体,比较了LDM-1及采用了KL或VQ正则化的LDM-4,以及在第一阶段中没有任何注意力的VQ-LDM-4的修复性能,后者在高分辨率下减少了用于解码的GPU内存使用。为了可比性,固定了所有模型的参数数量。
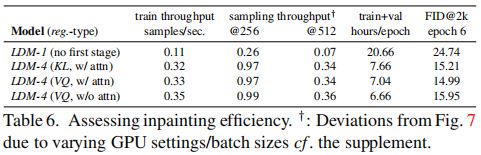
上表显示了 25 6 2 256^2 2562和 51 2 2 512^2 5122分辨率下不同配置模型的训练和采样吞吐量,每个epoch的总训练时间以及在训练6个epoch后的FID评分。观察到,LDM-4的速度比基于像素LDM-1至少提高了2.7倍,同时FID分数提高了至少1.6倍。

上表为LDM与其他修复方法的结果。观察到,有注意力的LDM-4比LaMa取得更高的FID,未掩码图像修复任务中LDM-4的LPIPS略高于LaMa,与LDM产生的结果相比,LaMa的结果倾向于恢复更平均的图像。
基于上述结果,实验又在第一阶段使用VQ正则化的配置下训练了一个更大的LDM,该DM的UNet在其三个特征层上使用了注意力层,并使用BigGAN的残差块对潜表示进行上下采样,该LDM具有387M参数。对该模型训练后,在 25 6 2 256^2 2562和 51 2 2 512^2 5122分辨率下生成的样本质量相比原始LDM显著提高,初步认为这是由额外的注意力模块导致的。此外,对 51 2 2 512^2 5122分辨率的模型进行半个epoch的微调,可以使模型适应新的特征统计,并在图像修复上取得最先进的FID(big, w/o attn)。

上图为LDM-4(big, w/o attn)图像修复的定性结果。
Limitations & Societal Impact
Limitations
虽然与基于像素的方法相比,ldm显着减少了计算需求,但其顺序采样过程仍然比GAN慢。此外,当需要高精度的生成图像时,ldm的仍旧存在问题,下采样的自编码器的重建能力会成为细粒度精度生成的瓶颈。
Societal Impact
图像生成模型是一把双刃剑:一方面,其可以启发各种创造性的应用程序,另一方面,这也意味着深度造假图像的创建和传播变得更加容易。
生成式模型的生成图像中可能会暴漏其训练数据,而当训练数据包含敏感或个人信息且未经明确同意的情况下,会导致各种社会问题。
最后,深度学习往往会重现或加强数据存在的偏差,虽然DM比基于GAN的方法能更好地覆盖数据分布,但LDM的两阶段方法结合了对抗性训练和基于可能性的目标,在多大程度上误导了数据仍然是一个重要的研究问题。
Appendix
Detailed Information on Denoising Diffusion Models
DM可以用信噪比 S N R ( t ) = α t 2 σ t 2 SNR(t)=\frac {\alpha^2_t} {\sigma^2_t} SNR(t)=σt2αt2组成的序列 ( α t ) t = 1 T (\alpha_t)^T_{t=1} (αt)t=1T 和 ( σ t ) t = 1 T (\sigma_t)^T_{t=1} (σt)t=1T 来指定,故从数据样本 x 0 x_0 x0开始,定义一个前向diffusion过程 q q q:
q ( x t ∣ x 0 ) = N ( x t ∣ α t x 0 , σ t 2 I ) q(x_t|x_0)=N(x_t|\alpha_tx_0,\sigma^2_tI) q(xt∣x0)=N(xt∣αtx0,σt2I)
指定 s < t s
q ( x t ∣ x s ) = N ( x t ∣ α t ∣ s x s , σ t ∣ s 2 I ) α t ∣ s = α t α s σ t ∣ s 2 = σ t 2 − α t ∣ s 2 σ s 2 q(x_t|x_s)=N(x_t|\alpha_{t|s}x_s,\sigma^2_{t|s}I) \\ \alpha_{t|s}=\frac {\alpha_t} {\alpha_s} \\ \sigma^2_{t|s}=\sigma^2_t-\alpha^2_{t|s}\sigma^2_s q(xt∣xs)=N(xt∣αt∣sxs,σt∣s2I)αt∣s=αsαtσt∣s2=σt2−αt∣s2σs2
去噪DM本质上是生成模型 p ( x 0 ) p(x_0) p(x0),其类似逆向马尔科夫过程,即可定义为:
p ( x 0 ) = ∫ z p ( x T ) ∏ t = 1 T p ( x t − 1 ∣ x t ) p(x_0)=\int_zp(x_T)\prod^T_{t=1}p(x_{t-1}|x_t) p(x0)=∫zp(xT)t=1∏Tp(xt−1∣xt)
与该模型相关的证据下界(ELBO)在离散时间步长上可分解为:
− log p ( x 0 ) ≤ K L ( q ( x T ∣ x 0 ) ∣ p ( x T ) ) + ∑ t = 1 T E q ( x t ∣ x 0 ) K L ( q ( x t − 1 ∣ x t , x 0 ) ∣ p ( x t − 1 ∣ x t ) ) -\log p(x_0)\le \mathbb{KL}(q(x_T|x_0)|p(x_T))+\sum^T_{t=1} \mathbb{E}_{q(x_t|x_0)}\mathbb{KL}(q(x_{t-1}|x_t,x_0)|p(x_{t-1}|x_t)) −logp(x0)≤KL(q(xT∣x0)∣p(xT))+t=1∑TEq(xt∣x0)KL(q(xt−1∣xt,x0)∣p(xt−1∣xt))
先验 p ( x T ) p(x_T) p(xT)通常被定义为标准的正态分布,故ELBO的第一项只依赖于最终的信噪比 S N R ( T ) SNR(T) SNR(T)。此时目标为最小化其余项,故采用变分推断使参数化的 q ( x t − 1 ∣ x t , x 0 ) q(x_{t−1}|x_t,x_0) q(xt−1∣xt,x0)接近 p ( x t − 1 ∣ x t ) p(x_{t−1}|x_t) p(xt−1∣xt)。其中,未知项 x 0 x_0 x0由基于当前步骤 x t x_t xt的估计值 x θ ( x t , t ) x_θ(x_t,t) xθ(xt,t)替代,则有:
p ( x t − 1 ∣ x t ) : = q ( x t − 1 ∣ x t , x θ ( x t , t ) ) = N ( x t − 1 ∣ μ θ ( x t , t ) , σ t ∣ t − 1 2 σ t − 1 2 σ t 2 I ) σ t − 1 ∣ t 2 = σ t ∣ t − 1 2 σ t − 1 2 σ t 2 p(x_{t-1}|x_t):=q(x_{t-1}|x_t,x_{\theta}(x_t,t)) =N(x_{t-1}|\mu_{\theta}(x_t,t),\sigma^2_{t|t-1} \frac {\sigma^2_{t-1}} {\sigma^2_t}I) \\ \sigma^2_{t-1|t} = \sigma^2_{t|t-1} \frac {\sigma^2_{t-1}} {\sigma^2_t} p(xt−1∣xt):=q(xt−1∣xt,xθ(xt,t))=N(xt−1∣μθ(xt,t),σt∣t−12σt2σt−12I)σt−1∣t2=σt∣t−12σt2σt−12
其中均值为:
μ θ ( x t , t ) = α t ∣ t − 1 σ t − 1 2 σ t 2 x t + α t − 1 σ t ∣ t − 1 2 σ t 2 x θ ( x t , t ) = α t ∣ t − 1 σ t ∣ t − 1 2 x t + α t − 1 σ t − 1 2 x θ ( x t , t ) \mu_{\theta}(x_t,t)=\frac {\alpha_{t|t-1}\sigma^2_{t-1}} {\sigma^2_t}x_t+ \frac {\alpha_{t-1}\sigma^2_{t|t-1}} {\sigma^2_t}x_{\theta}(x_t,t) \\ =\frac {\alpha_{t|t-1}} {\sigma^2_{t|t-1}}x_t+ \frac {\alpha_{t-1}} {\sigma^2_{t-1}}x_{\theta}(x_t,t) μθ(xt,t)=σt2αt∣t−1σt−12xt+σt2αt−1σt∣t−12xθ(xt,t)=σt∣t−12αt∣t−1xt+σt−12αt−1xθ(xt,t)
则ELBO的总和简化为:
∑ t = 1 T E q ( x t ∣ x 0 ) K L ( q ( x t − 1 ∣ x t , x 0 ) ∣ p ( x t − 1 ) ) = ∑ t = 1 T E N ( ϵ ∣ 0 , I ) 1 2 ( S N R ( t − 1 ) − S N R ( t ) ) ∣ ∣ x 0 − x θ ( α t x 0 + σ t ϵ , t ) ∣ ∣ 2 \sum^T_{t=1} \mathbb{E}_{q(x_t|x_0)}\mathbb{KL}(q(x_{t-1}|x_t,x_0)|p(x_{t-1})) \\ =\sum^T_{t=1}\mathbb{E}_{N(\epsilon|0,I)} \frac 1 2(SNR(t-1)-SNR(t))||x_0-x_\theta(\alpha_tx_0+\sigma_t\epsilon,t)||^2 t=1∑TEq(xt∣x0)KL(q(xt−1∣xt,x0)∣p(xt−1))=t=1∑TEN(ϵ∣0,I)21(SNR(t−1)−SNR(t))∣∣x0−xθ(αtx0+σtϵ,t)∣∣2
使用重参化有:
ϵ θ ( x t , t ) = ( x t − α t x θ ( x t , t ) ) / σ t \epsilon_{\theta}(x_t,t)=(x_t-\alpha_tx_{\theta}(x_t,t))/\sigma_t ϵθ(xt,t)=(xt−αtxθ(xt,t))/σt
则可将重建目标表达为一个去噪目标为:
∣ ∣ x 0 − x θ ( α t x 0 + σ t ϵ , t ) ∣ ∣ 2 = σ t 2 α t 2 ∣ ∣ ϵ − ϵ θ ( α t x 0 + σ t ϵ , t ) ∣ ∣ 2 ||x_0-x_{\theta}(\alpha_tx_0+\sigma_t\epsilon,t)||^2=\frac {\sigma^2_t} {\alpha^2_t}||\epsilon-\epsilon_{\theta}(\alpha_tx_0+\sigma_t\epsilon,t)||^2 ∣∣x0−xθ(αtx0+σtϵ,t)∣∣2=αt2σt2∣∣ϵ−ϵθ(αtx0+σtϵ,t)∣∣2
最终的DM优化目标为:
L D M = E x , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] L_{DM}=\mathbb{E}_{x,\epsilon\sim N(0,1),t}[||\epsilon-\epsilon_\theta(x_t,t)||^2_2] LDM=Ex,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22]
Image Guiding Mechanisms
DM的一个特点是,无条件模型可以在测试时被设置条件。故可以采用一个分类器 log p Φ ( y ∣ z t ) \log p_{\Phi}(y|z_t) logpΦ(y∣zt)来指导在ImageNet数据集上训练的无条件和有条件DM,该分类器在diffusion过程的每个 x t x_t xt上训练。故对具有固定方差的 ϵ \epsilon ϵ,可以给定分类条件指导算法:
ϵ ^ ← ϵ θ ( z t , t ) + 1 − α t 2 ∇ z t log p Φ ( y ∣ z t ) \hat\epsilon\gets\epsilon_{\theta}(z_t,t)+\sqrt {1-\alpha^2_t}\nabla_{z_t} \log p_{\Phi}(y|z_t) ϵ^←ϵθ(zt,t)+1−αt2∇ztlogpΦ(y∣zt)
可以解释为用条件分布 log p Φ ( y ∣ z t ) \log p_{\Phi}(y|z_t) logpΦ(y∣zt) 修正 ϵ θ \epsilon_{\theta} ϵθ。
也可以将引导分布 p Φ ( y ∣ T ( D ( z 0 ( z t ) ) ) ) p_{\Phi}(y|T(D(z_0(z_t)))) pΦ(y∣T(D(z0(zt))))解释为一个通用的图像到图像任务,给定一个目标图像 y y y,设 T T T为任意的图像到图像的任务所采用的微调变换,如identity、下采样等。 若给定一个固定方差为 σ 2 = 1 \sigma^2=1 σ2=1 的高斯导数,则:
log p Φ ( y ∣ z t ) = − 1 2 ∣ ∣ y − T ( D ( z 0 ( z t ) ) ) ∣ ∣ 2 2 \log p_{\Phi}(y|z_t)=-\frac 1 2||y-T(D(z_0(z_t)))||^2_2 logpΦ(y∣zt)=−21∣∣y−T(D(z0(zt)))∣∣22
可成为一个 L 2 L_2 L2回归目标。

上图为这种机制下训练的模型的生成示例。
Additional Results
Choosing the Signal-to-Noise Ratio for High-Resolution Synthesis
潜空间方差( V a r ( z ) / σ t 2 Var(z)/σ^2_t Var(z)/σt2)产生的信噪比会显著影响卷积采样的结果。例如,当直接在KL正则化模型的潜空间中训练LDM时,会产生高信噪比,这样模型在反向去噪过程的早期就会分配到大量的图像语义细节;当按照潜空间的分量标准偏差重新缩放潜空间时,信噪比会降低。
上图为不同正则化潜空间的景观模型生成结果,因为VQ正则化空间的方差接近于1,因此其潜向量不必重新缩放。
Full List of all First Stage Models
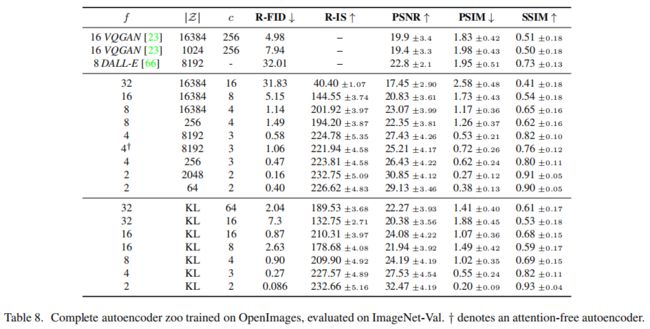
上表提供了在OpenImages数据集上训练的各种自编码器的详细信息。
Layout-to-Image Synthesis
本节提供基于语义布局(semantic layouts)的图像合成模型额外的定量评估结果,实验在COCO和OpenImages数据集上训练一个模型,随后在COCO上进行了额外的微调。

上表显示了结果。观察到,LDM-4模型达到了最近在布局到图像合成方面最先进的性能。
上图展示了在COCO上微调的模型生成的其他样本。
Class-Conditional Image Synthesis on ImageNet

上表包含了用FID和Inception评分(IS)测量的类别条件LDM的结果。其中,LDM-8的参数和计算量相比其他模型明显更少,同时实现了非常有竞争力的性能。与之前的工作类似,通过在每个噪声级别上训练一个分类器并对LDM进行指导来进一步提高性能,与基于像素的方法不同,该分类器在潜空间中训练的成本非常低。
上两图为其余定性结果,显示了ImageNet数据集上训练的LDM-4生成的不同类别的图像。
Sample Quality vs. V100 Days
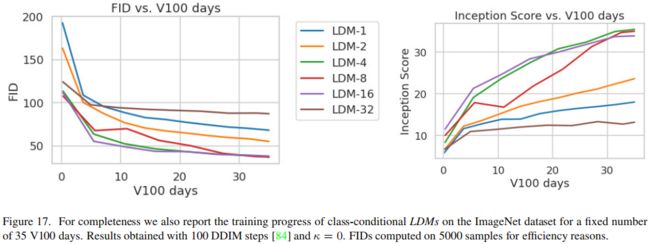
上表显示了在不同训练步骤下,LDM的FID和IS分数分布情况。
Super-Resolution

为了使超分辨率任务下的LDM和DM在像素空间中具有更好的可比性,本实验将经过相同step训练的DM与LDM进行了比较,两者具有相同的参数量。结果如上图最后两行,表明了LDM实现了更好的性能,同时具有更快的生成速度。
上图为定性比较结果,显示了来自LDM和基于像素空间的DM的随机生成样本。
LDM-BSR: General Purpose SR Model via Diverse Image Degradation
为了评估LDM-SR的泛化性,将其应用于来自ImageNet训练的类别条件LDM模型的合成样本和从互联网抓取的图像。观察到,只使用中的双三次下采样条件训练的LDM-SR,不能很好地推广到没有遵循这种预处理的图像。因此,为了获得泛化的真实世界图像的超分辨率模型,采用经过调整的BSR退化管道取代了LDM-SR中的双三次下采样操作。BSR退化过程会将JPEG压缩噪声、相机传感器噪声、不同的图像下采样插值、高斯模糊核和高斯噪声以随机顺序应用于图像的退化流水线。

上图直接比较LDM-SR和LDM-BSR。观察到,后者产生的图像比LDM-SR清晰得多,其更适合于现实世界的应用。
上图为LDM-BSR的进一步结果。
Implementation Details and Hyperparameters
Hyperparameters
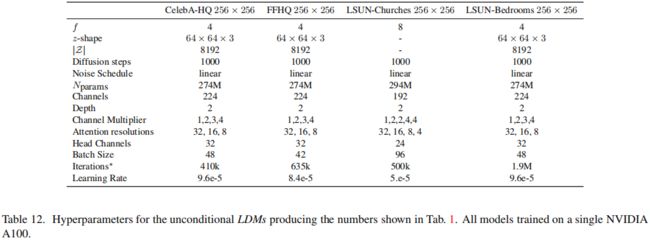


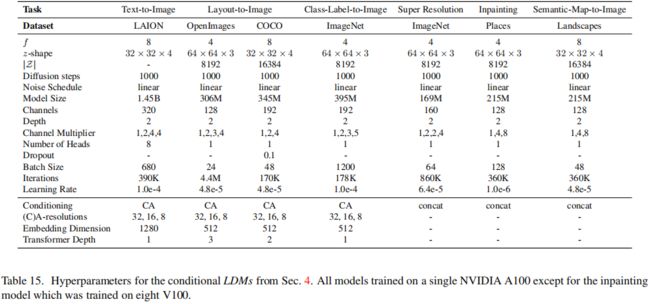
上列表提供了本文所有训练过的LDM模型的超参数的概述。
Implementation Details
Implementations of τ θ τ_θ τθ for conditional LDMs
对于文本到图像和布局到图像合成的LDM模型,对应的条件模型 τ θ τ_θ τθ为一个无掩码transformer,其会将tokenized的输入 y y y转换为输出 ζ : = τ θ ( y ) ζ:=τ_θ(y) ζ:=τθ(y),其中 ζ ∈ R M × d τ ζ∈\R^{M×d_τ} ζ∈RM×dτ。其中,transformer由N个transformer块组成,每个transformer块由全局自注意力层、层归一化和mlp组成,具体如下:
ζ ← T o k E m b ( y ) + P o s E m b ( y ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ\gets TokEmb(y)+PosEmb(y) ζ←TokEmb(y)+PosEmb(y)
f o r i = 1 , … , N : ζ 1 ← L a y e r N o r m ( ζ ) ζ 2 ← M u l t i H e a d S e l f A t t e n t i o n ( ζ 1 ) + ζ ζ 3 ← L a y e r N o r m ( ζ 2 ) ζ ← M L P ( ζ 3 ) + ζ 2 ζ ← L a y e r N o r m ( ζ ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ for \ i=1,\dots,N: \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ_1\gets LayerNorm(ζ) \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ_2\gets MultiHeadSelfAttention(ζ_1)+ζ \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ_3\gets LayerNorm(ζ_2) \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ\gets MLP(ζ_3)+ζ_2 \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ ζ\gets LayerNorm(ζ) for i=1,…,N: ζ1←LayerNorm(ζ) ζ2←MultiHeadSelfAttention(ζ1)+ζ ζ3←LayerNorm(ζ2) ζ←MLP(ζ3)+ζ2 ζ←LayerNorm(ζ)
条件 ζ ζ ζ会通过交叉注意机制映射到UNet中,映射模块定义为“ablated UNet”。

“ablated UNet”的详细配置如上表。
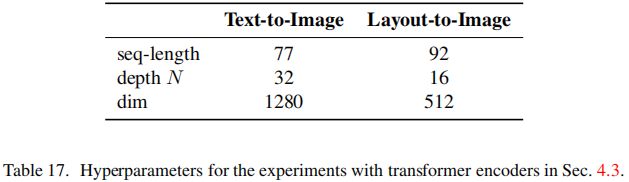
对于文本到图像模型,本文采样一个公开可用的tokenizer。布局到图像模型离散化了边界框的空间位置,每个框都会编码为一个 ( l , b , c ) (l,b,c) (l,b,c)元组,其中 l l l表示左上角, b b b表示右下角, c c c为类别信息。上述两个任务中,UNet的超参数如上表。
另外,本文提供的类别条件模型也通过交叉注意力实现,其中 τ θ τ_θ τθ是一个维度为512的可学习嵌入层,其会将类 y y y映射到 ζ ∈ R 1 × 512 ζ∈\R^{1×512} ζ∈R1×512。
Inpainting
本文的图像绘画实验使用了LaMa的部分代码来生成mask区域,并使用了Places中的2k个验证样本和的30k个测试样本的固定集合。训练期间使用大小为 256 × 256 256×256 256×256的random crops图像,评估期间使用大小为为 512 × 512 512×512 512×512的random crops图像,并遵循LaMa的训练和测试方案。
上图为LDM-4 w/attn的附加定性结果。
上图为LDM-4 w/o attn、big,w/ft的附加定性结果。
Computational Requirements

上表提供了对LDM使用的计算资源的更详细的分析,并将在CelebA-HQ、FFHQ、LSUN和ImageNet数据集上的最佳LDM模型与以往最先进模型进行了比较。观察到LDM在显著减少所需的计算资源的情况下,性能接近于StyleGAN2和ADM等最先进方法。
Details on Autoencoder Models
本文采用对抗性(adversarial)方式训练自编码器模型,通过优化一个基于patch的判别器 D ψ D_{\psi} Dψ,来区分原始图像和重建(reconstructions) D ( E ( x ) ) D(E(x)) D(E(x))。为了避免潜空间的任意缩放,引入了正则化损失项,使潜表示 z z z服从零中心,小方差。
本文研究了两种不同的正则化(regularization)方法:
- 标准变分自编码器中采用的 q E ( z ∣ x ) = N ( z ; E μ , E σ 2 ) q_E(z|x)=N(z;E_μ,E_{\sigma^2}) qE(z∣x)=N(z;Eμ,Eσ2)和标准正态分布 N ( z ; 0 , 1 ) N(z;0,1) N(z;0,1)之间的低权重KL散度
- 以及通过一个可学习的codebook ∣ Z ∣ |Z| ∣Z∣,采用矢量量化层正则化潜空间
为了获得高保真重建,两种情况都使用非常小的正则化,即要么将KL项按因子 1 0 − 6 10^{-6} 10−6加权,要么选择一个高维度codebook ∣ Z ∣ |Z| ∣Z∣。自编码模型 ( E , D ) (E,D) (E,D)的完整训练目标如下:
L A u t o e n c o d e r = min E , D max ψ ( L r e c ( x , D ( E ( x ) ) ) − L a d v ( D ( E ( x ) ) ) + log D ψ ( x ) + L r e g ( x ; E , D ) ) L_{Autoencoder}=\min_{ E,D} \ \max_{\psi}(L_{rec}(x,D( E(x)))-L_{adv}(D( E(x)))+\log D_{\psi}(x)+L_{reg}(x;E,D)) LAutoencoder=E,Dmin ψmax(Lrec(x,D(E(x)))−Ladv(D(E(x)))+logDψ(x)+Lreg(x;E,D))
其中 L r e c L_{rec} Lrec为重建损失, L a d v L_{adv} Ladv为对抗性损失, log D ψ ( x ) \log D_{\psi}(x) logDψ(x)为判别器损失, L r e g L_{reg} Lreg为正则化损失。
DM Training in Latent Space
对于在潜空间上学习训练的DM,对不同的潜空间正则化方法,对应不同的方法来学习 p ( z ) p(z) p(z)或 p ( z ∣ y ) p(z|y) p(z∣y):
- 对于KL正则化的潜空间,其输出 z = E μ ( x ) + E σ ( x ) ⋅ ε = : E ( x ) z=E_{\mu}(x)+E_{\sigma}(x)\cdotε=:E(x) z=Eμ(x)+Eσ(x)⋅ε=:E(x),其中 ε ∼ N ( 0 , 1 ) ε\sim N(0,1) ε∼N(0,1)。当重新缩放潜空间时,方差估计为: σ ^ 2 = 1 b c h w ∑ b , c , h , w ( z b , c , h , w − μ ^ ) 2 \hat\sigma^2=\frac 1 {bchw} \sum_{b,c,h,w}(z^{b,c,h,w}-\hat\mu)^2 σ^2=bchw1∑b,c,h,w(zb,c,h,w−μ^)2,其中 μ ^ = 1 b c h w ∑ b , c , h , w z b , c , h , w \hat\mu=\frac 1 {bchw} \textstyle\sum_{b,c,h,w}z^{b,c,h,w} μ^=bchw1∑b,c,h,wzb,c,h,w。该步骤中, E E E的输出会被缩放,重新缩放的潜表示具有单位标准偏差,即 z ← z σ ^ = E ( x ) σ ^ z\gets \frac z {\hat\sigma}=\frac {E(x)} {\hat\sigma} z←σ^z=σ^E(x)。
- 对于VQ正则化的潜空间,本文在量化层之前提取 z z z,并将量化操作吸收到解码器中。即该正则化为解码器 D D D的第一层。
Additional Qualitative Results
下列为本文训练的景观模型(语义合成)、无条件模型(CelebA-HQ、FFHQ和LSUN数据集)提供的额外定性结果。

reference
Rombach, R. , Blattmann, A. , Lorenz, D. , Esser, P. , & Ommer, B. . (2021). High-resolution image synthesis with latent diffusion models.