【自然语言处理】实验3,文本情感分析
清华大学驭风计划课程链接
学堂在线 - 精品在线课程学习平台 (xuetangx.com)
代码和报告均为本人自己实现(实验满分),只展示主要任务实验结果,如果需要详细的实验报告或者代码可以私聊博主
有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~
案例简介

情感分析旨在挖掘文本中的主观信息,它是自然语言处理中的经典任务。在本次任务中,我们将在影评 文本数据集(Rotten Tomato)上进行情感分析,通过实现课堂讲授的模型方法,深刻体会自然语言处 理技术在生活中的应用。 同学们需要实现自己的情感分析器,包括特征提取器(可以选择词袋模型、词向量模型和预训练模 型)、简单的线性分类器以及梯度下降函数。随后在数据集上进行训练和验证。我们提供了代码框架, 同学们只需补全 model.py 中的两个函数。
数据说明
我们使用来自Rotten Tomato的影评文本数据。其中训练集 data_rt.train 和测试集 data_rt.test 均 包含了3554条影评,每条影评包含了文本和情感标签。示例如下:
![]()
其中, +1 表示这条影评蕴涵了正面感情,后面是影评的具体内容。
文本特征提取
TODO:补全 featureExtractor 函数 在这个步骤中,同学们需要读取给定的训练和测试数据集,并提取出文本中的特征,输出特征向量。同学们需要实现词袋模型、词向量模型和预训练模型(选做)来生成句子表示,并对比不同方法的表现有何差异。
Bag of Words得到句子的0-1向量(选做:用TFIDF计算句子向量)
Word2Vec词向量求和/取平均(选做:实现Doc2Vec[1])
使用BERT得到[CLS]向量/词的隐状态取平均(选做)
训练分类器
TODO:补全 learnPredictor 函数 我们提供的训练数据集中,每句话的标签在文本之前,其中 +1 表示这句话蕴涵了正面感情, -1 表示这 句话蕴涵了负面感情。因此情感分析问题就成为一个分类问题。

同学们需要实现一个简单的线性分类器,并推导出相应的梯度下降函数。
实验与结果分析
在训练集上完成训练后,同学们需要在测试集上测试分类器性能。本小节要求同学们画出训练集上的损 失函数下降曲线和测试集的最终结果(损失函数、准确率),并对结果进行分析。
评分要求
同学们需要提交源代码和实验报告。实验报告中应包含以下内容: 对hinge loss反向传播的理论推导,请写出参数的更新公式。 对实验结果的分析,请描述采用的模型结构、模型在训练集上的损失函数下降曲线和测试集的最终 结果,并对结果进行分析。分析可以从模型的泛化能力、参数对模型性能的影响以及不同特征的影 响等方面进行。
[1] Distributed Representations of Sentences and Documents. https://arxiv.org/pdf/1405.4053.pdf
实验结果
1,反向传播推导

2,文本特征提取
2.1 使用 BOW 作为特征
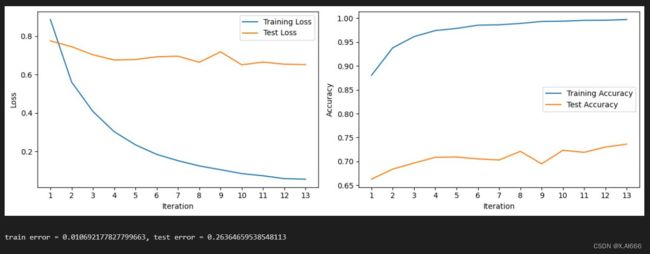
2.2 使用 N-gram 作为特征
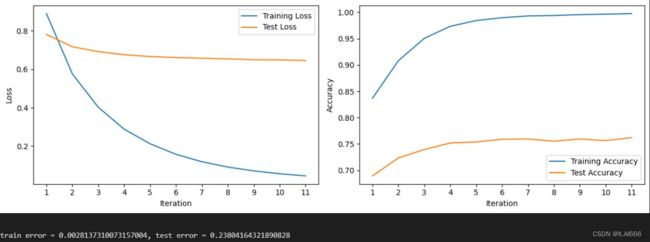 从图中可以看出 loss 曲线不管是训练还是训练的 loss 都在下降,跟前面的情况类似,也是训练的 loss 下降很快,而测试的 loss 下降较为平缓。从准确率图来看训练的也几乎饱满,测试也是随着周期变大达到最高,最终 test 的错误值为 0.238,达到新低。可以看出我们调参的方法非常有效,通过对多个学习率的运行,找出了对于每个级别的最佳超参数,并且精准把控训练轮数达到最优结果。
从图中可以看出 loss 曲线不管是训练还是训练的 loss 都在下降,跟前面的情况类似,也是训练的 loss 下降很快,而测试的 loss 下降较为平缓。从准确率图来看训练的也几乎饱满,测试也是随着周期变大达到最高,最终 test 的错误值为 0.238,达到新低。可以看出我们调参的方法非常有效,通过对多个学习率的运行,找出了对于每个级别的最佳超参数,并且精准把控训练轮数达到最优结果。
2.3 使用 BERT 得到[CLS]向量作为特征
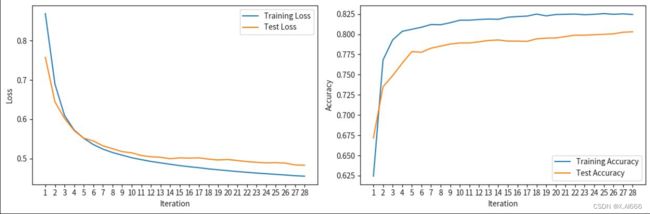
3,总结三种方法对比差异:
这三种方法使用了不同的特征提取方式,导致最终结果的差异。让我详细解释一下可能的区别和影响。