原文链接 包教包会的Kotlin Flow教程 公众号「稀有猿诉」
Kotlin中的Flow是专门用于处理异步数据流的API,是函数响应式编程范式(Functional Reactive Programming FRP)在Kotlin上的一个实现,并且深度融合了Kotlin的协程。是Kotlin中处理异步数据流问题的首先方案。今天就来认识一下Flow并学会如何使用它。

Hello, Flow!
老规矩,新学习一个新东西的时候,总是要从一个基础的『Hello, world』开始,快速上手体验,有个第一印象。我们就从一个简单的『Hello, Flow!』开始Flow之旅:
fun main() = runBlocking {
val simple = flow {
listOf("Hello", "world", "of", "flows!")
.forEach {
delay(100)
emit(it)
}
}
simple.collect {
println(it)
}
}
//Hello
//world
//of
//flows!这里创建了一个异步产生String的数据流Flow
可以看出Flow本质上是一个生产者消费者模式,流出的数据是由生产者产生的,且最终被消费者消费掉。可以把Flow想像成为一个生产线中的传送带,产品(数据)在上面不停的流动,经过各个站点的加工,最终成型,由消费者消费掉。从这个小例子中可以看出Flow API的三要素:数据流的上游是创建Flow(生产者);中游是变幻操作(数据的处理和加工);下游是收集数据(消费者),我们一一的详细来学习。
创建Flow
Flow是一个生产者,创建Flow也就是把数据放到传送带上。数据可以是基础数据或者集合,也可以是其他方式生成的数据,如网络或者回调或者硬件。创建Flow的API称作flow builder函数。
用集合创建Flow
这是创建Flow的最简单的方式,有两个,一个是flowOf用于从固定数量的元素创建,多用于示例,实际中基本上用不到:
val simple = flowOf("Hello", "world", "of", "flows!")
simple.collect { println(it) }或者,通过asFlow把现有的集合转为Flow,这个还是比较实用的:
listOf("Hello", "world", "of", "flows!").asFlow()
.collect { println(it) }
(1..5).asFlow().collect { println(it) }通用flow builder
最为通用的flow builder就是flow {...}了,这是最为通用,也是最为常用的构造器。在代码块中调用emit就可以了,这个代码块会运行在协程之中,所以在这个代码里可以调用suspend函数:
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.collect { println(it) }
}
//Emitting: 1
//1
//Emitting: 2
//2
//Emitting: 3
//3这是一个代码块,只要调用了emit产生数据即可,又可调用suspend函数,因此非常的实用,比如可以执行网络请求,请求回来后emit等等。
终端操作符
数据从生产者流出,直到消费者把数据收集起来进行消费,而只有数据被消费了才有意义。因此,还需要终端操作(Terminal flow operators)。需要注意的是终端操作符是Flow的终点,并不算是Flow传送带内部,因此终端操作都是suspend函数,调用者需要负责创建协程以正常调用这些suspending terminal operators。

常见的终端操作有三个:
- collect 最为通用的,可执行一个代码块,参数就是Flow流出的数据
- 转换为集合Collections,如toList和toSet等,可以方便把收集到的数据转换为集合
- 取特定的值,如first()只取第一个,last只取最后一个, single只要一个数据(无数据和超过一个数据时都会抛异常。
- 降维(或者叫作聚合accumulate)操作,如折叠fold和化约reduce,折叠和化约可以对数据流进行降维,如求和,求积,求最大值最小值等等。
- count 其实也是降维的一种,返回数据流中的数据个数,它还可以结合过滤以计算某种过滤条件后的数据数量。
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.collect { println(it) }
println("toList: ${simple.toList()}")
println("first: ${simple.first()}")
println("sum by fold: ${simple.fold(0) { s, a -> s + a }}")
}输出:
Emitting: 1
1
Emitting: 2
2
Emitting: 3
3
Emitting: 1
Emitting: 2
Emitting: 3
toList: [1, 2, 3]
Emitting: 1
first: 1
Emitting: 1
Emitting: 2
Emitting: 3
sum by fold: 6这些终端操作符都简单,比较好理解,看一眼示例就知道怎么用了。需要注意的就是first()和single(),first是只接收数据流中的第一个,而single则要求数据流只能有一个数据(没有或者超过一个都会抛异常)。比较有意思就是last(),数据流是一个流,一个产品传送带,通常情况下都是指无限或者说不确定数据 数量时才叫数据流,那又何来最后一个数据呢?通常情况下last都是无意义的。只有当我们知道流的生产者只生产有限数量数据时,或者采用了一些限制性的变幻操作符时,last才能派上用场。
再有就是注意fold和reduce的区别,这里它们的区别跟集合上的操作是一样的,fold可以提供初始值,流为空时返回初始值;而reduce没初始值,流为空时会抛异常。
变幻操作符
数据在流动的过程中可以对数据进行转化操作,从一种数据类型变别另外一种,这就是变幻(Transformation),这是数据流最为灵活和强大的一个方面。这跟集合的变幻是类似的。
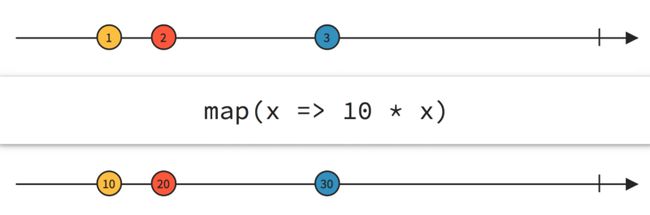
转换
最常见的变幻就是转换,也就是把从一种数据类型转换为另一种数据类型,用的最多当然是map,还有更为通用的transform。它们都能把数据流中的数据从一种类型转换为另一种类型,比如把Flow
fun main() = runBlocking {
val simple = flow {
for (i in 1..3) {
delay(100)
println("Emitting: $i")
emit(i)
}
}
simple.map { " Mapping to ${it * it}" }
.collect { println(it) }
simple.transform { req ->
emit(" Making request $req")
emit(performRequest(req))
}.collect {
println(it)
}
}
fun performRequest(req: Int) = "Response for $req"输出是:
Emitting: 1
Mapping to 1
Emitting: 2
Mapping to 4
Emitting: 3
Mapping to 9
Emitting: 1
Making request 1
Response for 1
Emitting: 2
Making request 2
Response for 2
Emitting: 3
Making request 3
Response for 3还有一个操作符withIndex它与集合中的mapIndexed是类似的,它的作用是把元素变成IndexedValue,这样在后面就可以得到元素和元素的索引 了,在某些场景下还是比较方便的。
限制
数据流里面的数据不一定都是需要的,所以通常需要对数据元素进行过滤,这就是限制性操作符,最常见的就是filter,这里与集合的限制操作也是类似的:
- filter 把数据转为布尔型,从而对数据流进行过滤。
- distinctUntilChanged 过滤数据流中重复的元素。
- drop 丢弃前面一定数量的元素。
- take 只返回流中前面一定数量的元素,当数量达到时流将被取消,注意take与drop是相反的。
- debounce 仅保留流中一定超时间隔内的元素,比如超时时间是1秒,那只返回到达1秒时最新的元素,这个元素前面的将被丢弃。这个在秒杀场景拦截疯狂点击,或者一个服务中拦截疯狂请求时非常有用。只取一定时间间隔内的最新的元素,拦截掉无效数据。
- sample 以一定的时间间隔取元素,与debounce差不多,区别在于debounce会返回最后一个元素,而sample不一定,要看间隔最后一个元素能否落在一个时间间隔内。
@OptIn(FlowPreview::class)
fun main() = runBlocking {
val constraint = flow {
emit(1)
delay(90)
emit(2)
delay(90)
emit(3)
delay(1010)
emit(4)
delay(1010)
emit(5)
}
constraint.filter { it % 2 == 0 }
.collect { println("filter: $it") }
constraint.drop(3)
.collect { println("drop(3): $it") }
constraint.take(3)
.collect { println("take(3): $it") }
constraint.debounce(1000)
.collect { println("debounce(1000): $it") }
constraint.sample(1000)
.collect { println("sample(1000): $it") }
}仔细看它们的输出,以理解它们的作用:
filter: 2
filter: 4
drop(3): 4
drop(3): 5
take(3): 1
take(3): 2
take(3): 3
debounce(1000): 3
debounce(1000): 4
debounce(1000): 5
sample(1000): 3
sample(1000): 4需要留意,debounce和sample是Preview的API,需要加上Preview注解。
中游的变幻操作符仍属于流的一部分,它们都仍运行在Flow的上下文中,因此,这些操作符内,与流的builder一样,都可以直接调用其他的supsend函数,甚至是其他的耗时的,阻塞的函数都可以调用。并不需要特别的为上游和中游创建上下文。
Flow的操作符特别多,我们需要留意区别中游操作符和下游终端。看这些函数的返回类型就可以了,返回类型是具体数据的,一定是下游终端操作符;而对于上游生产者和中游变幻操作符,其返回值一定是一个Flow。
高级操作符
前面讲的操作符都是针对 某一个流本身的,但大多数场景一个流明显不够用啊,我们需要操作多个流,这时就需要用到一些高级操作符了。
合并多路流
多路流不可能一个一个的处理,合并成为一路流更加的方便,有以下合并方法:
- 归并merge把数据类型相同的多路流归并为一路,注意一定是数据类型相同的才可以归并,并且归并后的元素顺序是未知的,也即不会保留原各路流的元素顺序。归并流的数量没有限制。
- 粘合zip 当想要把两路流的元素对齐后粘合为一个元素时,就可以使用zip,当任何一个流结束或者被取消时,zip也就结束了。只能两个两个的粘合。
- 组合combine把多路流中的每个流的最新元素粘合成新数据,形成一个新的流,其元素是把每个元素都用每路流的最新元素来转换生成。最少需要2路流,最多支持5路流。
用一个来感受一下它们的作用:
fun main() = runBlocking {
val one = flowOf(1, 2, 3)
.map(Int::toString)
.onEach { delay(10) }
val two = flowOf("a", "b", "c", "d")
.onEach { delay(25) }
merge(one, two)
.collect { println("Merge: $it") }
one.zip(two) { i, s -> "Zip: $i. $s" }
.collect { println(it) }
combine(one, two) { i, s -> "Combine $i with $s" }
.collect { println(it) }
}这里是输出:
Merge: 1
Merge: 2
Merge: a
Merge: 3
Merge: b
Merge: c
Merge: d
Zip: 1. a
Zip: 2. b
Zip: 3. c
Combine 2 with a
Combine 3 with a
Combine 3 with b
Combine 3 with c
Combine 3 with d通过它们的输出可以看到它们的区别:merge就像把两个水管接到一样,简单没有多余加工,适合数据类型一样的流(比如都是水);zip会对齐两路流,让能对齐的元素两两结合,对不齐时就结束了。
而combine要等到集齐每路流的最新元素,才能转换成新数据,two是较one慢的,看到two的元素『a』时,one最新的元素是『2』,之后one的『3』来了,这时two最新的元素还是『a』,之后one停在了『3』,后续two的元素都与『3』组合。有同学可能会有疑问,为啥one的『1』丢弃了,没找到组合呢?因为它来的太早了,one的『1』来了时,two还没有元素,它肯定会等,但当two的第一个元素『a』来了时,这时one的最新元素已是『2』了,one是10发一个元素,two是隔25发一个元素,所以two的第1个元素到了时,one的第2个元素已经来了,它是最新的,所以组合时会用它。combine要集齐每路流的最新元素才能合成。
总结起来就是,zip会按顺序对齐元素;而combine要集齐每路流的最新元素,先要集齐,齐了时还要取每个流的最新元素。可以动手运行示例,修改delay的时间,看输出有啥不一样的,以加深理解。
展平(Flatten)
一个Flow就是一个异步数据流,它相当于一个传送带或者管道,货物(具体的数据)在其上面或者里面流动。正常情况下Flow内部都是常规数据(对象)在流动,但Flow本身也是一个对象,因此也可以嵌套,把流当成另一个流的数据,比如Flow
直接展平
最直观的展平莫过于对于已经是嵌套的Flow of Flows做展平处理,以能让终端操作符正常的消费Flow里面的数据,有两个API可以做展平:
- flattenConcat 把嵌套的Flow of Flows展平为一个Flow,内层的每个流都是按顺序拼接在一起的,串行拼接。比如Flow of 4 Flows,内层有四个管道,那就就变成了『内层1』->『内层2』->『内层3』->『内层4』。
- flattenMerge 把Flow of Flows展平为一个Flow,内层的所有Flow是以并发的方式将元素混合流入新管道,是并发式混合,相当于四个管道同时往另一个管道倒水,原流中的顺序会错乱掉。
@OptIn(ExperimentalCoroutinesApi::class)
fun main() = runBlocking {
val flow2D = flowOf("Hello", "world", "of", "flow!")
.map { it.toCharArray().map { c -> " '$c' " }.asFlow() }
.flowOn(Dispatchers.Default)
flow2D.collect { println("Flow object before flatten: $it") } // Data in flow are Flow objects
println("With flattenConcat:")
flow2D.flattenConcat()
.collect { print(it) }
println("\nWith flattenMerge:")
flow2D.flattenMerge()
.collect { print(it) }
}
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@1b0375b3
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@e580929
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@1cd072a9
//Flow object before flatten: kotlinx.coroutines.flow.FlowKt__BuildersKt$asFlow$$inlined$unsafeFlow$3@7c75222b
//With flattenConcat:
//'H' 'e' 'l' 'l' 'o' 'w' 'o' 'r' 'l' 'd' 'o' 'f' 'f' 'l' 'o' 'w' '!'
//With flattenMerge:
// 'H' 'e' 'l' 'l' 'o' 'w' 'o' 'r' 'l' 'd' 'o' 'f' 'f' 'l' 'o' 'w' '!'从输出中可以看出,如果不展平Flow里面是Flow对象,没法用。flattenConcat是把内层的流串行的接在一起。但flattenMerge的输出似乎与文档描述不太一致,并没有并发式的混合。
先转换再展平

大多数时候并没有现成的嵌套好的Flow of Flows给你展平,更多的时候是我们需要自己把元素转换为一个Flow,先生成Flow of Flows,然后再展平,且有定义好的API可以直接用:
- flatMapConcat 先把Flow中的数据做变幻,这个变幻必须从元素变成另一个Flow,这时就变成了嵌套式的Flow of Flows,然后再串行式展平为一个Flow。
- flatMapLatest 先把Flow中的最新数据做变幻,这个变幻必须从元素变成另一个Flow,这时会取消掉之前转换生成的内层流,结果虽然也是嵌套,但内层流只有一个,就是原Flow中最新元素转换生成的那个流。然后再展平,这个其实也不需要真展平,因为内层流只有一个,它里面的数据就是最终展平后的数据。
- flatMapMerge 与flatMapConcat一样,只不过展平的时候嵌套的内层流是以并发的形式来拼接的。
来看个就能明白它们的作用了:
@OptIn(ExperimentalCoroutinesApi::class)
fun main() = runBlocking {
val source = (1..3).asFlow()
.onEach { delay(100) }
println("With flatMapConcat:")
var start = System.currentTimeMillis()
source.flatMapConcat(::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
println("With flatMapMerge:")
start = System.currentTimeMillis()
source.flatMapMerge(4, ::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
println("With flatMapLatest:")
source.flatMapLatest(::requestFlow)
.collect { println("$it at ${System.currentTimeMillis() - start}ms from the start") }
}
fun requestFlow(x: Int): Flow = flow {
emit(" >>[$x]: First: $x")
delay(150)
emit(" >>[$x]: Second: ${x * x}")
delay(200)
emit(" >>[$x]: Third: ${x * x * x}")
} 输出比较多:
With flatMapConcat:
>>[1]: First: 1 at 140ms from the start
>>[1]: Second: 1 at 306ms from the start
>>[1]: Third: 1 at 508ms from the start
>>[2]: First: 2 at 613ms from the start
>>[2]: Second: 4 at 765ms from the start
>>[2]: Third: 8 at 969ms from the start
>>[3]: First: 3 at 1074ms from the start
>>[3]: Second: 9 at 1230ms from the start
>>[3]: Third: 27 at 1432ms from the start
With flatMapMerge:
>>[1]: First: 1 at 130ms from the start
>>[2]: First: 2 at 235ms from the start
>>[1]: Second: 1 at 284ms from the start
>>[3]: First: 3 at 341ms from the start
>>[2]: Second: 4 at 386ms from the start
>>[1]: Third: 1 at 486ms from the start
>>[3]: Second: 9 at 492ms from the start
>>[2]: Third: 8 at 591ms from the start
>>[3]: Third: 27 at 695ms from the start
With flatMapLatest:
>>[1]: First: 1 at 807ms from the start
>>[2]: First: 2 at 915ms from the start
>>[3]: First: 3 at 1021ms from the start
>>[3]: Second: 9 at 1173ms from the start
>>[3]: Third: 27 at 1378ms from the start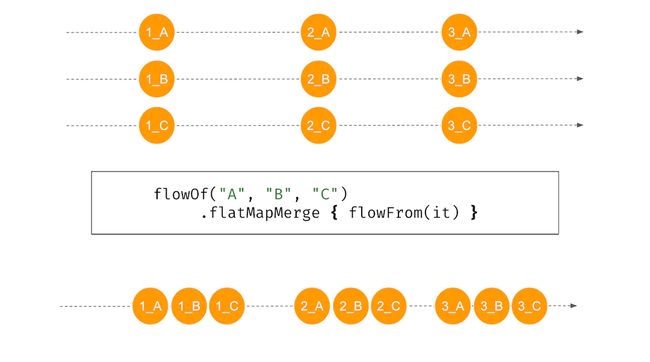
这个示例中原始Flow是一个Int值,把它转换成为一个字符串流Flow
展平的函数比较多容易学杂,其实有一个非常简单的区分方法:带有Map字样的函数就是先把元素转换成Flow之后再展平;带有Concat就是把嵌套内层流串行拼接;而带有Merge的则是把内层流并发式的混合。使用的时候,如果想保证顺序就用带有Concat的函数;想要并发性,想高效一些,并且不在乎元素顺序,那就用带有Merge的函数。
Flow是冷流
对于数据流来说有冷热之分,冷流(Cold stream)是指消费者开始接收数据时,才开始生产数据,换句话说就是生产者消费者整个链路搭建好了后,上游才开始生产数据;热流(Hot stream),与之相反,不管有没有人在消费,都在生产数据。有一个非常形象的比喻就是,冷流就好比CD,你啥时候都可以听,而且只要你播放就从头开始播放CD上所有的音乐;而热流就好比电台广播,不管你听不听,它总是按它的节奏在广播,今天不听,就错过今天的数据了,今天听跟明天听,听到的内容也是不一样的。
Kotlin的Flow是冷流,其实从上面的例子也能看出来,每个例子中都是只创建一个Flow对象,然后有多次collect,但每次collect都能拿到Flow中完整的数据,这就是典型的冷流。绝大多数场景,我们需要的也都是冷流。
扩展阅读Hot and cold data sources。
与ReactiveX的区别
Flow是用于处理异步数据流的API,是函数响应式编程范式FRP的一个实现。但它并不是唯一的,更为流行的RxJava也是符合FRP的异步数据流处理API,它出现的要更早,社区更活跃,资源更丰富,流行程度更高,基本上是每个安卓项目必备的依赖库,同时也是面试必考题。
因为Kotlin是基于JVM的衍生语言,它与Java是互通的,可以混着用。所以RxJava可以直接在Kotlin中使用,无需要任何改动。但毕竟RxJava是原生的Java库,Kotlin中的大量语法糖还是很香的,由此便有了RxKotlin。RxKotlin并不是把ReactiveX规范重新实现一遍,它只是一个轻量的粘合库,通过扩展函数和Kotlin的语法糖等,让RxJava更加的Kotlin友好,在Kotlin中使用RxJava时更加的顺滑。但核心仍是RxJava,如并发的实现仍是用线程。
那么Flow相较RxJava有啥区别呢?区别就在于Flow是纯的Kotlin的东西,它们背后的思想是一样的都是异步数据流,都是FRP,但Flow是原生的,它与Kotlin的特性紧密结合,比如它的并发是用协程通信用的是Channel。使用建议就是,如果本身对RxJava很熟悉,且是遗留代码,那就没有必要去再改成Flow;但如果是新开发的纯新功能,并且不与遗留代码交互,也没有与架构冲突,还是建议直接上Flow。
什么时候用Flow
每一个工具都有它特定的应用场景,Flow虽好,但不可滥用,要以架构的角度来认清问题的本质,符合才可以用。Flow是用于处理异步数据流的API,是FRP范式下的利器。因此,只当核心业务逻辑是由异步数据流驱动的场景时,用Flow才是合适的。现在绝大多数端(前端,客户端和桌面)GUI应用都是响应式的,用户输入了,或者服务器Push了数据,应用做出响应,所以都是符合FRP范式的。那么重点就在于数据流了,如果数据连串成流,就可以用Flow。比如用户输出,点击事件/文字输入等,这并不只发生一次,所以是数据流(事件流)。核心的业务数据,比如新闻列表,商品列表,文章列表,评论列表等都是流,都可以用Flow。配置,设置和数据库的变化也都是流。
但,一个单篇的文章展示,一个商品展示这就不是流,只有一个文章,即使用流,它也只有一个数据,而且我们知道它只有一个数据。这种情况就没有必要用Flow,直接用一个supsend请求就好了。
在Android中使用Flow

安卓开发的官方语言已经变成了Kotlin了,安卓应用也非常符合FRP范式,那么对于涉及异步数据流的场景自然要使用Flow。
扩展阅读:
- What is Flow in Kotlin and how to use it in Android Project?
- Kotlin flows on Android
- Learn Kotlin Flow by real examples for Android
书籍推荐
Flow本身的东西其实并不多,就是三板斧:创建,变幻和终端。但Flow背后的思想是很庞大的,想要用好Flow必须要学会函数响应式编程范式。也就是说只有学会以FRP范式来构建软件时,才能真正用好Flow。
《Functional Reactive Programming》