数据分析 — Matplotlib 、Pandas、Seaborn 绘图
目录
- 一、Matplotlib
-
- 1、折线图
- 2、柱状图
- 3、水平条形图
- 4、直方图
- 5、散点图
- 6、饼图
- 二、pandas
-
- 1、折线图
- 2、柱状图
- 三、seaborn
-
- 1、散点图
- 2、箱线图
- 3、直方核密度图
- 4、成对图
一、Matplotlib
Matplotlib 是一个用于绘制数据可视化图形的 Python 库。它提供了丰富的绘图工具,可以用于创建各种类型的图表。
安装和导入:
pip install matplotlib
import matplotlib.pyplot as plt # 导入 Matplotlib 库
1、折线图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 设置画布大小
plt.figure(figsize=(10, 5))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 设置字体大小为 15
plt.rcParams['font.size'] = 15
# 定义 x 和 y 数据
x = [1, 2, 3, 4, 5] # 星期
y = [25, 27, 22, 30, 32] # 气温
# 绘制折线图
plt.plot(x, y, marker='D', # 设置点的形状
markerfacecolor='gold', # 设置折点填充颜色
markersize=10, # 设置折点大小
markeredgecolor='red', # 设置边缘颜色为红色
color='green', # 设置折线颜色为绿色
linewidth=3, # 设置折线宽度为3
linestyle=':', # 设置折线样式为虚线(折线样式:'-', '--', '-.', ':', '')
label='温度' # 设置标签为'温度'
)
# 设置 x 轴刻度标签为中文星期名
tick_labels = ['星期一', '星期二', '星期三', '星期四', '星期五']
plt.xticks(x, tick_labels)
# 设置 y 轴标签
plt.ylabel('气温(℃)')
# 设置 x 轴标签
plt.xlabel('星期')
# 设置图形标题
plt.title("一周的温度变化情况")
# 显示图例
plt.legend()
# 显示图形
plt.show()

2、柱状图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
import random # 导入 random 库,用于生成随机数
# 设置画布大小
plt.figure(figsize=(10, 6))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 定义 x 轴的城市名称
x = ['北京市', '上海市', '天津市', '重庆市']
# 生成包含4个随机整数的列表,表示每个城市的数据
y = [random.randint(10000, 14000) for i in range(4)]
# 绘制柱状图,设置柱宽为0.6
plt.bar(x, y, width=0.6)
# 设置 y 轴的取值范围为 [8000, 15000]
plt.ylim([8000, 15000])
# 在每个柱状图上添加数据标签
for i, j in enumerate(y):
# 打印城市索引和对应的数据值
print(i, j)
# 在每个柱状图上方添加文本标签,位置为 (i, j + 100),水平居中对齐
plt.text(i, j + 100, j, ha='center')
# 显示图形
plt.show()

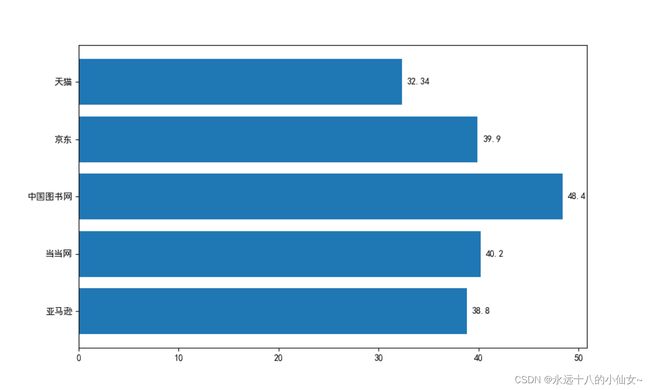
3、水平条形图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 设置画布大小
plt.figure(figsize=(10, 6))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 定义价格和标签数据
price = [38.8, 40.2, 48.4, 39.9, 32.34]
label = ['亚马逊', '当当网', '中国图书网', '京东', '天猫']
# 绘制水平条形图
plt.barh(label, price)
# 在每个条形图右侧添加数据标签
for i, j in enumerate(price):
# 在每个条形图右侧添加文本标签,位置为 (j + 0.5, i),垂直居中对齐
plt.text(j + 0.5, i, j, va='center')
# 显示图形
plt.show()
4、直方图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 设置画布大小
plt.figure(figsize=(10, 6))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 解决坐标轴负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 生成包含1000个随机数的一维数组
data = np.random.randn(1000)
# 绘制直方图,分成20个箱子,颜色为蓝色,透明度为0.5,添加标签为'直方图'
plt.hist(data, bins=20, color='blue', alpha=0.5, label='直方图')
# 添加图例
plt.legend()
# 显示图形
plt.show()

5、散点图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 设置画布大小
plt.figure(figsize=(8,5))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 定义身高和体重的数据
height = [120, 161, 170, 182, 175, 173, 165, 155, 150, 110]
weight = [38, 45, 58, 80, 90, 59, 55, 45, 40, 30]
# 根据体重生成散点的大小
sizes = [i * 20 for i in weight]
# 生成随机颜色
colors = np.random.rand(len(weight))
# 绘制散点图,设置点的大小、颜色
plt.scatter(height, weight, s=sizes, c=colors)
# 显示图形
plt.show()

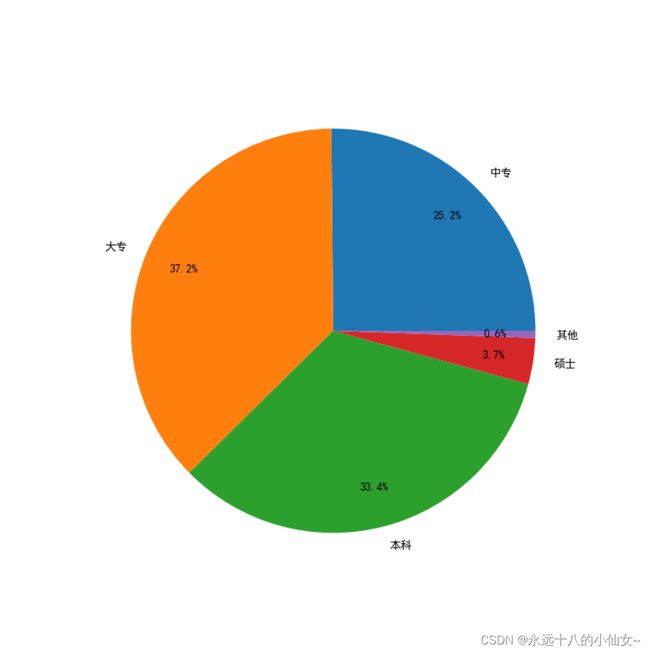
6、饼图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 设置画布大小
plt.figure(figsize=(8, 8))
# 设置字体为中文黑体
plt.rcParams['font.family'] = 'SimHei'
# 构造数据
x = [0.2515, 0.3724, 0.3336, 0.0368, 0.0057]
# 定义标签
labels = ['中专', '大专', '本科', '硕士', '其他']
# 绘制饼图
plt.pie(x, # x 表示设置饼每块的值
labels=labels, # 设置标签
autopct="%1.1f%%", # 设置成百分比的形式
pctdistance=0.8 # 设置百分比标签到圆心距离的比例
)
# 显示图形
plt.show()
二、pandas
1、折线图
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 生成包含10个随机数的一维数组,并计算累积和,将其转换为 Pandas 的 Series
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
# 绘制折线图,设置图形大小为 (7, 5) inches,颜色映射为 'viridis'
s.plot(figsize=(7, 5), colormap='viridis')
# 显示图形
plt.show()
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 生成一个包含10行4列随机数的二维数组,并对每列进行累积和
# 将其转换为 Pandas 的 DataFrame,指定列名和索引
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['one', 'two', 'three', 'four'],
index=np.arange(0, 100, 10))
# 绘制 DataFrame 中每列的折线图,设置图形大小为 (10, 6) inches
df.plot(figsize=(10, 6))
# 显示图形
plt.show()
2、柱状图
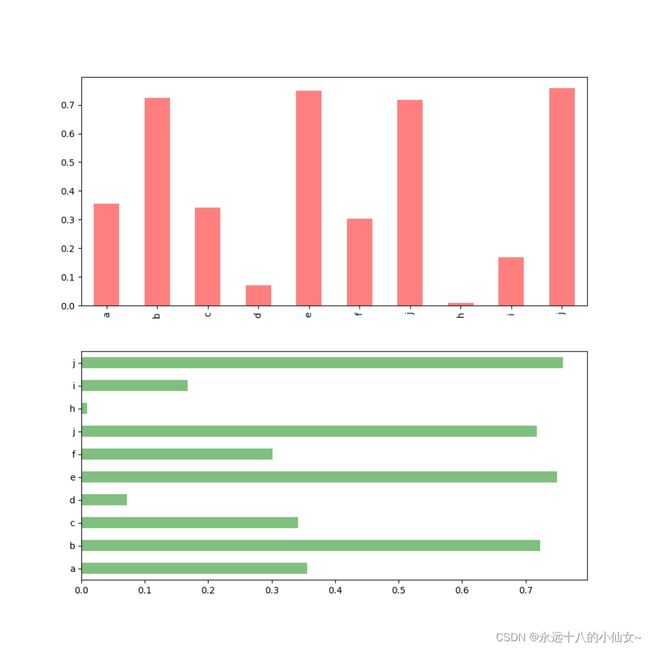
import numpy as np # 导入 NumPy 库并使用别名 np
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
# 创建一个包含两个子图的图形,fig是图形对象,axes是包含两个子图的数组
fig, axes = plt.subplots(2, 1)
# 生成包含10个随机数的一维数组,并转换为 Pandas 的 Series,指定索引
data = pd.Series(np.random.rand(10), index=list('abcdefjhij'))
# 在第一个子图上绘制垂直柱状图,设置图形大小、颜色、透明度
data.plot.bar(figsize=(10, 10), ax=axes[0], color='r', alpha=0.5)
# 在第二个子图上绘制水平柱状图,设置图形大小、颜色、透明度
data.plot.barh(figsize=(10, 10), ax=axes[1], color='g', alpha=0.5)
# 显示图形
plt.show()
图表适用场景总结:
1、折线图:表示数据的趋势情况,如几年每个月份的销量走势、股票走势。
2、散点图:查看数据的分布情况,是否有离群点、异常值(极小值、极大值 )、分布是否集中。
3、饼图:查看数据的占比情况,如整个市场的份额。
4、柱状图:多组数据数据对比。
5、直方图:查看数据的分布情况,集中程度、主要分布在哪个区间。
三、seaborn
Seaborn 是建立在 Matplotlib 基础上的一个数据可视化库。它提供了一些方便的函数,用于创建统计图形,特别适用于数据集的可视化和分析。
安装和导⼊:
pip install seaborn==0.11
import seaborn as sns # 导入 Seaborn 库并使用别名 sns
读取数据:
import pandas as pd # 导入 Pandas 库并使用别名 pd
iris = pd.read_csv(r'F:\data\iris.csv')
print(iris)
1、散点图
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
import seaborn as sns # 导入 Seaborn 库并使用别名 sns
# 从 CSV 文件中读取 Iris 数据集,将其存储为 Pandas 的 DataFrame
iris = pd.read_csv(r'F:\data\iris.csv')
# 设置图形大小为 (15, 6) inches
plt.figure(figsize=(15, 6))
# 使用 Seaborn 绘制散点图
sns.scatterplot(x='sepal_length', # 横坐标为 'sepal_length'
y='sepal_width', # 纵坐标为 'sepal_width'
hue='species', # 颜色按 'species' 划分
data=iris) # 数据来自于 Iris 数据集
# 显示图形
plt.show()

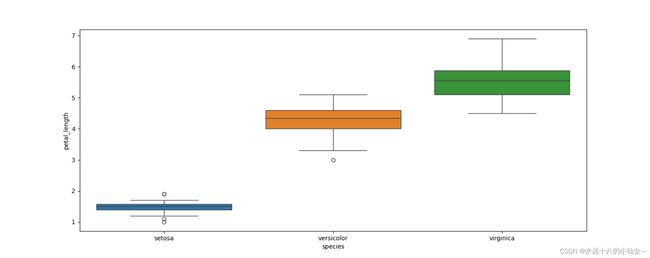
2、箱线图
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
import seaborn as sns # 导入 Seaborn 库并使用别名 sns
# 从 CSV 文件中读取 Iris 数据集,将其存储为 Pandas 的 DataFrame
iris = pd.read_csv(r'F:\data\iris.csv')
# 设置图形大小为 (15, 6) inches
plt.figure(figsize=(15, 6))
# 使用 Seaborn 绘制箱线图,根据 'species' 分组,展示花瓣长度的分布情况
sns.boxplot(x='species', # 横坐标为 'species'
y='petal_length', # 纵坐标为 'petal_length'
hue='species', # 颜色按 'species' 划分
data=iris) # 数据来自于 Iris 数据集
# 显示图形
plt.show()
3、直方核密度图
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
import seaborn as sns # 导入 Seaborn 库并使用别名 sns
# 从 CSV 文件中读取 Iris 数据集,将其存储为 Pandas 的 DataFrame
iris = pd.read_csv(r'F:\data\iris.csv')
# 设置图形大小为 (15, 6) inches
plt.figure(figsize=(15, 6))
# 使用 Seaborn 绘制直方图,根据 'species' 分组,展示花瓣长度的分布情况
sns.histplot(data=iris, # 数据来自于 Iris 数据集
x='petal_length', # 横坐标为 'petal_length'
hue='species', # 颜色按 'species' 划分
kde=True) # 在直方图上绘制核密度估计曲线
# 显示图形
plt.show()

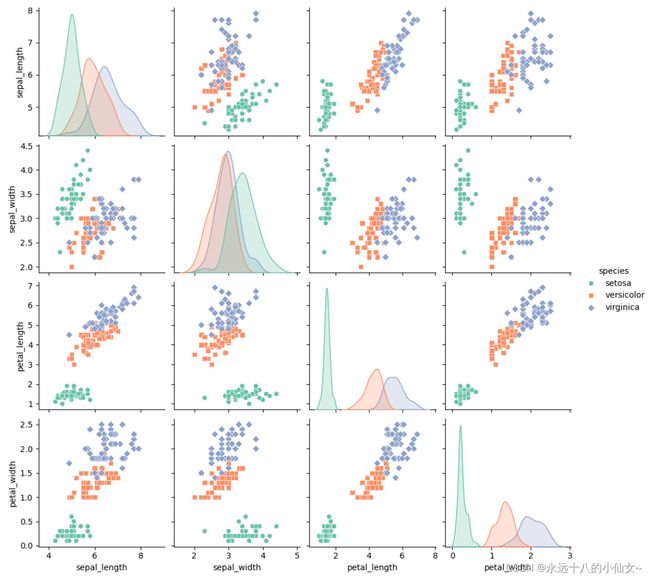
4、成对图
import pandas as pd # 导入 Pandas 库并使用别名 pd
import matplotlib.pyplot as plt # 导入 Matplotlib 库
import seaborn as sns # 导入 Seaborn 库并使用别名 sns
# 从 CSV 文件中读取 Iris 数据集,将其存储为 Pandas 的 DataFrame
iris = pd.read_csv(r'F:\data\iris.csv')
# 使用 Seaborn 绘制成对关系图,显示不同特征之间的关系
# 横轴和纵轴的关系用散点图表示,对角线上是每个特征的单变量分布(直方图或核密度估计)
sns.pairplot(data=iris, # 数据来自于 Iris 数据集
hue='species', # 颜色按 'species' 划分
markers=["o", "s", "D"], # 指定不同类别的标记样式
palette='Set2') # 指定颜色方案
# 显示图形
plt.show()
记录学习过程,欢迎讨论交流,尊重原创,转载请注明出处~