08.canal+kafka同步数据消息顺序一致性问题
canal+kafka同步数据环境回顾
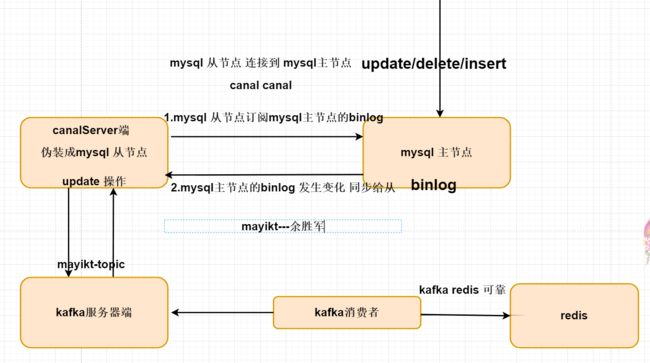
1.canal伪装成mysql从节点 订阅mysql主节点的binlog文件;
\2. 当我们的mysql主节点binlog文件发生了变化,则将该binlog文件
发送给canal服务器端;
3.canal服务器端将该binlog文件二进制转化成json格式发送给kafka服务器端
4.kafka消费者订阅kafka服务器端,将需要同步的数据同步到redis。
思考下:如何提高mysql与redis数据同步的速度问题?
kafka中保证消息顺序一致性问题
产生问题
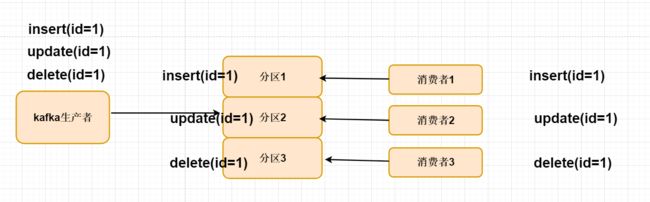
1.在kafka中一个topic主题会有n多个不同的分区模型来存放的消息;
2.为了提高同步的速度,我们会对kafka消费者实现集群消费,避免消息一直
堆积在kafka服务器端。
3.在kafka分区模型中,每个消费者对应一个独立的分区模型消费;
4.kafka生产默认的情况下 投递消息采用均匀模式,如果我们的消息需要
保证严格的顺序,就会出现问题,消费集群的情况下,每个消费在不同的JVM中取出对应的消息,没有执行顺序问题 可能先执行 update、也有可能先执行delete,最终导致同步
数据发生了错乱。
如何解决消息顺序一致性问题
1.只有一个分区、最终该消息被一个消费者消费,缺点就是同步效率非常低;
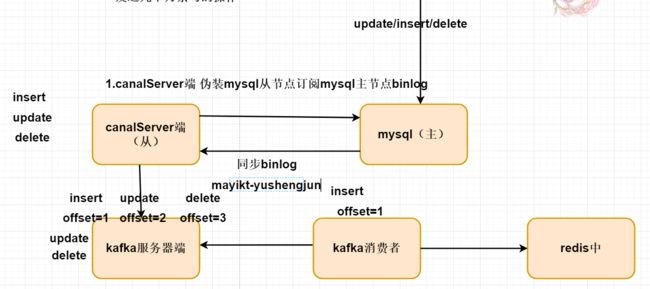
2.根据表中字段 例如 id 做Hash 运算 相同的 id最终落地存放同一个分区中,
同一个分区中最终被同一个消费者消费。这也是为什么kafka需要设计多个分区模型,
因为每个分区模型对应一个独立消费者,如果需要提高消费者速率可以分成n多个
分区模型,实现横向扩展。
canal配置kafka消息顺序一致性
topic相关配置
1.单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS(默认的实现方式)
canal 整合kafka 默认 单topic单分区
例如对mysql 所有db数据 来做同步
假设 在同一个db下 有n多个不同的表结构
insert mayikt01(id=1)
insert mayikt02(id=1)
insert mayikt03(id=1)
update mayikt01(id=1)
update mayikt02(id=1)
update mayikt03(id=1)
delete mayikt01(id=1)
delete mayikt02(id=1)
delete mayikt03(id=1)
2.多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
同步数据 每张表 有自己独立的topic主题-- 每个主题 只会分成一个分区
mayikt01 mayikt02 mayikt03
insert mayikt01(id=1)
insert mayikt02(id=1)
insert mayikt03(id=1)
update mayikt01(id=1)
update mayikt02(id=1)
update mayikt03(id=1)
delete mayikt01(id=1)
delete mayikt02(id=1)
delete mayikt03(id=1)
insert mayikt01(id=1)
update mayikt01(id=1)
delete mayikt01(id=1)
insert mayikt02(id=1)
update mayikt02(id=1)
delete mayikt02(id=1)
相同表名称落地到同一个分区中,最终被同一个消费者消费。----每张表
有自己对应独立的 消费者消费。
3.单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk
4.hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk
5.hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况.
如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题。根据表中的业务字段 相同的业务字段值 计算存放到同一个分区中,但是主要PK不能够发生变化。
update mayikt01 set pk=‘3’ where pk=‘1’;
update mayikt02 set name=‘1’ where pk= ‘3’
PK:primary key 主键
canal.mq.partitionHash
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
例子1:test\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
例子2:.*\\..*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
例子3:.*\\..*:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
例子4: 匹配规则啥都不写,则默认发到0这个partition上
例子5:.*\\..* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名 按表hash:
一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
例子6: test\\.test:id,.\\..* , 针对test的表按照id散列,其余的表按照table散列
在instance.properties 新增如下配置:
注意:canal 自动创建的 mayikt-topic 主题 默认是分区为0,如果在配置文件
指定canal.mq.partitionsNum=3 多个分区,canal投递消息到kafka中会报错:
kafka创建生产者报错:Invalid partition given with record: 1 is not in the range [0…1)
解决办法:
需要进入到docker kafka容器中:docker exec -it canal_kafka_1 bash
进入目录:/bin
kafka-topics.sh --zookeeper 192.168.75.145:2181 --alter --partitions 3 --topic mayikt-topic
修改分区是为3
kafka-topics.sh --zookeeper 192.168.75.145:2181 --alter --partitions 3 --topic mayikt-topic
在重启canal即可。


id=3 分区=2 消费者3
id=4 分区=0 消费者1
id=5 分区=2 消费者3
# mq config
canal.mq.topic=mayikt-topic
# hash partition config
canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
canal.mq.partitionHash=mayikt-test\\.commodity_info:id
根据表中:commodity_info 中的id字段 计算hash 相同的id 落地存放到同一个分区中,最终被同一个消费者消费,从而可以保证消息顺序一致性问题。
如果重启canal 报错:
Could not find first log file name in binary log index file
解决办法:
主要原因:
手工清理过binlog日志,没重置mysql binlog index信息
解决方法:
删除canal/conf/example/meta.dat 文件重启即可
消费者相关代码
package com.mayikt.consumer;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
/**
* @author 余胜军
* @ClassName CanalConsumer
* @qq 644064779
* @addres www.mayikt.com
* @createTime 2021年04月27日 19:14:00
*/
@Component
@Slf4j
public class CanalConsumer {
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* 消费者监听mayikt-topic
*
* @param consumer
*/
// @KafkaListener(topics = "meite-topic", topicPattern = "0", groupId = "mayikt01")
@KafkaListener(topicPartitions = {@TopicPartition(topic = "pp-topic", partitions = {"0"})}, groupId = "mayikt")
public void receive01(ConsumerRecord<?, String> consumer) {
log.info("分组1的消费者1>topic名称:{},,key:{},分区位置:{},offset{},数据:{}<",
consumer.topic(), consumer.key(), consumer.partition(), consumer.offset(), consumer.value());
JSONObject jsonObject = JSONObject.parseObject(consumer.value());
String type = jsonObject.getString("type");
switch (type) {
case MayiktConstant.CANAL_INSERT:
case MayiktConstant.CANAL_UPDATE:
updateRedis(jsonObject);
return;
case MayiktConstant.CANAL_DELETE:
deleteRedis(jsonObject);
}
}
//
// @KafkaListener(topics = "meite-topic", topicPattern = "1", groupId = "mayikt01")
@KafkaListener(topicPartitions = {@TopicPartition(topic = "pp-topic", partitions = {"1"})}, groupId = "mayikt")
public void receive02(ConsumerRecord<?, String> consumer) {
log.info("分组1的消费者2>topic名称:{},,key:{},分区位置:{},offset{},数据:{}<",
consumer.topic(), consumer.key(), consumer.partition(), consumer.offset(), consumer.value());
JSONObject jsonObject = JSONObject.parseObject(consumer.value());
String type = jsonObject.getString("type");
switch (type) {
case MayiktConstant.CANAL_INSERT:
case MayiktConstant.CANAL_UPDATE:
updateRedis(jsonObject);
return;
case MayiktConstant.CANAL_DELETE:
deleteRedis(jsonObject);
}
}
// @KafkaListener(topics = "meite-topic", topicPattern = "2", groupId = "mayikt01")
@KafkaListener(topicPartitions = {@TopicPartition(topic = "pp-topic", partitions = {"2"})}, groupId = "mayikt")
public void receive03(ConsumerRecord<?, String> consumer) {
log.info("分组1的消费者3>topic名称:{},,key:{},分区位置:{},offset{},数据:{}<",
consumer.topic(), consumer.key(), consumer.partition(), consumer.offset(), consumer.value());
JSONObject jsonObject = JSONObject.parseObject(consumer.value());
String type = jsonObject.getString("type");
switch (type) {
case MayiktConstant.CANAL_INSERT:
case MayiktConstant.CANAL_UPDATE:
updateRedis(jsonObject);
return;
case MayiktConstant.CANAL_DELETE:
deleteRedis(jsonObject);
}
}
/**
* 同步到Redis
*
* @param jsonObject
*/
private void updateRedis(JSONObject jsonObject) {
log.info("updateRedis:{}", jsonObject);
JSONArray datas = jsonObject.getJSONArray("data");
for (int i = 0; i < datas.size(); i++) {
JSONObject info = datas.getJSONObject(i);
String id = info.getString("id");
redisTemplate.opsForValue().set(id, info.toJSONString());
}
}
private void deleteRedis(JSONObject jsonObject) {
log.info("deleteRedis:{}", jsonObject);
JSONArray datas = jsonObject.getJSONArray("data");
for (int i = 0; i < datas.size(); i++) {
JSONObject info = datas.getJSONObject(i);
String id = info.getString("id");
redisTemplate.delete(id);
}
}
}
笔记
canal+kafka+mysql+redis 数据同步问题
1.如果是有多个消费者集群 消费的情况下,如果都是在同一个分组当中。
集群消费的情况下就会发生 消息顺序一致性问题。
mysql 主
insert
update
delete
mysql同步canal Server端,canal Server端 将该msg消息投递到
kafka中。---- 存放到mq服务器端 是保证顺序
先进先出 后进后出原则(前提条件没有分区)。
解决 kafka 消息顺序一致性问题
核心思想点:
1.投递到mq中需要保证顺序
2.最终是被同一个消费者消费(同步到Redis中) 速率非常低。
如何解决该问题?
kafka 底层 分区模型
在kafka中 将topic主题消息 采用分区模型形式存放。
分成n多个不同的目录存放msg。
解决消息顺序一致性 提高效率。
kafka中设计 每个分区只能够对应一个消费者消费。
生产者投递msg时,相同的id最终投递到同一个
kafka分区模型中存放,最终被同一个消费者消费。
如果需要提高mysql与redis同步速度问题,
直接将topic主题分成n多个分区模型,提高
分区模型,每个分区对应一个消费者消费。
而消费的过程中 都是同时。
即可保证消息顺序一致性问题,提高消费的速度。
每个分区是被–同一个分组 同一个消费者消费
不是同一个组是可以重复消费
在canal配置文件中指定的:mayikt-topic 主题名称
是有 canal 创建— canalServer端还没有收到需要同步的数据