搜索专题—dfs和bfs——迷宫矩阵问题学习笔记以及细节处理
目录
·深度优先搜索-dfs:
·原理:
·典型例题:
题目:
输入格式
输出格式
数据范围
输入样例:
输出样例:
· 代码
· 图解
· 总结
·广度优先搜索-bfs;
·原理:
·小结
·典型例题
题目:
输入格式
输出格式
数据范围
输入样例:
输出样例:
代码
总结
迷宫矩阵问题以及细节处理
例题1·数字矩阵
题目:
思考:
1.用dfs解决
2.用bfs解决
小结:
例题2·字符矩阵
题目:
输入格式
输出格式
数据范围
输入样例:
输出样例:
思考:
代码
小结
细节问题处理:
1. 对于输入多个样例的矩阵问题的状态数组的处理
2. 对于位移数组的处理
3.对于字符矩阵输入时的细节处理
学习感悟:
·深度优先搜索-dfs:
·原理:
dfs主要就是递归的思想,就是一条路走到头,然后回溯到上一步,一直重复这个步骤。(废话无用,直接看例题)
·典型例题:
题目:
把 1∼n 这 n 个整数排成一行后随机打乱顺序,输出所有可能的次序。
输入格式
一个整数 n。
输出格式
按照从小到大的顺序输出所有方案,每行 1 个。
首先,同一行相邻两个数用一个空格隔开。
其次,对于两个不同的行,对应下标的数一一比较,字典序较小的排在前面。
数据范围
1≤n≤9
输入样例:
3
输出样例:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
| 难度:简单 |
| 时/空限制:5s / 256MB |
| 总通过数:41773 |
| 总尝试数:54118 |
| 来源:《算法竞赛进阶指南》 |
| 算法标签 |
这里我们采用dfs来解决这个问题,来研究dfs的原理
· 代码
#include
#include
#include
#include
using namespace std;
const int N = 10;
int n;
int state[N]; // 0 表示还没放数,1~n表示放了哪个数
bool used[N]; // true表示用过,false表示还未用过
void dfs(int u)
{
if (u > n) // 边界
{
for (int i = 1; i <= n; i ++ ) printf("%d ", state[i]); // 打印方案
puts("");
return;
}
// 依次枚举每个分支,即当前位置可以填哪些数
for (int i = 1; i <= n; i ++ )
if (!used[i])
{
state[u] = i;
used[i] = true;
dfs(u + 1);
// 恢复现场
state[u] = 0;
used[i] = false;
}
}
int main()
{
scanf("%d", &n);
dfs(1);
return 0;
}
· 图解
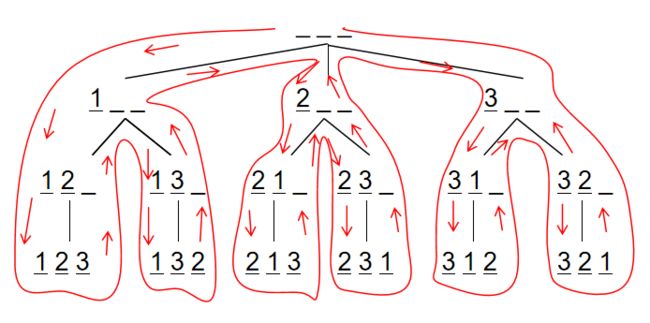
此图来自AcWing中的Hasity作者;
· 总结
拒绝废话,我也是刚学,在我看来dfs就是递归的一个应用,实在不理解的还是老老实实把递归学会了,再来学dfs吧,或着就和我一样,先背下来,一直敲,不理解的地方就画图研究原理,我刚开始就特别不理解回溯,后来画画图才逐渐理解了,手写模拟yyds!
·广度优先搜索-bfs;
·原理:
BFS(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和广度优先搜索类似的思想。属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。(说了一堆没什么用)
简单的说bfs就是来求最短路径的,这个是从最上面(树冠)一层一层的搜索,搜的目标就停止了,
可以和dfs做一个比较,dfs是从最开始沿着一个枝干走的头再回溯(不撞南墙不回头)
·小结
dfs 主要用于全排列
bfs 主要用于最短路径问题
不过后面不用把dsf,bfs分那么清,主要目的还是解决问题,有的题dfs和bfs都能解决
算法只是一个思路,解决问题还得灵活一些
·典型例题
题目:
阿尔吉侬是一只聪明又慵懒的小白鼠,它最擅长的就是走各种各样的迷宫。
今天它要挑战一个非常大的迷宫,研究员们为了鼓励阿尔吉侬尽快到达终点,就在终点放了一块阿尔吉侬最喜欢的奶酪。
现在研究员们想知道,如果阿尔吉侬足够聪明,它最少需要多少时间就能吃到奶酪。
迷宫用一个 R×C的字符矩阵来表示。
字符 S 表示阿尔吉侬所在的位置,字符 E 表示奶酪所在的位置,字符 # 表示墙壁,字符 . 表示可以通行。
阿尔吉侬在 1 个单位时间内可以从当前的位置走到它上下左右四个方向上的任意一个位置,但不能走出地图边界。
输入格式
第一行是一个正整数 T,表示一共有 T 组数据。
每一组数据的第一行包含了两个用空格分开的正整数 R 和 C,表示地图是一个 R×C 的矩阵。
接下来的 R行描述了地图的具体内容,每一行包含了 C 个字符。字符含义如题目描述中所述。保证有且仅有一个 S 和 E。
输出格式
对于每一组数据,输出阿尔吉侬吃到奶酪的最少单位时间。
若阿尔吉侬无法吃到奶酪,则输出“oop!”(只输出引号里面的内容,不输出引号)。
每组数据的输出结果占一行。
数据范围
1
输入样例:
3
3 4
.S..
###.
..E.
3 4
.S..
.E..
....
3 4
.S..
####
..E.
输出样例:
5
1
oop!| 难度:简单 |
| 时/空限制:1s / 64MB |
| 总通过数:13893 |
| 总尝试数:25804 |
| 来源:《信息学奥赛一本通》 |
| 算法标签 BFS |
这个就是典型的bfs求最短路径问题
代码
#include
#include
using namespace std;
const int N=1009;
int d[N][N];//判断状态同时计数
char g[N][N];//存地图
struct PII{
int x,y;
};
int x_o,y_o;
void bfs(int x_o,int y_o,int m,int n)
{//这里用队列实现bfs算法
queueq;
q.push({x_o,y_o});
int dx[4]={1,-1,0,0},dy[4]={0,0,1,-1};//移动位置必备的,图论问题基本都需要
while(q.size())//如果队列为空就结束
{
PII t=q.front();//取出队列第一个的值
q.pop();//弹出队列第一个值
for(int i=0;i<4;i++)
{
int xx=t.x+dx[i],yy=t.y+dy[i];
if(xx>=1&&xx<=m&&yy>=1&&yy<=n&&d[xx][yy]==0&&g[xx][yy]!='#')//判断是遍历的位置否符合要求
{
d[xx][yy]=d[t.x][t.y]+1;//记录步数
if(g[xx][yy]=='E')//如果找到终点,就输出,并结束
{
printf("%d\n",d[xx][yy]);
return ;
}
q.push({xx,yy});//将新的坐标压入队列
}
}
}
printf("oop!\n");
}
int main()
{
int t,n,m;
cin>>t;
while(t--)
{
scanf("%d%d",&m,&n);
for(int i=1;i<=m;i++)
{
for(int j=1;j<=n;j++)
{
cin>>g[i][j];
d[i][j]=0;//防止上一次的数据对这一次结果有影响
if(g[i][j]=='S')//记录初始位置
{
x_o=i;
y_o=j;
}
}
}
bfs(x_o,y_o,m,n);
}
return 0;
} 上面代码bfs里面那个while的意思是
1·队头出队。
2·遍历队头的上下左右四个方向:如果是 ‘.’ 走过去,并且该位置入队,该点对应的d值更新为队头的d+ 1,表示走过了,如果是 ‘E’,走到了终点,输出该点对应的d值。
总结
上面那个例题的难点在于对队列操作的理解,进队和出队的操作的理解。
不过图论问题用手写模拟都是可以发现原理的,我们现在的目标是理解算法并学会怎么用,不用它是怎么被发明的,所以只要学会这个思路来解决问题就行
如果实在不理解也不要慌太正常了,不会就多敲几遍,时间长了就会习惯这个思路了,达到会用即可,有时候把之前学过的知识再看一遍一会有不同的理解,所以学习算法是一个循序渐进的过程。
迷宫矩阵问题以及细节处理
结合题来看:
例题1·数字矩阵
题目:
吱吱吱吱吱吱吱吱吱
题目统计 全部提交
时间限制:C/C++ 3000MS,其他语言 6000MS
内存限制:C/C++ 256MB,其他语言 512MB
难度: 中等
出题人: wzychampion
描述
给你一个 n×m 格 a 的非负整数。数值 ai,j 表示 i (行)和 j (列)处的水深。
一个湖泊是一组这样的单元格:
- 集合中的每个单元格都有 ai,j>0 ,并且
- 在湖中的任意一对单元格之间存在一条路径,该路径可以向上、向下、向左或向右移动若干次,且不会踩到带有 ai,j=0 的单元格。
湖泊的体积是湖中所有单元格的深度之和。
请找出网格中最大的湖泊体积。
输入描述
输入
第一行包含一个整数 t ( 1≤t≤104 ) - 测试用例的数量。
每个测试用例的第一行包含两个整数 n,m ( 1≤n,m≤1000 ) - 分别是网格的行数和列数。
然后是 n 行,每行包含 m 个整数 ai,j ( 0≤ai,j≤1000 ) - 每个单元格的水深。
保证所有测试用例的 n⋅m 之和不超过 106 。
输出描述
输出
对于每个测试用例,输出一个整数 - 网格中湖泊的最大体积。
用例输入 1
5 3 3 1 2 0 3 4 0 0 0 5 1 1 0 3 3 0 1 1 1 0 1 1 1 1 5 5 1 1 1 1 1 1 0 0 0 1 1 0 5 0 1 1 0 0 0 1 1 1 1 1 1 5 5 1 1 1 1 1 1 0 0 0 1 1 1 4 0 1 1 0 0 0 1 1 1 1 1 1
用例输出 1
10 0 7 16 21
思考:
看见这个题有什么反应吗,是不是好像知道考的什么,但又想不出来用什么思路(对于初学者)
不知道就随便试试呗,反正是图论问题,你可以想想dfs和bfs,但问题又来了,你到底是选dfs还是选bfs呢,刚开始学看到这个有点迷惑太正常了,OK,不说废话了,不知道选什么就都试一遍,刚开始学绝对不能懒
1.用dfs解决
#include
using namespace std;
const int N=1009;
int n,m;
int g[N][N];//存地图
bool st[N][N];//存状态
int dx[4]={1,-1,0,0};//位移数组
int dy[4]={0,0,1,-1};//位移数组
int dfs(int x,int y,int n,int m)
{
st[x][y]=true;
int sum=g[x][y];
for(int i=0;i<4;i++)
{
int xx=x+dx[i];
int yy=y+dy[i];
if(x>=1&&x<=n&&y>=1&&y<=m&&!st[xx][yy]&&g[xx][yy]!=0)
{
sum += dfs(xx,yy,n,m);//递归
st[xx][yy]=true;
}
}
return sum;
}
int main()
{
int n,m,t;
cin>>t;
while(t--)
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&g[i][j]);
st[i][j]=false;
}
}
int max=0;
for(int i=1;i<=n;i++)//遍历
{
for(int j=1;j<=m;j++)
{
if(g[i][j]==0||st[i][j]) continue;
int num=dfs(i,j,n,m);
if(num>max) max=num;
}
}
printf("%d\n",max);
}
return 0;
} 只要递归学的好,这个还是很容易理解的
2.用bfs解决
#include
#include
#include
using namespace std;
const int N=1009;
int g[N][N],d[N][N];
int n,m;
typedef pair PII;
int bfs(int x1,int y1,int n,int m)
{
int sum=0;
queueq;
q.push({x1,y1});
int dx[4]={1,-1,0,0},dy[4]={0,0,1,-1};
while(q.size())
{
PII t=q.front();
q.pop();
for(int i=0;i<4;i++)
{
int x=t.first+dx[i],y=t.second+dy[i];
if(x>=1&&x<=n&&y>=1&&y<=m&&g[x][y]!=0&&d[x][y]==-1)
{
d[x][y]=1;
q.push({x,y});
sum+=g[x][y];
g[x][y]=0;
}
}
}
return sum+g[x1][y1];
}
int main()
{
int n,m,t;
cin>>t;
while(t--)
{
scanf("%d%d",&n,&m);
int max=0;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%d",&g[i][j]);
d[i][j]=-1;
}
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
if(g[i][j]==0)continue;
int num=bfs(i,j,n,m);
if(num>max) max=num;
}
}
cout< 用bfs解决这个问题时要注意状态标记防止重复遍历,可以用数组存状态,这里我的处理是把状态数组省略了,把每一个遍历过点给直接变成0,下一次就不会遍历了
小结:
对于这种问题其实bfs和dfs都是可以的,看个人习惯吧,不过我个人认为这个题用dfs代码会更简洁一点,不过我们这里主要是练习一下bfs和dfs的思路
例题2·字符矩阵
题目:
你现在被困在一个三维地牢中,需要找到最快脱离的出路!
地牢由若干个单位立方体组成,其中部分不含岩石障碍可以直接通过,部分包含岩石障碍无法通过。
向北,向南,向东,向西,向上或向下移动一个单元距离均需要一分钟。
你不能沿对角线移动,迷宫边界都是坚硬的岩石,你不能走出边界范围。
请问,你有可能逃脱吗?
如果可以,需要多长时间?
输入格式
输入包含多组测试数据。
每组数据第一行包含三个整数 L,R,C, 分别表示地牢层数,以及每一层地牢的行数和列数。
接下来是 L个 R 行 C 列的字符矩阵,用来表示每一层地牢的具体状况。
每个字符用来描述一个地牢单元的具体状况。
其中, 充满岩石障碍的单元格用”#”表示,不含障碍的空单元格用”.”表示,你的起始位置用”S”表示,终点用”E”表示。
每一个字符矩阵后面都会包含一个空行。
当输入一行为”0 0 0”时,表示输入终止。
输出格式
每组数据输出一个结果,每个结果占一行。
如果能够逃脱地牢,则输出”Escaped in x minute(s).”,其中X为逃脱所需最短时间。
如果不能逃脱地牢,则输出”Trapped!”。
数据范围
1≤L,R,C≤100
输入样例:
3 4 5
S....
.###.
.##..
###.#
#####
#####
##.##
##...
#####
#####
#.###
####E
1 3 3
S##
#E#
###
0 0 0
输出样例:
Escaped in 11 minute(s).
Trapped!| 难度:简单 |
| 时/空限制:1s / 64MB |
| 总通过数:8893 |
| 总尝试数:17956 |
| 来源:《信息学奥赛一本通》 , POJ2251 , kuangbin专题 |
| 算法标签 BFS |
思考:
最短路径问题,我们首先就应该想到的就是bfs,不过这个地牢是多层的,和我们之前二维的迷宫不太一样,看起来非常麻烦,但其实只要你一步步敲出来其实就会发现确实麻烦(开个小玩笑,hhh),其实思路和二维的一样,把那个位移数组变一下就行,再开三维数组存地图就行
代码
#include
#include
using namespace std;
struct PII{//开一个结构体存坐标
int x,y,z;
};
const int N=109;
char g[N][N][N];//开三维数组存地图
int d[N][N][N];//状态数组
int x_o,y_o,z_o;//初始位置
int dx[6]={1,-1,0,0,0,0},dy[6]={0,0,1,-1,0,0},dz[6]={0,0,0,0,1,-1};//因为一共有东西南北上下六个方向,所以要开大小为6的位移数组
void bfs(int x_o,int y_o,int z_o,int h,int n,int m)//这里其实可以把数据都定义再上面这里就不用传入了,看个人习惯
{
queueq;
q.push({x_o,y_o,z_o});
while(q.size())//这个的思路和二维数组的一样
{
PII t=q.front();
q.pop();
d[z_o][x_o][y_o]=1;
for(int i=0;i<6;i++)
{
int zz=t.z+dz[i],xx=t.x+dx[i],yy=t.y+dy[i];
if(xx>=1&&xx<=n&&yy>=1&&yy<=m&&zz>=1&&zz<=h&&d[zz][xx][yy]==0&&g[zz][xx][yy]!='#')
{
d[zz][xx][yy]=d[t.z][t.x][t.y]+1;
if(g[zz][xx][yy]=='E')//如果找到终点就输出并结束
{
printf("Escaped in %d minute(s).\n",d[zz][xx][yy]-1);
return ;
}
q.push({xx,yy,zz});
}
}
}
printf("Trapped!\n");
}
int main()
{
int h,n,m;
while(1)
{
scanf("%d%d%d",&h,&n,&m);
if(h==0&&n==0&&m==0)break;
for(int i=1;i<=h;i++)
{
for(int j=1;j<=n;j++)
{
for(int k=1;k<=m;k++)
{
cin>>g[i][j][k];
d[i][j][k]=0;//恢复现场,即初始化状态数组
if(g[i][j][k]=='S')//存初始位置
{
z_o=i;
x_o=j;
y_o=k;
}
}
}
}
bfs(x_o,y_o,z_o,h,n,m);
}
return 0;
} 小结
这个题只是看起来复杂一些其实就是bfs的基本应用,也可以用来检测一些自己有没有掌握bfs的基本用法
细节问题处理:
1. 对于输入多个样例的矩阵问题的状态数组的处理
最暴力的就是弄一个for循环遍历状态数组来初始化或用memset函数来初始化,不过这样比较浪费时间,我们这里可以做一个优化。
即在矩阵输入时顺便直接把状态数组初始化就行了,可以避免不必要的时间浪费,简单的说就是用哪个位置就初始化哪个
2. 对于位移数组的处理
可能对于初学者而言,不是很理解位移数组的原理,这里细说一下
就拿二维的简单情况来讲一下:
对于你现在所处的位置,你可以往上下左右走,放在坐标轴上就是x+1或x-1或y+1或y-1;
要记住你每一次只能走一个方向,所以你要开大小为4的位移数(因为有四个方向)
int dx[4]={1,-1,0,0};
int dy[4]={0,0,1,-1};数组里面的顺序没什么要求,但是相同下标的dx和dy必须有一个为0,因为你每一次只能走一个方向。(即当你dx的值不为0时,你是要左右走的,这个时候,dy的值必须为0)
结合这个位移的固定模板来看一下
for(int i=0;i<4;i++)
{
int xx=x+dx[i];
int yy=y+dy[i];
}用for来遍历四种情况,不能理解的可以把把位移数组里面的值随便变一下看看会发生上面,自己摸索也更容易理解。
3.对于字符矩阵输入时的细节处理
我们输入字符矩阵用cin好像理所当然,但对于初学者而言这里可能有一个细节没注意到,就是矩阵中都是存在回车的,但cin把他过滤掉了,但有时候为了输入更快我们会选择scanf但这个时候就出现问题了,因为这个时候会把回车也读进去。
(补充:在C++中,cin输入字符时会自动过滤回车是因为cin默认会忽略掉空格、回车、制表符等空白字符,这是为了方便用户输入。如果需要输入空白字符,可以使用noskipws流控制来关闭这个默认行为)
解决方法:
其实这个问题解决方法很多,主要是要注意这个细节,可以加一个gechar();来把回车给吃了,也可以把内层for循环初始值减一来存这个回车,不过新手还是建议用cin。
学习感悟:
算法就像一个工具,不过这个工具前人已经做好了,我们可以直接拿来用,而我们的目标就是要学习怎么用好这些工具,你可以不必在意这些工具如何发明的,理解原理即可,但不要浅尝辄止。