MySQL-运维
一、日志
1.错误日志
错误日志是MySQL中最重要的日志之一,它记录了当mysql启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关性息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录/var/log/,默认的日志文件名为mysqld.log。查看日志位置:
show variables like '%log_error%'
2.二进制日志
(1)介绍
二进制日志(BINLOG)记录了所有的DDL(数据定义语言)语句和DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句
作用:
- 灾难时的数据恢复
- MySQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
show variables like '%log_bin%'

(2)日志格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:
| 日志格式 | 含义 |
| STATEMENT | 基于SQL语句的日志记录,记录的是SQL语句,对数据进行修改的SQL都会记录在日志文件中 |
| ROW | 基于行的日志记录,记录的是每一行的数据变更。(默认) |
| MIXED | 混合了STATEMENT和ROW两种格式,默认采用STATEMENT,在某些特殊情况下会自动写换位ROW进行记录。 |
shoiw variables like '%binlog_format%';
(3)日志查看
由于日志是以二进制方式储存的,不能直接读取,需要通过二进制日志查询工具mysqlbinlog来查看,具体语法:
mysqlbinlog [ 参数选项 ] logfilename
参数选项:
-d 指定数据库名称,只列出指定的数据库相关操作。
-o 忽略掉日志中的前n行命令
-v 将行事件(数据变更)重构为SQL语句
-w 将行事件(数据变更)重构为SQL语句,并输出注释信息
(4)日志删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量的磁盘空间。通过以下几种方式清理日志:
| 指令 | 含义 |
| reset master | 删除全部binlog日志,删除之后,日志编号,将从binlog.000001重新开始 |
| purge master logs to ‘binlog.******’ | 删除******编号之前的所有日志 |
| purge master logs before ‘yyyy-mm-dd hh24:mi:ss' | 删除日志为yyyy-mm-dd hh24:mi:ss'之前产生的所有日志 |
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
show variabkles like '%binlog_expire_logs_seconds%';
(5)查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下是未开启的。如果需要开启查询日志,可以设置以下配置

修改MySQL的配置文件/etc/my.cnf文件添加如下内容:
#该选项用来开启查询日志,可选值:0或1;0代表关闭,1代表开启
general_log=1
#设置日志的文件名,如果没有指定,默认的文件名为host-name.log
general_log_file=mysql-query.log
(5)慢查询日志
慢查询日志记录了所有执行时间超过参数long_query_time设置值并且扫描记录数不小于min_examined_row_limit的所有日志,默认未开启。long_query_time默认值为10秒,最小值0,精度可以到微秒。
#慢查询日志
show_query_log=1
#执行时间参数
long_query_time=2
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用log_slow_admin_statements和更改此行为log_queries_not_using_indexes,如下所述。
#记录执行较慢的管理语句
log_slow_admin_statements=1
#记录执行较慢的未使用索引语句
log_queries_not_using_indexes=1
二、主从复制
1.概述
主从复制是指将主库数据的DDL和DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制,从主库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL复制的有点主要包含以下三个方面:
- 主库出现问题,可以快速切换到从库提供服务。
- 实现读写分离,降低主库的访问压力。
- 可以在从库中执行备份,以避免备份期间影响主库服务。
2.原理
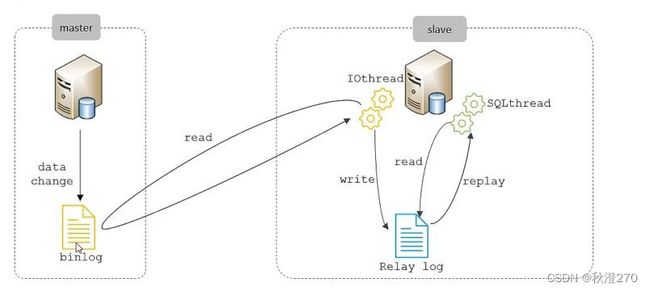
从上图来看,复制分成三部:
- Master主库在事务提交时,会把数据变更记录在二进制日志文件Binlog。
- 从库读取主库的二进制日志文件Binlog,写入到从库的中继日志Relay Log。
- slave重做中继日志中的文件,将改变反映他自己的数据。
3.搭建
(1)服务器准备

准备好两台服务器之后,在上述的两台服务器中分别安装好MySQL,并完成基础的初始化准备工作。
(2)主库配置
- 修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围:1-2的32的次方-1,默认为1
server-id=1
#是否只读,1代表只读,0代表读写
read-only=0
#忽略的数据,指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01
- 重启MySQL服务器
systemctl restart mysqld
- 登录mysql,创建远程连接的账号,并授予主从复制权限
#创建itcast用户,并设置密码,该用户可在任意主机连接MySQL服务
CREATE USER 'itcast'@'%'IDENTIFIED WITH mysql_native_password BY'Root@123456';
#为'itcast'@'%'用户分配主从复制权限
GRANT REPLICATION SLAVE ON*.*TO'itcast'@'%';
- 通过指令,查看二进制日志坐标
show master status;
字段含义说明:
file:从哪个日志文件开始推送日志文件
position:从哪个位置开始推送日志
binlog_ignore_db:指定不需要同步的数据库
(3)从库配置
- 修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围:1-2的32的次方-1,和主库不一样
server-id=2
#是否只读,1代表只读,0代表读写
read-only=1
- 重启MySQL服务器
systemctl restart mysqld
- 登录mysql,设置主库配置
CHANGE REPLICATION SOURCE TO SOURCE_HOST='xxx.xxx',SOURCE_USER='xxx',SOURCE_PASSWORD='xxx',SOURCE_LOG_FILE='xxx',SOURCE_LOG_POS=xxx;
上述是8.0.23中语法。如果mysql是8.0.23之前的版本,执行如下SQL:
CHANDE MASTER TO MASTER_HOST='xxx.xxx.xxx.xxx',MASTER_USER='xxx',MASTER_PASSWORD='xxx',MASTER_LOG_FILE='xxx',MASTER_LOG_POS-=xxx;
| 参数名 | 含义 | 8.0.23之前 |
| SOURCE_HOST | 主库IP地址 | MASTER_HOST |
| SOURCE_USER | 连接主库的用户名 | MASTER_USER |
| SOURCE_PASSWORD | 连接主库的密码 | MASTER_PASSWORD |
| SOURCE_LOG_FILE | binlog日志文件名 | MASTER_LOG_FILE |
| SOURCE_LOG_POS | binlog日志文件位置 | MASTER_LOG_POS |
- 开启同步操作
start replica; #8.0.22之后
start slave; #8.0.22之前
- 查看主从同步位置
show replica status; #8.0.22之后
show slave status: #8.0.22之前
三、分库分表
1.介绍
随着互联网及移动互联网的发展,应用系统的数据量也是呈指数式增长,若采用单数数据库进行数据库储存,存在以下性能瓶颈:
- IO瓶颈:热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低。请求数据太多,带宽不够,网络IO瓶颈。
- CPU瓶颈:排序、分组、连接查询、聚合统计等SQL会消耗大量的CPU资源,请求数太多,CPU出现瓶颈。
分库分表的中心思想都是将数据分散储存,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库新能的目的。
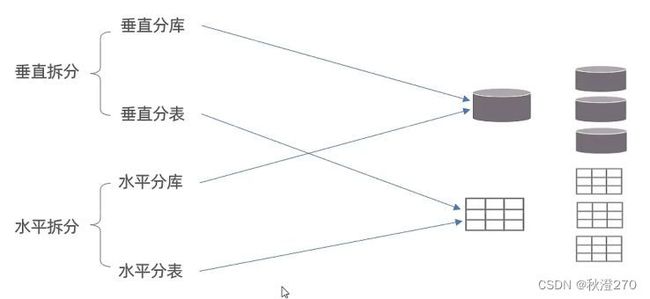
(1)拆分策略
(2)垂直拆分

垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
- 每个库的表结构都不一样。
- 每个库的数据也不一样。
- 所有库的并集是全量数据。

垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点:
- 每个表的结构都不一样
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全部数据。
(3)水平拆分

水平分库:以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
特点:
- 每个库的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全数据。
水平分表:以字段为依据,按照一定策略,将一个表的数据拆分到对各表中。
特点:
- 每个表的表结构都一样。
- 每个库的数据都不一样。
- 所有库的并集是全量数据。

- shardingJDBC:基于AOP原理,在应用程序中对本地执行的SQL进行拦截,解析、改写、路由处理。需要自行编码配置实现,只支持java语言,性能较高。
- MyCat:数据库分库分表中间件,不用调整代码即可实现分库分表,支持多种语言,性能不及前者
2.MyCat概述
(1)介绍
Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以向像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。
优势:
- 性能可靠稳定
- 强大的技术团体
- 体系完善
- 社区活跃
(2)安装
Mycat是采用java语言开发的开源的数据库中间件,支持Windows和Linux运行环境,下面介绍MyCat的Linux中的环境搭建。我们需要在准备好的服务器中安装如下软件。
- MySQL
- JDL
- Mycat
| 服务器 | 安装软件 | 说明 |
| 192.168.200.210 | JDK、Mycat | MyCat中间件文件 |
| 192.168.200.210 | MySQL | 分片服务器 |
| 192.168.200.213 | MySQL | 分片服务器 |
| 192.168.200.214 | MySQL | 分片服务器 |
(3)目录结构
bin:存放可执行文件:用于启动停止mycat
conf:存放mycat的配置文件
lib:存放mycat的项目依赖包(jar)
logs:存放mycat的日志文件
(4)概念介绍

3.Mycat入门
(1)需求
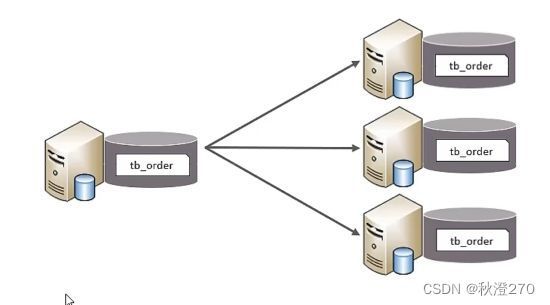
由于tb_order表中数据量很大,磁盘IO及容量都达到了瓶颈,现在需要对tb_order表进行数据分片,分为三个数据节点,每一个节点主机位于不同的服务器上,具体结构,参考下图:
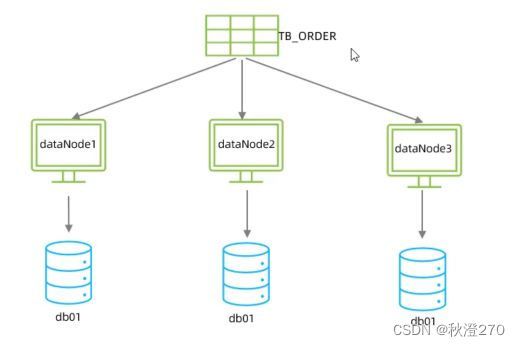
(2)环境准备

(3)分片配置

(4)启动服务
切换到Mycat的安装目录,执行如下指令,启动Mycat:
#启动
bin/mycat start
#停止
bin/mycat stop
Mycat启动之后,占用端口号8066
(5)分片指令测试
通过如下指令,就可以连接并登录Mycat。
mysql -h192.168.200.210 -P 8066 -uroot -p123456
然后就可以在Mycat中来创建表,并往表结构中插入数据,查看数据在MySQL中的分布情况。
CREATE TABLE TB_ORDER(
id BIGINT(20)NOT NULL,
title VARCHAR(100)NOT NULL,
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
INSERT INOT TB_ORDER(id,title)VALUES(1,'goods1');
INSERT INOT TB_ORDER(id,title)VALUES(2,'goods2');
INSERT INOT TB_ORDER(id,title)VALUES(3,'goods3');
INSERT INOT TB_ORDER(id,title)VALUES(1000000,'goods1000000');
INSERT INOT TB_ORDER(id,title)VALUES(10000000,'goods10000000');
4.Mycat配置
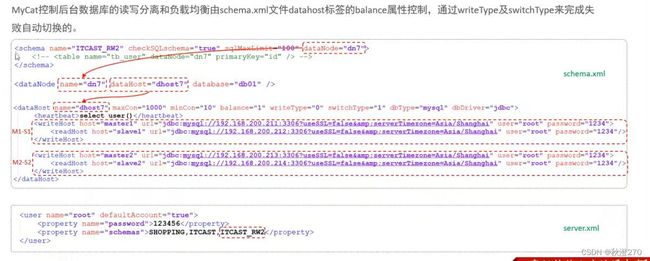
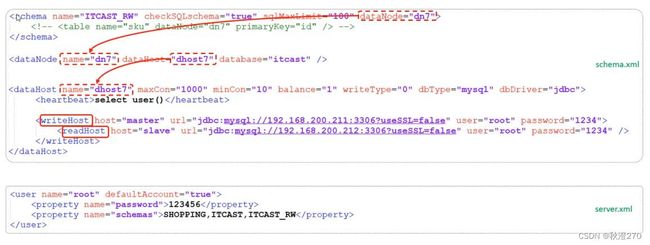
(1)schema.xml
schema.xml作为Mycat中最重要的配置文件之一,涵盖了Mycat的逻辑库、逻辑表、分片规则、分片节点及数据源的配置。
主要包含以下三组标签:
- schema标签
- datanode标签
- datahost标签
①schema标签
schema标签用于定义MyCat实例中的逻辑库,一个MyCat实例中,可以有多个逻辑库,可以通过schema标签来划分不同的逻辑库。
MyCat中的逻辑库的概念,等同于MyAQL中的database概念,需要操作某个逻辑库下的表时,也需要切换逻辑库(use xxx)。
核心属性:
- name:指定自定义的逻辑库库名
- checkSQLschema:在SQL语句操作时指定了数据库名称,执行时是否自动去除;true:自动去除,flase:不自动去除
- sqlMaxLimit:如果未指定limit进行查询,列表查询模式查询多少条记录
②schema标签(table)
table标签定义了MyCat中逻辑库schema下的逻辑表,所有需要拆分的表都需要在table标签中定义。
核心属性:
- name:定义逻辑表表明,在该逻辑库下唯一。
- dataMode:定义逻辑表所属的dataMode,该属性需要与dataMode标签中name对应;多个dataMode逗号分隔
- rule:分片规则的名字,分片规则名字是在rule.xml中定义的
- primaryKey:逻辑表对应真实表的主键
- type:逻辑表的类型,目前逻辑表只有全局表和普通表,如果未配置,就是普通表;全局表,配置为global
③dataMode标签
dataMode标签中定义了MyCat中的数据节点,也会就是我们通常的说的数据分片。一个dataNode标签就是一个独立的数据分片。
核心属性:
- name:定义数据节点名称
- dataHost:数据库实例主机名称,引用自dataHost标签中name属性
- database:定义分片所属数据库
④dataHost标签
该标签在MyCAT逻辑库中作为底层标签存在,直接定义了具体的数据库实例、读写分离、心跳语句。
核心属性:
- name:唯一标识,供上层标签使用
- maxCon/minCon:最大连接数/最小连接数
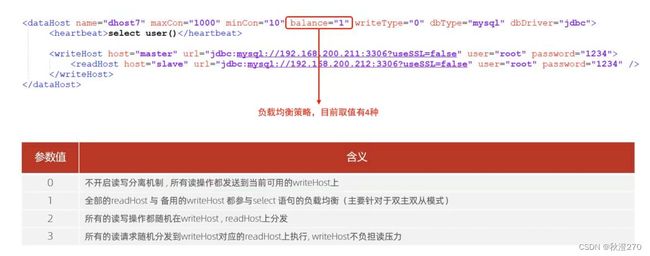
- balance:负载均衡策略,取值0,1,2,3
- writeType:写操作分发方法(0:写操作转发到第一个writeHost,第一个挂了,切换到第二个;1:写操作随机分发到配置的writeHost)
- dbDriver:数据库驱动,支持native、jdbc
⑤rule.xml
rule.xml中定义所有拆分表的规则,在使用过程中可以灵活的使用分片算法,或者对同一个分片算法使用不同的参数,他让分片过程可配置化。主要包含两类标签:tableRule、Funtion。
⑥server.xml
server.xml配置文件包含了MyCat的系统配置信息,主要有两个重要标签:system、user。
- system标签:对应的系统配置项及其含义,参考资料。

- user标签

5.Mycat分片
(1)垂直拆分
①场景
在业务系统中,涉及以下表结构,但是由于用户与订单每天都会产生大量的数据,单台服务器的数据储存及处理能力是有限的,可以对数据表进行拆分,原有的数据库表如下。

②准备

分别在三台MySQL中创建数据库shopping
③配置

④测试
在mycat的命令行中,通过source指令导入表结构,以及对应的数据,查看数据分布情况。
source/root/shopping-table.sql
source/root/shopping-insert.sql
查询用户的收件人及收件人地址信息(包含省、市、区)。
select ua.user_id,us.contact,p.province,c.city,r.area,ua.address from tb_user_address ua,tb_areas_city c,tb_areas_provinces p,tb_areas_region r where ua.province_id=p.provinceid and ua.city_id=c.cityid and ua.town_id=r.areaid;
查询每一笔订单及订单的收件地址信息(包含省、市、区)。
SELECT order_id,payment,receiver,province,city,area FROM tb_order_master o,tb_arears_city c,tb_arears_region r WHERE o.receiver_province = p.provinceid AND o.receiver_city=c.cityid AND o.receiver_region=r.areaid;
⑤全局表配置
对于省、市、区/县表tb_areas_provinces,tb_areas_city,tb_areas_region,是属于数据字典表,在多个业务模块中都可能会遇到,可以将其设置为全局表,利于业务操作。

(2)水平拆分
①场景
在业务系统中,有一张表(日志表),业务系统每天都会产生大量的日志数据,单台服务器的数据储存及处理能力是有限的,可以对数据库表进行拆分。

②准备

③配置

④测试
在mysql的命令行中,执行如下SQL创建表、并插入数据,查看数据分布情况。

(3)分片规则-范围
根据指定的字段及配置的范围与数据节点的对应情况,来决定该数据属于哪一个分片。
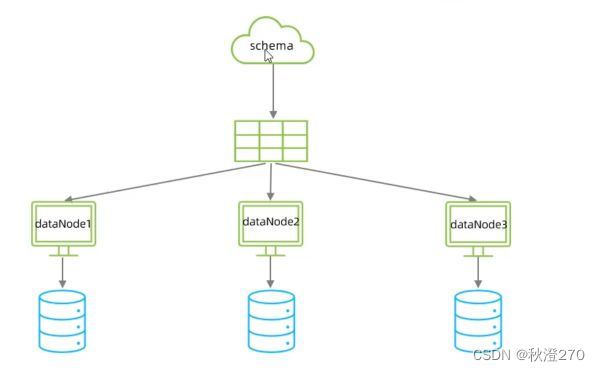
(4)分片规则-取模
根据指定的字段值与节点数量进行求模运算,根据运算结果,来决定该数据属于哪一个分片
(5)分片规则-一致性hash
所谓一致性哈希,相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置
(6)分片规则-枚举
通过在配置文件中配置可能的枚举值,指定数据分布到不同数据节点上,本规则适用于按照省份、性别、状态拆分数据等业务。
(7)分片规则-应用指定
运用阶段由应用自主决定路由到那个分片,直接根据字符字串(必须是数字)计算分片号。
(8)分片规则-固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取id的二进制低10位与1111111111进行位&运算。
特点:
- 如果是求模,连续的值,分别分配到各个不同的分片;但是此算法会将连续的值可能分配到相同的分片,降低事务处理的难度。
- 可以均匀分配,也可以非均匀分配。
- 分片字段必须为数字类型。
(9)分片规则-字符串hash解析
截取字符串中的指定位置的子字符串,进行hash算法,算出分片。
(10)分片规则-按(天)日期分片

(11)分片规则-自然月
使用场景为按照月份来分片,每个自然月为一个分片。
6.Mycat管理及监控
(1)Mycat原理

(2)Mycat管理
Mycat默认开通2个端口,可以在server.xml中进行修改。
- 8066数据访问端口,即进行DML和DDL操作。
- 9066数据库管理端口,即mycat服务管理控制功能,用于管理mycat的整个集群状态
mysql -h 192.168.200.210 -p 9066 -uroot -p123456
| 命令 | 含义 |
| show @@help | 查看Mycat管理工具帮助文档 |
| show @@version | 查看Mycat的版本 |
| reload @@config | 重新加载Mycat的配置文件 |
| show @@datasource |
查看Mycat的数据源信息 |
| show @@datanode | 查看MyCAT现有的分片节点信息 |
| show @@threadpool | 查看MyCat的线程池信息 |
| show @@sql | 查看执行的SQL |
| show @@sql.sum | 查看执行的SQL统计 |
(3)Mycat-eye
- 介绍
Mycat-web(Mycat-eye)是对mycat-server提供监控服务,功能不局限于对mycat-server使用。它通过JDBC连接对Mycat、Mysql监控,监控远程服务器(目前仅限于linux系统)的cpu、内存、网络、磁盘。
Mycat-eye运行过程中需要依赖zookeeper,因此需要先安装zookeeper。
四、读写分离
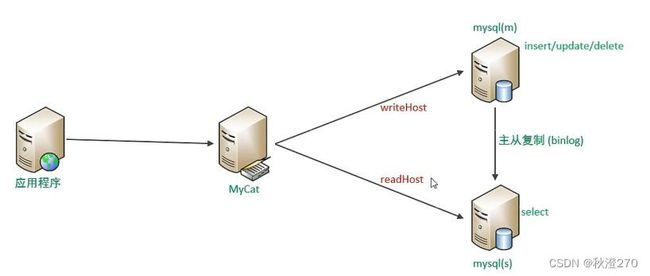
1.介绍
读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务武器。主数据库提供读操作,这样能有效地减轻单台数据库的压力。
通过Mycat即可轻易实现上述功能,不仅可以支持MySQL,也可以支持Oracle和SQL Server。
2.一主一从
(1)原理
MySQL地主从复制,是基于二进制日志(binlog)实现的

(2)环境准备
| 主机 | 角色 | 用户名 | 密码 |
| 192.168.200.211 | master | root | 1234 |
| 192.168.200.212 | slave | root | 1234 |
3.一主一从读写分离
(1)配置
Mycat控制后台数据库地读写分离和负载均衡由schema.xml文件datahost标签地balance属性控制。
(2)测试
连接Mycat,并在Mycat中执行DML、DQL查看是否能够进行读写分离。
4.双主双从
(1)介绍
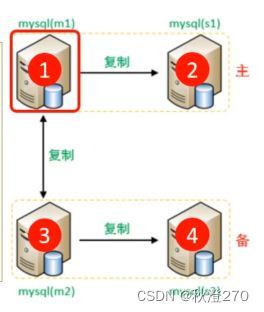
一个主机Master1用于处理所有写请求,他的从机Slave1和另一台主机Master2还有他的从机Savle2负责所有读请求。当Master1主机宕机后,Master2主机负责写请求,Master1、Master2互为备机。构架图如下:

(2)准本工作
(3)搭建
①主库配置(Master1-192.168.200.211)
- 修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围:1-2的32次方-1,默认1
server-id=1
#指定同步的数据库
binlog-do-db=db01
binlog-do-db=db02
binlog-do-db=db03
#在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
- 重启MySQL服务器
systemctl restart mysqld
- 两台主库创建账户并授权
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'itcast'@'%'IDENTIFIED WITH mysql_native-password BY'Root@123456';
#为'itcast‘@’%'用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'2@'%';
通过指令,查看两台主库的二进制日志坐标
show master status;
②从库配置
- 修改配置文件/etc/my.cnf
#mysql服务ID,保证整个集群环境中唯一,取值范围:1-2的32次方-1,默认1
server-id=2
- 重启MySQL服务器
systemctl restart mysqld
- 两台从库配置关联的主库
CHANGE MASTER TO MASTER_HOST='xxx.xxx.xxx.xxx',MASTER_USER='xxx',MASTER_PASSWORD='xxx',MASTER_LOG_FILE='xxx',MASTER_LOG_POS=xxx;
需要注意salve1对应的是master1,salve2对应的是master2.
启动两台从库主从复制,查看从库状态
start slave;
show slave status \G;
- 两台主库相互复制Master2复制Master1,Master1复制Master2
CHANGE MASTER TO MASTER_HOST='xxx.xxx.xxx.xxx',MASTER_USER='xxx',MASTER_PASSWORD='xxx',
MASTER_LOG_FILF='xxx',MASTER_LOG_POS=xxx;
启动两台从库主从复制,查看从库状态
start slave;
show slave status \G;
- 测试

5.双主双从读写分离
(1)配置