当知识图谱遇上预训练语言模型 -- 留言送书
点击下面卡片,关注我呀,每天给你送来AI技术干货!

留言点赞前五名,送该书籍,如果阅读量约3k,就送8本~
知识图谱与语言预训练是什么关系呢?
本文就将从语言预训练模型开始,介绍知识对语言预训练模型的价值,并介绍几个前沿的知识图谱增强语言预训练模型。
01
知识图谱与语言预训练
关于“知识”的话题有两条不同的技术思路。
一条思路认为需要构建知识图谱,利用符号化的表示手段描述知识,才能完成复杂的语言理解和推理问题。
另外一条思路认为可以利用语言预训练模型,从大量文本语料中训练得到一个由大量参数组成的模型,这个模型中包含有参数化表示的知识,可以直接利用这个模型完成智能问答、语言理解、推理等各类任务。
事实上,这两者并非替代关系,而是互补关系。
文本的预训练模型主要捕获的还是词之间的共现关系,虽然在一定程度上能够捕获一些浅层的语义,但是知识层的推理逻辑是复杂的,仅仅依靠词的共现规律捕获这些复杂的推理逻辑是十分困难的。
因此,有越来越多的研究工作关注怎样把知识图谱和语言预训练模型结合起来,将知识图谱注入语言预训练模型中,以提升预训练模型处理复杂问题的能力。
02
语言预训练简介
首先简要介绍语言预训练模型。
在2013年,学者们就提出了词嵌入模型Word2Vec和Glove。
这些模型都是利用词的上下文获得每个单词的词嵌入向量。一个单词表达成词向量后,很容易找出语义相近的其他词汇。
然而,Word2Vec这类模型无法解决一词多义问题。比如多义词 Bank,有两个常用含义,但是Word2Vec无法区分这两个含义。
这是因为它们尽管上下文环境不同,但是在用语言模型训练的时候,不论什么上下文的句子,经过 Word2Vec,都是预测相同的单词 Bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的嵌入空间。
ELMo 提供了一种更为简洁优雅的解决方案。
ELMo 的本质思想是:事先用语言模型学好一个单词的向量,此时多义词无法区分,不过这没关系。
在实际使用词向量时,单词已经具备了特定的上下文了,这时可以根据上下文单词的语义调整单词的向量表示,这样经过调整后的向量表示更能表达在上下文中的具体含义,自然也就解决了多义词的问题了。
所以,ELMo 本身是一个根据当前上下文对词向量动态调整(Finetune)的思路。
当然,语言预训练的里程碑工作当属谷歌提出的BERT。
同ELMo相比,它采用更为强大的Transformer作为文本编码器,并基于掩码语言模型(Masked Language Model)进行预训练。
如图1所示,BERT随机遮蔽掉训练语料中比如15%的词,要求模型能预测这些缺失的词,以此为主要监督信号来获得词的向量表示。BERT模型在多数常见的NLP任务中效果都非常显著。
![]()

图1 BERT语言预训练模型
在BERT模型之后,学者们沿着不同的方向,又陆续提出了若干改进的语言预训练模型。
如图2所示为语言预训练模型的发展示意图,展示了近年来语言预训练模型的传承和发展。
![]()

图2 各种语言预训练模型的发展示意图
03
知识图谱增强的语言预训练模型举例
1.为什么需要知识图谱
我们更关心的问题是知识图谱对于语言预训练模型有什么价值?
尽管纯文本的语言预训练模型可以取得较好的效果,然而由于语言天然存在长尾效应,现有的语言预训练模型难以捕捉低频的实体信息。
而知识图谱含有丰富的结构化知识,其中包含大量的实体知识,可以极大地促进现有的语言预训练模型的学习效果。
可以通过实体链接得到文本包含的实体的三元组信息,进而更好地学习文本中实体的表示。
此外,知识图谱中丰富的结构化知识还有助于支持一些知识驱动的下游任务,如关系抽取、实体分类等。
这些任务对实体表达能力依赖较强,因而长尾低频实体能够很好地通过外部知识图谱学习较好的表示,进而促进下游任务的效果。
越来越多的学者注意到了知识对于预训练语言模型的重要性,因而提出了很多知识(图谱)驱动的语言预训练模型,比如ERNIE模型、KnowBERT模型、WKLM模型、KEPLER模型和K-Adapter模型等。接下来选择几个典型的模型展开介绍。
2.直接用实体向量注入增强语言模型
利用知识图谱增强语言预训练模型的一个最简单的思路是把知识图谱中的实体向量表示直接注入语言模型中。比较典型的模型如ERNIE和KnowBERT。
ERNIE是一个利用大规模语料和知识图谱实现的语言预训练模型。
ERNIE以Wikipedia等作为文本语料输入,WikiData作为知识图谱输入。
在这个模型中,知识图谱作为一个重要的外部知识来源,为语言模型提供丰富的外部知识信息,从而促进语言预训练的效果。
知识驱动的语言预训练存在两个主要挑战:第一个是外部知识怎样融入语言模型中,第二个是怎样避免引入知识带来的噪声问题。
ERNIE模型通过一种层次的Transformer 进行外部知识的融合。
对于抽取并编码的知识信息,ERNIE首先识别文本中的命名实体,然后将这些实体与知识图谱中的实体进行匹配。
ERNIE并不直接使用知识图谱中基于图的事实,而是通过知识图谱嵌入算法(例如 TransE)编码知识图谱的图结构,并将多信息实体嵌入作为 ERNIE 的输入。
与 BERT 类似,ERNIE采用了带掩蔽(Mask)的语言模型,以及预测下一句文本作为预训练目标。
除此之外,为了更好地融合文本和知识特征,ERNIE采用了一种新型预训练目标,即随机掩蔽掉一些对齐了输入文本的命名实体,并要求模型从知识图谱中选择合适的实体以完成对齐。
现存的预训练语言表征模型只利用局部上下文预测缺失词,但 ERNIE 的新目标要求模型同时聚合上下文和知识实体的信息,并同时预测缺失词和实体,从而构建一种知识化的语言表征模型。
如图3所示,ERNIE 的整个模型架构由两个堆叠的模块构成:(1)底层的文本编码器(T-Encoder),负责获取输入词语的词法和句法信息;(2)上层的知识型编码器(K-Encoder),负责将额外的面向词语的知识信息整合自底层的文本信息,这样就可以在一个统一的特征空间中表征词语和实体的异构信息。

图3 ERNIE的模型结构
在ERNIE之后,KnowBERT也采用了类似的实体特征融合技术。KnowBERT通过端到端的方式,将BERT的语言预训练模型和一个实体链接模型同时进行训练,从而在语言模型中引入实体表示信息。这些工作都是通过实体的嵌入向量表示间接地引入知识图谱信息的。
3.利用多任务学习融合知识
前面提到的一些预训练模型虽然取得了较好的效果,但是使用训练好的图谱表示作为输入存在一些问题。
但都面临一个核心的困难是:图谱表示空间难以和语言表示空间融合。
另外一个思路是以外部知识为监督信号,通过多任务学习的方式增强语言预训练模型。
不同于前面介绍的知识驱动语言预训练模型,WKLM设计了一种弱监督训练目标,给定输入文本,首先将原始文本链接到维基百科的实体。然后将部分实体随机替换为同类型的其他实体。
训练时,模型对文本中实体是否被替换进行预测。这种对链接实体随机替换的方式比较容易扩展,同时以一种非常巧妙的方式将实体所包含的外部知识信息转化为弱监督信号,通过额外的多任务学习对语言模型进行训练,如图4所示。
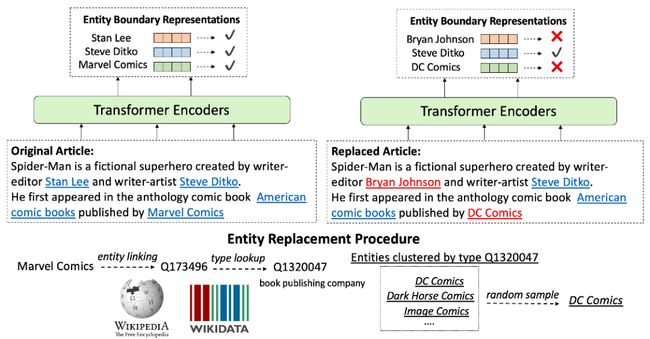
图4 以外部知识作为语言预训练的外部监督信号
该模型训练数据仍为所有的英文的维基百科文本,文本中的实体由维基百科中的实体链接标注好。除了对实体进行替换,训练目标还保留了BERT中基于掩蔽的训练目标,即对字符进行随机替换,但是替换的比例由15%降低为5%。
另外一个模型KEPLER模型主要通过添加类似于TransE的预训练机制增强对应文本的表示,进而增强预训练模型在一些知识图谱有关任务中的效果。
首先,KEPLER基于Wikipedia和Wikidata数据集,将每个实体与对应的维基百科描述相链接,并为每个实体获得其对应的文本描述信息。
之后,对于每一个三元组——<头实体,关系,尾实体>,KEPLER首先采用基于BERT的方法对实体的文本描述学习一个编码器,对每个实体进行编码。
如图5所示,在通过编码器得到头实体和尾实体对应的表示之后,KEPLER采用类似于TransE的训练方法,即基于头实体和关系预测尾实体。也就是对应图中KE Loss。
与此同时,KEPLER还采用BERT经典的基于掩蔽语言模型的损失函数,并使用RoBERTa的原始参数进行初始化。最终KEPLER提出的方法在知识图谱补全和若干NLP任务上均带来了增益,如图5所示。
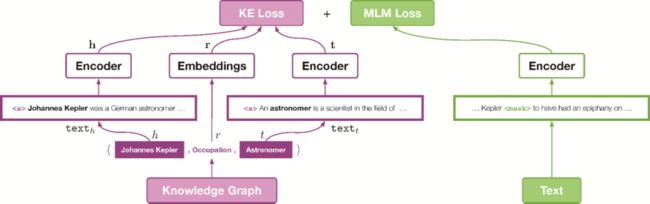
图5 KEPLER模型
4.通过额外模块融入知识
先前的工作主要集中在通过设计注入知识的训练目标,来增强语言模型的训练目标,并通过多任务学习的方式更新模型的全部参数。这样的方式存在两点限制:1)无法进行终身学习,模型的参数在引入新知识时需要重新训练,对于已经学到的知识,会造成灾难性遗忘;2)模型产生的是耦合的表示,为进一步探究引入不同知识的作用带来困难。
K-Adapter是一种灵活、简便的、向语言模型注入知识的方法,可以进行持续知识融合以及产生解耦的表示,保留了语言模型产生的原始表示,并引入多种知识,如图6所示。
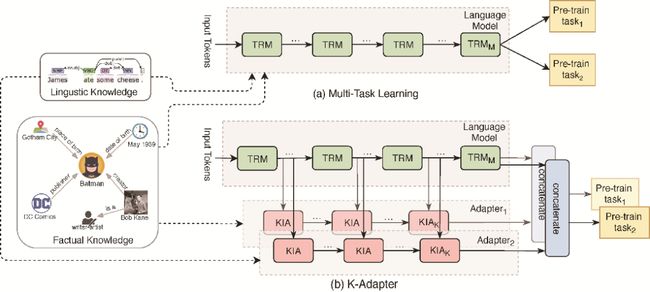
图6 K-Adapter模型
Adapter可以看作一个知识注入的插件,加在语言模型外部,输入包含语言模型中间层输出的隐状态,一种知识类型对应一个Adapter,一个语言模型可以连接多个Adapter,以注入不同类型的知识。
在注入知识的预训练过程中,预训练模型参数是固定的,模型只更新Adaptor参数,这样就有利于避免“知识遗忘”问题。
04
知识驱动的语言预训练总结
知识对于语言的理解至关重要,在语言预训练模型大行其道的当下,将知识融入语言预训练模型中是重要的技术发展方向。
将知识图谱融入语言预训练模型中大致有三种方法,包括直接把图谱表示向量作为特征输入的ERNIE和KnowBERT等模型;通过设计新的预训练任务实现知识注入的KEPLER和WKLM等模型;通过增加额外的模块的K-ADAPTER等模型。
知识的注入未必总是有效的,实验表明,知识注入对于低资源任务和低频的实体是有价值的,但因为外部知识的引入也可能带来噪声,因此也可能反而对语言模型带来模型损失。
留言点赞前五名,送该书籍,如果阅读量约3k,就送前八名~
截止时间:2021.9.3 20:00
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!