python基础语法 百度网盘,python基础语法合集下载
大家好,本文将围绕python基础语法 百度网盘展开说明,python基础语法合集下载是一个很多人都想弄明白的事情,想搞清楚python基础语法手册pdf需要先了解以下几个事情。

python语言的类型
python属于解释型语言
源代码(python)<->解释器(逐行解释每一句源代码)<->操作系统<->cpu
java属于编译型语言
源代码(java)->编译器->可执行文件->操作系统<->cpu
python语言数据的基本类型
容易混淆的几种表现形式
元组( ) 和列表[ ] 类似 只是元组不可以修改 这两个有点类似于C语言中的数组
集合 唯一{ } 和字典类似 只是没有values 字典中的key一定是不可变类型 而且字典查找速度快 缺点是占用内存 同样集合中的元素均是不可变的 所以不能有列表
可变序列和不可变序列
可变序列列和不可变序列区分的标准是是否能够对序列进行增、删、改操作;并且,增删改操作后的对象地址不发生改变。能做增删改操作的序列称为可变序列python的基本知识点总结。反之,不能做增删改操作的序列称为不可变序列。
可变序列:列表、字典、集合
不可变序列:数字、字符串、元组
列表
定义
列表(list)是Python中使用最频繁的数据类型,在其他语言中通常叫做数组,专门用来存储一组数据。
#第一种方式
name_list = [] OR name_list = ['tom','jack']
#第二种方式
data_list = list()
ps: 相当于C语言中的数组 只不过C语言的数组存的是同一类型的数据
count
data_list = ['python', 'java', 'python', 'php']
print(data_list.count("python")) #2
索引[] 列表可以用索引来用数据
name_list = ['张三', '李四']
print(name_list[0]) # 张三
print(name_list[1]) # 李四
append(数据) 在末尾插入数据
val_list = ["Web自动化", "UI自动化", "接口自动化"]
val_list.append("APP自动化")
print(val_list)
# ['Web自动化', 'UI自动化', '接口自动化', 'APP自动化']
ps:
可以插入的各种不同类型的数据 比如数字 字典 元组
extend()
使用新的序列来扩展当前序列,需要一个序列作为参数,它会将该序列中的元素添加到当前列表中
stus.extend(['唐僧','白骨精']) 相当于
stus += ['唐僧','白骨精']
clear()
stus = ['孙悟空','猪八戒','沙和尚','唐僧']
stus.clear() #清空序列 []
insert(位置,数据)
abc = [‘yinsheng’, ‘jiayou’, 1111, (11, 22, 33), {‘abc’: 456}]
abc.insert(0,{“key”:1})
print(abc)
#[{‘key’: 1}, ‘yinsheng’, ‘jiayou’, 1111, (11, 22, 33), {‘abc’: 456}]
remove()
# 删除指定值得元素,如果相同值得元素有多个,只会删除第一个
stus = ['孙悟空','猪八戒','沙和尚','唐僧','猪八戒']
stus.remove('猪八戒')
print(stus) #['孙悟空','沙和尚','唐僧','猪八戒']
pop (列表索引号) 删除某个数据
val_list = ["Web自动化", "UI自动化", "接口自动化"]
val = val_list.pop(0)
print(val, val_list)
# web自动化,['UI自动化', '接口自动化']
ps:
不指定位置号 那么默认删除最后一个
排序
reverse() 反转列表
my_list = [10,1,20,3,4,5,0,-2]
print('修改前',my_list) #[10,1,20,3,4,5,0,-2]
my_list.reverse()
print('修改后',my_list) #[-2, 0, 5, 4, 3, 20, 1, 10]
sort() 默认reverse=false
sort(reverse=true) #降序
sort(reverse=false) #升序
val_list = [8, 100, 30, 10, 40, 2]
val_list.sort(reverse=True)
print(val_list) # [100, 40, 30, 10, 8, 2]
val_list.sort()
print(val_list) #[2, 8, 10, 30, 40, 100]
sorted() 临时排序
val_list = [8, 100, 30, 10, 40, 2]
b= sorted(val_list)
print(val_list) #[8, 100, 30, 10, 40, 2]
print(b) #[2, 8, 10, 30, 40, 100]
嵌套
student_list = [["张三", "18", "功能测试"], {"key":1,"key1":2},(11,222,333)]
print(student_list[1]["key1"]) #2
print(student_list[0][1]) # 18
print(student_list[2][1]) #222
元组
ps: 和列表list 几乎差不多 只是不可以修改 但是这个不可以修改指的是指向永远不变
for example
t = ('a', 'b', ['A', 'B'],111,(2,3,4),{"key":1})
t[2][0] = 'x'
t[2][1] = 'y'
t[5]["key"]=2
print(t)
#('a', 'b', ['x', 'y'], 111, (2, 3, 4), {'key': 2})
定义
元组和列表一样,都可用于存储多个数据,不同之处在于元组的元素不能修改
#第一种方式
user_info = () OR name_list = ('zhangsan',18,1.75)
#第二种方式
info_tuple = tuple()
ps:元组中只包含一个元素时,需要在元素后面添加逗号
如 data=(1,)
查(by索引)
tuple1 = (1, 2, 3)
print(tuple1[1]) # 2
count
tuple1 = (1, 2, 3)
print(tuple1.count(3)) # 1
解包
元组的特殊用法: 交换两个变量的值
num1 = 100
num2 = 200
num2,num1 = num1,num2
print(num1) #200
print(num2) #100
ps:
1.在Python中可以使用对应数据个数的变量,获取对应元组数据中的每一个元素
2.在Python中定义多个元素的元组数据时,小括号可以省略
3.借助以上两个特性,可以通过元组快速实现交换两个变量的值
解包
my_tuple = 10 , 20 , 30 , 40
a , b , *c = my_tuple
print(a,b,c) #10 20 [30, 40]
a , *b , c = my_tuple
print(a,b,c) #10 [20, 30] 40
*a , b , c = my_tuple
print(a,b,c) #[10, 20] 30 40
注意
ps:
# 当元组不是空元组时,括号可以省略
# 如果元组不是空元组,它里边至少要有一个,
字典
定义
test = dict()
test2 = {}
d = dict(name1='孙悟空',age1=18,gender1='男')
print(d) #{'name1': '孙悟空', 'age1': 18, 'gender1': '男'}
#利用双值子序列
d = dict([('name','孙悟饭'),('age',18)])
print(d) #{'name': '孙悟饭', 'age': 18}
增加和修改 字典[键]=值
info = {
"name": "tom",
"age": 18
}
info["salary"] = 100000
print(info) # {'name': 'tom', 'age': 18, 'salary': 100000}
pop(键) 删除
info = {
"name": "tom",
"age": 18,
"gender": "男" }
info.pop("gender")
print(info) # {'name': 'tom', 'age': 18}
get(键) 查询
info = {
"name": "tom",
"age": 18,
"gender": "男" }
print(info.get("name")) # tom
print(info.get("abc")) # None
for key in 字典.keys()
#遍历得到所有键名
info = {
"name": "tom",
"age": 18,
"gender": "男" }
for key in info.keys():
print(key)
for value in 字典.values():
#遍历得到所有的键对应的值
info = {
"name": "tom",
"age": 18,
"gender": "男" }
for value in info.values():
print(value)
for k, v in 字典.items():
#遍历得到所有的键和值
info = {
"name": "tom",
"age": 18,
"gender": "男" }
for k, v in info.items():
print(f"key={k} value={v}")
一些常用方法
setdefault(key, default]) 可以用来向字典中添加key-value
#如果key已经存在于字典中,则返回key对应的value值,不会对字典做任何操作
#如果key不存在,则向字典中添加这个key,并设置value
d = dict([('name','孙悟饭'),('age',18)])
result = d.setdefault('name1','猪八戒')
result2 = d.setdefault('name','11111')
print(result) #猪八戒
print(result2) #孙悟饭
print(d) #{'name': '孙悟饭', 'age': 18, 'name1': '猪八戒'}
update()
#将其他的字典中的key-value添加到当前字典中
#如果有重复的key,则后边的会替换到当前的
d = {'a':1,'b':2,'c':3}
d2 = {'d':4,'e':5,'f':6, 'a':7}
d.update(d2)
print(d) #{'a': 7, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
del
d = {'a': 7, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
del d['a']
print(d) #{'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
del d['e']
print(d) #{'b': 2, 'c': 3, 'd': 4, 'f': 6}
popitem()
#随机删除字典中的一个键值对,一般都会删除最后一个键值对
#删除之后,它会将删除的key-value作为返回值返回
#返回的是一个元组,元组中有两个元素,第一个元素是删除的key,第二个是删除的value
#当使用popitem()删除一个空字典时,会抛出异常 KeyError
d = {'b': 2, 'c': 3, 'd': 4, 'f': 6}
result = d.popitem()
print(result) # ('f', 6)
print(d) # {'b': 2, 'c': 3, 'd': 4}
copy()
# 该方法用于对字典进行浅复制
# 复制以后的对象,和原对象是独立,修改一个不会影响另一个
# 注意,浅复制会简单复制对象内部的值,如果值也是一个可变对象,这个可变对象不会被复制 意味着修改了这个可变对象的值之后 两个地方的值均变化 因为它不独立
d = {'a':{'name':'孙悟空','age':18},'b':2,'c':3}
d2 = d.copy()
print(d2) # {'a': {'name': '孙悟空', 'age': 18}, 'b': 2, 'c': 3}
d2['a']['name'] = '测试一想'
d2['b']=6
print(d2) # {'a': {'name': '测试一想', 'age': 18}, 'b': 6, 'c': 3}
print('d = ',d , id(d)) #d = {'a': {'name': '测试一想', 'age': 18}, 'b': 2, 'c': 3} 2363954785808
print('d2 = ',d2 , id(d2)) #d2 = {'a': {'name': '测试一想', 'age': 18}, 'b': 6, 'c': 3} 2363954786168
clear()
d = {'b': 2, 'c': 3, 'd': 4}
d.clear() #{}
in not in
注意
字典的值可以是任意对象
字典的键可以是任意的不可变对象(int、str、bool、tuple ...),但是一般我们都会使用str
字典的键是不能重复的,如果出现重复的后边的会替换到前边的
集合
定义
a = set()
print(type(a))
a = {1,3,4}
print(type(a))
将列表 字符串 字典 元组转化为集合
s = set([1,2,3,4,5,1,1,2,3,4,5])
print(s) # {1, 2, 3, 4, 5}
s = set('hello')
print(s) # {'l', 'o', 'e', 'h'}
s = set({'a':1,'b':2,'c':3})
print(s) # {'a', 'b', 'c'}
s = (1,2,3,4)
print(set(s)) # {1, 2, 3, 4}
常用方法
in not in
使用in和not in来检查集合中的元素
s = {'a' , 'b' , 1 , 2 , 3 , 1}
print('c' not in s) #True
print('a' in s) #True
add()
s = {'a' , 'b' , 1 , 2 , 3 , 1}
s.add(10)
print(s) #{1, 2, 3, 'a', 10, 'b'}
update()
update() 将一个集合中的元素添加到当前集合中
update()可以传递序列或字典作为参数,字典只会使用键
s = {'a' , 'b' , 1 , 2 , 3 , 1}
s2 = set('hello')
s.update(s2)
print(s) #{1, 2, 3, 'o', 'e', 'a', 'h', 'b', 'l'}
s.update((10,20,30,40,50))
print(s) #{1, 2, 3, 'o', 40, 10, 'e', 'a', 'h', 50, 20, 30, 'b', 'l'}
s.update({10:'ab',20:'bc',100:'cd',1000:'ef'})
print(s) #{1, 2, 3, 100, 'o', 40, 10, 'e', 1000, 'a', 'h', 50, 20, 30, 'b', 'l'}
pop()
pop()随机删除并返回一个集合中的元素
s = {'a' , 'b' , 1 , 2 , 3 , 1}
result = s.pop()
print(result) #1
print(s) #{2, 3, 'a', 'b'}
remove()
s = {'a' , 'b' , 100 , 2 , 3 , 100}
s.remove(100)
print(s) # {2, 3, 'b', 'a'}
clear()
copy() #对集合进行浅复制
集合的运算
&
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# & 交集运算
result = s & s2
print(result) # {3, 4, 5}
|
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# | 并集运算
result = s | s2
print(result) # {1,2,3,4,5,6,7}
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# - 差集
result = s - s2
print(result) # {1, 2}
^
s = {1,2,3,4,5}
s2 = {3,4,5,6,7}
# ^ 异或集 获取只在一个集合中出现的元素
result = s ^ s2
print(result) # {1, 2, 6, 7}
<=
<= 检查一个集合是否是另一个集合的子集
如果a集合中的元素全部都在b集合中出现,那么a集合就是b集合的子集,b集合是a集合超集
a = {1,2,3}
b = {1,2,3,4,5}
result = a <= b # True
result = {1,2,3} <= {1,2,3} # True
result = {1,2,3,4,5} <= {1,2,3} # False
<
< 检查一个集合是否是另一个集合的真子集
如果超集b中含有子集a中所有元素,并且b中还有a中没有的元素,则b就是a的真超集,a是b的真子集
result = {1,2,3} < {1,2,3} # False
result = {1,2,3} < {1,2,3,4,5} # True
大于和>=
# >= 检查一个集合是否是另一个的超集
# > 检查一个集合是否是另一个的真超集
通用方法
包含字符串(str) 元组(tuple) 列表(list)
切片操作
ps: 列表 元组 字符串 均可切片 集合和字典不可切片
数据[起始索引:结束索引:步长]
name = "abcdefg"
print(name[2:5:1]) # cde
print(name[2:5]) # cde
print(name[:5]) # abcde
print(name[1:]) # bcdefg
print(name[:]) # abcdefg
print(name[::2]) # aceg
print(name[:-1]) # abcdef, 负1表示倒数第一个数据print(name[-
4:-1]) # def
print(name[::-1]) # gfedcba
len()
str_data = "hello python"
print(len(str_data)) # 12: 字符中字符个数(包含空格)
list_data = ["python", "java"]
print(len(list_data)) # 2: 列表中元素个数
tuple_data = ("admin", 123456, 8888)
print(len(tuple_data)) # 3: 元组中元素个数
dict_data = {"name": "tom", "age": 18, "gender": "男"}
print(len(dict_data)) # 3: 字典中键值对的个数
加减乘除 不是都是哦
字符串 和 列表 和 元组 可以 + * 字典和集合不行
in or not in
max() min()
count() 对 字典和集合不适用
index_1 = '123'
print(index_1.count('1')) #1
index_1 = [1,2,3]
print(index_1.count(1)) #1
index_1 = (1,2,3)
print(index_1.count(1)) #1
index() 对 字典和集合不适用
index_1 = (1,2,3)
print(index_1.index(1)) #0
index_1 = [1,2,3]
print(index_1.index(3)) #2
index_1 = 'abc'
print(index_1.index('b')) #1
函数
定义的语法格式:
函数名命名遵循标识符命名规则:字母,数字,下划线,不能以数字开头,不用使用系统关键字
def是英文define的缩写
函数名最好能够表达函数内部封装的代码的功能,方便后续的获取调用[见名知意]
def 函数名():
函数封装的代码
模块和包
一个py文件就是一个模块
一个包就是包含多个模块的特殊目录
缺省函数、多值函数、匿名函数
缺省函数
def print_info(name, title="", gender="男生"):
print(f"{title}{name} 是 {gender}")
# 提示:在指定缺省参数的默认值时,应该使用最常见的值作为默认值!
print_info("小明") #小明 是 男生
print_info("老王", title="班长") #班长老王 是 男生
print_info("小美", gender="女生") #小美 是 女生
多值函数
def demo(num, *args):
print(num)
print(args)
demo(1, 2, 3, 4, 5) # 1换行 (2, 3, 4, 5)
def sum_numbers(*args):
num = 0
# 遍历 args 元组求和
for n in args:
num += n
return num
nums = (1, 2, 3)
result = sum_numbers(*nums)
print(f"result={result}") #result=6
匿名函数
user_list = [
{'name': '张三', 'age': 22, 'title': '测试工程师'},
{'name': '李四', 'age': 24, 'title': '开发工程师'},
{'name': '王五', 'age': 21, 'title': '测试工程师'}
]
# 按照age进行排序
user_list.sort(key=lambda m: m["age"])
print(user_list)
基础一步一步实践开始
编码
ANSI 最开始 是美国 那边针对 英语26个单词 几乎采用是1个字节编码 这样范围是256
之后 我们中国有中文 日本有日语 韩国有韩语 这样都出了对应的编码 可这太乱了
于是 unicode 应运而生 采用2个字节编码 但这样对那些英文字母只需1个字节编码的来说 浪费了空间
于是 utf-8 应运而生 采用可变编码UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节 对于英文被编码1个字节 中文通常3个字节 特别偏僻的一般4-6个字节
内存中的编码都是unicode 最后存储的时候转化为utf-8存储
编码 decode 主要是编成 unicode
解码 encode 主要是解编成 utf-8
格式化
格式化的四种形式
name = 'yinsheng'
print('欢迎 '+name+' 光临!')
# 多个参数
print('欢迎',name,'光临!')
# 占位符
print('欢迎 %s 光临!'%name)
# 格式化字符串
print(f'欢迎 {name} 光临!')
迭代
for 循环 也称为 迭代
列表生成式
[x*x for x in range(0,10)]
其实 字典也可以 {x*x for x in range(0,10)}
生成器
列表生成式 换成元组 其实就是 生成器了
g=(x*x for x in range(0,10))
然后通过 next(g) 或者for循环来 for x in g :
还可以弄成函数形式 其中 field就是一个标志
迭代器
生成器的对象 一定是迭代器
字典、集合 列表、元组 字符串 不是迭代器 但是可以通过iter()函数变成迭代器
字典 集合 列表 元组 字符串 生成器 都是可迭代的
返回值_闭包
闭包 就是 函数里面返回函数
调用闭包 创建的函数哪怕一模一样 也不相等
注意闭包函数 里面调用的变量 比如 i 这种有变化的 用函数封装 不要用 for 循环
里面 引用外面的变量要赋值的话 注意nonlocal 声明变量
访问限制
__开头的变量和函数 类外面调用不了
_开头的变量和函数 类外面可以调用 但是不要调用 它已经代表私有的意思在里面了
而要调用以及修改 则类要多加两个函数 get调用获取 和set 修改
继承和多态
当我们定义一个class的时候,我们实际上就定义了一种数据类型。我们定义的数据类型和Python自带的数据类型,比如str、list、dict没什么两样: ---------<廖雪峰>
继承(ocp原则 保持代码不变但是可扩展)
多重继承(排在前面的方法会覆盖后面的方法) 比如
class A(B,C):
pass
假如B和C中都有test方法 B中的test方法优先调用 相当于覆盖率C中的test方法
私有属性和私有方法
当属性和方法只需要在类定义内部使用时,就可以使用私有属性和私有方法特点:在类定义外部,无论是通过类对象还是实例对象均无法获取私有属性和调用私有方法
获取对象信息
dir 获取属性和方法
getattr 获得属性名称的值 getattr(obj,属性名称)
setattr 建立属性 setattr(obj,属性名称,值)
hasattr 判断是否有属性 hasattr(obj,属性名名称)
异常处理
Built-in Exceptions — Python 3.10.5 documentation
捕获异常 try: exception finally
1捕获成功 打印出对应的提示信息
2没有捕获成功 则一层一层抛出错误的信息 要学会定位到真正的地方 且接下来的不会执行 要想有错误信息且执行后面的语句 就要借助logging模块 logging.exception(错误信息)
抛出异常
1.捕获之后 也可以抛出异常
2.抛出的异常和捕获的异常不一样 相当于转化了异常错误类型
进制转换
二进制转十进制 用 int(a,2)
八进制 16进制转十进制 用int(a,8) int(a,16)
十进制转二进制 bin(a)
十进制转八进制 oct(a)
十进制转16进制 hex(a)
python一些内在的原理图片
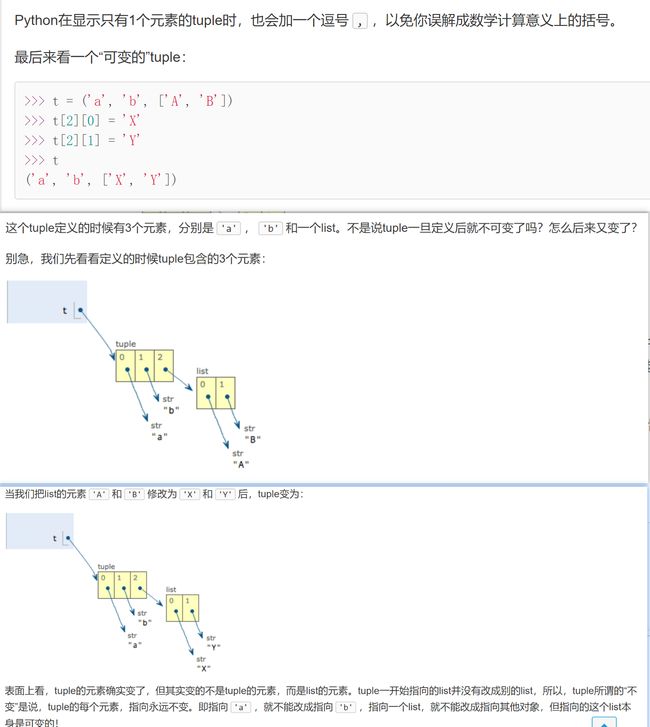
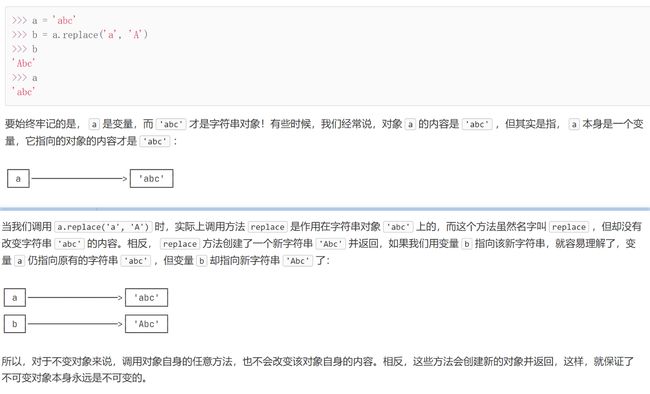
正则表达式
Python3 正则表达式特殊符号及用法(详细列表) - alanminmin - 博客园 (cnblogs.com)
lesson_尚硅谷
数值
Python数值分成了三种:整数、浮点数(小数)、复数
Python中的整数的大小没有限制,可以是一个无限大的整数
如果数字的长度过大,可以使用下划线作为分隔符
python 二进制表现形式 0b 开头 八进制表现形式 0o开头 十进制表现形式 0x开头
10进制的数字不能以0开头 其他进制的整数,只要是数字打印时一定是以十进制的形式显示的
只要带小数对python来说都是浮点数 以及浮点数相加会得到一个不精确的结果
字符串
单引号和双引号不能跨行使用
三重引号可以跨行,并且会保留字符串中的格式
可以使用 \ 作为转义字符,通过转义字符,可以在字符串中使用一些特殊的内容
\' 表示'
\" 表示"
\t 表示制表符
\n 表示换行符
\\ 表示反斜杠
\uxxxx 表示Unicode编码
b = 'hello %3.5s'%'abcdefg' # %3.5s字符串的长度限制在3-5之间
b = 'hello %s' % 123.456 #%s也可对应浮点数和整数
字符串 + 是拼接 *是 复制 -和/不行
布尔值和空值
布尔值实际上也属于整型,True就相当于1,False就相当于0
None(空值)
# None专门用来表示不存在
类型
整数 浮点数 字符串 None bool
转换
int(a) a不能是None 不能是非整数字符串如’yinsheng’ 不能是浮点数字符串如 ‘123.4’
float(a) 和int差不多
str(a) 啥都行
bool(a) 啥都行 0和None转化成的false
ps
int()函数不会对原来的变量产生影响,他是对象转换为指定的类型并将其作为返回值返回
# 如果希望修改原来的变量,则需要对变量进行重新赋值
运算符
1.算术运算符 + - * / //(整除) **(幂) %
2.赋值运算符 += -= /= //= %= *= **=
3.关系运算符 > >= < <= == is is not
关系运算符用来比较两个值之间的关系,总会返回一个布尔值
如果关系成立,返回True,否则返回False
result = 1 == True # True
result = 1 is True # False
result = 1 is not True # True
ps:
is 比较两个对象是否是同一个对象,比较的是对象的id
== 比较两个对象的值是否相等
result = 'ab' > 'b' # False
result = '2' > '11' # True
ps:
当对字符串进行比较时,实际上比较的是字符串的Unicode编码
比较两个字符串的Unicode编码时,是逐位比较的
且我发现 ord('A') 只能转个位字符串
4.逻辑运算符
and or not
and or 都是短路 比如and前面是false后面久不执行了 比如or前面是true后面就不执行了
非布尔值的与或运算 当我们对非布尔值进行与或运算时,Python会将其当做布尔值运算,最终会返回原值(主要看执行到哪一条语句 执行第一条就不执行了 则返回第一条语句的值)
not 对于非布尔值,运算会先将其转换为布尔值 然后进行运算
5.条件运算符
语句1 if 条件表达式 else 语句2
执行流程:
条件运算符在执行时,会先对条件表达式进行求值判断
如果判断结果为True,则执行语句1,并返回执行结果
如果判断结果为False,则执行语句2,并返回执行结果
运算符优先级
查表
流程控制语句
input函数返回的是字符串类型
if else
if elif else
while 条件表达式:
语句
else:
语句
修改元素 针对的是可变序列
stus = ['孙悟空','猪八戒','沙和尚','唐僧','蜘蛛精','白骨精']
stus[0:2] = ['牛魔王','红孩儿']
print(stus) #['牛魔王','红孩儿','沙和尚','唐僧','蜘蛛精','白骨精']
stus[0:2] = ['牛魔王','红孩儿','二郎神']
print(stus) #['牛魔王','红孩儿','二郎神','沙和尚','唐僧','蜘蛛精','白骨精']
stus[0:0] = ['牛魔王']
print(stus) #['牛魔王','牛魔王','红孩儿','二郎神','沙和尚','唐僧','蜘蛛精','白骨精']
stus[::2] = ['牛魔王','红孩儿','二郎神','加油']
print(stus) #['牛魔王','牛魔王','红孩儿','二郎神','二郎神','唐僧','加油','白骨精']
del stus[0:2]
print(stus) #['红孩儿','二郎神','二郎神','唐僧','加油','白骨精']
del stus[::2]
print(stus) #['二郎神','唐僧','白骨精']
stus[0] = '哈哈'
print(stus) #['哈哈','唐僧','白骨精']
del stus[2]
print(stus) #['哈哈','唐僧']
函数参数
位置参数
默认参数
def fn(a = 5 , b = 10 , c = 20):
print('a =',a)
print('b =',b)
print('c =',c)
fn(1 , 2 , 3) #1 2 3
fn(1 , 2) #1 2 20
fn() #5 10 20
关键字参数 **
**形参可以接收其他的关键字参数,它会将这些参数统一保存到一个字典中,字典的key就是参数的名字,字典的value就是参数的值
**形参只能有一个,并且必须写在所有参数的最后
def fn3(b,c,**a) :
print('a =',a,type(a))
print('b =',b)
print('c =',c)
fn3(1,2,k=5,w=6)
#a = {'k': 5, 'w': 6}
#b = 1
#c = 2
可变参数 *
可变参数不是必须写在最后,但是注意,带*的参数后的所有参数,必须以关键字参数的形式传递
如果在形参的开头直接写一个*,则要求我们的所有的参数必须以关键字参数的形式传递
*形参只能接收位置参数,而不能接收关键字参数
def fn2(*a,b,c):
print('a =',a)
print('b =',b)
print('c =',c)
fn2(1,b=2,c=3)
def fn2(a,*b,c):
print('a =',a)
print('b =',b)
print('c =',c)
fn2(1,2,c=3)
def fn3(*a) :
print('a =',a)
fn3(1,2,3,4)
fn3(b=1) #错误
高阶函数
高阶函数(
1.参数是函数 体现为map filtter 等等
2.返回值是函数 体现为闭包 闭包呢又可以导致出装饰器
)
zip 和 dict list 的结合

类方法和实例方法
实例方法
在类中定义,以self为第一个参数的方法都是实例方法
实例方法在调用时,Python会将调用对象作为self传入
实例方法可以通过实例和类去调用
当通过实例调用时,会自动将当前调用对象作为self传入
当通过类调用时,不会自动传递self,此时我们必须手动传递self
类方法
在类内部使用 @classmethod 来修饰的方法属于类方法
类方法的第一个参数是cls,也会被自动传递,cls就是当前的类对象
类方法和实例方法的区别,实例方法的第一个参数是self,而类方法的第一个参数是cls
实例方法当通过类调用时,不会自动传递self,此时我们必须手动传递self
类方法可以通过类去调用,也可以通过实例调用,没有区别
例子
class A(object):
def test(self):
print('这是test方法~~~ ' , self)
@classmethod
def test_2(cls):
print('这是test_2方法,他是一个类方法~~~ ',cls)
print(cls.count)
a = A()
a.test() 等价于 A.test(a)
A.test_2() 等价于 a.test_2()
json是字典的字符串的格式,两种可以相互转换
内置函数
find count index isalpha、isdigit、isspace pow abs
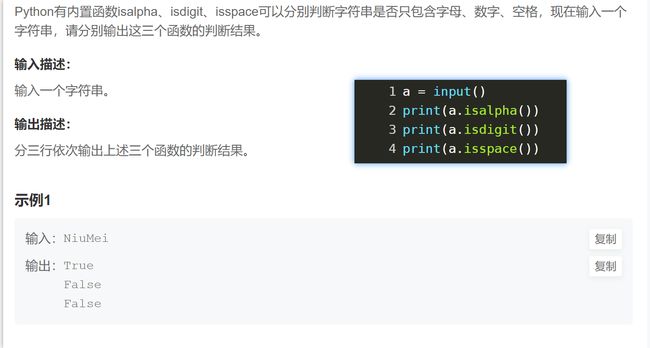
字符串 find count (ps xx.find(‘寻找的字符串’,start,end) 返回找到的第一个下标位置 没有找到则返回-1)
(ps xx.count(‘寻找的字符串’) 返回对应数量)
join(ps ‘按啥分隔’.join(xx) xx 可以是字符串 列表 元组)
a = '123456' #也可以是列表或元组
b = ' '.join(a)
print([b]) #['1 2 3 4 5 6']
print(type(b)) #
round()
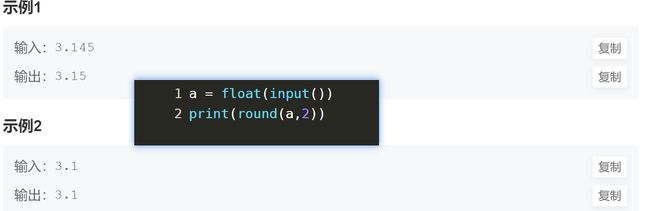
eval()
# a = ' 3 * 7 '
# print(eval(a)) #21