MIT-BEVFusion系列七--量化2_Camera、Fuser、Decoder网络的量化
目录
-
-
-
- Camera 量化
-
- Camera Backbone (Resnet50) 量化
-
- 替换量化层,增加residual_quantizer,修改bottleneck的前向
- 对 Add 操作进行量化
- Camera Neck (GeneralizedLSSFPN) 量化
-
- 将 Conv2d 模块替换为 QuantConv2d 模块
- Camera Neck 中添加对拼接操作的量化
- 替换 Camera Neck 中的 Forward
- Camera VTransform 量化
-
- 将 Conv2d 模块替换为 QuantConv2d 模块
- 模型中所有的拼接使用相同的 scale
-
- 处理 Camera Backbone 的 layer3 中的 concat
- 处理 Camera Backbone 的 layer3 中的 concat
- Fuser 量化
-
- 将 Conv2d 模块替换为 QuantConv2d 模块
- Decoder 量化
-
-
Camera 量化
从终端输出、onnx、csdn上博主网络结构图、代码四个角度熟悉camera的backbone即Resnet50网络的结构。
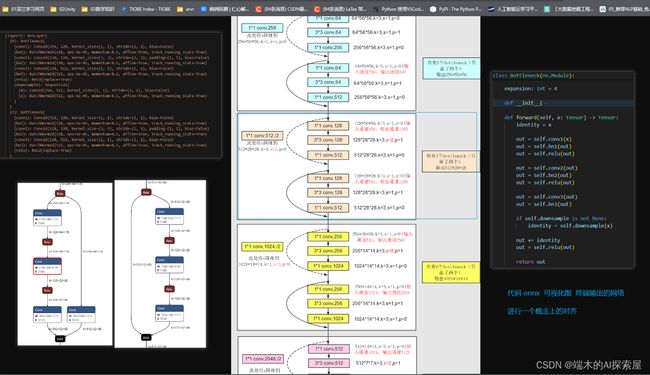

- 观察
model.encoders.camera、neck、vtransform- 组成部分
backbone、
- 组成部分
ModuleDict(
(backbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': '[https://download.pytorch.org/models/resnet50-0676ba61.pth'}](https://download.pytorch.org/models/resnet50-0676ba61.pth'%7D)
(neck): GeneralizedLSSFPN(
(lateral_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(3072, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
(fpn_convs): ModuleList(
(0): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(vtransform): DepthLSSTransform(
(dtransform): Sequential(
(0): Conv2d(1, 8, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(8, 32, kernel_size=(5, 5), stride=(4, 4), padding=(2, 2))
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(32, 64, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2))
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
(depthnet): Sequential(
(0): Conv2d(320, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 198, kernel_size=(1, 1), stride=(1, 1))
)
(downsample): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(80, 80, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
)
)
)
Camera Backbone (Resnet50) 量化

对 camera backbone 进行量化
替换量化层,增加residual_quantizer,修改bottleneck的前向
389行,pytorch_quantization中支持的层替换为量化层。
下图剩余部分遍历model_camera_backbone的所有模块,找到bottleneck.__class__.__name__为Bottleneck的模块,即有加法(残差)的模块,手动增加residual_quantizer层,residual_quantizer层的量化起使用Bottleneck的模块中名字为conv1的卷积层的量化器(bottleneck.conv1._input.quantizer)这是为了为量化加法即QuantAdd做准备。
通常,量化能考虑到加法、concat等方法, 防止reformate节点,已经算比较精细的量化了。

bottleneck.__class__.__name__举例
'TensorQuantizer'
'BatchNorm2d'
'Bottleneck'
'QuantConv2d'
'Sequential'

遍历` _DEFAULT_QUANT_MAP 中的所有量化映射条目,将每个条目中的 orig_mod (原始模块) 中的 mod_name (模块属性名称) 对应的属性提取出来,然后将提取的属性的 id 作为 key,属性本身作为 value 储存在 module_dict 中。
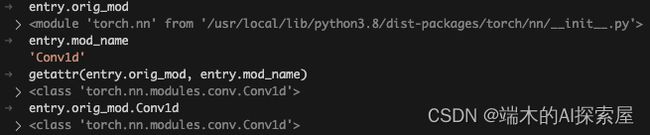
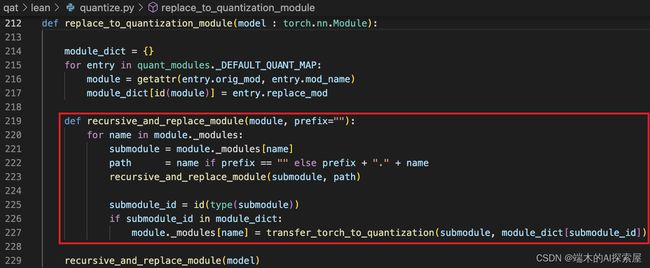
之后会对 model (resnet50) 中的所有子模块进行遍历,知道当前的模块中没有子模块为止,查看当前的模块的 id 是否在之前的 module_dict 中,如果存在,这个模块就会被替换为量化后的模块。

上图188行,使用__new__创建一个空的量化模块对象,遍历需要量化的模块nninstance中的所有属性和属性的值,并将获得属性和值添加到量化模块quant_instance对象中,这样就可以保证量化模块对象与需要量化的模块具有相同的属性。
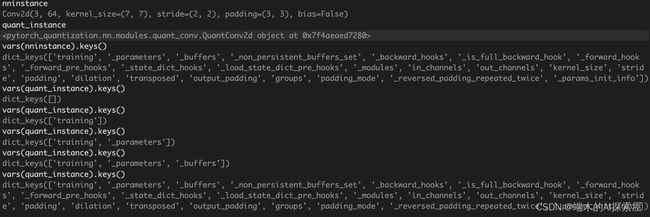
添加属性的过程
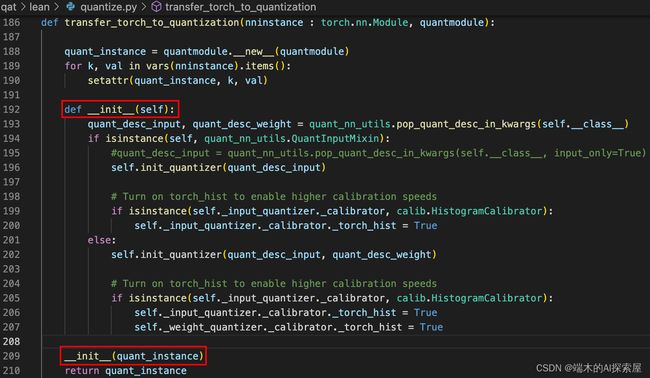
上图289行,调用__init__函数进行初始化,这里的 self 就是 quant_instance。主要是初始化 QuantInputMixin中的输入的量化描述器或者 QuantMixin 中的输入和权重的量化描述器。
以量化卷积为例,pytorch_quantization中的量化卷积继承两个类,看下图,分别是nn的_ConvNd以及pytorch_quantization中的QuantMixin。

继承QuantMixin类的通常是activation(input)与weight都要量化的,比如卷积

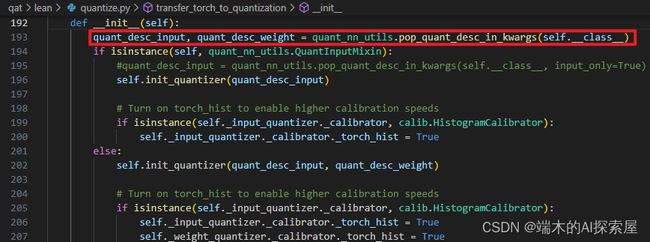

上上图193行,这里会将 kwargs 中的键为 quant_desc_input的值 pop 出来,如果不存在,就是用默认的输入量化描述器。
上图162行的 input_only 就表示是 QuantInputMixin 还是 QuantMixin,影响后续返回的量化描述器的个数。

- 上图
self.init_quantizer就是调用QuantInputMixin或者QuantMixin的类方法,来创建self._input_quantizer以及self._weight_quantizer

self._input_quantizer 和 self._weight_quantizer 会根据上面默认的量化描述器进行初始化,因为最开始我们对每个 DEAFULT_QUANT_MAP 都设置了 _calib_method 为 'histogram’,所以上图创建 TensorQuantizer 对象时,就会将 self._input_quantizer._calibrator 设置为一个 HistogramCalibrator 对象。
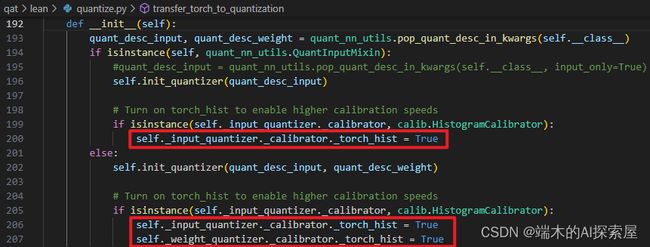
根据 self.init_quantizer 中的配置,上图对于卷积的input来说,self._input_quantizer._calibrator 就是 calib.HistorgramsCalirator 的对象。
上图200行打开_torch_hist开关,来开启高性能的标定。否则标定将会非常慢
总的来说,init 函数的作用就是为输入 (和权重) 初始化量化器和量化方法。
replace_to_quantization_module 函数中,先判断 camer backbone 中的不可再分的子模块是否有匹配的可量化模块,如果存在,就将这个子模块替换为量化模块,并未量化模块进行初始化。在下面用于替换其他 BEVFusion 网络中的子模块时,也是相同的作用。
对 Add 操作进行量化

之后需要对 resnet50 模型中的所有 Bottleneck 模块进行修改。Resnet50 中有四个残差块,残差块中的 Bottleneck 的数量设置为 [3, 4, 6, 3],每个残差块的第一个 Bottleneck 中才具有 Downsample 模块。
![]()
将 Bottleneck 的 Downsample 中的卷积层的输入量化器设置为与该残差块中的第一个卷积层的输入量化器,主要是为了避免在残差连接时进行精度的转换。

然后对 bottleneck 添加一个 residule_quantizer 属性用于对残差计算进行量化。
- 举例if中增加的
residual_quantizer- 下图右下角WAATCH中显示
name=layer2.0对应resnet的第2个ResLayer,有4个Bottleneck,第一个bottleneck有downsample。就会触发if选项。 - 第315行执行完毕。就会发现在
downsample下多出了residual_quantizer。per-tensor量化,直方图校准。见下方文本框
- 下图右下角WAATCH中显示


Bottleneck(
(conv1): QuantConv2d(
256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): QuantConv2d(
128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): QuantConv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): QuantConv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residual_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)
- 举例
else中增加的residual_quantizer- 直接在Bottleneck最后增加(residual_quantizer)

- 直接在Bottleneck最后增加(residual_quantizer)
Bottleneck(
(conv1): QuantConv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): QuantConv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): QuantConv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(_input_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
(_weight_quantizer): TensorQuantizer(8bit fake axis=0 amax=dynamic calibrator=MaxCalibrator scale=1.0 quant)
)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(residual_quantizer): TensorQuantizer(8bit fake per-tensor amax=dynamic calibrator=HistogramCalibrator scale=1.0 quant)
)


对原始输入通过residual_quantizer再去和out相加

原始的bottleneck.forward
最后将 bottleneck.forward 替换为自定义的函数 (hook_bottleneck_forward) 进行前向。通过对比可以发现,区别在于进行量化时,会将 identity,即对输入进行与卷积操作相同的量化精度,这样在后续进行残差操作时,可以保证不会发生 reformat。

找到Bottleneck后,打印的模块信息,也可以确认它在每层的数量为[3, 4, 6, 3]
总结一下 camera backbone 的量化流程
-
先遍历 resnet50 中所有的子模块,将 Conv2d 替换为量化模块并初始化一些量化的参数,

未量化前

量化后

量化后与量化前onnx可视化对比
- 之后将 resnet50 中的 bottleneck 中的残差计算替换为包含了量化的计算方法。
Camera Neck (GeneralizedLSSFPN) 量化

将 Conv2d 模块替换为 QuantConv2d 模块

这里与量化 camera backbone 时的操作相同,会将模型中的子模块替换为量化模块并初始化量化模块。在 neck 中,torch.nn.Conv2d 模块会被替换为 quant_nn.QuantConv2d 模块。

替换量化模块前的neck网络结构
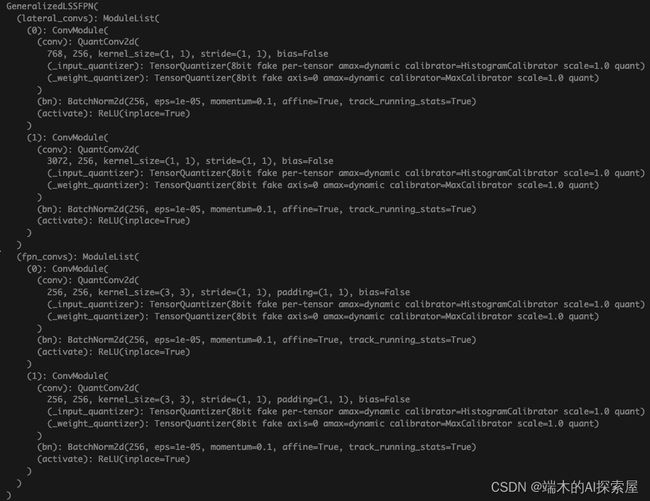
替换量化模块后的neck网络结构
Camera Neck 中添加对拼接操作的量化

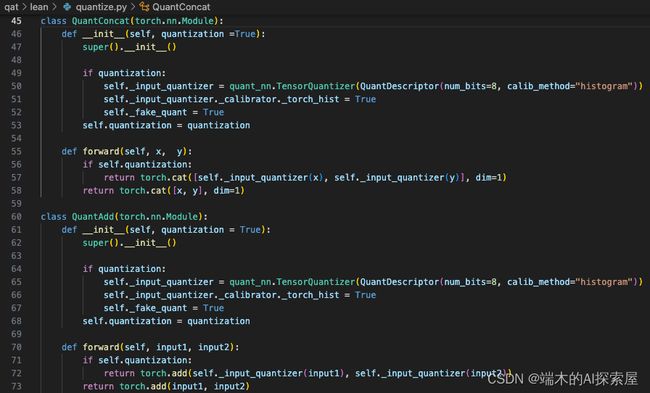
上图50行,创建 _input_quantizer,使用一个精度为 8,校准方法为 histogram 的 QuantDescriptor 创建的 TensorQuantizer 赋值,将输入量化器的 _calibrator_torch_hist 设置为 True,并将 _fake_quant 也设置为 True。
在前向中,如果需要量化,就会使用输入量化器对输入进行伪量化 (QDQ),之后再进行拼接或相加的操作,这里可以看到对多个输入也使用了相同的输入量化器,保证进行相同精度的量化。

替换 Camera Neck 中的 Forward


执行了新添加的两个quant_concat的前向
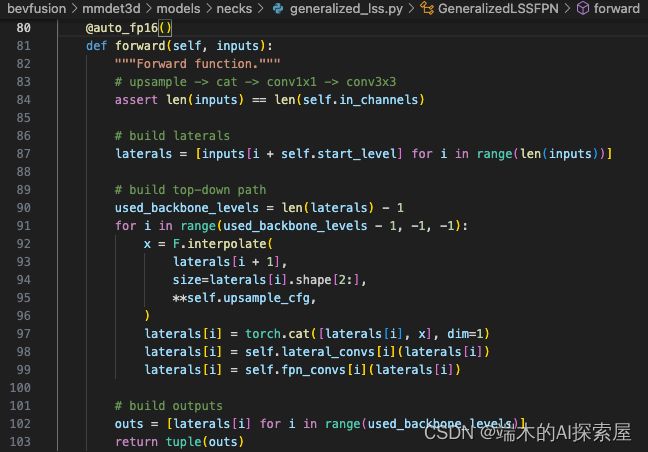
原来 GeneralizedLSSFPN 的 forward
对比之后,可以看到区别在于拼接方法的使用。在自定义的 forward 中,会将原来的 torch.concat 替换为自定义的 QuantConcat 对象,如果需要进行量化,就会对两个输入张量进行相同量化精度操作,再将这两个量化的结果通过 torch.concat 操作进行拼接。
Camera VTransform 量化

对 camera vtransform 中的 dtransform 和 depthnet 进行量化。

将 Conv2d 模块替换为 QuantConv2d 模块

将模型中这两个模块中的子模块替换为量化模块并初始化量化模块,主要就是将 torch.nn.Conv2d 替换为 quant_nn.QuantConv2d。
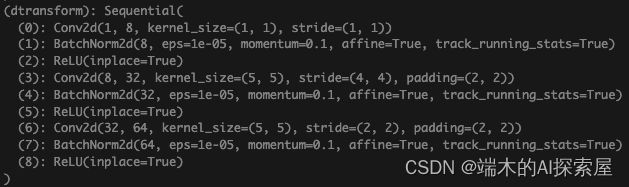
替换量化模块前的dtransform网络结构
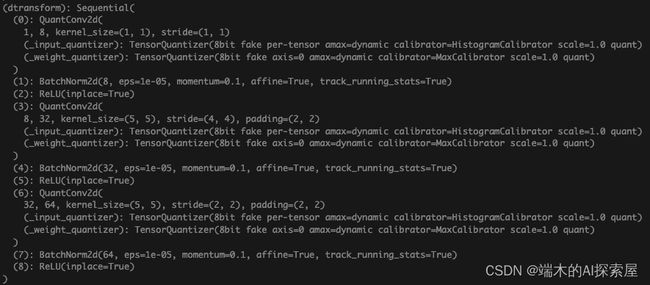
替换量化模块后的dtransform网络结构

替换量化模块前的depthnet网络结构
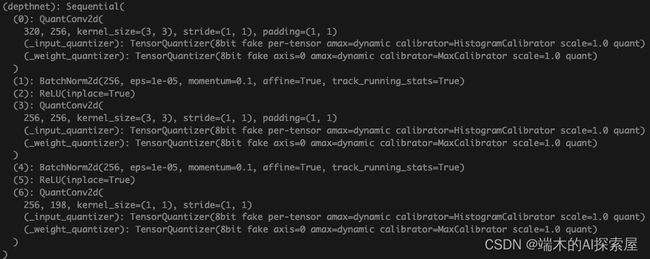
替换量化模块后的depthnet网络结构
模型中所有的拼接使用相同的 scale
这种做法在最开始提到过,主要是为了使用 TensorRT 前向时提高性能。
处理 Camera Backbone 的 layer3 中的 concat

处理 Camera Backbone 的 layer3 中的 concat

Fuser 量化
将 Conv2d 模块替换为 QuantConv2d 模块
将模型中的子模块替换为量化模块并初始化量化模块,主要就是将 torch.nn.Conv2d 替换为 quant_nn.QuantConv2d。

替换量化模块前的ConvFuser网络结构

替换量化模块后的ConvFuser网络结构
Decoder 量化
- 也是主要替换卷积,后decoder中是transformer结构,在导出onnx时会有所不同
- 结构
_ModuleDict(_
_ (backbone): SECOND(_
_ (blocks): ModuleList(_
_ (0): Sequential(_
_ (0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (2): ReLU(inplace=True)_
_ (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (4): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (5): ReLU(inplace=True)_
_ (6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (7): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (8): ReLU(inplace=True)_
_ (9): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (10): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (11): ReLU(inplace=True)_
_ (12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (13): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (14): ReLU(inplace=True)_
_ (15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (16): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (17): ReLU(inplace=True)_
_ )_
_ (1): Sequential(_
_ (0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)_
_ (1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (2): ReLU(inplace=True)_
_ (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (4): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (5): ReLU(inplace=True)_
_ (6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (7): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (8): ReLU(inplace=True)_
_ (9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (10): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (11): ReLU(inplace=True)_
_ (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (13): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (14): ReLU(inplace=True)_
_ (15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)_
_ (16): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (17): ReLU(inplace=True)_
_ )_
_ )_
_ )_
_ init_cfg={'type': 'Kaiming', 'layer': 'Conv2d'}_
_ (neck): SECONDFPN(_
_ (deblocks): ModuleList(_
_ (0): Sequential(_
_ (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)_
_ (1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (2): ReLU(inplace=True)_
_ )_
_ (1): Sequential(_
_ (0): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)_
_ (1): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)_
_ (2): ReLU(inplace=True)_
_ )_
_ )_
_ )_
_ init_cfg=[{'type': 'Kaiming', 'layer': 'ConvTranspose2d'}, {'type': 'Constant', 'layer': 'NaiveSyncBatchNorm2d', 'val': 1.0}]_
_)_