Structured Streaming
目录
一、概述
(一)基本概念
(二)两种处理模型
(三)Structured Streaming和Spark SQL、Spark Streaming关系
二、编写Structured Streaming程序的基本步骤
(一)实现步骤
(二)运行测试
三、输入源
(一)File源
(二)Kafka源
(三)Socket源
(四)Rate源
四、输出操作
(一)启动流计算
(二)输出模式
(三)输出接收器
一、概述
提供端到端的完全一致性是设计Structured Streaming 的关键目标之一,为了实现这一点,Spark设计了输入源、执行引擎和接收器,以便对处理的进度进行更可靠的跟踪,使之可以通过重启或重新处理,来处理任何类型的故障。如果所使用的源具有偏移量来跟踪流的读取位置,那么,引擎可以使用检查点和预写日志,来记录每个触发时期正在处理的数据的偏移范围;此外,如果使用的接收器是“幂等”的,那么通过使用重放、对“幂等”接收数据进行覆盖等操作,Structured Streaming可以确保在任何故障下达到端到端的完全一致性。
Spark一直处于不停的更新中,从Spark 2.3.0版本开始引入持续流式处理模型后,可以将原先流处理的延迟降低到毫秒级别。
(一)基本概念
Structured Streaming的关键思想是将实时数据流视为一张正在不断添加数据的表。可以把流计算等同于在一个静态表上的批处理查询,Spark会在不断添加数据的无界输入表上运行计算,并进行增量查询。

在无界表上对输入的查询将生成结果表,系统每隔一定的周期会触发对无界表的计算并更新结果表。如图Structured Streaming编程模型。

(二)两种处理模型
1、微批处理
Structured Streaming默认使用微批处理执行模型,这意味着Spark流计算引擎会定期检查流数据源,并对自上一批次结束后到达的新数据执行批量查询。数据到达和得到处理并输出结果之间的延时超过100毫秒。

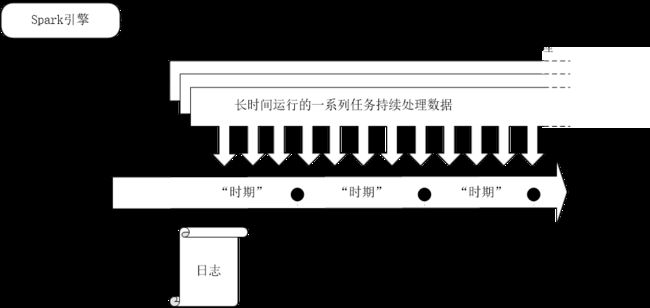
2、持续处理模型
Spark从2.3.0版本开始引入了持续处理的试验性功能,可以实现流计算的毫秒级延迟。在持续处理模式下,Spark不再根据触发器来周期性启动任务,而是启动一系列的连续读取、处理和写入结果的长时间运行的任务。
(三)Structured Streaming和Spark SQL、Spark Streaming关系
Structured Streaming处理的数据跟Spark Streaming一样,也是源源不断的数据流,区别在于,Spark Streaming采用的数据抽象是DStream(本质上就是一系列RDD),而Structured Streaming采用的数据抽象是DataFrame。
Structured Streaming可以使用Spark SQL的DataFrame/Dataset来处理数据流。虽然Spark SQL也是采用DataFrame作为数据抽象,但是,Spark SQL只能处理静态的数据,而Structured Streaming可以处理结构化的数据流。这样,Structured Streaming就将Spark SQL和Spark Streaming二者的特性结合了起来。
Structured Streaming可以对DataFrame/Dataset应用前面章节提到的各种操作,包括select、where、groupBy、map、filter、flatMap等。
Spark Streaming只能实现秒级的实时响应,而Structured Streaming由于采用了全新的设计方式,采用微批处理模型时可以实现100毫秒级别的实时响应,采用持续处理模型时可以支持毫秒级的实时响应。
二、编写Structured Streaming程序的基本步骤
编写Structured Streaming程序的基本步骤包括:
(1)导入pyspark模块
(2)创建SparkSession对象
(3)创建输入数据源
(4)定义流计算过程
(5)启动流计算并输出结果
实例任务:一个包含很多行英文语句的数据流源源不断到达,Structured Streaming程序对每行英文语句进行拆分,并统计每个单词出现的频率。
(一)实现步骤
1、步骤一:导入pyspark模块
导入PySpark模块,代码如下:
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode由于程序中需要用到拆分字符串和展开数组内的所有单词的功能,所以引用了来自pyspark.sql.functions里面的split和explode函数。
2、步骤二:创建SparkSession对象
创建一个SparkSession对象,代码如下:
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')3、步骤三:创建输入数据源
创建一个输入数据源,从“监听在本机(localhost)的9999端口上的服务”那里接收文本数据,具体语句如下:
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()4、步骤四:定义流计算过程
有了输入数据源以后,接着需要定义相关的查询语句,具体如下:
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()5、步骤五:启动流计算并输出结果
定义完查询语句后,下面就可以开始真正执行流计算,具体语句如下:
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.trigger(processingTime="8 seconds") \
.start()
query.awaitTermination()(二)运行测试
把上述五步的代码写入文件StructuredNetworkWordCount.py。在执行StructuredNetworkWordCount.py之前,需要启动HDFS。启动HDFS的命令如下:
start-dfs.sh新建一个终端(记作“数据源终端”),输入如下命令:
nc -lk 9999再新建一个终端(记作“流计算终端”),执行如下命令:
cd /usr/local/mycode/structuredstreaming/
spark-submit StructuredNetworkWordCount.py为了模拟文本数据流,可以在“数据源终端”内用键盘不断敲入一行行英文语句,nc程序会把这些数据发送给StructuredNetworkWordCount.py程序进行处理,比如输入如下数据:
apache spark
apache hadoop
则在“流计算终端”窗口内会输出类似以下的结果信息:
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| word|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| word|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+
三、输入源
(一)File源
File源(或称为“文件源”)以文件流的形式读取某个目录中的文件,支持的文件格式为csv、json、orc、parquet、text等。需要注意的是,文件放置到给定目录的操作应当是原子性的,即不能长时间在给定目录内打开文件写入内容,而是应当采取大部分操作系统都支持的、通过写入到临时文件后移动文件到给定目录的方式来完成。
File源的选项(option)主要包括如下几个。
(1)path:输入路径的目录,所有文件格式通用。path支持glob通配符路径,但是目录或glob通配符路径的格式不支持以多个逗号分隔的形式。
(2)maxFilesPerTrigger:每个触发器中要处理的最大新文件数(默认无最大值)。
(3)latestFirst:是否优先处理最新的文件,当有大量文件积压时,设置为True可以优先处理新文件,默认为False。
(4)fileNameOnly:是否仅根据文件名而不是完整路径来检査新文件,默认为False。如果设置
为True,则以下文件将被视为相同的文件,因为它们的文件名"dataset.txt"相同:
这里以一个JSON格式文件的处理来演示File源的使用方法,主要包括以下两个步骤:
(1)创建程序生成JSON格式的File源测试数据
(2)创建程序对数据进行统计
1、创建程序生成JSON格式的File源测试数据
为了演示JSON格式文件的处理,这里随机生成一些JSON格式的文件来进行测试。代码文件spark_ss_filesource_generate.py内容如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 导入需要用到的模块
import os
import shutil
import random
import time
TEST_DATA_TEMP_DIR = '/tmp/'
TEST_DATA_DIR = '/tmp/testdata/'
ACTION_DEF = ['login', 'logout', 'purchase']
DISTRICT_DEF = ['fujian', 'beijing', 'shanghai', 'guangzhou']
JSON_LINE_PATTERN = '{{"eventTime": {}, "action": "{}", "district": "{}"}}\n‘
# 测试的环境搭建,判断文件夹是否存在,如果存在则删除旧数据,并建立文件夹
def test_setUp():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)
os.mkdir(TEST_DATA_DIR)
# 测试环境的恢复,对文件夹进行清理
def test_tearDown():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)
# 生成测试文件
def write_and_move(filename, data):
with open(TEST_DATA_TEMP_DIR + filename,
"wt", encoding="utf-8") as f:
f.write(data)
shutil.move(TEST_DATA_TEMP_DIR + filename,
TEST_DATA_DIR + filename)
if __name__ == "__main__":
test_setUp()
for i in range(1000):
filename = 'e-mall-{}.json'.format(i)
content = ''
rndcount = list(range(100))
random.shuffle(rndcount)
for _ in rndcount:
content += JSON_LINE_PATTERN.format(
str(int(time.time())),
random.choice(ACTION_DEF),
random.choice(DISTRICT_DEF))
write_and_move(filename, content)
time.sleep(1)
test_tearDown()
这段程序首先建立测试环境,清空测试数据所在的目录,接着使用for循环一千次来生成一千个文件,文件名为“e-mall-数字.json”, 文件内容是不超过100行的随机JSON行,行的格式是类似如下:
{"eventTime": 1546939167, "action": "logout", "district": "fujian"}\n2、创建程序对数据进行统计
spark_ss_filesource.py”,其代码内容如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 导入需要用到的模块
import os
import shutil
from pprint import pprint
from pyspark.sql import SparkSession
from pyspark.sql.functions import window, asc
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType
# 定义JSON文件的路径常量
TEST_DATA_DIR_SPARK = 'file:///tmp/testdata/'
if __name__ == "__main__":
# 定义模式,为时间戳类型的eventTime、字符串类型的操作和省份组成
schema = StructType([
StructField("eventTime", TimestampType(), True),
StructField("action", StringType(), True),
StructField("district", StringType(), True)])
spark = SparkSession \
.builder \
.appName("StructuredEMallPurchaseCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark \
.readStream \
.format("json") \
.schema(schema) \
.option("maxFilesPerTrigger", 100) \
.load(TEST_DATA_DIR_SPARK)
# 定义窗口
windowDuration = '1 minutes'
windowedCounts = lines \
.filter("action = 'purchase'") \
.groupBy('district', window('eventTime', windowDuration)) \
.count() \
.sort(asc('window'))
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.option('truncate', 'false') \
.trigger(processingTime="10 seconds") \
.start()
query.awaitTermination()
3、测试运行程序
程序运行过程需要访问HDFS,因此,需要启动HDFS,命令如下:
start-dfs.sh新建一个终端,执行如下命令生成测试数据:
cd /usr/local/mycode/structuredstreaming/file
python3 spark_ss_filesource_generate.py新建一个终端,执行如下命令运行数据统计程序:
cd /usr/local/mycode/structuredstreaming/file
spark-submit spark_ss_filesource.py运行程序以后,可以看到类似如下的输出结果:
-------------------------------------------
Batch: 0
-------------------------------------------
+---------+------------------------------------------+-----+
|district |window |count|
+---------+------------------------------------------+-----+
|guangzhou|[2019-01-08 17:19:00, 2019-01-08 17:20:00]|283 |
|shanghai |[2019-01-08 17:19:00, 2019-01-08 17:20:00]|251 |
|fujian |[2019-01-08 17:19:00, 2019-01-08 17:20:00]|258 |
|beijing |[2019-01-08 17:19:00, 2019-01-08 17:20:00]|258 |
|guangzhou|[2019-01-08 17:20:00, 2019-01-08 17:21:00]|492 |
|beijing |[2019-01-08 17:20:00, 2019-01-08 17:21:00]|499 |
|fujian |[2019-01-08 17:20:00, 2019-01-08 17:21:00]|513 |
|shanghai |[2019-01-08 17:20:00, 2019-01-08 17:21:00]|503 |
|guangzhou|[2019-01-08 17:21:00, 2019-01-08 17:22:00]|71 |
|fujian |[2019-01-08 17:21:00, 2019-01-08 17:22:00]|74 |
|shanghai |[2019-01-08 17:21:00, 2019-01-08 17:22:00]|66 |
|beijing |[2019-01-08 17:21:00, 2019-01-08 17:22:00]|52 |
+---------+------------------------------------------+-----+
(二)Kafka源
Kafka源是流处理最理想的输入源,因为它可以保证实时和容错。Kafka源的选项(option)包括如下几个。
(1)assign:指定所消费的Kafka主题和分区。
(2)subscribe:订阅的Kafka主题,为逗号分隔的主题列表。
(3)subscribePattern:订阅的Kafka主题正则表达式,可匹配多个主题。
(4)kafka.bootstrap.servers:Kafka服务器的列表,逗号分隔的 "host:port"列表。
(5)startingOffsets:起始位置偏移量。
(6)endingOffsets:结束位置偏移量。
(7)failOnDataLoss:布尔值,表示是否在Kafka数据可能丢失时(主题被删除或位置偏移量超出范围等)触发流计算失败。一般应当禁止,以免误报。
在这个实例中,使用生产者程序每0.1秒生成一个包含2个字母的单词,并写入Kafka的名称为“wordcount-topic”的主题(Topic)内。Spark的消费者程序通过订阅wordcount-topic,会源源不断收到单词,并且每隔8秒钟对收到的单词进行一次词频统计,把统计结果输出到Kafka的主题wordcount-result-topic内,同时,通过2个监控程序检查Spark处理的输入和输出结果。
1、启动Kafka
在Linux系统中新建一个终端(记作“Zookeeper终端”),输入下面命令启动Zookeeper服务:
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
不要关闭这个终端窗口,一旦关闭,Zookeeper服务就停止了。另外打开第二个终端(记作“Kafka终端”),然后输入下面命令启动Kafka服务:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties不要关闭这个终端窗口,一旦关闭,Kafka服务就停止了。
再新开一个终端(记作“监控输入终端”),执行如下命令监控Kafka收到的文本:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordcount-topic再新开一个终端(记作“监控输出终端”),执行如下命令监控输出的结果文本:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordcount-result-topic2、编写生产者(Producer)程序
代码文件spark_ss_kafka_producer.py内容如下:
#!/usr/bin/env python3
import string
import random
import time
from kafka import KafkaProduce
if __name__ == "__main__":
producer = KafkaProducer(bootstrap_servers=['localhost:9092'])
while True:
s2 = (random.choice(string.ascii_lowercase) for _ in range(2))
word = ''.join(s2)
value = bytearray(word, 'utf-8')
producer.send('wordcount-topic', value=value).get(timeout=10)
time.sleep(0.1)
如果还没有安装Python3的Kafka支持,需要按照如下操作进行安装:
(1)首先确认有没有安装pip3,如果没有,使用如下命令安装:
apt-get install pip3(2)安装kafka-python模块,命令如下:
pip3 install kafka-python然后在终端中执行如下命令运行生产者程序:
cd /usr/local/mycode/structuredstreaming/kafka/
python3 spark_ss_kafka_producer.py生产者程序执行以后,在“监控输入终端”的窗口内就可以看到持续输出包含2个字母的单词。
3、编写消费者(Consumer)程序
代码文件spark_ss_kafka_consumer.py内容如下:
#!/usr/bin/env python3
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredKafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN‘)
lines = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", 'wordcount-topic') \
.load() \
.selectExpr("CAST(value AS STRING)")
wordCounts = lines.groupBy("value").count()
query = wordCounts \
.selectExpr("CAST(value AS STRING) as key", "CONCAT(CAST(value AS STRING), ':', CAST(count AS STRING)) as value") \
.writeStream \
.outputMode("complete") \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("topic", "wordcount-result-topic") \
.option("checkpointLocation", "file:///tmp/kafka-sink-cp") \
.trigger(processingTime="8 seconds") \
.start()
query.awaitTermination()
在终端中执行如下命令运行消费者程序:
cd /usr/local/mycode/structuredstreaming/kafka/
/usr/local/spark/bin/spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 \
spark_ss_kafka_consumer.py消费者程序运行起来以后,可以在“监控输出终端”看到类似如下的输出结果:
sq:3
bl:6
lo:8
…
(三)Socket源
Socket源从一个本地或远程主机的某个端口服务上读取数据,数据的编码为UTF8。因为Socket源使用内存保存读取到的所有数据,并且远端服务不能保证数据在出错后可以使用检查点或者指定当前已处理的偏移量来重放数据,所以,它无法提供端到端的容错保障。Socket源一般仅用于测试或学习用途。
Socket源的选项(option)包括如下几个。
(1)host:主机IP地址或者域名,必须设置。
(2)port:端口号,必须设置。
(3)includeTimestamp:是否在数据行内包含时间戳。使用时间戳可以用来测试基于时间聚合的
功能。
Socket源的实例可以参考“二、编写Structured Streaming程序的基本步骤”的StructuredNetworkWordCount.py。
(四)Rate源
Rate源可每秒生成特定个数的数据行,每个数据行包括时间戳和值字段。时间戳是消息发送的时间,值是从开始到当前消息发送的总个数,从0开始。Rate源一般用来作为调试或性能基准测试。
Rate源的选项(option)包括如下几个。
(1)rOwsPerSecond:每秒产生多少行数据,默认为1。
(2)rampUpTime:生成速度达到rowsPerSecond需要多少启动时间,使用比秒更精细的粒度将
会被截断为整数秒,默认为0秒。
(3)numPartitions:使用的分区数,默认为Spark的默认分区数。
Rate源会尽可能地使每秒生成的数据量达到rowsPerSecond,可以通过调整numPartitions以尽快达到所需的速度。这几个参数的作用类似一辆汽车从0加速到100千米/小时并以100千米/小时进行巡航的过程,通过增加“马力”(numPartitions),可以使得加速时间(rampUpTime)更短。
代码文件spark_ss_rate.py内容如下:
#!/usr/bin/env python3
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("TestRateStreamSource") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN‘)
lines = spark \
.readStream \
.format("rate") \
.option('rowsPerSecond', 5) \
.load()
print(lines.schema)
query = lines \
.writeStream \
.outputMode("update") \
.format("console") \
.option('truncate', 'false') \
.start()
query.awaitTermination()
在Linux终端中执行如下命令执行spark_ss_rate.py:
cd /usr/local/mycode/structuredstreaming/rate/
spark-submit spark_ss_rate.py
上述命令执行后,会得到类似如下的结果:
StructType(List(StructField(timestamp,TimestampType,true),StructField(value,LongType,true)))
-------------------------------------------
Batch: 0
-------------------------------------------
+---------+-----+
|timestamp|value|
+---------+-----+
+---------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+-----------------------+-----+
|timestamp |value|
+-----------------------+-----+
|2018-10-01 15:42:38.595|0 |
|2018-10-01 15:42:38.795|1 |
|2018-10-01 15:42:38.995|2 |
|2018-10-01 15:42:39.195|3 |
|2018-10-01 15:42:39.395|4 |
+-----------------------+-----+
四、输出操作
(一)启动流计算
DataFrame/Dataset的.writeStream()方法将会返回DataStreamWriter接口,接口通过.start()真正启动流计算,并将DataFrame/Dataset写入到外部的输出接收器,DataStreamWriter接口有以下几个主要函数:
(1)format:接收器类型。
(2)outputMode:输出模式,指定写入接收器的内容,可以是Append模式、Complete模式或Update模式。
(3)queryName:查询的名称,可选,用于标识查询的唯一名称。
(4)trigger:触发间隔,可选,设定触发间隔,如果未指定,则系统将在上一次处理完成后立即检查新数据的可用性。如果由于先前的处理尚未完成导致超过触发间隔,则系统将在处理完成后立即触发新的查询。
(二)输出模式
输出模式用于指定写入接收器的内容,主要有以下几种:
(1)Append模式:只有结果表中自上次触发间隔后增加的新行,才会被写入外部存储器。这种模式一般适用于“不希望更改结果表中现有行的内容”的使用场景。
(2)Complete模式:已更新的完整的结果表可被写入外部存储器。
(3)Update模式:只有自上次触发间隔后结果表中发生更新的行,才会被写入外部存储器。这种模式与Complete模式相比,输出较少,如果结果表的部分行没有更新,则不会输出任何内容。当查询不包括聚合时,这个模式等同于Append模式。
不同的流计算查询类型支持不同的输出模式,二者之间的兼容性如下表所示。
| 查询类型 | 支持的输出模式 | 备注 | |
|---|---|---|---|
| 聚合查询 | 在事件时间字段上使用水印的聚合 | Append Complete Update |
Append模式使用水印来清理旧的聚合状态 |
| 其他聚合 | Complete Update |
||
| 连接查询 | Append | ||
| 其他查询 | Append Update |
不支持Complete模式,因为无法将所有未分组数据保存在结果表内 | |
(三)输出接收器
系统内置的输出接收器包括File接收器、Kafka接收器、Foreach接收器、Console接收器、Memory接收器等,其中,Console接收器和Memory接收器仅用于调试用途。有些接收器由于无法保证输出的持久性,导致其不是容错的。Spark内置的输出接收器的详细信息如下表所示。
| 接收器 | 支持的输出模式 | 选项 | 容错 |
|---|---|---|---|
| File接收器 | Append | path:输出目录的路径必须指定 | 是。数据只会被处理一次 |
| Kafka接收器 | Append Complete Update |
选项较多,具体可查看Kafka对接指南 | 是。数据至少被处理一次 |
| Foreach接收器 | Append Complete Update |
无 | 依赖于ForeachWriter的实现 |
| Console接收器 | Append Complete Update |
numRows:每次触发后打印多少行,默认为20; truncate:如果行太长是否截断,默认为“是” |
否 |
| Memory接收器 | Append Complete |
无 | 否。在Complete输出模式下,重启查询会重建全表 |
以File接收器为例,这里把“二、编写Structured Streaming程序的基本步骤”的实例修改为使用File接收器,修改后的代码文件为StructuredNetworkWordCountFileSink.py:
#!/usr/bin/env python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
from pyspark.sql.functions import length
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCountFileSink") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
all_length_5_words = words.filter(length("word") == 5)
query = all_length_5_words \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "file:///tmp/filesink") \
.option("checkpointLocation", "file:///tmp/file-sink-cp") \
.trigger(processingTime="8 seconds") \
.start()
query.awaitTermination()
在Linux系统中新建一个终端(记作“数据源终端”),输入如下命令:
nc -lk 9999再新建一个终端(记作“流计算终端”),执行如下命令执行StructuredNetworkWordCountFileSink.py:
cd /usr/local/mycode/structuredstreaming
spark-submit StructuredNetworkWordCountFileSink.py
为了模拟文本数据流,可以在数据源终端内用键盘不断敲入一行行英文语句,并且让其中部分英语单词长度等于5。
由于程序执行后不会在终端输出信息,这时可新建一个终端,执行如下命令查看File接收器保存的位置:
cd /tmp/filesink
ls
可以看到以parquet格式保存的类似如下的文件列表:
part-00000-2bd184d2-e9b0-4110-9018-a7f2d14602a9-c000.snappy.parquet
part-00000-36eed4ab-b8c4-4421-adc6-76560699f6f5-c000.snappy.parquet
part-00000-dde601ad-1b49-4b78-a658-865e54d28fb7-c000.snappy.parquet
part-00001-eedddae2-fb96-4ce9-9000-566456cd5e8e-c000.snappy.parquet
_spark_metadata
可以使用strings命令查看文件内的字符串,具体如下:
strings part-00003-89584d0a-db83-467b-84d8-53d43baa4755-c000.snappy.parquet