【TRIE字典树实现:400行】(模糊匹配 | AC自动机 | 多模式匹配 | 串排序 | 词频计数 | 相似度分析 | RAII模式 | 前缀比较 )
目录
程序测试
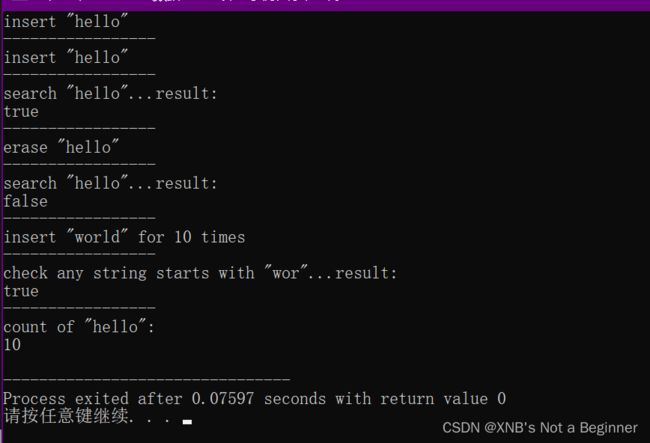
[insert_erase_count DEMO] 插入测试
【 AC Automiton | Multi pattern matching DEMO】AC自动机 | 多模式匹配测试
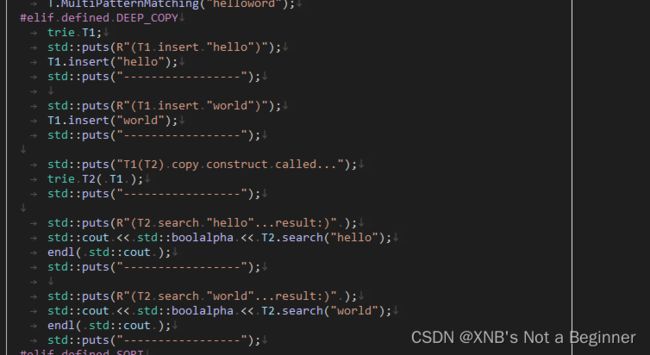
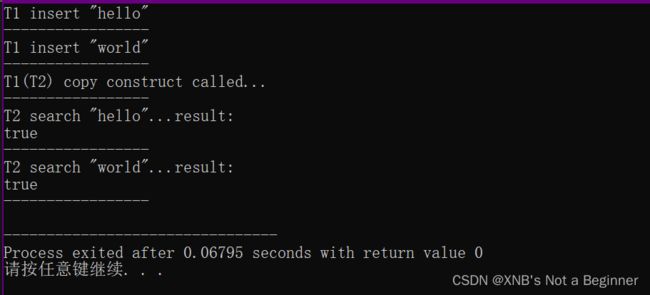
【Recursivet deep copy construct DEMO】多叉树的递归深拷贝测试
【string sort DEMO】串的非比较排序测试
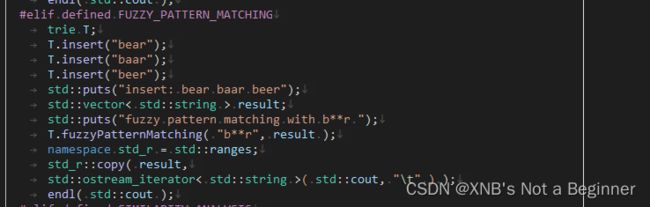
【fuzzy pattern matching DEMO】模糊匹配测试
【Similarity analysis DEMO】文本相似度分析测试
单元实现
首先,include。头文件仙人。。
[Member types ] and [member attributes] 类的成员属性和成员类型
[prefiex_matching(private)] 前缀匹配
编辑 【overloaded recurring deep copy construction】深拷贝
[insert]插入
[erase] 删除
[search] 查找
[count] 统计
[prefix matching(public)] 前缀匹配(透明接口)
[AC automiton builder] AC自动机的初始化
[Multi patter matching] 多模式串匹配
[string sort] 串排序
[fuzzy pattern matching] 模糊匹配
[similarity analysis] 相似度分析
【source code】完整源码
程序测试
[insert_erase_count DEMO] 插入测试


【 AC Automiton | Multi pattern matching DEMO】AC自动机 | 多模式匹配测试


【Recursivet deep copy construct DEMO】多叉树的递归深拷贝测试
【string sort DEMO】串的非比较排序测试


【fuzzy pattern matching DEMO】模糊匹配测试

【Similarity analysis DEMO】文本相似度分析测试
单元实现
比较值得注意的是unique_ptr接管节点指针
图的深拷贝中使用双哈希
移动构造中智能指针所有权的转交
optional取代传统的pair< return_type, bool > 检索返回类型
ranges,views范围库相关标准设施在代码简化的重要作用
类接口的设计使得代码较大程度复用
还有大大小小的算法等等
首先,include。头文件仙人。。

[Member types ] and [member attributes] 类的成员属性和成员类型

[prefiex_matching(private)] 前缀匹配
【overloaded recurring deep copy construction】深拷贝

[insert]插入
[erase] 删除

[search] 查找

[count] 统计

[prefix matching(public)] 前缀匹配(透明接口)

[AC automiton builder] AC自动机的初始化
[Multi patter matching] 多模式串匹配

[string sort] 串排序


[fuzzy pattern matching] 模糊匹配


[similarity analysis] 相似度分析
template < std::size_t N, std::size_t M, typename Ty >
using matrix = std::array< std::array< Ty, M >, N >;
static constexpr std::size_t LENGTH_LIMIT { 64 };
enum state : char { SAME_AS = 0, LHS, RHS } ;
template < std::size_t N >
void GetLCString( matrix< N, N, state > &record,
std::size_t i, std::size_t j,
const std::vector< std::string >& dest,
std::vector< std::size_t >& indices ){
if( !i || !j ) return;
if( record[i][j] == SAME_AS ){
indices.push_back( i );
GetLCString( record, i-1, j-1, dest, indices );
}else if( record[i][j] == LHS )
GetLCString( record, i-1, j, dest, indices );
else
GetLCString( record, i, j-1, dest, indices );
}
void similarity_analysis( const std::string& Str1, const std::string& Str2 ){
std::istringstream s1( Str1 );
std::istringstream s2( Str2 );
std::vector< std::string > words1;
std::vector< std::string > words2;
std::string buffer;
while( s1 >> buffer ) words1.emplace_back( std::move( buffer ) );
while( s2 >> buffer ) words2.emplace_back( std::move( buffer ) );
std::size_t length1 { words1.size() };
std::size_t length2 { words2.size() };
matrix< LENGTH_LIMIT, LENGTH_LIMIT, std::size_t > dp;
matrix< LENGTH_LIMIT, LENGTH_LIMIT, state > record;
for( auto i { 1U }; i < length1; ++i )
for( auto j { 1U }; j < length2; ++j ){
if( words1[i] == words2[j] ){
dp[i][j] = dp[i-1][j-1] + 1;
record[i][j] = SAME_AS;
}else if( dp[i][j-1] <= dp[i-1][j]){
dp[i][j] = dp[i-1][j];
record[i][j] = LHS;
}else{
dp[i][j] = dp[i][j-1];
record[i][j] = RHS;
}
}
std::vector< std::size_t > indices;
indices.reserve( length1 << 1U | 1U );
GetLCString( record, length1 - 1, length2 - 1, words1, indices );
std::size_t common_length { dp[ length1 - 1 ][ length2 - 1 ] };
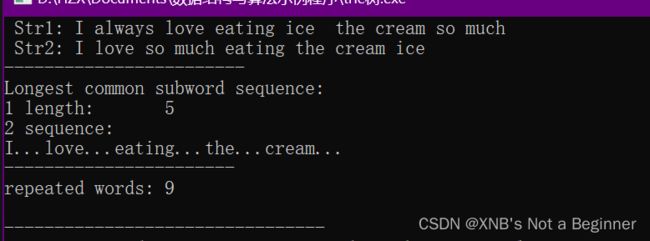
std::cout << "Longest common subword sequence:\n";
std::cout << "1 length:\t" << common_length << '\n';
puts("2 sequence:");
namespace std_v = std::views;
for( const auto& Word :
indices | std_v::reverse | std_v::transform(
[&]< typename Value>( Value index ){
return words1[index];
} ) )
std::cout << Word << "...";
endl( std::cout );
trie T;
for( const auto& W : words1 )
T.insert( W );
std::size_t repeated { 0U };
for( const auto& W : words2 )
repeated += T.count( W );
std::puts("-----------------------");
std::cout << "repeated words:\t" << repeated << '\n';
}【source code】完整源码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
class trie{
struct Node{
using hasher =
std::unordered_map< char,
std::unique_ptr< Node > >;
using container =
std::unordered_set< std::string >;
std::optional< std::size_t >
frequency { std::nullopt };
hasher children;
container patterns;
Node *failed { nullptr };
};
private:
std::unique_ptr< Node > root { new Node };
Node *prefix_pattern_matching( const std::string_view& pattern ) const{
namespace std_v = std::views;
Node *ptr { root.get() };
for( const auto& _Char :
pattern | std_v::filter(
[]< typename Value >( Value _Char )
{ return std::isalpha( _Char ); } )
| std_v::transform(
[]< typename Value >( Value _Char )
{ return std::tolower( _Char ); } ) ){
if( ! ptr->children.count( _Char ) )
return static_cast< Node * >( nullptr );
ptr = ptr->children[ _Char ].get();
}
return ptr;
}
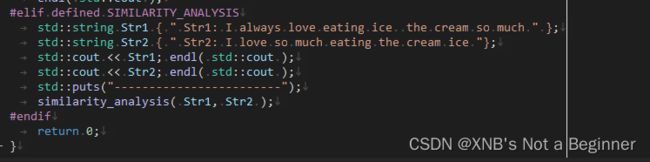
void hasherConstor( Node *o,
std::unordered_map< Node *, Node * >& hasher ){
Node *clone { new Node };
clone->patterns = o->patterns;
clone->frequency = o->frequency;
hasher[ o ] = clone;
for( auto & [ _Char, child ] : o->children )
hasherConstor( child.get(), hasher );
}
void hasherMapper( Node *o,
std::unordered_map< Node *, Node * >& hasher ){
hasher[o]->failed = hasher[o->failed];
for( auto& [ _Char, child ] : o->children ){
hasher[ o ]->children[ _Char ].reset(
hasher[ o->children[ _Char ].get() ] );
hasherMapper( child.get(), hasher );
}
}
void sortedHelper( Node * o, std::vector< std::string >& result, std::string Str ) const{
if( o->frequency ) result.emplace_back( std::move( Str ) );
for( auto _Char { 'a' }; _Char <= 'z'; ++_Char)
if( o->children.count( _Char ) )
sortedHelper( o->children[ _Char ].get(),
result,
Str + _Char );
}
void fuzzyPatternMatchingHelper( Node *o, std::size_t index,
const std::string_view& fussy,
std::vector< std::string >& result, std::string Str ) const {
if( index == fussy.length() ){
if( o->frequency ) result.emplace_back( std::move( Str ) );
return;
}
const auto& _Char { fussy[index] };
if( _Char == PLACE_HOLDER ){
for( auto _Alpha { 'a' }; _Alpha <= 'z'; ++_Alpha ){
if( o->children.count( _Alpha) )
fuzzyPatternMatchingHelper(
o->children[ _Alpha ].get(),
index + 1,
fussy,
result,
Str + _Alpha);
}
}else if( o->children.count( _Char ) )
fuzzyPatternMatchingHelper(
o->children[ _Char ].get(),
index + 1,
fussy,
result,
Str + _Char);
}
public:
explicit trie( void ) noexcept = default;
explicit trie( trie&& ) noexcept = default;
~trie( void ) noexcept{ root.release(); }
explicit trie( const trie& other ) {
std::unordered_map< Node *, Node * > hasher;
hasherConstor( other.root.get(), hasher );
hasherMapper( other.root.get(), hasher );
root.reset( hasher[ other.root.get() ] );
}
void erase( const std::string_view& Str ){
auto ptr { prefix_pattern_matching( Str ) };
if( ptr && ptr->frequency )
ptr->frequency = std::nullopt;
}
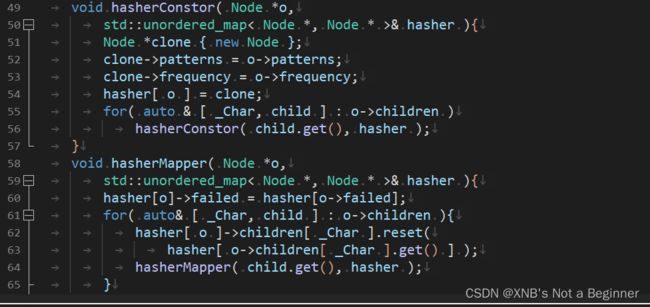
void insert( const std::string_view& Str ){
namespace std_v = std::views;
Node *ptr { root.get() };
for( const auto& _Char :
Str | std_v::filter(
[]< typename Value >( Value _Char )
{ return std::isalpha( _Char ); } )
| std_v::transform(
[]< typename Value >( Value _Char )
{ return std::tolower( _Char ); } ) ){
if( ! ptr->children.count( _Char ) )
ptr->children[ _Char ] = std::make_unique< Node >();
ptr = ptr->children[ _Char ].get();
}
if( ! ptr->frequency ){
ptr->frequency = 1;
ptr->patterns.emplace( Str );
}
else ++*( ptr->frequency );
}
inline bool search( const std::string_view& Str ) const{
auto ptr { prefix_pattern_matching( Str ) };
return static_cast< bool >( ptr && ptr->frequency );
}
inline std::size_t count( const std::string_view& Str ) const{
return prefix_pattern_matching( Str )->frequency.value_or( 0U );
}
bool hasAnyStartsWith( const std::string_view& Str ) const{
return static_cast< bool >( prefix_pattern_matching( Str ) );
}
void AhoCorasickAutomatonBuilder( void ){
std::queue< Node * > Q;
root->failed = root.get();
for( auto& [ _Char, child ] : root->children ){
child->failed = root.get();
Q.push( child.get() );
}
while( !Q.empty() ){
Node *current { Q.front() };
Q.pop();
for( auto& [ _Char, child ] : current->children ){
Q.push( child.get() );
Node *jumper { current->failed };
while( !( jumper == root.get() )
&& !( jumper->children.count( _Char ) ) )
jumper = jumper->failed;
child->failed =
jumper->children.count( _Char )
? jumper->children[ _Char ].get()
: root.get();
child->patterns.merge(
Node::container( child->failed->patterns ) );
}
}
}
void MultiPatternMatching( const std::string_view& Str ) const{
namespace std_r = std::ranges;
Node *current { root.get() };
for( const auto& _Char : Str ){
while( !( current == root.get() )
&& !( current->children.count( _Char ) ) )
current = current->failed;
if( current->children.count( _Char ) )
current = current->children[ _Char ].get();
if( !current->patterns.empty() )
std_r::copy( current->patterns,
std::ostream_iterator< std::string >
( std::cout, "|" ) );
}
}
void sorted( std::vector< std::string >& result ) const {
using namespace std::literals::string_literals;
sortedHelper( root.get(), result, ""s );
}
static constexpr char PLACE_HOLDER { '*' };
void fuzzyPatternMatching( const std::string_view& fuzzy,
std::vector< std::string >& result ) const{
using namespace std::literals::string_literals;
fuzzyPatternMatchingHelper( root.get(), 0U, fuzzy, result, ""s );
}
};
template < std::size_t N, std::size_t M, typename Ty >
using matrix = std::array< std::array< Ty, M >, N >;
static constexpr std::size_t LENGTH_LIMIT { 64 };
enum state : char { SAME_AS = 0, LHS, RHS } ;
template < std::size_t N >
void GetLCString( matrix< N, N, state > &record,
std::size_t i, std::size_t j,
const std::vector< std::string >& dest,
std::vector< std::size_t >& indices ){
if( !i || !j ) return;
if( record[i][j] == SAME_AS ){
indices.push_back( i );
GetLCString( record, i-1, j-1, dest, indices );
}else if( record[i][j] == LHS )
GetLCString( record, i-1, j, dest, indices );
else
GetLCString( record, i, j-1, dest, indices );
}
void similarity_analysis( const std::string& Str1, const std::string& Str2 ){
std::istringstream s1( Str1 );
std::istringstream s2( Str2 );
std::vector< std::string > words1;
std::vector< std::string > words2;
std::string buffer;
while( s1 >> buffer ) words1.emplace_back( std::move( buffer ) );
while( s2 >> buffer ) words2.emplace_back( std::move( buffer ) );
std::size_t length1 { words1.size() };
std::size_t length2 { words2.size() };
matrix< LENGTH_LIMIT, LENGTH_LIMIT, std::size_t > dp;
matrix< LENGTH_LIMIT, LENGTH_LIMIT, state > record;
for( auto i { 1U }; i < length1; ++i )
for( auto j { 1U }; j < length2; ++j ){
if( words1[i] == words2[j] ){
dp[i][j] = dp[i-1][j-1] + 1;
record[i][j] = SAME_AS;
}else if( dp[i][j-1] <= dp[i-1][j]){
dp[i][j] = dp[i-1][j];
record[i][j] = LHS;
}else{
dp[i][j] = dp[i][j-1];
record[i][j] = RHS;
}
}
std::vector< std::size_t > indices;
indices.reserve( length1 << 1U | 1U );
GetLCString( record, length1 - 1, length2 - 1, words1, indices );
std::size_t common_length { dp[ length1 - 1 ][ length2 - 1 ] };
std::cout << "Longest common subword sequence:\n";
std::cout << "1 length:\t" << common_length << '\n';
puts("2 sequence:");
namespace std_v = std::views;
for( const auto& Word :
indices | std_v::reverse | std_v::transform(
[&]< typename Value>( Value index ){
return words1[index];
} ) )
std::cout << Word << "...";
endl( std::cout );
trie T;
for( const auto& W : words1 )
T.insert( W );
std::size_t repeated { 0U };
for( const auto& W : words2 )
repeated += T.count( W );
std::puts("-----------------------");
std::cout << "repeated words:\t" << repeated << '\n';
}
#define SIMILARITY_ANALYSIS
int main( void ){
#ifdef INSERT_ERASE_COUNT
trie T;
std::puts(R"(insert "hello")");
T.insert("hello");
std::puts("-----------------");
std::puts(R"(insert "hello")");
T.insert("hello");
std::puts("-----------------");
std::puts(R"(search "hello"...result:)");
std::cout << std::boolalpha << T.search("hello");
endl( std::cout );
std::puts("-----------------");
std::puts(R"(erase "hello")");
T.erase("hello");
std::puts("-----------------");
std::puts(R"(search "hello"...result:)" );
std::cout << std::boolalpha << T.search("hello");
endl( std::cout );
std::puts("-----------------");
std::puts(R"(insert "world" for 10 times)");
auto counter { 10 };
while( counter -- ) T.insert("world");
std::puts("-----------------");
std::puts(R"(check any string starts with "wor"...result:)");
std::cout << std::boolalpha << T.hasAnyStartsWith("wor");
endl( std::cout );
std::puts("-----------------");
std::cout << R"(count of "hello":)" "\t\n"
<< T.count("world");
endl( std::cout );
#elif defined MULTI_PATTERN_MATCHING
trie T;
std::puts(R"(insert "he")");
T.insert("he");
std::puts("-----------------");
std::puts(R"(insert "ell")");
T.insert("ell");
std::puts("-----------------");
std::puts(R"(insert "lowor")");
T.insert("lowor");
std::puts("-----------------");
std::puts(R"(insert "rd")");
T.insert("rd");
std::puts("-----------------");
std::puts("Building MultiPatternMatching with KMP Algo...");
T.AhoCorasickAutomatonBuilder();
std::puts("-----------------");
std::puts(R"("Multi pattern matching with string: "helloword")" );
T.MultiPatternMatching("helloword");
#elif defined DEEP_COPY
trie T1;
std::puts(R"(T1 insert "hello")");
T1.insert("hello");
std::puts("-----------------");
std::puts(R"(T1 insert "world")");
T1.insert("world");
std::puts("-----------------");
std::puts("T1(T2) copy construct called...");
trie T2( T1 );
std::puts("-----------------");
std::puts(R"(T2 search "hello"...result:)" );
std::cout << std::boolalpha << T2.search("hello");
endl( std::cout );
std::puts("-----------------");
std::puts(R"(T2 search "world"...result:)" );
std::cout << std::boolalpha << T2.search("world");
endl( std::cout );
std::puts("-----------------");
#elif defined SORT
trie T;
T.insert("fsd");
T.insert("set");
T.insert("iowe");
T.insert("aosid");
std::puts("insert: fsd set iowe aosid");
puts("----------------------");
std::puts("sorted result:");
std::vector< std::string > sorted_result;
T.sorted( sorted_result );
namespace std_r = std::ranges;
std_r::copy( sorted_result,
std::ostream_iterator< std::string >( std::cout, "\t" ) );
endl( std::cout );
#elif defined FUZZY_PATTERN_MATCHING
trie T;
T.insert("bear");
T.insert("baar");
T.insert("beer");
std::puts("insert: bear baar beer");
std::vector< std::string > result;
std::puts("fuzzy pattern matching with b**r ");
T.fuzzyPatternMatching( "b**r", result );
namespace std_r = std::ranges;
std_r::copy( result,
std::ostream_iterator< std::string >( std::cout, "\t" ) );
endl( std::cout );
#elif defined SIMILARITY_ANALYSIS
std::string Str1 { " Str1: I always love eating ice the cream so much " };
std::string Str2 { " Str2: I love so much eating the cream ice "};
std::cout << Str1; endl( std::cout );
std::cout << Str2; endl( std::cout );
std::puts("------------------------");
similarity_analysis( Str1, Str2 );
#endif
return 0;
}