datawhale 10月学习——树模型与集成学习:梯度提升树
前情回顾
- 决策树
- CART树的实现
- 集成模式
- 两种并行集成的树模型
- AdaBoost
结论速递
本次学习了GBDT,首先了解了用于回归的GBDT,将损失使用梯度下降法进行减小;用于分类的GBDT要稍微复杂一些,需要对分类损失进行定义。学习了助教提供的代码。
目录
-
- 前情回顾
- 结论速递
- 1 用于回归的GBDT
-
- 1.1 原理
- 1.2 代码实现
- 2 用于分类的GBDT
-
- 2.1 原理
- 2.2 代码实现
1 用于回归的GBDT
1.1 原理
与AdaBoost类似,对于每一轮集成来说,上一轮的集成输出都是常数。
设数据集为 D = { ( X 1 , y 1 ) , . . . , ( X N , y N ) } D=\{(X_1,y_1),...,(X_N,y_N)\} D={(X1,y1),...,(XN,yN)},模型的损失函数为 L ( y , y ^ ) L(y,\hat{y}) L(y,y^),现希望利用多棵回归决策树来进行模型集成:设第 m m m轮时,已知前 m − 1 m-1 m−1轮中对第 i i i个样本的集成输出为 F m − 1 ( X i ) F_{m-1}(X_i) Fm−1(Xi),则本轮的集成输出 y ^ i \hat{y}_i y^i
F m ( X i ) = F m − 1 ( X i ) + h m ( X i ) F_{m}(X_i)=F_{m-1}(X_i)+h_m(X_i) Fm(Xi)=Fm−1(Xi)+hm(Xi)
其中, h m h_m hm是使得当前轮损失 ∑ i = 1 N L ( y i , y ^ i ) \sum_{i=1}^N L(y_i,\hat{y}_i) ∑i=1NL(yi,y^i)达到最小的决策树模型。
特别地,当 m = 0 m=0 m=0时, F 0 ( X i ) = arg min y ^ ∑ i = 1 N L ( y i , y ^ ) F_{0}(X_i)=\arg\min_{\hat{y}} \sum_{i=1}^N L(y_i,\hat{y}) F0(Xi)=argminy^∑i=1NL(yi,y^)。
【思考题】对于均方损失函数和绝对值损失函数,请分别求出模型的初始预测 F 0 F_{0} F0
F 0 = arg min y ^ ∑ i = 1 N ( y i − y ^ ) 2 F_{0}=\arg\min_{\hat{y}}\sum_{i=1}^{N}(y_i-\hat{y})^2 F0=argminy^∑i=1N(yi−y^)2
F 0 = arg min y ^ ∑ i = 1 N ∣ y i − y ^ ∣ 2 F_{0}=\arg\min_{\hat{y}}\sum_{i=1}^{N} \vert y_i-\hat{y}\vert^2 F0=argminy^∑i=1N∣yi−y^∣2
则可以记第m轮的损失函数
G ( h m ) = ∑ i = 1 N L ( y i , F m − 1 ( X i ) + h m ( X i ) ) G(h_m) = \sum_{i=1}^NL(y_i, F_{m-1}(X_i)+h_m(X_i)) G(hm)=i=1∑NL(yi,Fm−1(Xi)+hm(Xi))
学习一个决策树模型等价于对数据集 D ~ = { ( X 1 , h ∗ ( X 1 ) ) , . . . , ( X N , h ∗ ( X N ) ) } \tilde{{D}}=\{(X_1,h^*(X_1)),...,(X_N,h^*(X_N))\} D~={(X1,h∗(X1)),...,(XN,h∗(XN))}进行拟合,设 w i = h ∗ ( X i ) w_i=h^*(X_i) wi=h∗(Xi), w = [ w 1 , . . . , w N ] \textbf{w}=[w_1,...,w_N] w=[w1,...,wN],此时的损失函数可改记为
G ( w ) = ∑ i = 1 N L ( y i , F m − 1 ( X i ) + w i ) G(\textbf{w})=\sum_{i=1}^NL(y_i, F_{m-1}(X_i)+w_i) G(w)=i=1∑NL(yi,Fm−1(Xi)+wi)
由于只要我们获得最优的 w \textbf{w} w,就能拟合出第 m m m轮相应的回归树,此时一个函数空间的优化问题已经被转换为了参数空间的优化问题,即对于样本 i i i而言,最优参数为
w i = arg min w L ( y i , F m − 1 ( X i ) + w ) w_i=\arg\min_{w}L(y_i,F_{m-1}(X_i)+w) wi=argwminL(yi,Fm−1(Xi)+w)
接下来就可以用梯度下降,使损失最小,恰好是决策树要拟合的 h ∗ ( X i ) h^*(X_i) h∗(Xi)。
以损失函数 L ( y , y ^ ) = ∣ y − y ^ ∣ L(y,\hat{y})=\sqrt{\vert y-\hat{y}\vert} L(y,y^)=∣y−y^∣为例,记残差为
r i = y i − F m − 1 ( X i ) r_i = y_i-F_{m-1}(X_i) ri=yi−Fm−1(Xi)
则实际损失为
L ( w i ) = ∣ r i − w i ∣ L(w_i)=\sqrt{\vert r_i-w_i\vert } L(wi)=∣ri−wi∣
【思考题】给定了上一轮的预测结果 F m − 1 ( X i ) F_{m-1}(X_i) Fm−1(Xi)和样本标签 y i y_i yi,请计算使用平方损失时需要拟合的 w i ∗ w^*_i wi∗。
记残差为
r i = y i − F m − 1 ( X i ) r_i = y_i-F_{m-1}(X_i) ri=yi−Fm−1(Xi)
则损失为
L ( w i ) = ( r i − w i ) 2 L(w_i)=(r_i-w_i)^2 L(wi)=(ri−wi)2
根据在零点处的梯度下降可知:
w i ∗ = 0 − ∂ L ∂ w ∣ w = 0 = 1 2 ∣ r i ∣ s i g n ( r i ) \begin{aligned} w^*_i &= 0 - \left.\frac{\partial L}{\partial w} \right|_{w=0}\\ &= \frac{1}{2\sqrt{\vert r_i\vert}}sign(r_i) \end{aligned} wi∗=0−∂w∂L∣∣∣∣w=0=2∣ri∣1sign(ri)
【思考题】当样本 i i i计算得到的残差 r i = 0 r_i=0 ri=0时,本例中的函数在 w = 0 w=0 w=0处不可导,请问当前轮应当如何处理模型输出?
取比0大一些或者小一些的数?
接下来,可以引入学习率来缓解过拟合。
为了缓解模型的过拟合现象,我们需要引入学习率参数 η \eta η来控制每轮的学习速度,即获得了由 w ∗ \textbf{w}^* w∗拟合的第m棵树 h ∗ h^* h∗后,当前轮的输出结果
y ^ i = F m − 1 ( X i ) + η h m ∗ ( X i ) \hat{y}_i=F_{m-1}(X_i)+\eta h^*_m(X_i) y^i=Fm−1(Xi)+ηhm∗(Xi)
另一种理解
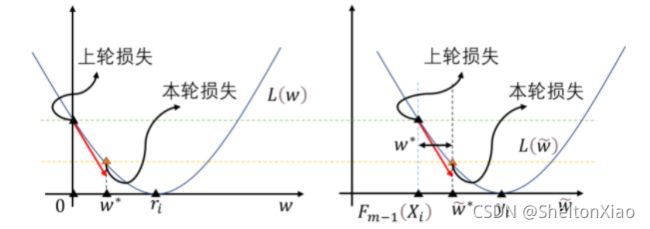
对于上述的梯度下降过程,还可以从另一个等价的角度来观察:若设当前轮模型预测的输出值为 w ~ i = F m − 1 ( X i ) + w i \tilde{w}_i= F_{m-1}(X_i)+w_i w~i=Fm−1(Xi)+wi,求解的问题即为
w ~ i = arg min w ~ L ( y i , w ~ ) \tilde{w}_i=\arg\min_{\tilde{w}} L(y_i, \tilde{w}) w~i=argw~minL(yi,w~)
从而当前轮学习器 h h h需要拟合的目标值 w i ∗ w^*_i wi∗为
w i ∗ = w ~ i − F m − 1 ( X i ) = 0 − ∂ L ∂ w ∂ w ∂ w ~ ∣ w ~ = F m − 1 ( X i ) = 0 − ∂ L ∂ w ∣ w ~ = F m − 1 ( X i ) = 0 − ∂ L ∂ w ∣ w = 0 \begin{aligned} w^*_i &= \tilde{w}_i-F_{m-1}(X_i)\\ &=0-\frac{\partial L}{\partial w} \left.\frac{\partial w}{\partial \tilde{w}} \right|_{\tilde{w}=F_{m-1}(X_i)} \\ &= 0-\left.\frac{\partial L}{\partial w} \right|_{\tilde{w}=F_{m-1}(X_i)} \\ &= 0 - \left.\frac{\partial L}{\partial w} \right|_{w=0} \end{aligned} wi∗=w~i−Fm−1(Xi)=0−∂w∂L∂w~∂w∣∣∣∣w~=Fm−1(Xi)=0−∂w∂L∣∣∣∣w~=Fm−1(Xi)=0−∂w∂L∣∣∣∣w=0
上述的结果与先前的梯度下降结果完全一致,事实上这两种观点在本质上没有任何区别,只是损失函数本身进行了平移
1.2 代码实现
基础库及函数导入
from sklearn.tree import DecisionTreeRegressor as DT
from sklearn.datasets import make_regression
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
import numpy as np
类分为几个主要方法,核心是fit部分,record_score部分用来支持早停机制。
class GBDTRegressor:
def __init__(self, max_depth=4, n_estimator=1000, lr=0.2):
self.max_depth = max_depth
self.n_estimator = n_estimator
self.lr = lr
self.booster = []
self.best_round = None
def record_score(self, y_train, y_val, train_predict, val_predict, i):
mse_val = mean_absolute_error(y_val, val_predict)
if (i+1)%10==0:
mse_train = mean_absolute_error(y_train, train_predict)
print("第%d轮\t训练集: %.4f\t"
"验证集: %.4f"%(i+1, mse_train, mse_val))
return mse_val
def fit(self, X, y):
# 在数据集中划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.25, random_state=0)
train_predict, val_predict = 0, 0
next_fit_val = np.full(X_train.shape[0], np.median(y_train))
# 为early_stop做记录准备
last_val_score = np.infty
for i in range(self.n_estimator):
# 本轮回归树
cur_booster = DT(max_depth=self.max_depth)
cur_booster.fit(X_train, next_fit_val)
train_predict += cur_booster.predict(X_train) * self.lr
val_predict += cur_booster.predict(X_val) * self.lr
# 平方损失为((y - (F_{m-1} + w)^2)/2,若记残差为r
# 即为((r - w)^2)/2,此时关于w在0点处的负梯度求得恰好为r
# 因此拟合的值就是y_train - train_predict
next_fit_val = y_train - train_predict
self.booster.append(cur_booster)
cur_val_score = self.record_score(
y_train, y_val, train_predict, val_predict, i)
if cur_val_score > last_val_score:
#早停
self.best_round = i
print("\n训练结束!最佳轮数为%d"%(i+1))
break
last_val_score = cur_val_score
def predict(self, X):
cur_predict = 0
# 在最佳验证集得分的轮数停止,防止过拟合
for i in range(self.best_round):
cur_predict += self.lr * self.booster[i].predict(X)
return cur_predict
运行结果如下

2 用于分类的GBDT
2.1 原理
用于分类的GBDT最大的问题在于,不能够直接的拿类别嘉禾处理,需要引入损失。
在GBDT中,我们仍然使用回归树来处理分类问题,那此时拟合的对象和流程又是什么呢?
对于 K K K分类问题,我们假设得到了 K K K个得分 F 1 i , . . . , F K i F_{1i},...,F_{Ki} F1i,...,FKi来代表样本 i i i属于对应类别的相对可能性,那么在进行Softmax归一化后,就能够得到该样本属于这些类别的概率大小。其中,属于类别k的概率即为 e F k i ∑ c = 1 K e F c i \frac{e^{F_{ki}}}{\sum_{c=1}^Ke^{F_{ci}}} ∑c=1KeFcieFki。此时,我们就能够使用多分类的交叉熵函数来计算模型损失,设 y i = [ y 1 i , . . . , y K i ] \textbf{y}_i=[y_{1i},...,y_{Ki}] yi=[y1i,...,yKi]为第 i i i个样本的类别独热编码,记 F i = [ F 1 i , . . . , F K i ] \textbf{F}_i=[F_{1i},...,F_{Ki}] Fi=[F1i,...,FKi],则该样本的损失为
L ( y i , F i ) = − ∑ c = 1 K y c i log e F c i ∑ c ~ = 1 K e F c ~ i L(\textbf{y}_i,\textbf{F}_i)=-\sum_{c=1}^K y_{ci}\log \frac{e^{F_{ci}}}{\sum_{\tilde{c}=1}^Ke^{F_{\tilde{c}i}}} L(yi,Fi)=−c=1∑Kycilog∑c~=1KeFc~ieFci
上述的 K K K个得分可以由 K K K棵回归树通过集成学习得到,树的生长目标正是使得上述的损失最小化。记第 m m m轮中 K K K棵树对第 i i i个样本输出的得分为 h i ( m ) = [ h 1 i ( m ) , . . . , h K i ( m ) ] \textbf{h}^{(m)}_i=[h^{(m)}_{1i},...,h^{(m)}_{Ki}] hi(m)=[h1i(m),...,hKi(m)],则此时 F i ( m ) = F i ( m − 1 ) + h i ( m ) \textbf{F}^{(m)}_i=\textbf{F}^{(m-1)}_i+\textbf{h}^{(m)}_i Fi(m)=Fi(m−1)+hi(m)。与GBDT处理回归问题的思路同理,只需要令损失函数 L ( y i , F i ) L(\textbf{y}_i,\textbf{F}_i) L(yi,Fi)在 F i = F i ( m − 1 ) \textbf{F}_i=\textbf{F}_i^{(m-1)} Fi=Fi(m−1)处梯度下降即可:
F i ∗ ( m ) = F i ( m − 1 ) − ∂ L ∂ F i ∣ F i = F i ( m − 1 ) \textbf{F}_i^{*(m)} = \textbf{F}_i^{(m-1)} - \left.\frac{\partial L}{\partial \textbf{F}_i} \right|_{\textbf{F}_i=\textbf{F}_i^{(m-1)}} Fi∗(m)=Fi(m−1)−∂Fi∂L∣∣∣∣Fi=Fi(m−1)
K K K棵回归树的学习目标为:
h i ∗ ( m ) = F i ∗ ( m ) − F i ( m − 1 ) = − ∂ L ∂ F i ∣ F i = F i ( m − 1 ) = [ y 1 i − e F 1 i ( m − 1 ) ∑ c = 1 K e F c i ( m − 1 ) , . . . , y K i − e F K i ( m − 1 ) ∑ c = 1 K e F c i ( m − 1 ) ] \begin{aligned} \textbf{h}_i^{*(m)} &= \textbf{F}_i^{*(m)} - \textbf{F}_i^{(m-1)}\\ &= - \left.\frac{\partial L}{\partial \textbf{F}_i} \right|_{\textbf{F}_i=\textbf{F}_i^{(m-1)}} \\ &= [y_{1i} - \frac{e^{F^{(m-1)}_{1i}}}{\sum_{c=1}^K e^{F^{(m-1)}_{ci}}},...,y_{Ki} - \frac{e^{F^{(m-1)}_{Ki}}}{\sum_{c=1}^K e^{F^{(m-1)}_{ci}}}] \end{aligned} hi∗(m)=Fi∗(m)−Fi(m−1)=−∂Fi∂L∣∣∣∣Fi=Fi(m−1)=[y1i−∑c=1KeFci(m−1)eF1i(m−1),...,yKi−∑c=1KeFci(m−1)eFKi(m−1)]
同样需要引入学习率,以减少过拟合。
除此之外,可以利用概率和为1的性质,减少拟合次数,提升计算效率。
具体来说,此时我们需要 K − 1 K-1 K−1个得分,记为 F 1 i , . . . , F ( K − 1 ) i F_{1i},...,F_{(K-1)i} F1i,...,F(K−1)i,则样本相应属于 K K K个类别的概率值可表示为
[ e F 1 i 1 + ∑ c = 1 K − 1 e F c i , . . . , e F ( K − 1 ) i 1 + ∑ c = 1 K − 1 e F c i , 1 1 + ∑ c = 1 K − 1 e F c i ] [\frac{e^{F_{1i}}}{1+\sum_{c=1}^{K-1}e^{F_{ci}}},...,\frac{e^{F_{(K-1)i}}}{1+\sum_{c=1}^{K-1}e^{F_{ci}}},\frac{1}{1+\sum_{c=1}^{K-1}e^{F_{ci}}}] [1+∑c=1K−1eFcieF1i,...,1+∑c=1K−1eFcieF(K−1)i,1+∑c=1K−1eFci1]
当 K ≥ 3 K\geq3 K≥3时,仍然使用独热编码来写出损失函数:
L ( F 1 i , . . . , F ( K − 1 ) i ) = y K i log [ 1 + ∑ c = 1 K − 1 e F c i ] − ∑ c = 1 K − 1 y c i log e F c i 1 + ∑ c = 1 K − 1 e F c i L(F_{1i},...,F_{(K-1)i})= y_{Ki}\log [1+\sum_{c=1}^{K-1}e^{F_{ci}}] -\sum_{c=1}^{K-1} y_{ci}\log \frac{e^{F_{ci}}}{1+\sum_{c=1}^{K-1}e^{F_{ci}}} L(F1i,...,F(K−1)i)=yKilog[1+c=1∑K−1eFci]−c=1∑K−1ycilog1+∑c=1K−1eFcieFci
类似地记 F i = [ F 1 i , . . . , F ( K − 1 ) i ] \textbf{F}_i=[F_{1i},...,F_{(K-1)i}] Fi=[F1i,...,F(K−1)i],我们可以求出负梯度:
− ∂ L ∂ F k i ∣ F i = F i ( m − 1 ) = { − e F k i ( m − 1 ) 1 + ∑ c = 1 K − 1 e F c i ( m − 1 ) y K i = 1 y k i − e F k i ( m − 1 ) 1 + ∑ c = 1 K − 1 e F c i ( m − 1 ) y K i = 0 -\left.\frac{\partial L}{\partial F_{ki}} \right|_{\textbf{F}_i=\textbf{F}_i^{(m-1)}} = \left\{ \begin{aligned} -\frac{e^{F^{(m-1)}_{ki}}}{1+\sum_{c=1}^{K-1} e^{F^{(m-1)}_{ci}}} &\qquad y_{Ki}=1 \\ y_{ki} - \frac{e^{F^{(m-1)}_{ki}}}{1+\sum_{c=1}^{K-1} e^{F^{(m-1)}_{ci}}} & \qquad y_{Ki}=0 \\ \end{aligned} \right. −∂Fki∂L∣∣∣∣Fi=Fi(m−1)=⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧−1+∑c=1K−1eFci(m−1)eFki(m−1)yki−1+∑c=1K−1eFci(m−1)eFki(m−1)yKi=1yKi=0
当 K = 2 K=2 K=2时,不妨规定 y i ∈ { 0 , 1 } y_i\in \{0,1\} yi∈{0,1},此时损失函数可简化为
L ( F i ) = − y i log e F i 1 + e F i − ( 1 − y i ) log 1 1 + e F i L(F_i) = - y_i\log \frac{e^{F_i}}{1+e^{F_i}} - (1-y_i)\log \frac{1}{1+e^{F_i}} L(Fi)=−yilog1+eFieFi−(1−yi)log1+eFi1
负梯度为
− ∂ L ∂ F i ∣ F i = F i ( m − 1 ) = y i − e F i 1 + e F i -\left.\frac{\partial L}{\partial F_{i}} \right|_{F_i=F^{(m-1)}_i}=y_i-\frac{e^{F_i}}{1+e^{F_i}} −∂Fi∂L∣∣∣∣Fi=Fi(m−1)=yi−1+eFieFi
2.2 代码实现
导入库及函数
from sklearn.tree import DecisionTreeRegressor as DT
from sklearn.datasets import make_classification
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import numpy as np
同样,核心方法为fit
class GBDTClassifier:
def __init__(self, max_depth=4, n_estimator=1000, lr=0.2):
self.max_depth = max_depth
self.n_estimator = n_estimator
self.lr = lr
self.booster = []
self.best_round = None
def record_score(self, y_train, y_val, train_predict, val_predict, i):
train_predict = np.exp(train_predict) / (1 + np.exp(train_predict))
val_predict = np.exp(val_predict) / (1 + np.exp(val_predict))
auc_val = roc_auc_score(y_val, val_predict)
if (i+1)%10==0:
auc_train = roc_auc_score(y_train, train_predict)
print("第%d轮\t训练集: %.4f\t"
"验证集: %.4f"%(i+1, auc_train, auc_val))
return auc_val
def fit(self, X, y):
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.25, random_state=0)
train_predict, val_predict = 0, 0
# 按照二分类比例的初始化公式计算
fit_val = np.log(y_train.mean() / (1 - y_train.mean()))
next_fit_val = np.full(X_train.shape[0], fit_val)
last_val_score = - np.infty
for i in range(self.n_estimator):
#本轮回归树
cur_booster = DT(max_depth=self.max_depth)
cur_booster.fit(X_train, next_fit_val)
train_predict += cur_booster.predict(X_train) * self.lr
val_predict += cur_booster.predict(X_val) * self.lr
next_fit_val = y_train - np.exp(
train_predict) / (1 + np.exp(train_predict))
self.booster.append(cur_booster)
cur_val_score = self.record_score(
y_train, y_val, train_predict, val_predict, i)
if cur_val_score < last_val_score:
self.best_round = i
print("\n训练结束!最佳轮数为%d"%(i+1))
break
last_val_score = cur_val_score
def predict(self, X):
cur_predict = 0
for i in range(self.best_round):
cur_predict += self.lr * self.booster[i].predict(X)
return np.exp(cur_predict) / (1 + np.exp(cur_predict))
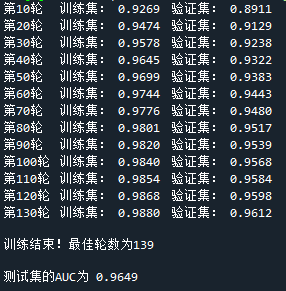
运行结果如下