音视频/流媒体协议和编码汇总
一、流媒体协议
1. RTMP/RTMPT/RTMPS/RTMPE 等多变种
是应用层协议,使用TCP作为底层传输协议,并提供了低延迟、高带宽利用率和实时性的特点。
(1)RTMP协议是Adobe的私有协议,未完全公开
(2)一般传输的是 flv,f4v 格式流
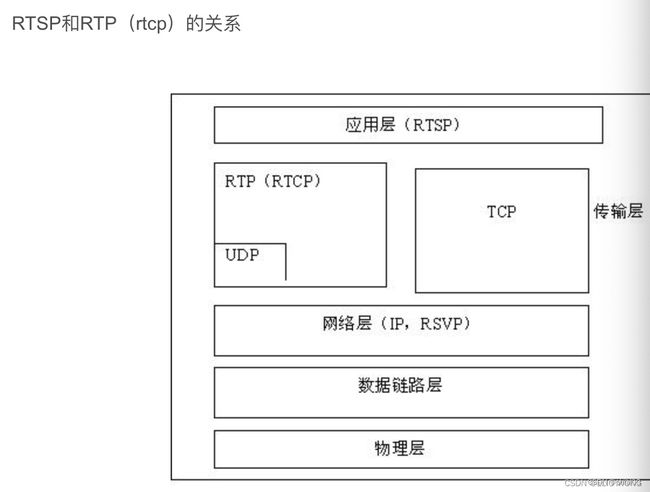
2. RTP/RTCP/SRTP
都作用于OSI模型中的传输层。
RTCP是RTP的补充协议,用于提供对RTP会话的控制和监控。RTCP负责传输会话中的控制信息,包括发送者和接收者的统计信息、网络延迟、会话质量反馈等
SRTP是在RTP(Real-time Transport Protocol)的基础上添加了加密和认证机制,用于保护音频和视频数据的机密性和完整性。
3. RTSP/RTSPS
是一种应用层协议,本身并不传输媒体数据,但它可以与其他协议结合使用,如RTP来实现实时流媒体的传输。
(1)RTSP可以使用TCP作为底层传输协议,也可以使用UDP
(2)RTSPS是RTSP的安全版本,使用了TLS/SSL协议来加密和保护数据传输,以防止数据在传输过程中被窃听和篡改。RTSPS通常使用TCP作为底层传输协议。
(3)一般传输的是 ts、mp4 格式的流
4. HTTP-FLV
是一个应用层协议,用于传输Flash Video (FLV) 格式的音视频数据
5. HTTP-TS
基于MPEG-2 TS(Transport Stream)标准。它将视频、音频和其他媒体数据打包成小的TS分片,并通过HTTP协议进行传输。每个TS分片通常包含几秒钟的媒体数据。这种分片的方式使得流媒体可以通过HTTP协议进行可靠的传输,并且具有较低的延迟。在接收端,客户端会按顺序下载和播放这些TS分片,从而实现连续的流媒体播放。
6. HTTP-FMP4
基于Fragmented MP4(FMP4)标准。与HTTP-TS不同,HTTP-FMP4将视频、音频和其他媒体数据打包成小的MP4片段(Fragment),而不是MPEG-2 TS分片。这些MP4片段通常包含几秒钟的媒体数据。与HTTP-TS相比,HTTP-FMP4在流媒体传输中更为常见,因为它具有更广泛的兼容性和较低的延迟。它也更适合在移动设备和浏览器中播放。
7. MP4
MP4(MPEG-4 Part 14)是一种常见的媒体容器格式,用于存储音频、视频和其他媒体数据。它可以包含多种编码的音频和视频流,以及字幕、章节标记和元数据等信息。MP4文件通常用于存储和传输点播内容。
MP4和HTTP-FMP4之间的主要区别在于:
- 格式:MP4是媒体容器格式,用于存储和传输媒体数据。HTTP-FMP4是基于FMP4标准的流媒体格式,用于通过HTTP协议传输切分后的MP4片段。
- 传输方式:MP4文件可以通过各种传输方式进行传输,包括HTTP、FTP等。HTTP-FMP4则是特定于HTTP协议的流媒体传输格式,利用HTTP分片传输技术将切分后的MP4片段逐个传输和播放。
- 应用场景:MP4适用于存储和传输点播内容,用户可以随时选择和播放。HTTP-FMP4主要用于流媒体传输,支持实时流媒体和自适应流媒体传输,适用于直播、实时通信和点播等应用。
8. HLS
是一个应用层协议,将媒体文件切片成小的TS(Transport Stream)文件,通过HTTP协议进行分段传输
9. DASH
是一个应用层协议,是一种广义术语,描述基于HTTP的动态自适应流媒体传输方法,由MPEG提供支持。它将媒体文件切片成小的MP4文件,通过HTTP协议进行分段传输,并根据网络条件和设备能力动态选择最适合的片段进行播放
10. MPEG-DASH
MPEG-DASH是由国际标准化组织ISO/IEC MPEG(Moving Picture Experts Group)制定的标准,即ISO/IEC 23009-1。MPEG-DASH建立在DASH的概念和原则之上,是一个具体的标准,提供了标准化的规范和指南,旨在实现跨不同厂商和平台的互操作性。提供了一些特性(如自适应比特率调整、多音轨和字幕支持等)
11. WebSocket-FLV
使用WebSocket协议传输FLV(Flash Video)格式的流媒体协议
12. WebSocket-TS
使用WebSocket协议传输MPEG-2 TS(Transport Stream)格式的流媒体
13. WebSocket-FMP4
使用WebSocket协议传输Fragmented MP4(fMP4)格式的流媒体
14. SRT
SRT是一个在传输层提供可靠和安全数据传输的协议。它使用UDP作为底层传输协议,并在其上添加了自定义的机制来实现可靠性和安全性。是一个传输层协议。
SRT全称Secure Reliable Transport,是Haivision推出的一个广播传输协议,主要是为了 替代RTMP,实际上OBS、vMix、FFmpeg等直播推流编码器都已经支持了SRT。SRT使用的封装是TS封装,因此对于新的Codec天然就支持。而SRT基于UDP协议,因此对于延迟和弱网传输,也比RTMP要好不少。 一般RTMP延迟在1到3秒以上,而SRT的延迟在300到500毫秒,而且在弱网下表现也很稳定。在广播电视l领域,由于长距离跨国跨地区 传输,或者户外广播时,网络不稳定,因此SRT比RTMP的优势会更明显。
15. SCTP
是一个传输层协议,它与传输控制协议(TCP)和用户数据报协议(UDP)类似,是一种作为一个独立的传输层协议而存在。
主要特点:
- 可靠性:SCTP提供了可靠的传输机制,通过使用序列号、确认机制和重传机制来确保数据的可靠传输。它还能够检测和恢复网络中的丢失、重复、乱序和拥塞等问题。
- 多流传输:SCTP支持将数据划分为多个独立的逻辑流进行传输。每个流都有自己的序列号和确认机制,可以独立地传输和重传数据。这种多流传输机制使得SCTP适用于同时传输多个应用程序数据流的场景,提供更好的性能和效率。
- 心跳机制:SCTP通过发送心跳包来检测对等端的可用性。心跳机制可以用于检测连接中断、故障节点和网络拥塞等情况,并触发相应的处理机制。
- 有序交付:SCTP可以保证数据按照发送的顺序交付给应用程序,即使在网络中发生乱序的情况下也能够进行重新排序。
- 拥塞控制:SCTP具有自适应的拥塞控制算法,可以根据网络拥塞程度动态调整发送速率,以避免网络拥塞和数据丢失。


16. RIST
RIST是一个在传输层使用UDP协议,并在应用层提供可靠性和流控制功能的流传输协议。它并不是一个纯粹的应用层协议,而是在传输层和应用层之间操作的协议。
RIST的设计目标是解决流媒体传输中的可靠性和性能问题,使得传输更加稳定和高效。
RIST的主要特点和功能包括:
- 可靠性:RIST使用前向纠错(Forward Error Correction)和重传机制来确保数据的可靠传输。前向纠错技术允许接收端在接收到部分丢失或损坏的数据时进行恢复,而重传机制可在发生数据丢失时重新发送数据。
- 安全性:RIST支持加密和身份验证机制,以保护传输的数据的机密性和完整性。它可以使用TLS(Transport Layer Security)协议对传输进行加密,并使用数字证书对通信双方进行身份验证。
- 低延迟:RIST通过优化传输机制和减少协议开销,以实现较低的传输延迟。这对于实时应用程序(如直播和远程协作)至关重要,可以提供更好的用户体验。
- 带宽利用:RIST使用动态带宽控制和拥塞控制机制,以适应网络条件和变化的带宽。它可根据当前网络状况自适应地调整传输速率,以充分利用可用的带宽并避免网络拥塞。
17. SIP(SIP-T )
SIP 是应用层协议,SIP-T是SIP的一个变体,专门设计用于传统电话网络(Public Switched Telephone Network,PSTN)与IP网络之间的互联。它是一种扩展的SIP协议,支持传统电话网络中的信令和媒体传输。
18. SDP
SDP是一个应用层协议,通常与其他应用层协议(如SIP、WebRTC等)一起使用,以实现多媒体通信的功能。
19. WebRTC
WebRTC(Web Real-Time Communication)不是一个单独的协议,而是一个包含多个协议和技术的集合,用于在Web浏览器之间实现实时通信。因此,WebRTC并不属于单一的协议层,而是跨越了多个协议层。
WebRTC涵盖了应用层、传输层和网络层等多个协议层的功能和特性。(1)在应用层,WebRTC提供了JavaScript API,使开发者能够通过Web浏览器直接访问音频、视频和数据流,使开发者能够从摄像头、麦克风等设备中捕获音视频流,并对其进行处理和处理。(2)在传输层,WebRTC使用实时传输协议(Real-Time Transport Protocol,RTP)和用户数据报协议(User Datagram Protocol,UDP)等协议,用于实时传输音视频和数据。支持点对点(Peer-to-Peer)和点对多(Peer-to-Multi-Peer)的通信模式。(3)在网络层,WebRTC通过使用ICE(Interactive Connectivity Establishment)和STUN(Session Traversal Utilities for NAT)等技术,解决了在NAT和防火墙后面进行通信的问题。
WebRTC使用信令协议来协商和建立通信会话。常用的信令协议包括基于SIP(Session Initiation Protocol)的协议和WebSocket等。通过信令,浏览器能够交换SDP(Session Description Protocol)消息,以协商会话参数和建立连接。
20. MGCP
一种用于控制媒体网关的协议,负责协调和控制VoIP网络中的语音和多媒体流的传输。它使用客户端/服务器模型,将媒体网关作为执行者,由中央控制器发送MGCP命令来控制和管理媒体网关的行为。
21. H.323
H.323是一套用于在IP网络上进行语音、视频和数据实时通信的标准和协议套件。它提供了终端、网关、MCU等组件,以及呼叫控制信令和RTP等协议,实现了多媒体通信的互操作性和实时性
22. QUIC
应用层协议,基于 UDP传输层协议。
QUIC协议的关键特点和功能:
- 快速连接建立:QUIC使用UDP协议以及自定义的QUIC协议栈,通过减少握手往返次数和使用连接迁移技术,大大减少了连接建立的延迟。
- 多路复用:QUIC支持在单个连接上同时传输多个数据流,这些数据流可以并行传输,并且不会相互阻塞。这种多路复用的特性有助于提高网络利用率和传输效率。
- 低延迟:QUIC通过使用更低的连接建立延迟、减少拥塞控制延迟和优化数据包传输路径等方式,努力降低网络延迟,提供更快的数据传输速度。
- 安全性:QUIC内置了加密机制,使用TLS(Transport Layer Security)协议来保护数据的机密性和完整性。它还提供了快速的握手过程和零RTT(Round-Trip Time)恢复,以提供更快的安全连接建立和恢复速度。
- 连接迁移:QUIC具有连接迁移功能,可以在客户端和服务器之间切换网络连接,而无需重新建立全新的连接。这在移动设备从Wi-Fi切换到移动网络或网络切换的情况下特别有用。
- 拥塞控制:QUIC使用自己的拥塞控制算法,以适应不同网络条件下的拥塞情况,并通过动态调整数据包发送速率来优化网络性能。
23. GB28181
GB28181是中国国家标准局发布的《基于IP的视频监控联网系统》标准,也被称为《视频监控联网系统信息传输、交互和控制协议》。它是一种用于视频监控系统中设备间通信和互联互通的协议和标准。
GB28181采用基于IP的架构,使用标准的网络协议和技术,如HTTP、RTSP、RTP等,实现视频设备的联网和互操作。该标准规范了视频设备之间的信令交互、媒体传输和设备控制等方面的规范,以确保视频监控系统的互联互通和协同工作。
具体来说,GB28181标准包括以下主要内容:
- 设备注册和发现:定义了设备注册、注销和发现的过程和机制,使监控中心能够自动发现和管理网络中的视频设备。
- 媒体传输:规定了基于IP的视频和音频数据的传输方式,使用实时流媒体协议(如RTP、RTSP)进行传输。
- 控制和事件:定义了设备之间的控制命令和事件通知机制,包括设备状态查询、云台控制、告警事件等。
- 安全认证和加密:提供了安全认证机制和加密传输的支持,以保障视频监控系统的安全性和数据保密性。
- 系统架构和接口:规范了视频监控系统的整体架构、组件和接口,以确保不同厂商的设备能够相互兼容和互操作。
通过遵循GB28181标准,不同厂商的视频设备可以实现互联互通,监控中心能够集中管理和控制各个设备,实现统一的视频监控系统。该标准的实施促进了视频监控系统的互联互通和集成,提高了系统的可扩展性、灵活性和互操作性。


RIST 和 SCTP 设计和功能区别:
RIST(Reliable Internet Stream Transport)和SCTP(Stream Control Transmission Protocol)是两种不同的协议,具有不同的设计目标和应用场景。
- 目标和应用场景:RIST是用于在互联网上传输流媒体的可靠传输协议,旨在解决流媒体传输中的可靠性、安全性和带宽利用等问题。它适用于视频直播、远程制片、远程采访和远程监控等应用。而SCTP是一种传输层协议,旨在提供可靠的数据传输和多流并发传输。它适用于需要可靠传输和多个逻辑流的应用场景,如VoIP、视频传输和实时游戏等。
- 可靠性机制:RIST使用前向纠错和重传机制来确保数据的可靠传输。前向纠错技术允许接收端在接收到部分丢失或损坏的数据时进行恢复,而重传机制可在发生数据丢失时重新发送数据。SCTP也提供可靠的传输机制,通过序列号、确认机制和重传机制来确保数据的可靠交付。它还支持有序交付和拥塞控制等功能。
- 多流传输:RIST支持将数据划分为多个独立的逻辑流进行传输,每个流都有自己的序列号和确认机制。这种多流传输机制使得RIST适用于同时传输多个应用程序数据流的场景。而SCTP本身即支持多流传输,可以在一个SCTP连接上并行传输多个逻辑流,每个流都有自己的序列号和确认机制。
- 安全性:RIST支持加密和身份验证机制,以保护传输的数据的机密性和完整性。它可以使用TLS协议对传输进行加密,并使用数字证书对通信双方进行身份验证。而SCTP本身并没有内建的加密和身份验证机制,但可以与其他安全协议(如IPsec)结合使用,以提供安全的传输。
总的来说,RIST是一个用于流媒体传输的可靠传输协议,着重解决流媒体传输中的可靠性和性能问题。而SCTP是一种传输层协议,提供可靠的数据传输和多流并发传输。它们在目标、应用场景和功能上有所差异,但都可以用于特定的流媒体传输需求。
二、协议分类和封装
1. 从交互方式看
1.1 直播(LIVE)
HLS, RTMP, http+MP4, http+flv, RTP+RTSP
1.2 点播(VOD)
http+MP4, http+flv, HLS, DASH
2. 从业务场景看
2.1 直播
RTMP, HLS, http+flv
2.2 音视频通话:
webrtc(RTP), SIP+RTP
2.3 视频点播:
http+MP4, http+flv, hls
2.4 IPTV:
RTSP(信令)+RTP(媒体)
2.5 会议电视:
RTP(媒体)+SIP(信令),H323(信令)+RTP(媒体)
2.6 视频监控:
国标SIP(信令)+RTP(媒体),RTSP(媒体)+RTP(媒体)
2.7 VOIP
SIP(信令)+RTP(媒体)
3. 从传输层方式:
3.1 TCP
基于http 类传输协议和rtmp协议底层是tcp传输;
RTSP通常做信令,用TCP来承载
3.2 UDP
RTP协议和RTCP协议是基于UDP承载的
3.3 SCTP
注:关于TCP和UDP承载的区别
1)TCP 传输的特点:面向连接,保序,可靠;
TCP的协议栈完成了拥塞控制,流量控制,乱序重排,丢包重传等工作。保证数据是有序可靠的。适合对数据完整性要求高的场景:如文件下载,网页浏览,信令传输。
2)UDP 传输特点:面向无连接,不保序,不可靠连接
UDP协议不是面向连接的,只是简单向对方发送数据,哪怕对方不存在。正因为协议简单,所以传输效率高,实时高,延迟低。适合对数据完整性要求不高,但实时性高的场景。如音视频传输,游戏等。
3)关于组播与广播,单播
TCP是一个面向连接的协议,TCP一定是点对点的,一定是两个主机来建立连接的,TCP肯定是单播。只有UDP才会使用广播和组播。有时一个主机要向网上的所有其它主机发送帧,这就是广播,广播分为二层广播(目的MAC全F)和三层广播(IP地址的主机位全1),二层广播是不能跨路由器的,三层广播是可以跨路由器路由的。多播(组播)属于单播和广播之间,帧仅传送给属于多播组的多个主机。在广播电视领域为了减少服务器压力,通常使用组播跟用户推流。如IPTV,通常机顶盒通过光猫加入某个组播地址,接收某个CDN的组播流。


三、流媒体编码
1. 视频编码
1.1 H.264/AVC
一种广泛使用的视频编码标准,具有高压缩比和良好的视频质量。
1.2 H.265/HEVC
一种高效的视频编码标准,提供更好的压缩性能和视频质量。
1.3 VP9
由Google开发的开源视频编码格式,具有高压缩效率和良好的视频质量。
1.4 AV1
由Alliance for Open Media开发的开源视频编码格式,旨在提供高效的视频压缩和更好的图像质量。
1.5 MPEG-2
一种常见的视频压缩标准,广泛应用于广播、DVD和数字电视等领域。
1.6 MPEG-4:
一种多媒体压缩标准,支持视频、音频和其他媒体数据的压缩和传输。
1.7 VP8:
由On2 Technologies开发的视频编码格式,是VP9的前身,现在仍然被一些应用使用。
1.8 VC-1
VC-1是软件巨头微软力推的一种视频编码的格式,弱于H.264,也弱于MPEG-4
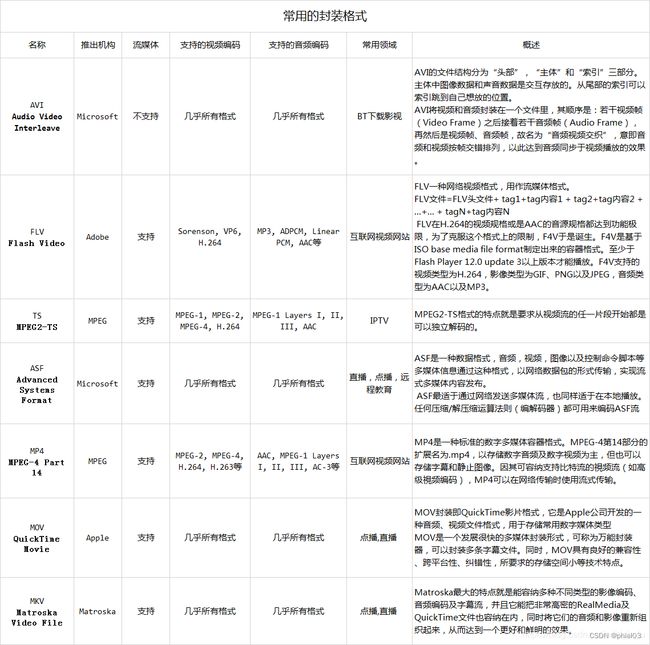
2. 视频格式
2.1 MP4
2.2 AVI
2.3 FLV
2.4 F4V
2.5 MOV
2.6 MPEG
2.7 MKV
2.8 TS
2.9 RMVB
2.10 WEBM
常见在线流媒体格式:mp4、flv、f4v、webm
移动设备格式:m4v、mov、3gp、3g2
RealPlayer :rm、rmvb
微软格式 :wmv、avi、asf
MPEG 视频 :mpg、mpeg、mpe、ts
DV格式 :div、dv、divx
其他格式 :vob、dat、mkv、lavf、cpk、dirac、ram、qt、fli、flc、mod
3. 视频帧
3.1.1 帧
根据编码思路,H.264标准分了三种帧:I帧、P帧与B帧
(1)I帧
I 帧,帧内编码图像帧,不参考其他图像帧,只利用本帧的信息进行编码。
I帧是一个完整编码的帧,即一个序列的第一帧。
(2)P帧
P 帧,即预测编码图像帧,利用之前的 I 帧或 P 帧,进行帧间预测编码。
P帧根据之前的之前的I帧或者P帧,利用运动预测的方式,编码与前一帧的差值。由于I、P帧可能被后续的P帧作为计算基础所参考,所以I、P帧都称之为**参考帧****,**参考帧的错误解码会导致后续的帧解码也发生错误,造成解码错误扩散。
(3)B帧
B 帧,即双向预测编码图像帧,它既需要之前的图像帧(I 帧或 P 帧),也需要后来的图像帧(P 帧),进行帧间双向预测编码。
B帧需要同时根据前后两个参考帧作为基础进行计算,但B帧本身不作为参考帧,B帧解码错误不会引起扩散。同时B帧的编码效率最好,可以提高视频压缩率,但会增加视频解码的复杂度。
B帧并不是必须的,在需要压缩空间时通常会使用,例如存电影等,使用大量的B帧可以节约空间。而对于直播等这种对实时性要求比较高的场景,B帧需要缓冲多余的数据,还会加重CPU的负担,因此通常不使用B帧。
3.1.2 GOP与IDR
GOP即是一个序列长度,由一组I、P、B帧组成。其中序列的首帧(显然,一定是I帧)被称为IDR帧,解码器在读到IDR帧后会清除掉之前参考帧的缓存,从这个I帧开始重新进行计算,可以避免前边的GOP出错影响到后续的解码。
现代编码器会动态的根据帧内容变化幅度,来决定GOP的长度,获得一个比较好的编码效率。
3.1.3 PTS和DTS
在使用B帧时,由于B帧需要前后参考的特性,所以需要把B帧之后的P帧挪到前边去传输。但这样就引入了一个问题,播放的顺序与传输的顺序不一致。所以就有PTS和DTS,分别用来标识传输的顺序与播放的顺序,像这样
Stream: I P B B
DTS: 1 2 3 4
PTS: 1 4 2 3
3.1.4 帧内压缩
(1)帧内预测
一般来说,对于一幅图片,图片中像素的分布一般是有规律的,可以用几种模式大致的匹配像素分布的样,子H.264就根据这个原理进行帧内预测。按像素预测效率比较低,因此H.264提出块的概念。一个1616的像素块成21为宏块,一个宏块还能进一步分为一个44的子块(考虑到YUV的编码模式,都是基于4个Y共享UV的逻辑)。H.264提前针对子块和宏块设定了预置的预测模式(色度块和亮度块都有自己的预测模式),用于描述对于相邻块的变化。
对于比较平坦的部分,我们记录相邻宏块的预测模式即可。对于带有大量细节的部分,则细化到子块,记录子块的变化模式。
显然,这样预测出来的图片和现实图片是有差别的,所以我们还需要计算一遍残差,即和原始图片的区别。将残差和预测模式合到一起,就可以还原出原来的图片了
(2)残差压缩
我们刚刚获得的残差图还是比较大的,使用DCT-离散余弦变换可以进一步压缩残差图/
(3)量化
H.264还会对图像进行量化,计算方法如下
FQ = round( y / QP )
即对于每个像素点的编码数据y,会指定一个步长QP,用编码数值去除步长就会获得一个编码范围比较小的量化值FQ。但是量化同时会使图像的动态范围变窄,会丢失一些精度。
4. 视频基础概念
4.1 分辨率(Resolution)
视频的分辨率指的是图像的像素数量,通常表示为宽度×高度(例如,1920×1080)。较高的分辨率意味着更多的像素,提供更清晰的图像。
4.2 帧率(Frame Rate)
视频的帧率表示每秒显示的图像数量,通常以帧每秒(fps)为单位。常见的视频帧率包括30fps、60fps等。较高的帧率可以提供更流畅的视频体验。
4.3 码率(Bit Rate)
视频的码率表示每秒传输的数据量,通常以比特率(bps)为单位。较高的码率可以提供更高质量的图像,但也需要更高的带宽。
- 码率与视频质量关系:视频的码率与图像质量之间存在一定的关系。较高的码率通常会提供更高的图像质量,因为更多的数据可以用于表示图像细节和运动。然而,随着码率增加,图像质量的提升逐渐减弱。在一定范围内,增加码率可以改善图像质量,但超过一定点后,增加的码率对图像质量的改善效果较小。
- 码率与文件大小关系:视频的码率也会直接影响到视频文件的大小。较高的码率会导致更大的文件大小,因为更多的数据被用于表示图像细节和运动。因此,在视频编码中需要权衡码率和文件大小之间的关系,以平衡视频质量和存储/传输成本。
- 码率与带宽要求关系:视频的码率还决定了在传输视频时所需的带宽。较高的码率需要更大的带宽来传输,因此在网络传输视频时,需要考虑网络带宽的限制。如果网络带宽不足以支持视频的码率,可能会导致视频卡顿、缓冲等问题。
- 码率与编码效率关系:不同的视频编码标准具有不同的编码效率,即相同码率下能够提供的视频质量。一种高效的编码标准可以在相同码率下提供更好的图像质量,或者在相同图像质量下使用更低的码率。因此,选择合适的视频编码标准也是影响视频码率和质量的重要因素。
4.4 编码(Encoding)
视频编码是将原始视频信号转换为数字数据的过程。常见的视频编码标准包括H.264(AVC)、H.265(HEVC)、MPEG-2等。编码可以压缩视频数据,减小文件大小或传输带宽。
4.5 容器格式(Container Format)
视频容器格式是将视频、音频和其他元数据组合在一起的文件格式。常见的视频容器格式包括MP4、MKV、AVI等。容器格式可以包含不同编码的音视频流,并提供元数据和同步信息。

5. 音频编码
5.1 AAC
5.2 MP3
5.3 WMA
5.4 WAV
5.5 OGG
5.6 APE
5.7 AC-3
5.8 FLAC
6. 音频格式
6.1 MP3
6.2 AAC
6.3 WAV
6.4 AIFF
7. 音频基础概念
7.1 采样率(Sample Rate)
采样率表示每秒对声音信号进行采样的次数,通常以赫兹(Hz)为单位。采样频率越高,声音的还原就越真实越自然,当然数据量就越大。采样率根据使用类型不同大概有以下几种:
- 8khz:电话等使用,对于记录人声已经足够使用。
- 22.05khz:广播使用频率。
- 44.1khz:音频CD。
- 48khz:DVD、数字电视中使用。
- 96khz-192khz:DVD-Audio、蓝光高清等使用。
采样精度常用范围为 8bit-32bit,而 CD 中一般都使用 16bit。
7.2 位深度(Bit Depth)
位深度也称采样位数,也称量化级、样本尺寸、量化数据位数,指每个采样点能够表示的数据范围,它以位(Bit)为单位。采样位数通常有 8bits 或 16bits 两种,采样位数越大,所能记录声音的变化度就越细腻,相应的数据量就越大。8 位字长量化(低品质)和 16 位字长量化(高品质),16 bit 是最常见的采样精度。
7.3 通道数(Channels)
声道数是指支持能不同发声的音响的个数,它是衡量音响设备的重要指标之一。
音频的通道数表示同时传输的独立音频信号的数量。常见的通道数包括单声道(Mono)、立体声(Stereo)、5.1声道等。不同的通道数可以提供不同的音频空间效果。
7.4 量化
将采样后离散信号的幅度用二进制数表示出来的过程称为量化。(日常生活所说的量化,就是设定一个范围或者区间,然后看获取到的数据在这个条件内的收集出来)。
7.5 比特率
比特率(也称位速、比特率),是指在一个数据流中每秒钟能通过的信息量,代表了压缩质量。比如 MP3 常用码率有 128kbit/s、160kbit/s、320kbit/s 等等,越高代表着声音音质越好。
比特率 = 采样率 × 采样深度 × 通道数。比如 采样率 = 44100,采样深度 = 16,通道 = 2 的音频的的比特率就是 44100 * 16 * 2 = 1411200 bps。
7.6 编码(Encoding)
音频编码是将原始音频信号转换为数字数据的过程。常见的音频编码标准包括MP3、AAC、Opus等。编码可以压缩音频数据,减小文件大小或传输带宽。
7.7 容器格式(Container Format)
音频容器格式是将音频、视频和其他元数据组合在一起的文件格式。常见的音频容器格式包括MP3、WAV、FLAC等。容器格式可以包含不同编码的音频流,并提供元数据和同步信息。
四、图像像素
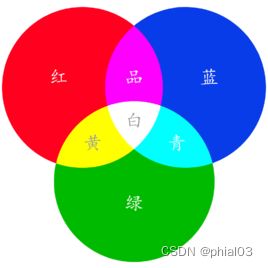
1. RGB
RGB是red,green, blue的简写,也就是红绿蓝三种颜色。他们是三原色,通过不同的比例相加,以产生多种多样的色光。
(1)索引形式
A. 索引格式是计算机早期的一种格式,它的优点比较节省空间,缺点是表现的色彩有限,目前格式基本被抛弃了,不再被使用,这里只做简单介绍。
B. 索引格式中的bit存储的并非是实际的R,G, B值,而是对应点的像素在调色板中的索引。
C. 调色板,可以简单理解为通过编号映射到颜色的一张二维表。如01索引,表示红色。采用索引格式的RGB,红色的像素对应存储的值便是索引01。就像指针一样,存储的是值的地址,而不是真正的值。
- RGB1
每个像素用1个bit表示,可表示的颜色范围为双色,即黑和白。1个bit只能表示0,1两种值。需要调色板,不过调色板只包含两种颜色。 - RGB4
每个像素用4个bit表示,4个bit所能够表示的索引范围是0-15,共16个。也就是可以表示16种颜色。即调色板中包含16中颜色。 - RGB8
每个像素用8个bit表示。8个bit所能够表示的索引范围是0-255,共256个。也就是可以表示256中颜色。即调色板中包含256中颜色。
(2)像素形式
RGB像素格式中的bit存储的是每一个像素点的R,G,B值
注意:java默认使用大端字节序,c/c++默认使用小端字节序,android平台下Bitmap.config.ARGB_8888的Bitmap默认是大端字节序,当需要把这个图片内存数据给小端语言使用的时候,就需要把大端字节序转换为小端字节序。例如:java层的ARGB_565传递给jni层使用时,需要把java层的ARGB_565的内存数据转换为BGRA565!
- RGB565

一个像素用16个bit = 2个字节表示 ,R=5 G=6 B=5
R = color & 0xF800; //获取高字节的5个bit
G = color & 0x07E0; //获取中间6个bit
B = color & 0x001F; //获取低字节5个bit
- RGB555

一个像素用16个bit = 2个字节,但是最高位不用,R=5 G=5 B=5
R = color & 0x7C00; //获取高字节的5个bit
G = color & 0x03E0; //获取中间5个bit
B = color & 0x001F; //获取低字节5个bit
- RGB24

一个像素用24个bit = 3个字节来表示,R=8 G=8 B=8
R = color & 0x0000FF00;
G = color & 0x00FF0000;
B = color & 0xFF000000;
- RGB32

一个像素用32个bit = 4个字节 来表示,R=8 G=8 B=8,存储顺序为B, G, R,最后8个字节保留
R = color & 0x0000FF00;
G = color & 0x00FF0000;
B = color & 0xFF000000;
A = color & 0x000000FF;
2. YUV
YUV,是一种颜色编码方法。常使用在各个影像处理组件中。 YUV在对照片或影片编码时,考虑到人类的感知能力,允许降低色度的带宽。
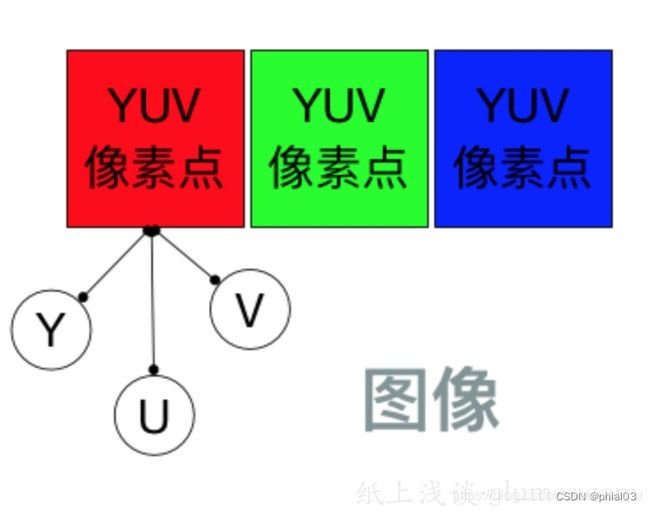
Y表示明亮度(Luminance或Luma),也就是灰度值;
U(Cb)表示色度(Chrominance)
V(Cr)表示浓度(Chroma)
通常UV一起描述影像色彩和饱和度,用于指定像素的颜色。
对于 YUV 图像来说,并不是每个像素点都需要包含了 Y、U、V 三个分量,根据不同的采样格式,可以每个 Y 分量都对应自己的 UV 分量,也可以几个 Y 分量共用 UV 分量。
(1)采样格式
- YUV444

YUV 4:4:4 采样,意味着 Y、U、V 三个分量的采样比例相同,因此在生成的图像里,每个像素的三个分量信息完整,都是 8 bit,也就是一个字节。
图像像素数据: Y0U0V0 Y1U1V1 Y2U2V2 Y3U3V3
采样的码流: Y0 U0 V0 Y1 U1 V1 Y2 U2 V2 Y3 U3 V3
为什么叫4:4:4 , 意思是每4个像素里的数据有4个Y, 4个U, 4个V
Y分量的大小: wh
U分量的大小: wh
V分量的大小: w*h
通过YUV444采样的图像大小和RGB颜色模型的图像大小是一样的。
一张 1280 * 720 大小的图片,在 YUV 4:4:4 采样时的大小为:
(1280*720*8 + 1280*720*8 + 1280*720*8)/8/1024/1024 = 2.64 MB
- YUV422

YUV 4:2:2 采样,意味着每采样过一个像素点,都会采样其 Y 分量,而 U、V 分量就会间隔一个采集一个,Y 分量和 UV 分量按照 2 : 1 的比例采样。如果水平方向有8个像素点,那么就采样8 个 Y 分量,4 个 UV 分量。
图像像素数据: Y0U0V0 Y1U1V1 Y2U2V2 Y3U3V3
采样的码流: Y0 U0 Y1 V1 Y2 U2 Y3 V3
为什么叫4:2:2,意思是每4个像素里面有4个Y,2个U,2个V
Y分量的大小: wh
U分量的大小: wh/2
V分量的大小: wh/2
一张 1280 * 720 大小的图片,在 YUV 4:2:2 采样时的大小为:
(12807208 + (1280720)/28 + (1280720)/2*8)/8/1024/1024 = 1.76 MB
通过与YUV444采样进行比较可以算出,YUV422 采样的图像比YUV444采样图像节省了三分之一的存储空间,在传输时占用的带宽也会减少。
- YUV420
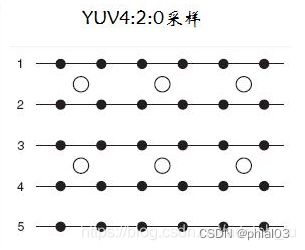
YUV 4:2:0 采样,并不是指只采样 U 分量而不采样 V 分量。而是指,其中,每采样过一个像素点,都会采样其 Y 分量,而 U、V 分量就会间隔一行按照 2 : 1 进行采样。比如,第一行扫描时,YU 按照 2 : 1 的方式采样,那么第二行扫描时,YV 分量按照 2:1 的方式采样。对于每个色度分量来说,它的水平方向和竖直方向的采样和 Y 分量相比都是 2:1 。
图像像素数据: [Y0 U0 V0]、[Y1 U1 V1]、 [Y2 U2 V2]、 [Y3 U3 V3]
[Y5 U5 V5]、[Y6 U6 V6]、 [Y7 U7 V7] 、[Y8 U8 V8]
采样的码流: Y0 U0 Y1 Y2 U2 Y3
Y5 V5 Y6 Y7 V7 Y8
为什么叫4:2:0,意思是每4个像素中有4个Y,2个U,0个V,而下一行的四个像素中有4个Y,0个U,2个V
Y分量的大小: wh
U分量的大小: wh/4
V分量的大小: w*h/4
一张 1280 * 720 大小的图片,在 YUV 4:2:0 采样时的大小为:
(1280*720*8 + (1280*720)/4*8 + (1280*720)/4*8)/8/1024/1024 = 1.32 MB
可以看到 YUV420 采样的图像比 RGB 模型图像节省了一半的存储空间,因此它也是比较主流的采样方式。
(2)存储格式
- planar
平面格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,然后是所有像素点的V;将几个分量分开存,比如YUV420中,data[0]专门存Y,data[1]专门存U,data[2]专门存V。 - packed
打包格式,每个像素点的Y,U,V是连续交错存储的,所有数据都存在data[0]中。
(3)常见格式
根据采样方式和存储格式的不同,就有了多种 YUV 格式。这些格式主要是基于 YUV 4:2:2 和 YUV 4:2:0 采样。
常见的基于 YUV 4:2:2 采样的格式如: - YUV422P
YUV 422P 格式,又叫做 I422,采用的是平面格式进行存储,先存储所有的 Y 分量,再存储所有的 U 分量,再存储所有的 V 分量。
Y0 Y1 Y2 Y3 U0 U1 V0 V1
- YUYV
YUYV 格式是采用打包格式进行存储的,指每个像素点都采用 Y 分量,但是每隔一个像素采样它的 UV 分量,排列顺序如下:
Y0 UO Y1 V0 Y2 U1 Y3 V1
Y0 和 Y1 公用 U0 V0 分量,Y2 和 Y3 公用 U1 V1 分量
- UYVY
UYVY 格式是采用打包格式进行存储,它的顺序和 YUYV 相反,先采用 U 分量再采样 Y 分量,排列顺序如下:
U0 Y0 V0 Y1 U1 Y2 V1 Y3
常见的基于 YUV 4:2:0 采样的格式如:
| YUV420采样 | YUV420采样 | |
|---|---|---|
| YUV420P存储 | YV12 | NV12 |
| YUV420SP存储 | NV12 | NV21 |
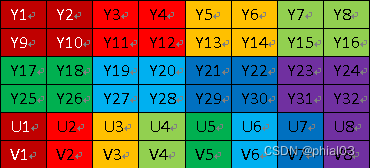
YUV420P 和 YUV420SP 都是基于 Planar 平面模式 进行存储的,先存储所有的 Y 分量后, YUV420P 类型就会先存储所有的 U 分量或者 V 分量,而 YUV420SP 则是按照 UV 或者 VU 的交替顺序进行存储了.
-
YUV420P
-
YUV420SP

-
YV12
YV12,采用的是平面格式进行存储,先存 Y 分量,再存 V 分量,最后U分量
Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7
V0
U0
- YU12
YU12,采用的是平面格式进行存储,先存 Y 分量,再存 U分量,最后V分量
Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7
U0
V0
- NV12 (ios常用)
NV12,采用的是平面格式进行存储,再 UV 进行交替存储
Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7
U0 V0
- NV21(android常用)
NV21,采用的是平面格式进行存储,再 VU 进行交替存储
Y0 Y1 Y2 Y3 Y4 Y5 Y6 Y7
V0 U0
五、关键技术和应用
1. OpenCV(JavaCV,JavaCpp)
开源的计算机视觉和图像处理库,提供了丰富的函数和工具,用于处理图像和视频数据
2. OpenCL/OpenGL
OpenCL是一种基于开放标准的平台,它可以让应用程序使用各种计算平台,包括CPU、GPU和FPGA。OpenCL的主要目的是充分利用基于多核处理器的计算机硬件。
教程:https://deepinout.com/opencl
3. FFmpeg
开源的跨平台多媒体音视频处理工具集
4. CUDA
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的并行计算平台和编程模型。它允许开发者利用NVIDIA GPU的并行计算能力来加速各种计算任务,包括科学计算、机器学习、图形渲染等。CUDA提供了一组编程接口和工具,使开发者能够在GPU上编写并行程序,并利用GPU的大规模并行处理能力来加速计算。
5. TensorRT
Tesseract是一个开源的OCR(Optical Character Recognition)引擎,由Google开发和维护。它能够将图像中的文本内容转换为可编辑的文本形式。Tesseract支持多种语言,并且具有一定的准确性和稳定性。
6. SRS
流媒体服务,官网地址 :https://ossrs.net/
7. ZLMediaKit
流媒体服务,官网地址 :https://docs.zlmediakit.com/