Linux内核文件读取流程
本文代码基于Linux5.10。
当上层调用read函数读取一个文件时, Linux 内核究竟如何处理? 本文主要介绍这个问题
数据结构
address_space
linux 的文件在磁盘上可能是不连续的, 但文件读取又需要将文件当成一个连续的字节流, 为了解决这个矛盾, 就引入了address_space。
address_space的作用就是将文件在磁盘上的数据也page的方式连续地呈现出来, 这样读取文件的操作便转换成了先将不连续的磁盘上的内容读取的page中, 再从连续的page中去读取连续的数据。
address_spage的定义如下
include/linux/fs.h
struct address_space {
struct inode *host;
struct xarray i_pages;
gfp_t gfp_mask;
atomic_t i_mmap_writable;
#ifdef CONFIG_READ_ONLY_THP_FOR_FS
/* number of thp, only for non-shmem files */
atomic_t nr_thps;
#endif
struct rb_root_cached i_mmap;
struct rw_semaphore i_mmap_rwsem;
unsigned long nrpages;
unsigned long nrexceptional;
pgoff_t writeback_index;
const struct address_space_operations *a_ops;
unsigned long flags;
errseq_t wb_err;
spinlock_t private_lock;
struct list_head private_list;
void *private_data;
} __attribute__((aligned(sizeof(long)))) __randomize_layout;host: 该结构体对应的文件的inode
i_pages: pages对应的数组
nrpages: 页面总数
a_ops: 地址空间的操作函数
整体流程
由于page cache的存在, read 并不是直接文件中读取, 而是从page cache中读,那么整体流程大概是: 如果page cache存在, 则直接从page cache中读取, 如果不存在, 则将文件内容先读到page cache中, 再copy给用户。
入口函数
read 系统调用的定义如下:
fs/read_write.c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}ksys_read的定义如下:
fs/read_write.c
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos, *ppos = file_ppos(f.file); /* 1 */
if (ppos) {
pos = *ppos;
ppos = &pos;
}
ret = vfs_read(f.file, buf, count, ppos); /* 2 */
if (ret >= 0 && ppos)
f.file->f_pos = pos; /* 3 */
fdput_pos(f);
}
return ret;
}(1) 获取当前文件的偏移
(2) 调用vfs_read执行具体的read流程
(3) 如果读取成功, 更新当前文件的偏移
vfs_read 的定义如下:
fs/read_write.c
ksys_read-> vfs_read
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_READ))
return -EINVAL;
if (unlikely(!access_ok(buf, count))) /* 1 */
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count); /* 2 */
if (ret)
return ret;
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
ret = new_sync_read(file, buf, count, pos); /* 3 */
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
return ret;
}(1) 对文件的模式及用户buf进行检测
(2) 校验用户读取的区域是否有效
(3) 调用new_sync_read进行读取。 由于目前大多数文件系统都是用的新的read_iter回调, 故一般都会走到这里来。 read_iter和read的区别是, read_iter一次性可以读取多个文件片段
new_sync_read的实现如下:
fs/read_write.c
ksys_read-> vfs_read->new_sync_read
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = (ppos ? *ppos : 0);
iov_iter_init(&iter, READ, &iov, 1, len); /* 1 */
ret = call_read_iter(filp, &kiocb, &iter); /* 2 */
BUG_ON(ret == -EIOCBQUEUED);
if (ppos)
*ppos = kiocb.ki_pos;
return ret;
}(1) 初始化kiocb 和iov_iter 这两个结构体,他们用来控制read行为。 其定义如下:
include/linux/fs.h
struct kiocb {
struct file *ki_filp;
/* The 'ki_filp' pointer is shared in a union for aio */
randomized_struct_fields_start
loff_t ki_pos;
void (*ki_complete)(struct kiocb *iocb, long ret, long ret2);
void *private;
int ki_flags;
u16 ki_hint;
u16 ki_ioprio; /* See linux/ioprio.h */
union {
unsigned int ki_cookie; /* for ->iopoll */
struct wait_page_queue *ki_waitq; /* for async buffered IO */
};
randomized_struct_fields_end
};
include/linux/uio.h
struct iov_iter {
/*
* Bit 0 is the read/write bit, set if we're writing.
* Bit 1 is the BVEC_FLAG_NO_REF bit, set if type is a bvec and
* the caller isn't expecting to drop a page reference when done.
*/
unsigned int type;
size_t iov_offset;
size_t count;
union {
const struct iovec *iov;
const struct kvec *kvec;
const struct bio_vec *bvec;
struct pipe_inode_info *pipe;
};
union {
unsigned long nr_segs;
struct {
unsigned int head;
unsigned int start_head;
};
};
};kiocb 用来控制整个读取流程, kernel 每一次读写都会对应一个kiocb (kernel io control block)
iov_iter 记录了所有读取片段的信息。 由于kernel 支持readv这样的调用, 支持一次读取多个片段, iov_iter就是 用来记录所有的片段信息。其中:
iov 指向一个数组, 代表了所有的片段信息
nr_segs 代表iov的数组长度
count代表所有的iov的总长度,即一次读取的总的文件长度
(2) call_read_iter实际上就是调用了file->f_op->read_iter(kio, iter);
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->read_iter(kio, iter);
}以exfat文件系统为例, 其read_iter的实现为
fs/exfat/file.c
const struct file_operations exfat_file_operations = {
.llseek = generic_file_llseek,
.read_iter = generic_file_read_iter,
.write_iter = generic_file_write_iter,
.mmap = generic_file_mmap,
.fsync = exfat_file_fsync,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
};
mm/filemap.c
ksys_read-> vfs_read->new_sync_read->generic_file_read_iter
ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
size_t count = iov_iter_count(iter);
ssize_t retval = 0;
if (!count)
goto out; /* skip atime */
if (iocb->ki_flags & IOCB_DIRECT) {
struct file *file = iocb->ki_filp;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
loff_t size;
size = i_size_read(inode);
if (iocb->ki_flags & IOCB_NOWAIT) {
if (filemap_range_has_page(mapping, iocb->ki_pos,
iocb->ki_pos + count - 1))
return -EAGAIN;
} else {
retval = filemap_write_and_wait_range(mapping,
iocb->ki_pos,
iocb->ki_pos + count - 1);
if (retval < 0)
goto out;
}
file_accessed(file);
retval = mapping->a_ops->direct_IO(iocb, iter);
if (retval >= 0) {
iocb->ki_pos += retval;
count -= retval;
}
iov_iter_revert(iter, count - iov_iter_count(iter));
/*
* Btrfs can have a short DIO read if we encounter
* compressed extents, so if there was an error, or if
* we've already read everything we wanted to, or if
* there was a short read because we hit EOF, go ahead
* and return. Otherwise fallthrough to buffered io for
* the rest of the read. Buffered reads will not work for
* DAX files, so don't bother trying.
*/
if (retval < 0 || !count || iocb->ki_pos >= size ||
IS_DAX(inode))
goto out;
}
retval = generic_file_buffered_read(iocb, iter, retval); /* 1 */
out:
return retval;
}
EXPORT_SYMBOL(generic_file_read_iter);可以看到, read_iter 的实现为generic_file_read_iter, 如果不是DIO, 则直接调用generic_file_buffered_read
mm/filemap.c
ksys_read-> vfs_read->new_sync_read->generic_file_read_iter->generic_file_buffered_read
ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct page *pages_onstack[PAGEVEC_SIZE], **pages = NULL;
unsigned int nr_pages = min_t(unsigned int, 512,
((iocb->ki_pos + iter->count + PAGE_SIZE - 1) >> PAGE_SHIFT) -
(iocb->ki_pos >> PAGE_SHIFT));
int i, pg_nr, error = 0;
bool writably_mapped;
loff_t isize, end_offset;
if (unlikely(iocb->ki_pos >= inode->i_sb->s_maxbytes))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
if (nr_pages > ARRAY_SIZE(pages_onstack))
pages = kmalloc_array(nr_pages, sizeof(void *), GFP_KERNEL);
if (!pages) {
pages = pages_onstack;
nr_pages = min_t(unsigned int, nr_pages, ARRAY_SIZE(pages_onstack));
}
do {
cond_resched();
/*
* If we've already successfully copied some data, then we
* can no longer safely return -EIOCBQUEUED. Hence mark
* an async read NOWAIT at that point.
*/
if ((iocb->ki_flags & IOCB_WAITQ) && written)
iocb->ki_flags |= IOCB_NOWAIT;
i = 0;
pg_nr = generic_file_buffered_read_get_pages(iocb, iter,
pages, nr_pages); /* 1 */
if (pg_nr < 0) {
error = pg_nr;
break;
}
/*
* i_size must be checked after we know the pages are Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
isize = i_size_read(inode);
if (unlikely(iocb->ki_pos >= isize))
goto put_pages;
end_offset = min_t(loff_t, isize, iocb->ki_pos + iter->count);
while ((iocb->ki_pos >> PAGE_SHIFT) + pg_nr >
(end_offset + PAGE_SIZE - 1) >> PAGE_SHIFT)
put_page(pages[--pg_nr]);
/*
* Once we start copying data, we don't want to be touching any
* cachelines that might be contended:
*/
writably_mapped = mapping_writably_mapped(mapping);
/*
* When a sequential read accesses a page several times, only
* mark it as accessed the first time.
*/
if (iocb->ki_pos >> PAGE_SHIFT !=
ra->prev_pos >> PAGE_SHIFT)
mark_page_accessed(pages[0]);
for (i = 1; i < pg_nr; i++)
mark_page_accessed(pages[i]);
for (i = 0; i < pg_nr; i++) { /* 2 */
unsigned int offset = iocb->ki_pos & ~PAGE_MASK;
unsigned int bytes = min_t(loff_t, end_offset - iocb->ki_pos,
PAGE_SIZE - offset);
unsigned int copied;
/*
* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (writably_mapped)
flush_dcache_page(pages[i]);
copied = copy_page_to_iter(pages[i], offset, bytes, iter);
written += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
if (copied < bytes) {
error = -EFAULT;
break;
}
}
put_pages:
for (i = 0; i < pg_nr; i++)
put_page(pages[i]);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
file_accessed(filp);
if (pages != pages_onstack)
kfree(pages);
return written ? written : error;
}
EXPORT_SYMBOL_GPL(generic_file_buffered_read);这个函数的整体逻辑应该是: 将文件内容读取到page中, 然后再拷贝到对应的iov上
(1) 找到对应的page, 如果不存在, 则新建, 并将文件内容读取到其中
(2) 遍历相关的page, 将其内容拷贝到iov_iter中
文件预读
在读取文件内容到page 的过程中, 存在预读的过程。
预读算法预测即将访问的页面,并提前将页面批量读入内存缓存。
这段逻辑可以参考https://mp.weixin.qq.com/s/8GIeK8C3bz8nbLcwmk1vcA?from=singlemessage&isappinstalled=0&scene=1&clicktime=1646449253&enterid=1646449253, 这里面说的很详细
读取磁盘内容到page
文件预读的最后一步, 是读取文件内容到page中。 这个会调用到address_space_operations的readpage 函数,在exFAT 文件系统中, 这个函数的实现为:
static const struct address_space_operations exfat_aops = {
.readpage = exfat_readpage,
.readahead = exfat_readahead,
.writepage = exfat_writepage,
.writepages = exfat_writepages,
.write_begin = exfat_write_begin,
.write_end = exfat_write_end,
.direct_IO = exfat_direct_IO,
.bmap = exfat_aop_bmap
};
static int exfat_readpage(struct file *file, struct page *page)
{
return mpage_readpage(page, exfat_get_block);
}可以看到, 这个函数会调用到, mpage_readpage
int mpage_readpage(struct page *page, get_block_t get_block)
{
struct mpage_readpage_args args = {
.page = page,
.nr_pages = 1,
.get_block = get_block,
};
args.bio = do_mpage_readpage(&args);
if (args.bio)
mpage_bio_submit(REQ_OP_READ, 0, args.bio);
return 0;
}
EXPORT_SYMBOL(mpage_readpage);最终调用到do_mpage_readpage。这个是读取文件内容到 page中的关键函数, 在理解这个函数之前, 需要先做几点说明, 否则无法理解其中的逻辑。
文件空洞
linux 中有些文件系统是允许文件空洞的。
例如一个文件只有1M , 但用户可以seek到2M的地方去写1M, 这中间的1M区域就成了空洞(hole) , 你查看文件大小, 显示的是3M, 但实际上在硬盘上只占用了2M的空间,中间1M的区域, 你读取会读到0。

fallocate、truncate 以及GNU dd的seek扩展命令都可以实现创建空洞文件的效果
fallocate -l 10G bigfile
truncate -s 10G bigfile
dd of=bigfile bs=1 seek=10G count=0bio 和buffer_head
linux 中, vfs 下发一个io 请求到block 层, 一般有两种方式, 一种是通过 bio , 一种是buffer_head。
buffer_head 代表的是一个sector(一般是512字节), 你可以将磁盘上一个sector的内容读到一个buffer_head结构体中。
一个bio代表了物理连续的多个sector, 用于请求一大段连续的空间。
do_mpage_readpage
理解了上面两点, 下面可以来解释这个函数的具体逻辑。 一般来说,一个page 是4k, 一般包含多个 sector(512B)。 如果要读取一个page, 最理想的场景是, 这个page对应的sector在磁盘上是连续的, 那么我们只需要通过下发一个长度为4k的bio下去,就可以读取到所有的内容。 但是, 很有可能一个page对应的内容在磁盘上是不连续的, 甚至可能不存在(文件空洞), 这种情况就没法通过下发一个bio去读取了, 因为文件内容是不连续的, 只能通过一个buffer_head一个sector一个sector去读。
linux 中, 如果要读取某个buffer_head, 需要指定它对应了物理磁盘上哪个sector。 流程一般如下
sector_t phys = x;
struct super_block *sb = ...
struct buffer_head *bh_result
map_bh(bh_result, sb, phys); // 设置buffer_head对应的物理sector
submit_bh(REQ_OP_READ, 0, bh_result); // 读取对应sector的内容到buffer_head中那么, 读取文件时, 怎么知道某个buffer_head对应的物理sector是哪个呢?
这个就需要用到mpage_readpage传进来的get_block的这个这个回调。
例如, 如果读文件的头4k的内容, 其在文件中的逻辑sector号分别是0,1,2....7, 那通过get_block这个回调, 就可以得到文件中第0个sector对应了物理上的那个sector。 知道了这个物理sector号, 就可以通过buffer_head或者bio 的方式去读取了。
do_mpage_readpage的整体逻辑就是, 尽量通过bio的方式去读取连续的sector, 如果不行, 就转而通过buffer_head的方式一个sector一个sector去读。 一个页面的逻辑块被映射到磁盘可能有以下几种情况(以下内容主要参考《存储技术原理分析, 敖青云》)
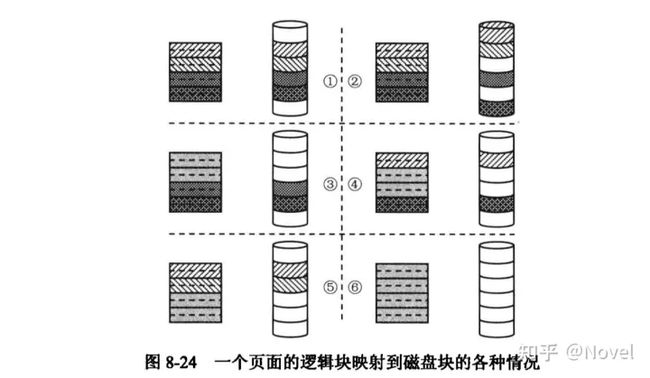
(1) 页面所有逻辑块映射到了磁盘上连续的逻辑块, 这种情况下会以bio方式提交。如果传入了bio,并和本页面在磁盘上连续, 那个尽可能合成一个bio
(2) 页面的逻辑块映射到了磁盘 上不连续的逻辑块。如果要作为bio的方式提交的话, 将不只一个请求, 会增加复杂性。所以采用buffer_head的方式处理, 如果传入了bio, 那么先将bio提交。
(3)页面的前面部分逻镇块未被映射到磁盘上 (标记为纯灰色的逻辑块)。尽管只有一个请求段,但它的起始位置不是从0开始,支持这种情况并非不可能,但代码会更复杂。所以也采用buffer_head的方式处理。如果调用时传入了一个bio,那么先把提交执行。
(4)页面的中间部分逻辑块未被映射到磁盘上,也就是说,中间部分为“空洞”。同第二种情况一样,因为有多个请求段,也只能采用缓冲页面的方式来处理。如果调用时传入了一个bio,那么先把提交执行。
(5)页面的后面部分逻强块末被映射到磁盘上,它会以bio 方式来提交。如果函数调用时传入了个bio, 并且和本页面在磁盘上连续,那么会将这个页面添加到传入的 bio 中,如果可行的话。
(6) 页面的所有逻镇块都未被映射到磁盘上,这时会跳过这个页面的处理。如果调用时传入了一个bio,则依旧将它返回,以期可以继续合并后面的页面。
理解了上面的情况, 下面就可理解do_mpage_readpage的逻辑
fs/mpage.c
static struct bio *do_mpage_readpage(struct mpage_readpage_args *args)
{
struct page *page = args->page;
struct inode *inode = page->mapping->host;
const unsigned blkbits = inode->i_blkbits;
const unsigned blocks_per_page = PAGE_SIZE >> blkbits;
const unsigned blocksize = 1 << blkbits;
struct buffer_head *map_bh = &args->map_bh;
sector_t block_in_file;
sector_t last_block;
sector_t last_block_in_file;
sector_t blocks[MAX_BUF_PER_PAGE];
unsigned page_block;
unsigned first_hole = blocks_per_page;
struct block_device *bdev = NULL;
int length;
int fully_mapped = 1;
int op_flags;
unsigned nblocks;
unsigned relative_block;
gfp_t gfp;
if (args->is_readahead) {
op_flags = REQ_RAHEAD;
gfp = readahead_gfp_mask(page->mapping);
} else {
op_flags = 0;
gfp = mapping_gfp_constraint(page->mapping, GFP_KERNEL);
}
if (page_has_buffers(page))
goto confused;
block_in_file = (sector_t)page->index << (PAGE_SHIFT - blkbits);
last_block = block_in_file + args->nr_pages * blocks_per_page;
last_block_in_file = (i_size_read(inode) + blocksize - 1) >> blkbits;
if (last_block > last_block_in_file)
last_block = last_block_in_file;
page_block = 0;
/*
* Map blocks using the result from the previous get_blocks call first.
*/
nblocks = map_bh->b_size >> blkbits;
if (buffer_mapped(map_bh) &&
block_in_file > args->first_logical_block &&
block_in_file < (args->first_logical_block + nblocks)) {
unsigned map_offset = block_in_file - args->first_logical_block;
unsigned last = nblocks - map_offset;
for (relative_block = 0; ; relative_block++) {
if (relative_block == last) {
clear_buffer_mapped(map_bh);
break;
}
if (page_block == blocks_per_page)
break;
blocks[page_block] = map_bh->b_blocknr + map_offset +
relative_block;
page_block++;
block_in_file++;
}
bdev = map_bh->b_bdev;
} /* 1 */
/*
* Then do more get_blocks calls until we are done with this page.
*/
map_bh->b_page = page;
while (page_block < blocks_per_page) {
map_bh->b_state = 0;
map_bh->b_size = 0;
if (block_in_file < last_block) {
map_bh->b_size = (last_block-block_in_file) << blkbits;
if (args->get_block(inode, block_in_file, map_bh, 0)) /* 2 */
goto confused;
args->first_logical_block = block_in_file;
}
if (!buffer_mapped(map_bh)) { /* 3 */
fully_mapped = 0;
if (first_hole == blocks_per_page)
first_hole = page_block;
page_block++;
block_in_file++;
continue;
}
/* some filesystems will copy data into the page during
* the get_block call, in which case we don't want to
* read it again. map_buffer_to_page copies the data
* we just collected from get_block into the page's buffers
* so readpage doesn't have to repeat the get_block call
*/
if (buffer_uptodate(map_bh)) { /* 4 */
map_buffer_to_page(page, map_bh, page_block);
goto confused;
}
if (first_hole != blocks_per_page) /* 5 */
goto confused; /* hole -> non-hole */
/* Contiguous blocks? */
if (page_block && blocks[page_block-1] != map_bh->b_blocknr-1) /* 6 */
goto confused;
nblocks = map_bh->b_size >> blkbits;
for (relative_block = 0; ; relative_block++) { /* 7 */
if (relative_block == nblocks) {
clear_buffer_mapped(map_bh);
break;
} else if (page_block == blocks_per_page)
break;
blocks[page_block] = map_bh->b_blocknr+relative_block;
page_block++;
block_in_file++;
}
bdev = map_bh->b_bdev;
}
if (first_hole != blocks_per_page) { /* 8 */
zero_user_segment(page, first_hole << blkbits, PAGE_SIZE);
if (first_hole == 0) {
SetPageUptodate(page);
unlock_page(page);
goto out;
}
} else if (fully_mapped) {
SetPageMappedToDisk(page);
}
if (fully_mapped && blocks_per_page == 1 && !PageUptodate(page) &&
cleancache_get_page(page) == 0) {
SetPageUptodate(page);
goto confused;
}
/*
* This page will go to BIO. Do we need to send this BIO off first?
*/
if (args->bio && (args->last_block_in_bio != blocks[0] - 1)) /* 9 */
args->bio = mpage_bio_submit(REQ_OP_READ, op_flags, args->bio);
alloc_new:
if (args->bio == NULL) { /* 10 */
if (first_hole == blocks_per_page) {
if (!bdev_read_page(bdev, blocks[0] << (blkbits - 9),
page))
goto out;
}
args->bio = mpage_alloc(bdev, blocks[0] << (blkbits - 9),
min_t(int, args->nr_pages,
BIO_MAX_PAGES),
gfp);
if (args->bio == NULL)
goto confused;
}
length = first_hole << blkbits;
if (bio_add_page(args->bio, page, length, 0) < length) { /* 11 */
args->bio = mpage_bio_submit(REQ_OP_READ, op_flags, args->bio);
goto alloc_new;
}
relative_block = block_in_file - args->first_logical_block;
nblocks = map_bh->b_size >> blkbits;
if ((buffer_boundary(map_bh) && relative_block == nblocks) ||
(first_hole != blocks_per_page))
args->bio = mpage_bio_submit(REQ_OP_READ, op_flags, args->bio);
else
args->last_block_in_bio = blocks[blocks_per_page - 1];
out:
return args->bio;
confused: /* 12 */
if (args->bio)
args->bio = mpage_bio_submit(REQ_OP_READ, op_flags, args->bio);
if (!PageUptodate(page))
block_read_full_page(page, args->get_block);
else
unlock_page(page);
goto out;
}先对这个函数中涉及到的变量做一些解释:
blocks_per_page: 一个page中包含的block数(一般来说是8, 因为一个page是4k, 一个block是512B)
blocksize: 一个block大小, 一般是512B
block_in_file: 文件中的逻辑sector号
blocks: 映射数组, 每个元素表示这个页面给定的逻辑sector对应的物理sector
page_block: page 中第几个sector
first_hole: 第一个文件空洞的位置(如果有空洞的话)
在这个函数调用之前, 可能已经有了其他page的bio(args->bio), 可以和即将创建的bio合成一个更大的bio下发。
(1) 这段if逻辑处理调用这个函数之前, 对应page的内容已经被部分map的情况。 对于这种情况,把对应部门的内容记录来。赋值给blocks[page_block] (2) 接来下处理page中剩余的部分。调用get_block 映射block_in_file对应的文件sector, 结果存在map_bh中。 (3) 如果没有被映射, 说明对应的sector是一个文件洞。 这种情况下, 用first_hole 记录当前的位置, 然后继续循环。
(4)某些文件系统会在 get block 函数进行映射时复制数据到页面中,这就没必要再次从磁盘读取了。调用map_buffer_to_page复制我们收集的数据到页面缓冲区中,然后跳转到标号 confused 处继续执行,这样readpage 不需要重复调用 get block。
(5) 程序继续运行,那一定是缓冲头己经有映射的情况。如果这时 first hole 已经设置,说明这个页面在经过空洞后又重新被映射,没有办法用bio 方式来提交,跳转到 confused 标号处。
(6)如果这个逻镇块不是页面的第一个,判断它是否和前一个逻辑块在磁盘上也是连续的。如果不是,也没有办法用bio 方式来提交,跳转到 confused 标号处
(7) 根据缓冲头的映射信息,记录页面每个逻辑块在磁盘上对应的块编号。如果映射信息用光,清除缓冲头的 mapped 标志,退出循环;如果这个页面的所有sector都己经处理完,也退出循环,如果此时映射信息可能还没有用光,则留给下一个页面。
(8) 页面的所有逻辑块都经过上面的处理后,可以采用 bio 方式提交的情况就清楚了。只可能会是三种情况。页面的逻辑块被映射到磁盘上连续的逻辑块,这时设置页面的映射标志;页面只有前面一些逻辑块被映射到磁盘,这时清零没有被映射部分的数据:控个页面都没有被映射,清除整个页面,并设置最新标志。
(9) 如果传入了一个bio, 需要判断本页面第一个逻街块和传入bio 的最后一个逻辑块在磁盘上是否连续,也就是看是否可以将本页面作为一个请求段加入传入的 bio 中。如果不连续,那么mpage_bio_submit提交前面的bio, 这个函数恒返回 NULL
(10) 如果传入的bio 为 NULL, 或者传入的bio 已提交,那么,我们需要调用 mpage_alloc 重新分配一个bio。
(11) 设置该bio的参数, 并将该bio返回
(12) 对于无法用bio处理的情况, 先将已有的bio提交, 然后调用block_read_full_page 通过buffer_head的方式进行读取
从文件块编号推导物理块编号
下面以exFAT文件系统为例, 讲解一下get_block这个函数的具体实现。
fs/exfat/inode.c
static int exfat_get_block(struct inode *inode, sector_t iblock,
struct buffer_head *bh_result, int create)
{
struct exfat_inode_info *ei = EXFAT_I(inode);
struct super_block *sb = inode->i_sb;
struct exfat_sb_info *sbi = EXFAT_SB(sb);
unsigned long max_blocks = bh_result->b_size >> inode->i_blkbits;
int err = 0;
unsigned long mapped_blocks = 0;
unsigned int cluster, sec_offset;
sector_t last_block;
sector_t phys = 0;
loff_t pos;
mutex_lock(&sbi->s_lock);
last_block = EXFAT_B_TO_BLK_ROUND_UP(i_size_read(inode), sb);
if (iblock >= last_block && !create)
goto done;
/* Is this block already allocated? */
err = exfat_map_cluster(inode, iblock >> sbi->sect_per_clus_bits, /* 1 */
&cluster, create);
if (err) {
if (err != -ENOSPC)
exfat_fs_error_ratelimit(sb,
"failed to bmap (inode : %p iblock : %llu, err : %d)",
inode, (unsigned long long)iblock, err);
goto unlock_ret;
}
if (cluster == EXFAT_EOF_CLUSTER)
goto done;
/* sector offset in cluster */
sec_offset = iblock & (sbi->sect_per_clus - 1);
phys = exfat_cluster_to_sector(sbi, cluster) + sec_offset;
mapped_blocks = sbi->sect_per_clus - sec_offset;
max_blocks = min(mapped_blocks, max_blocks);
/* Treat newly added block / cluster */
if (iblock < last_block)
create = 0;
if (create || buffer_delay(bh_result)) {
pos = EXFAT_BLK_TO_B((iblock + 1), sb);
if (ei->i_size_ondisk < pos)
ei->i_size_ondisk = pos;
}
if (create) {
err = exfat_map_new_buffer(ei, bh_result, pos);
if (err) {
exfat_fs_error(sb,
"requested for bmap out of range(pos : (%llu) > i_size_aligned(%llu)\n",
pos, ei->i_size_aligned);
goto unlock_ret;
}
}
if (buffer_delay(bh_result))
clear_buffer_delay(bh_result);
map_bh(bh_result, sb, phys); /* 2 */
done:
bh_result->b_size = EXFAT_BLK_TO_B(max_blocks, sb);
unlock_ret:
mutex_unlock(&sbi->s_lock);
return err;
}get_block 这个函数用于查找inode对应的文件中第iblock位置的sector在物理上对应那个sector, 并将结果保存在bh_result, create表示如果没有找到对应的sector, 是否进行创建。
(1) 调用exfat_map_cluster 去查找某个文件中的iblock 对应的实际的cluster。 这里面就涉及到文件系统的具体操作。
(2) 将bh_result映射到phys对应的位置