跨模态行人重识别:Discover Cross-Modality Nuances for Visible-Infrared Person Re-Identification学习记录笔记
目录
摘要
网络结构
具体方法
MAM
PAM
模态分类损失
共享特征ID损失
中心簇损失
总损失
试验
注意模式
可视化分布
结果
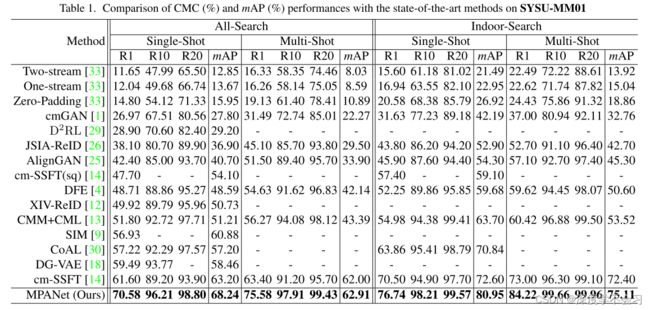
原文链接:Discover Cross-Modality Nuances for Visible-Infrared Person Re-Identification
摘要
提出了一种联合模态和模式对齐网络 (MPANet) 来发现可见红外人 Re-ID 不同模式中的跨模态细微差别,它引入了模态缓解模块和模式对齐模块来共同提取判别特征。模态缓解模块以从提取的特征图中去除模态信息。 然后设计了一个模式对齐模块,它为一个人的不同模式生成多个模式图,以发现细微差别。 最后引入了一种相互均值学习方式来缓解模态差异,并提出了一个中心聚类损失来指导身份学习和细微差别发现。
贡献:
为了发现细微差别并提取判别性特征,提出了模式对齐模块 (PAM),以无监督方式发现不同模式中的细微差别,并提出中心簇损失和分离损失。
为了在保留身份信息的同时减轻模态差异,提出了模态缓解模块(MAM),它在相互均值学习方式的指导下选择性地应用实例归一化。
网络结构
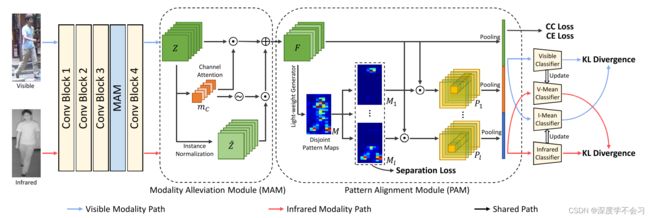
联合模态和模式对齐网络 (MPANet) 的框架。模态缓解模块 (MAM) 从前块接收特征图,以提取与模态无关的特征图。
模式对齐模块 (PAM) 生成模式图,以发现不同模式中的细微差别。提出了分离损失,以确保模式图集中在不同的模式上。然后,提出的中心聚类损失指示每个模式图集中于某个模式,并通过交叉熵损失共同指导身份学习。为了指导网络缓解模态差异,以相互均值学习的方式将两个特定于模态的分类器与两个相应的均值分类器一起应用。
所提出的MPANet框架包括两个用于缓解模态差异的模态缓解模块 (MAM),一个用于发现不同模式中的细微差别的模式对齐模块 (PAM),以及一种相互均值学习方式来训练具有中心聚类损失和交叉熵损失的模型以进行身份识别。具体来说,MAM使用实例归一化来缓解模态差异,同时保持对扩展的区分性。通过轻量级生成器,图案对齐模块生成一组图案图,这些图案图参加不同的图案以发现细微差别。该模块的输出是通过将模式特征和全局特征连接在一起获得的。为了以无监督的方式发现细微差别,设计了一个区域分离约束,以确保每个模式映射都属于不同的模式。然后提出了中心簇丢失,以减少相同身份的某些模式特征之间的距离,同时增加不同身份的特征中心之间的距离。我们进一步应用两个特定于模态的分类器来从每个模态中学习特征的身份,并预测相同特征的分类结果。此外,通过以相互平均学习的方式减少由不同模态特定分类器生成的同一图像的预测之间的分布差异,可以缓解模态差异。最后,对这两个模块进行级联和端到端的联合优化。通过上述工作,MPANet提取的特征是模态不变的,可以表示不同模式中的细微差别。
具体方法
MPANet采用预先训练的单流CNN从可见光和红外模态中提取特征图。由卷积块3和4提取的特征图分别被馈送到模态缓解模块 (MAM) 中,该模块细化特征图以缓解模态差异,同时保留特征图的身份识别能力。
为了学习细微差别和区别特征,模式对齐模块 (PAM) 生成模式图,旨在识别人的不同模式中的细微差别。这两个模块通过相互的平均学习方式级联并联合优化,以学习不相关的模态特征,同时,通过交叉熵和中心聚类损失来监督,以学习可见光-红外人的身份识别特征。
MAM
输入图像 x,我们将其卷积块提取的特征图 Z ∈ Rh×w×c 表示为 MAM 的输入,为了减轻模态差异,应用了实例归一化(IN),减少实例之间的差异,但是直接应用 IN 可能会损坏识别信息,从而对 Re-ID 任务产生不利影响。 为了克服这些缺点,应用通道注意力引导的 IN 来减轻模态差异,同时保留身份信息:
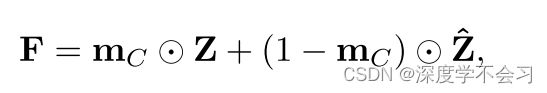
![]() 是指示与身份相关的信道掩码:
是指示与身份相关的信道掩码:
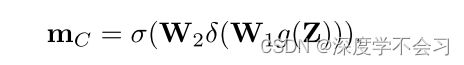
其中g(·) 表示全局平均池化,W1和W2为两个两个无偏置全连接层的可学习参数,其后是relu激活函数 δ(·) 和sigmod激活函数 σ(·)。
![]() 表示实例化后的值:
表示实例化后的值:
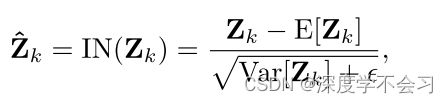
其中 Zk ∈ Rh×w 是特征图 Z 的第 k 维,ε 用于避免被零除,均值 E[·] 和标准差 Var[·] 是按维度计算的。
PAM
发现跨身份的不同模式中的细微差别,将特征图分成l个模式,模式图M = [M1,M2,...,Ml] ∈ R h × w × l。
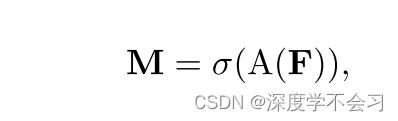
A 是内核大小为 1 的卷积, 每个模式图都应注意不同的模式,以发现其中包含的细微差别。
通过这些模式映射,我们可以将特征映射F分割为l个模式,如下所示:
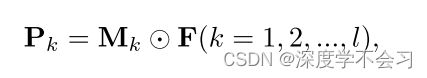
⊙ 表示逐元素乘法。根据模式图将特征图拆分为l个模式,则通过全局平均池g(·) 提取第k个模式pk = g(Pk) ∈ Rc的特征。最后,PAM的输出特征f :
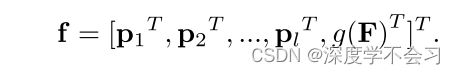
为了确保模式图可以捕获不同的模式,我们应用分离损失来强制每个图关注不同的模式。 将掩模 M(h×w×l )调整为 M(hw×l 后),分离损失定义为
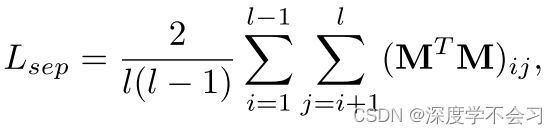
(MTM)ij是MTM在第i行和第j列上的元素。通过最小化每两个掩模之间的重叠区域,分离损失可以监督模式图以从不同的模式中学习特征。
模态分类损失
来自可见模态的特征 fv 和来自红外模态的 fr,特定于模态的分类器提供它们的预测
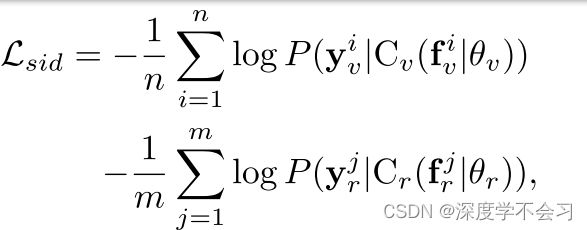
由于馈送到每个分类器的训练图像来自特定的模态,因此分类器仅从其相应的模态中学习知识。因此,给定特征f,无论它来自哪个模态,如果两个模态特定的分类器提供相同的预测,模式差异被消除了。
基于KL散度的模态约束
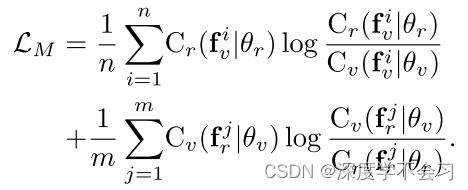
这个损失表示无论它来自什么模态,鼓励特定于模态的分类器为同一性特征提供一致的预测。 但是这直接将使两个分类器的预测迅速变得相似,因为分类器从具有等式的另一种模态中学习知识,而不是学习与情态无关的特征。
为了解决上述问题,提出了两个与模态特定分类器具有相同网络结构的均值分类器,用于预测来自另一模态的样本。
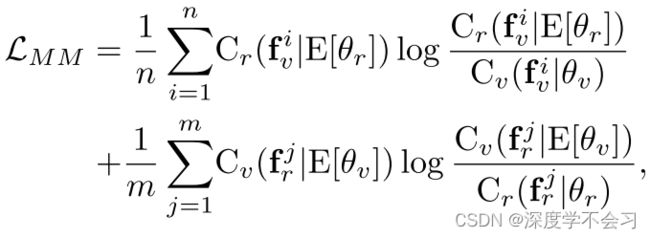
E[θ v] 和E[θ r] 分别表示两个均值分类器的参数。这些参数以时间平均方式更新。因此,在第t次迭代时,参数E(t)[θ v] 和E(t)[θ r]
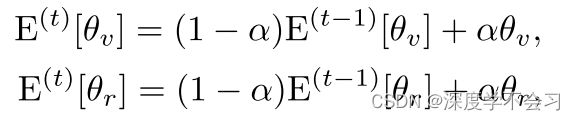
共享特征ID损失
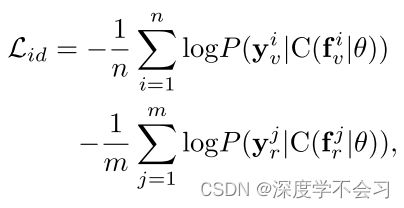
中心簇损失
中心簇损失旨在将特征收集到它们的中心。 此外,从某个身份内模式中提取的模式特征会相互接近。 在这个过程中,模型以无监督的方式学习细微差别信息。 同时,损失直接建立类之间而不是样本之间的关系,将身份学习建立在类级别上,避免在推开不同身份样本的同时增加模态差异。
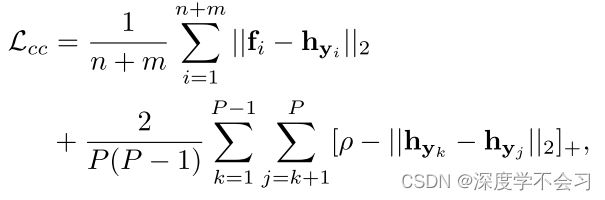
![]() 是当前批次中带有标签yi的特征的平均值,P是当前批次中的身份数,ρ 是中心之间的最小余。
是当前批次中带有标签yi的特征的平均值,P是当前批次中的身份数,ρ 是中心之间的最小余。
总损失

试验
注意模式

图说明了两个身份的三个行人图像的个人注意模式,其中第k列是Mk ⊙ F的可视化结果。我们可以观察到,PAM生成的每个模式图都集中在某种不同于其他模式的模式上,而没有模态和姿势的影响。可视化显示了细微差别在此任务中的重要性,并且PAM在其上运行良好。
可视化分布

圆形和三角形表示从可见光和红外光中提取的特征。(a)由在图像集上预先训练的基线提取的特征; (b)由基线提取的特征; (c)由 mpanet 提取的特征。结果表明,mpanet 能较好地缓解语气差异,提高区分能力.
结果