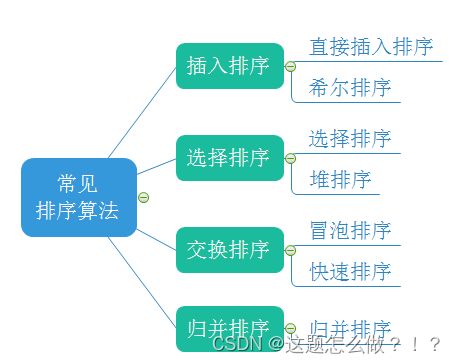
排序算法大全:冒泡排序【含优化】,选择排序【含优化】,直接插入排序,希尔排序,堆排序,快速排序【含3种实现版本及非递归实现】,归并排序【含非递归实现】。详细图解,文字解释,代码实现,性能分析。
目录
一、冒泡排序
1、冒泡排序思想
2、冒泡排序算法的性能分析
二、选择排序
1、选择排序思想
2、选择排序算法的性能分析
三、直接插入排序
1、直接插入排序思想
2、直接插入排序算法的性能分析
四、希尔排序
1、希尔排序思想
2、希尔排序算法的性能分析
五、堆排序
六、快速排序
1、hoare划分法
2、挖坑法
3、前后指针法
快速排序优化
快速排序的非递归实现
七、归并排序
1、归并排序递归实现
2、归并排序非递归实现
一、冒泡排序
1、冒泡排序思想
冒泡排序的基本思想是通过相邻元素之间的比较和交换来逐步将最大(或最小)的元素移到右边(或左边)。具体来说,冒泡排序的步骤如下:
- 从数组的第一个元素开始,依次比较相邻的两个元素。如果前面的元素大于后面的元素,则交换它们的位置,以使较大的元素向右移动。
- 继续向数组的下一个相邻元素进行比较和交换,直到最后一个元素,此时最大的元素已经移到了数组的最右侧。
- 重复以上步骤,但这次只需要比较和交换前 n-1 个元素,因为最大的元素已经在正确的位置上。
- 重复进行 n-1 轮比较和交换,直到所有元素都按照从小到大(或从大到小)的顺序排列。
2、冒泡排序算法的性能分析
- 最好的情况下,当输入数组已经是有序的,冒泡排序只需进行一轮比较,时间复杂度为 O(n)。
- 最坏的情况下,当输入数组是逆序的,冒泡排序需要进行 n-1 轮比较和交换,时间复杂度为 O(n^2)。
- 平均情况下,冒泡排序的时间复杂度为 O(n^2)。
- 冒泡排序是一种稳定排序算法,不会改变相等元素的相对顺序。
- 冒泡排序是一种原地排序算法,不需要额外的空间。
1、普通版本:
// 定义一个交换函数,用于交换两个整数的值
void swap(int* a, int* b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
// 冒泡排序函数,对数组进行排序
void BubbleSort(int* a, int n)
{
int i, j;
// 外层循环控制排序的轮数
for (i = 0; i < n - 1; i++)
{
// 内层循环进行相邻元素的比较和交换
for (j = 0; j < n - i - 1; j++)
{
// 如果前一个元素大于后一个元素,则交换它们的位置
if (a[j] > a[j + 1])
{
swap(&a[j], &a[j + 1]);
}
}
}
}2、优化版本 :
思想:在优化版本的冒泡排序算法中,通过添加一个标记变量flag,可以在一轮排序过程中标记是否有进行过交换操作,如果某一轮排序中没有进行过任何交换,说明数组已经有序,可以提前结束排序。
// 定义一个交换函数,用于交换两个整数的值
void swap(int* a, int* b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
// 冒泡排序函数,对数组进行排序
void BubbleSortPro(int* a, int n)
{
int i, j, flag = 0;
// flag用于标记是否有交换发生,初始值为0
// 外层循环控制排序的轮数
for (i = 0; i < n - 1; i++)
{
flag = 0; // 在每一轮开始时,将flag重置为0
// 内层循环进行相邻元素的比较和交换
for (j = 0; j < n - i - 1; j++)
{
// 如果前一个元素大于后一个元素,则交换它们的位置,并将flag设置为1
if (a[j] > a[j + 1])
{
swap(&a[j], &a[j + 1]);
flag = 1;
}
}
// 如果在一轮排序中没有进行过任何交换,说明数组已经有序,可以提前结束排序
if (flag == 0)
{
break;
}
}
}二、选择排序
1、选择排序思想
选择排序的基本思想可以概括为以下几个步骤:
- 遍历待排序的数组,将数组中的第一个元素视为当前最小值。
- 在剩余的未排序部分中,依次查找比当前最小值更小的元素。
- 如果找到了比当前最小值更小的元素,则将其标记为新的最小值。
- 遍历完未排序部分,将新的最小值与当前最小值交换位置。
- 如此循环,直到所有元素都被排序。
通过每次从剩余未排序部分选择最小的元素,并将其放在已排序部分的末尾,逐步构建有序序列。
2、选择排序算法的性能分析
- 选择排序的时间复杂度为O(n^2),其中n是待排序数组的元素个数。这是因为在每一轮遍历中,需要比较剩余未排序部分的所有元素,最坏情况下要进行n-1次比较。总共需要进行n-1轮遍历,因此时间复杂度为O(n^2)。
- 选择排序是一种不稳定的排序算法。当待排序数组中存在相同元素时,选择排序可能会改变相同元素的相对顺序。具体来说,在选择过程中,如果当前的最小元素与其他相同元素交换位置,可能会改变它们的相对顺序。
- 选择排序是一种原地排序算法,即排序过程中不需要额外的空间。它只需要一个额外的变量来记录最小(或最大)元素的位置,通过交换元素位置来实现排序,所以空间复杂度为O(1)。
综上所述,选择排序的时间复杂度为O(n^2),空间复杂度为O(1),并且是一种不稳定的排序算法。

1、普通版本:
void swap(int* a,int* b)
{
int temp;
temp=*a;
*a=*b;
*b=temp;
}
void SelctSort(int* a, int n)
{
int i, j, key;
// 遍历数组,i表示已排序部分的末尾元素的索引
for (i = 0; i < n - 1; i++)
{
key = i; // 将当前位置视为最小值的索引
// 在未排序部分中查找最小值
for (j = i + 1; j < n; j++)
{
if (a[key] > a[j])
{
key = j; // 更新最小值的索引
}
}
// 如果最小值不是当前位置的元素,则交换位置
if (key != i)
{
swap(&a[i], &a[key]);
}
}
}2、优化版本
优化版本的思想是在选择排序的基础上,同时追踪并找出未排序部分的最大值和最小值,并将它们分别放置在已排序部分的末尾和开头。通过这种方式,可以减少交换的次数,从而提高排序的效率。
void swap(int* a,int* b)
{
int temp;
temp=*a;
*a=*b;
*b=temp;
}
void SelctSortPro(int* a, int n)
{
int i, j;
int begin = 0, end = n - 1;
int maxi = end, mini = begin;
// 在每一次循环中,将未排序部分的最大值和最小值分别放置在已排序部分的末尾和开头
while (begin < end)
{
i = begin;
j = end;
maxi = end;
mini = begin;
// 在未排序部分中查找最大值和最小值
while (i <= end)
{
if (a[maxi] < a[i])
{
maxi = i; // 更新最大值的索引
}
if (a[mini] > a[i])
{
mini = i; // 更新最小值的索引
}
i++;
}
// 将最小值放置在已排序部分的开头
swap(&a[begin], &a[mini]);
// 如果最大值所在位置等于begin,更新最大值所在位置为mini
if (maxi == begin)
{
maxi = mini;
}
// 将最大值放置在已排序部分的末尾
swap(&a[end], &a[maxi]);
// 更新已排序部分和未排序部分的起始和结束位置
begin++;
end--;
}
}三、直接插入排序
1、直接插入排序思想
直接插入排序是一种简单直观的排序算法,其思想是通过构建已排序部分和未排序部分,将待排序元素按照大小逐个插入到已排序部分的正确位置中,完成排序。
具体步骤如下:
- 将待排序序列的第一个元素看作已排序部分。
- 从待排序序列中依次取出元素,从已排序部分的末尾开始,向前比较。
- 如果当前取出的元素大于已排序部分的某个元素,则将该元素插入到该位置后面,即将该位置以及其后面的元素都向后移动一位。
- 如果当前取出的元素小于或等于已排序部分的某个元素,则将该元素插入到该位置前面的位置。
- 重复步骤2-4,直到待排序部分中的所有元素都被插入到已排序部分中
2、直接插入排序算法的性能分析
时空复杂度:
- 时间复杂度:直接插入排序的平均时间复杂度为O(n^2),最好情况下的时间复杂度为O(n),最坏情况下的时间复杂度为O(n^2)。
- 空间复杂度:直接插入排序的空间复杂度为O(1),它是一种原地排序算法,不需要额外的空间。
稳定性:
直接插入排序是稳定的,即相等元素的相对次序在排序前后保持不变。当比较相等元素时,由于只有当前元素小于等于已排序部分的某个元素时才插入,因此相等元素的相对次序不会发生改变。
需要注意的是,尽管直接插入排序在最坏情况下的时间复杂度较高,但对于小规模或基本有序的序列,直接插入排序的性能较为优秀。

void InsertSort(int* a, int n)
{
int i, j, temp;
for (i = 0; i < n - 1; i++)
{
temp = a[i + 1]; // 将当前待插入的元素暂存到变量temp中
j = i; // j用于记录已排序部分的最后一个元素的索引
while (j >= 0)
{
if (temp < a[j])
{
a[j + 1] = a[j]; // 如果temp比已排序部分的元素小,将该元素后移一位
}
else
{
break; // 如果temp不小于已排序部分的元素,跳出循环
}
j--; // 继续向前比较
}
a[j + 1] = temp; // 将暂存的元素插入到正确位置
}
}四、希尔排序
1、希尔排序思想
希尔排序是基于插入排序的一种改进算法,也称为缩小增量排序。它通过将待排序序列按照一定间隔分成多个子序列,并对每个子序列进行插入排序的方式来逐步减小间隔,最终使整个序列有序。
具体步骤如下:
- 选择一个增量序列,通常是除以2逐步缩小得到的序列。
- 根据增量序列将待排序序列分成多个子序列。
- 对每个子序列进行插入排序,即将子序列中的元素按照插入排序的方式进行排序。
- 逐步缩小增量,重复步骤2和步骤3,直到增量为1。
- 最后进行一次增量为1的插入排序,完成整个序列的排序。
希尔排序的思想是利用了插入排序对基本有序的序列性能较好的特点,通过提前部分排序减少了逆序对的数量,从而提高了排序效率。
2、希尔排序算法的性能分析
时空复杂度:
- 时间复杂度:希尔排序的时间复杂度与增量序列的选择有关,平均时间复杂度为O(nlogn),最好情况下的时间复杂度为O(nlog^2n),最坏情况下的时间复杂度为O(n^2)。
- 空间复杂度:希尔排序的空间复杂度为O(1),它是一种原地排序算法,不需要额外的空间。
稳定性:
希尔排序是不稳定的,因为在每个子序列中进行插入排序时,相等元素的相对次序可能会发生改变。

void ShellSort(int* a, int n)
{
int gap = n; // 设置初始的增量gap为序列长度
int temp, i, j;
while (gap > 1)
{
gap = gap / 2; // 缩小增量
for (i = 0; i < n - gap; i++)
{
temp = a[i + gap]; // 将当前待插入的元素暂存到变量temp中
j = i;
while (j >= 0)
{
if (temp < a[j])
{
a[j + gap] = a[j]; // 如果temp比已排序部分的元素小,将该元素后移gap位
j -= gap; // 向前移动gap位
}
else
{
break; // 如果temp不小于已排序部分的元素,跳出循环
}
}
a[j + gap] = temp; // 将暂存的元素插入到正确位置
}
}
}五、堆排序
堆排序是一种基于二叉堆(heap)数据结构的排序算法。它的思想可以概括为以下几个步骤:
-
构建堆:将待排序的数组视为一个完全二叉树,并将其转化为一个堆。这可通过从最后一个非叶子节点开始,逐个向上调整每个节点来完成。调整操作会使得当前节点和其子树满足堆的性质,即父节点的值大于等于(或小于等于)其子节点的值。这样就构建了一个最大堆(或最小堆)。
-
排序:经过构建堆操作后,堆顶元素是最大(或最小)的元素。我们可以将堆顶元素与堆中最后一个元素交换位置,然后将堆的大小减小 1。这样,最大(或最小)的元素会被放置到正确的位置(即最后一个位置)。接着,我们对堆顶元素进行向下调整,使得堆再次满足堆的性质。重复以上步骤,直到堆中只剩下一个元素。
-
返回有序序列:当堆中只剩下一个元素时,所有的元素都已经交换并放置到了正确的位置。此时,我们就得到了一个有序的序列。
堆排序的时间复杂度为 O(nlogn),其中 n 是数组的大小。它是一种原址排序算法,因为它只需要用到原始数组,不需要使用额外的空间。同时,堆排序也是一种稳定的排序算法。

代码及注释:
void AdjustDown(int* a, int parent, int n)
{
// 计算左子节点的索引
int child = parent * 2 + 1;
// 当左子节点在数组范围内时进行循环
while (child < n)
{
// 如果右子节点存在且比左子节点大,则选择右子节点作为与父节点进行比较的子节点
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
// 如果父节点小于子节点,则交换它们的值
if (a[parent] < a[child])
{
swap(&a[parent], &a[child]);
// 更新父节点和子节点的索引
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
// 从最后一个非叶子节点开始,依次调用 AdjustDown 函数,构建最大堆
int i = 0;
int end = n / 2 - 1;
for (i = end; i >= 0; i--)
{
AdjustDown(a, i, n);
}
// 交换堆顶元素与最后一个元素,并向下调整堆
for (i = 0; i < n; i++)
{
swap(&a[0], &a[n - i - 1]);
AdjustDown(a, 0, n - i - 1);
}
}六、快速排序
快速排序使用分治的思想来进行排序,其基本过程如下:
- 从待排序数组中选择一个元素作为枢轴(pivot)。
- 将数组分割成两个子数组,使得左侧子数组的元素都小于等于枢轴,右侧子数组的元素都大于等于枢轴。这个分割的过程称为划分(partition)。
- 对左右子数组分别递归地进行快速排序。
- 递归结束的条件是子数组只有一个元素或者为空。
时空复杂度:
- 平均时间复杂度:O(nlogn)
- 当数组有序时,最坏时间复杂度:O(n^2)
- 空间复杂度:O(logn)
1、hoare划分法

void QuickSortHoare(int* a, int begin, int end)
{
// begin为首元素下标,end为尾元素下标
if (begin >= end)
{
return; // 递归结束条件:子数组只有一个元素或为空,不需要排序
}
int left = begin; // 左指针
int right = end; // 右指针
int key = begin; // 选择第一个元素作为基准元素
while (left < right)
{
// 从右侧开始,找到第一个比基准元素小的元素
while (a[right] >= a[key] && right > left)
{
right--;
}
// 从左侧开始,找到第一个比基准元素大的元素
while (a[left] <= a[key] && right > left)
{
left++;
}
// 如果左指针小于右指针,交换左右指针对应的元素
if (left < right)
{
swap(&a[left], &a[right]);
}
}
// 将基准元素放到正确的位置上
swap(&a[key], &a[left]);
// 对基准元素左侧和右侧的子数组进行递归调用
QuickSortHoare(a, begin, left - 1);
QuickSortHoare(a, left + 1, end);
}
2、挖坑法
挖坑法是一种简洁的快速排序实现方式,它通过交替移动两个指针,将元素一个个填入坑位的方式来进行划分。与Hoare划分法相比,挖坑法在划分的过程中不需要频繁地交换元素,因此实现上会更为简单。
void QuickSortLomuto(int* a, int begin, int end)
{
if (begin >= end)
{
return; // 递归结束条件:子数组只有一个元素或为空,不需要排序
}
int curi = begin; // 当前坑位的索引
int temp = a[begin]; // 枢轴元素的值
int left = begin; // 左指针
int right = end; // 右指针
while (left < right)
{
// 从右侧开始,找到第一个比枢轴小的元素的索引
while (a[right] >= temp && left < right)
{
right--;
}
a[curi] = a[right]; // 将右指针指向的元素填入当前坑位
curi = right; // 更新当前坑位的索引
// 从左侧开始,找到第一个比枢轴大的元素的索引
while (a[left] <= temp && left < right)
{
left++;
}
a[curi] = a[left]; // 将左指针指向的元素填入当前坑位
curi = left; // 更新当前坑位的索引
}
a[curi] = temp; // 将枢轴元素填入最后一个坑位,确保枢轴元素的位置被确定
// 对枢轴左侧和右侧的子数组进行递归调用
QuickSortLomuto(a, begin, left - 1);
QuickSortLomuto(a, left + 1, end);
}3、前后指针法
void QuickSortPB(int* a, int begin, int end)
{
if(begin > end)
{
return; // 递归结束条件:子数组为空,不需要排序
}
int prev = begin; // prev指针指向枢轴元素的位置
int cur = prev + 1; // cur指针指向待比较元素的位置
int key = begin; // 枢轴元素的位置
// 遍历数组,将小于等于枢轴元素的元素放在prev指针的后面
while(cur <= end)
{
if(a[cur] <= a[key])
{
prev++;
if(cur != prev)
{
swap(&a[prev], &a[cur]); // 交换prev指针和cur指针指向的元素
}
}
cur++;
}
swap(&a[begin], &a[prev]); // 将枢轴元素放到prev指针的位置
// 对枢轴左侧和右侧的子数组进行递归调用
QuickSortPB(a, begin, prev-1);
QuickSortPB(a, prev+1, end);
}快速排序优化
"三数取中"的方法是从待排序数组中随机选择三个元素,然后取这三个元素的中间值作为枢轴元素。具体步骤如下:
- 选择开始位置
begin、结束位置end和中间位置mid,计算mid = (begin + end) / 2。 - 比较
a[begin]、a[mid]和a[end]的大小,确定其中的中间值。 - 将选出的中间值与
a[begin]进行交换,将中间值放在数组开始的位置,作为枢轴元素。 - 进行正常的快速排序算法。
通过使用"三数取中"的方法选择枢轴元素,可以尽量避免了最坏情况的发生。最坏的情况是枢轴元素选择的不好,导致每次划分只将数组分成一个很小的部分和一个很大的部分,使得快速排序的时间复杂度退化为O(n^2)。而"三数取中"的方法通过选择一个近似于中位数的元素作为枢轴,能够更平衡地划分数组,减少这种最坏情况的发生,从而提高快速排序的效率。
int GetMidi(int* a, int begin, int end)
{
int midi = (begin + end) / 2; // 计算中间位置
// begin midi end 三个数选中位数
if (a[begin] < a[midi]) // 如果begin位置的值小于midi位置的值
{
if (a[midi] < a[end]) // 如果midi位置的值小于end位置的值
return midi; // 返回midi位置
else if (a[begin] > a[end]) // 如果begin位置的值大于end位置的值
return begin; // 返回begin位置
else
return end; // 返回end位置
}
else
{
if (a[midi] > a[end]) // 如果midi位置的值大于end位置的值
return midi; // 返回midi位置
else if (a[begin] < a[end]) // 如果begin位置的值小于end位置的值
return begin; // 返回begin位置
else
return end; // 返回end位置
}
}
int QuickSortHoare(int* a, int begin, int end)
{
int midi = GetMidi(a, begin, end); // 找到中间位置的索引
Swap(&a[midi], &a[begin]); // 交换中间位置的值和起始位置的值
int left = begin, right = end; // 设置左右指针
int keyi = begin; // 设置基准值索引
while (left < right)
{
// 右边找小
while (left < right && a[right] >= a[keyi]) // 从右边开始找小于基准值的数
{
--right;
}
// 左边找大
while (left < right && a[left] <= a[keyi]) // 从左边开始找大于基准值的数
{
++left;
}
Swap(&a[left], &a[right]); // 交换左右指针所指位置的值
}
Swap(&a[left], &a[keyi]); // 将基准值放到中间位置
return left; // 返回中间位置的索引
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return; // 如果起始位置大于等于终止位置,则返回
int keyi = QuickSortHoare(a, begin, end); // 使用快速排序的Hoare分区函数找到基准值的索引
QuickSort(a, begin, keyi - 1); // 对基准值左边的数组进行快速排序
QuickSort(a, keyi+1, end); // 对基准值右边的数组进行快速排序
}快速排序的非递归实现
快速排序的非递归实现使用了栈来模拟递归的过程,这样可以避免使用系统栈导致的递归调用过深的问题。
非递归实现的思想如下:
-
创建一个栈,用于存储待处理子数组的边界。初始时,将整个数组的开始位置和结束位置入栈。
-
进行循环,直到栈为空。循环的目的是处理栈中的每个子数组。
-
弹出栈顶的子数组边界,得到开始位置和结束位置。
-
在子数组中选择枢轴元素,并使用 Hoare 划分方式将子数组划分成两个部分。将划分点的下标入栈,保证后续对其进行排序。
-
根据划分点的下标更新子数组边界,将左侧子数组的开始位置和结束位置入栈,再将右侧子数组的开始位置和结束位置入栈。注意保证先处理左侧子数组,再处理右侧子数组。
-
重复步骤 3 到步骤 5,直到栈为空,即所有子数组都被处理完毕。
通过上述步骤,可以将递归的快速排序算法转化为非递归的实现。该实现使用栈来保存待处理的子数组边界,以模拟递归过程。每次处理子数组时,选择一个枢轴元素进行划分,并将划分点的下标入栈。然后根据划分点将子数组分成两部分,分别将左侧和右侧的子数组边界入栈。这样可以确保先处理左侧子数组,再处理右侧子数组,达到快速排序的效果。
typedef int StackDataType;
typedef struct StackNode
{
StackDataType data;
struct StackNode* next;
}StackNode;
typedef struct Stack
{
StackNode* q;
int size;
}Stack;
void StackInit(Stack* s)
{
StackNode* head=(StackNode*)malloc(sizeof(StackNode));
head->next=NULL;
s->q=head;
s->size=0;
}
void StackPush(Stack* s,StackDataType x)
{
StackNode* newnode=(StackNode*)malloc(sizeof(StackNode));
newnode->data=x;
newnode->next=s->q->next;
s->q->next=newnode;
s->size++;
}
int StackEmpty(Stack* s)
{
if(s->q->next==NULL)
{
return 1;
}
return 0;
}
StackDataType StackTop(Stack* s)
{
if(!StackEmpty(s))
{
return s->q->next->data;
}
else
{
return -1;
}
}
void StackPop(Stack* s)
{
if(!StackEmpty(s))
{
StackNode* temp=s->q->next;
s->q->next=s->q->next->next;
free(temp);
s->size--;
}
}
int get_keyi(int *a, int begin, int end)
{
int left = begin;
int right = end;
int key = begin;
while (left < right)
{
// 从右侧开始,找到第一个小于 key 的元素
while (a[right] >= a[key] && left < right)
{
right--;
}
// 从左侧开始,找到第一个大于 key 的元素
while (a[left] <= a[key] && left < right)
{
left++;
}
// 交换找到的两个元素
swap(&a[right], &a[left]);
}
// 将基准值放到中间位置
swap(&a[key], &a[left]);
return left; // 返回中间位置的索引
}
void QuickSortNR(int* a, int begin, int end)
{
Stack s;
StackInit(&s);
// 入栈起始和结束位置
StackPush(&s, end);
StackPush(&s, begin);
int left, mid, right;
// 当栈不为空时,循环执行
while (!StackEmpty(&s))
{
left = StackTop(&s);
StackPop(&s);
right = StackTop(&s);
StackPop(&s);
// 如果左边界小于右边界,进行划分
if (left < right)
{
mid = get_keyi(a, left, right);
}
// 将左边未排序的部分入栈
if (left < mid - 1)
{
StackPush(&s, mid - 1);
StackPush(&s, left);
}
// 将右边未排序的部分入栈
if (right > mid + 1)
{
StackPush(&s, right);
StackPush(&s, mid + 1);
}
}
}七、归并排序
1、归并排序递归实现
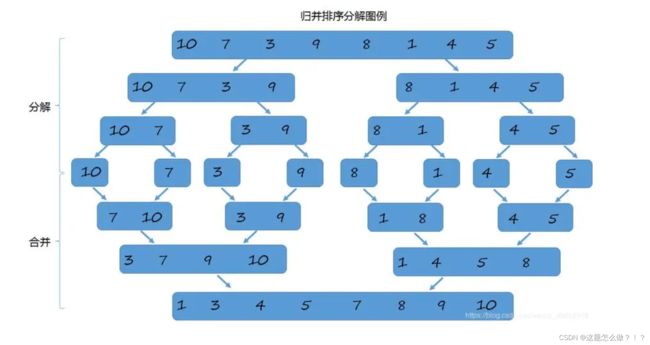
归并排序是一种经典的排序算法,它使用了分治法的思想。下面是归并排序的算法思想:
- 递归地将数组划分成较小的子数组,直到每个子数组的长度为1或者0。
- 将相邻的子数组合并,形成更大的已排序的数组,直到最终得到一个完全排序的数组。
归并排序的过程可以分为三个步骤:拆分(Divide)、合并(Merge)和排序(Sort)。
- 拆分:将待排序的数组不断地划分为两个子数组,直到每个子数组的长度为1或者0。
- 合并:将相邻的子数组合并为一个较大的已排序数组,通过比较两个子数组的首元素,按照从小到大的顺序逐个将元素放入一个辅助数组。
- 排序:重复进行合并的过程,直到最终得到完全排序的数组。
归并排序的时间复杂度为O(nlogn),其中n是待排序数组的长度。空间复杂度为O(n),主要是由于需要使用一个大小与原始数组相同的辅助数组来存储合并的结果。
归并排序是一种稳定的排序算法,即相等元素的相对顺序在排序前后保持不变。在合并的过程中,如果遇到两个相等的元素,我们会先将来自前一个子数组的元素放入辅助数组,这样可以确保相等元素的相对顺序不会改变。

// 归并排序具体功能实现函数
void MergeSortFun(int* a, int* temp, int begin, int end)
{
// 如果数组大小为1或者空,直接返回上一层
if (begin >= end)
{
return;
}
// 划分数组,递归调用 MergeSortFun 对左右子数组进行排序
int mid = (begin + end) / 2;
MergeSortFun(a, temp, begin, mid);
MergeSortFun(a, temp, mid + 1, end);
// 合并两个有序子数组
int begin1 = begin;
int end1 = mid;
int begin2 = mid + 1;
int end2 = end;
int i = begin;
// 依次比较两个子数组的元素,将较小的元素放入辅助数组 temp 中
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
temp[i++] = a[begin1++];
}
else
{
temp[i++] = a[begin2++];
}
}
// 将剩余的元素放入辅助数组 temp 中
while (begin1 <= end1)
{
temp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
temp[i++] = a[begin2++];
}
// 将辅助数组 temp 中的元素拷贝回原数组
for (i = begin; i <= end; i++)
{
a[i] = temp[i];
}
}
// 归并排序入口函数
void MergeSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
// 创建大小为 n 的辅助数组 temp
int* temp = (int*)malloc(sizeof(int) * n);
// 调用 MergeSortFun 对数组 a 进行归并排序
MergeSortFun(a, temp, begin, end);
// 释放辅助数组 temp 的内存空间
free(temp);
}2、归并排序非递归实现
归并排序可以使用非递归的方式实现,其算法思想如下:
- 将待排序的数组划分为多个大小为1的子数组。
- 分别对这些子数组进行两两合并,形成新的有序子数组。
- 不断重复步骤2,直到得到一个有序的数组。
具体的非递归实现过程如下:
- 首先,定义一个大小为n的辅助数组temp用于存储合并后的有序子数组。
- 设置一个变量gap初始值为1,表示每次合并的两个子数组的大小。
- 进行多轮合并,直到gap大于等于n。
- 在每一轮合并中,将数组分为多个大小为gap的子数组,将相邻的两个子数组合并为一个有序子数组。合并时,使用双指针i和j分别指向两个子数组的起始位置,比较两个子数组对应位置上的元素大小,较小的元素放入temp数组中,同时移动指针,直到一个子数组遍历完成。将未遍历完的子数组中剩余的元素直接放入temp数组中。
- 更新gap的值为2倍,继续下一轮合并。
- 最后一轮合并时,gap可能大于n,因此需要额外的判断和处理。
- 将temp数组中的元素拷贝回原数组中。
通过不断调整gap的大小,将待排序数组进行分组和合并操作,直到得到一个完全有序的数组。非递归实现的归并排序避免了递归带来的额外开销,提高了算法的效率。、

void mergesortnr(int* a, int* temp, int begin, int mid, int end)
{
// 定义指针和索引
int head1 = begin;
int tail1 = mid;
int head2 = mid + 1;
int tail2 = end;
int i = begin;
// 合并两个有序子数组
// [head1,tail1] 和 [head2,tail2] 归并
while (head1 <= tail1 && head2 <= tail2)
{
// 比较两个子数组对应位置上的元素大小,较小的元素放入temp数组中
if (a[head1] < a[head2])
{
temp[i++] = a[head1++];
}
else
{
temp[i++] = a[head2++];
}
}
// 将第一个子数组中剩余的元素放入temp数组中
while (head1 <= tail1)
{
temp[i++] = a[head1++];
}
// 将第二个子数组中剩余的元素放入temp数组中
while (head2 <= tail2)
{
temp[i++] = a[head2++];
}
// 将temp数组中的元素拷贝回原数组中
memcpy(a + begin, temp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSortNR(int *a, int n)
{
// 创建辅助数组
int* temp = (int*)malloc(sizeof(int) * n);
int gap = 1;
// 不断调整gap的大小,分组合并
for (gap = 1; gap < n; gap *= 2)
{
// 对每一组进行合并
for (int i = 0; i < n - gap; i += 2 * gap)
{
// 计算子数组的起始索引、中间索引和结束索引
int begin = i;、
/*如果i + 2 * gap - 1大于等于数组长度n,说明当前的子数组已经超出了数组的范围,此时将结束索引end赋值为n - 1,即最后一个元素的索引。
如果i + 2 * gap - 1小于数组长度n,说明当前的子数组还在数组的范围内,此时将结束索引end赋值为i + 2 * gap - 1。*/
int end = i + 2 * gap - 1 >= n ? n - 1 : i + 2 * gap - 1;
int mid = i + gap - 1;
// 调用mergesortnr函数合并子数组
mergesortnr(a, temp, begin, mid, end);
}
}
}