使用MITM进行HTTP流量检测
前言
网络爬虫是一个比较综合的技术,需要对前后端、网络协议等有比较多的了解,而且需要一些探索精神。
本人在早年工作期间主攻服务端,后来接触了前端开发。换工作进入互联网公司,开始接触爬虫。
爬虫发展与反爬技术是互相螺旋升级的,早先服务端渲染,然后前端渲染+REST接口,大部分情况下通过观察
网络访问记录能够很方便地进行数据观测。后来出现各种验证方式,包括Referer判定,IP地址拦截,
UA判定等,还多比较初级,可以针对性地对请求做调整以适应服务端规则,比如添加特定的HTTP头,或者加上
IP代理池等。再后来复杂的包括图片展示、字体加密等方式,所谓道高一尺魔高一丈。
网页站点的爬取,通过浏览器还能比较方便的对网络数据进行观测,而在移动端应用上会稍微复杂些。本文
利用MITM (Man In The Middle)工具,对某校园打卡软件(该软件类似于内嵌小程序,使用web技术)进行处理,
实现自动化打卡功能,包括工具的使用,加密的破解等,供大家参考。
工具准备
本文使用的是一款Python工具,https://mitmproxy.org/,该工具
开源,不但能观测流量数据,还能通过脚本重写请求。其他类似工具包括Charles,Fiddler等。
这边使用brew install mitmproxy安装MITM。完成后,我们使用mitmweb命令打开代理,代理
会监听在8080端口,浏览器会自动打开http://127.0.0.1:8081/,这样我们就可以通过浏览器方便
地查看网络请求。如下图:

启动中间人代理后,我们需要在手机端配置代理地址,以及代理的证书。配置代理:

在手机浏览器访问http://mitm.it,我们会看到证书安装指引文档(不同的系统设置有差异),
根据提示下载证书,并配置信任相关证书:


准备好之后,我们可以打开应用,然后在电脑的浏览器中观察数据请求,当看到如下界面时,表示应用
正在经过我们的代理服务:

分析
代理搭建完成并且配置好移动端后,我们就可以开始进行抓包了。在我们的客户端中进行一系列操作后,可以
查看浏览器中的网络请求情况。重点关注其中的数据请求部分,一般场景下如果数据未加密,我们可以方便地
看到请求参数及服务端返回内容(一般通过路径排除资源类的请求,如图片、CSS、JS等),
同时观察请求头的内容,寻找其中涉及认证的部分,包括cookie,auth token相关的头。如下图示例:

很不幸,这个例子中,使用了token的认证方式,而且请求和返回感觉是经过了加密操作,无法直接看出请求和响应的内容。
关于认证部分,简单的方式我们看是不是可以将token保存,经过一段时间后看还能不能进行访问,相当于回放
攻击的操作。或者在客户端退出登录,观察原先生成的token是否可用。在该例子中,我们复制该请求为cURL,
然后隔天进行请求,发现返回的内容有明显的差异,因此可以判定token有过期机制。这种情况下,我们需要
一步一步追踪历史的请求,看token是在哪个请求中返回的。这里不同的场景需要不同的策略,需要学会灵活应用。
在我们的例子中,我们可以从请求的URL路径中判断哪些是认证相关的请求,如下图所示:

如果不能直接判断,可以将mitmweb的请求保存为文本,进行全文检索。
当我们一步步往上追踪请求响应时,会在中间某环丢失token来源信息,比如该示例中,同一域名下的连续两次
请求,使用的token头有明显的差异,如图所示:
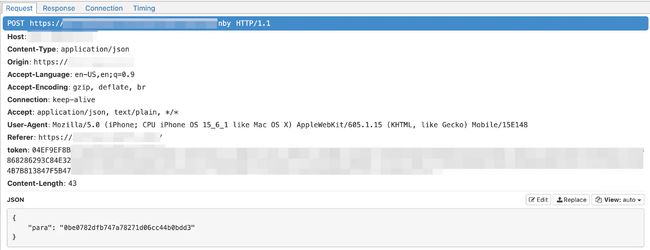

而其中第一个请求的响应经过了加密,无法直接提取第二个请求中的token信息。这时就需要我们对客户端
加解密做相关的调查。一般情况,web端加密需要在服务端进行解密,加密方式常见的有对称加密如AES。
理论上在web端的加密都是可以通过寻找JavaScript代码片段找到加密算法及密钥的,实际过程中也是需要
灵活应用。
而如何找到对应的JavaScript加密代码片段及密钥呢?首先我们需要将网络访问过程中的JavaScript代码保存至本地,
当前大部分前端工程都会使用打包工具对前端代码进行压缩打包。文件命名中,vendor一般是第三方库,不需要太
关注,app或者main开头的一般是主要的程序入口,而0. 1. 2.这样数字开头的,一般是按需加载
对前端代码进行的切分,配合manifest进行处理。
代码下载后,我们通过工具对压缩后的代码进行格式化,可以直接通过VS Code这样的开发环境直接格式化,
将单行JavaScript代码转成较易读的格式,当然里面的变量名等还是压缩后的,较难直接解读。接下来如何
寻找算法及密钥,不同的站点差异较大,仅以当前站点提供一些思路,供参考。
一种我们可以全文搜索路径名称,一般涉及到URL路径的会是最后实际发送HTTP请求的代码,
这部分可能会包含参数、HTTP头等处理,如下示例,搜索之前截图里面的路径nby,可以找到类似下面的代码片段:
async getInformationNBY() {
await this.$apiPost("/nby").then((t) => {
if (0 == t.code)
// omitted
});
},
可以观察到这个函数中并未涉及加解密以及请求头等处理,应该是在$apiPost这个函数中进行的处理。可以
继续搜索该函数,找到其定义的地方。
还有一种方式是,搜索请求中的关键参数,如之前截图中请求JSON里面的para,作为关键字搜索,可以得到
如下的代码片段:
function D(t, e, n = 1) {
S.commit("setShowLoding", !0);
var i = JSON.stringify({
para: (0, w.Encrypt)(JSON.stringify(e || {})),
});
return new Promise((e, r) => {
P.post(t, i)
// omitted
});
}
可以看到其中对para参数的操作,使用了w.Encrypt方法进行了加密,且设置了默认值{}。
接着我们全文搜索Encrypt函数,最后会找到如下代码片段(密钥等信息做了脱敏):
var i = n(2563),
r = i.enc.Utf8.parse("****************"),
a = i.enc.Utf8.parse("****************");
function o(t) {
var e = i.enc.Hex.parse(t),
n = i.enc.Base64.stringify(e),
o = i.AES.decrypt(n, r, {
iv: a,
mode: i.mode.CBC,
padding: i.pad.Pkcs7,
}),
s = o.toString(i.enc.Utf8);
return s.toString();
}
function s(t) {
var e = i.enc.Utf8.parse(t),
n = i.AES.encrypt(e, r, {
iv: a,
mode: i.mode.CBC,
padding: i.pad.Pkcs7,
});
return n.ciphertext.toString();
}
这是典型的AES加密、解密函数,其中i这个变量应该是作为包引入,o为解密函数,s为加密函数,
函数的变量名在模块export的时候进行了重命名。至此我们找到了对应的加解密算法及密钥。
关于算法使用的库,我们可以搜索下JavaScript主流的加密库,这边我们发现是使用的crypto-js库。
我们使用npm进行安装,之后可以在node命令行工具中进行验证。如下:
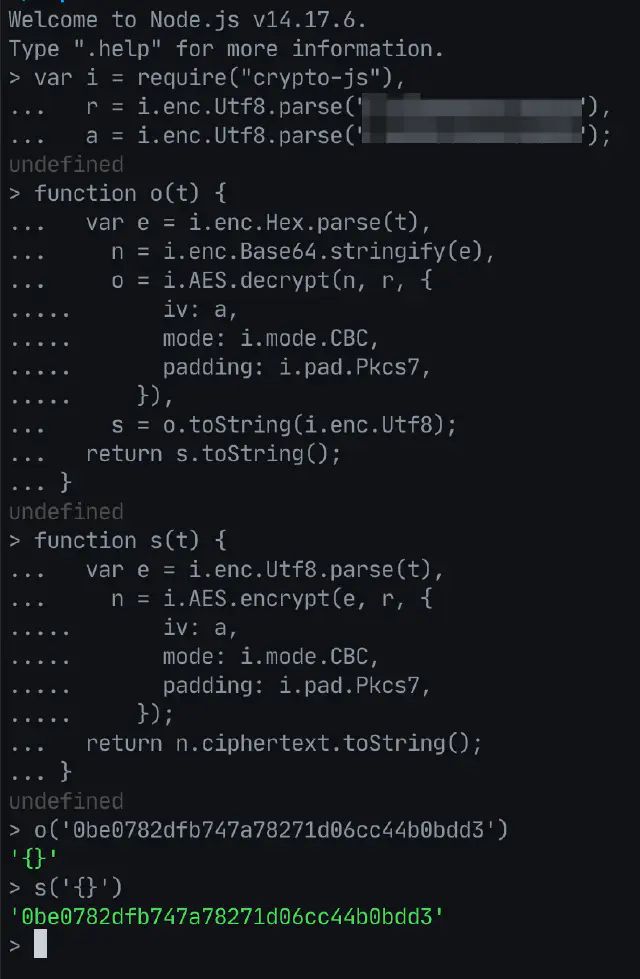
结果符合预期,抓取的请求中的数据能够完美加解密。我们可以对其他请求参数及结果进行解密,
查看其发送的及响应的参数与内容。
上面是用nodejs对数据加解密进行的测试,如果nodejs不符合当前的技术栈,可能需要对加解密代码进行
语言迁移,比如使用Python实现一遍:
import binascii
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
key = b"****************"
iv = b"****************"
block_size = 16
def encrypt(content):
cipher = AES.new(key, AES.MODE_CBC, iv)
content_padding = pad(content, block_size, style='pkcs7')
encrypt_bytes = cipher.encrypt(content_padding)
return binascii.hexlify(encrypt_bytes).decode('utf8')
def decrypt(ciphertext):
cipher = AES.new(key, AES.MODE_CBC, iv)
encrypt_bytes = binascii.unhexlify(ciphertext)
decrypt_bytes = cipher.decrypt(encrypt_bytes)
return unpad(decrypt_bytes, block_size, style='pkcs7').decode('utf-8')
总结
本篇文章以某移动端应用中的小程序为例,简要介绍了网络爬虫中涉及到的抓包、鉴权、加解密等方面的一般
分析流程。当然不同的应用使用的协议、认证方式、加密算法等都会有所差异,如何分析流量,检测代码片段,
或者识别加解密算法等,无法通过简单的说明全部涵盖,更需要的是对数据的分析和探索精神。
以上截图及部分代码片段等,已做脱敏,仅做分析使用。
原文链接在个人博客站点https://tomo.dev/posts/crawl-mitm-auth-and-cryptology/