图解数据结构C++版 - (02) - 图论
目录
2 图论
2.1 图的概念
(1)图的定义
(2)图的基本术语
2.2 图的存储结构
(1)邻接矩阵
(2)邻接表存储方法
(3)简化的连接表
【题1】LeetCode997:找到小镇的法官
2.3 图的遍历
【题2】LeetCode100:岛屿数量
【题3】LeetCode197寻找图中是否存在路径
2 图论
2.1 图的概念
(1)图的定义
图G(Graph)由两个集合V(Vertex)和E(Edge)组成,记为G=(V,E)。V是顶点的有限集合,记为V(G)。E是连接V中两个不同顶点(顶点对)的边的有限集合,记为E(G)。
无向图和有向图:
在图G中,如果代表边的顶点对(或序偶)是无序的,则称G为无向图。无向图中代表边的无序顶点对通常用圆括号括起来,用以表示一条无向边。
如果表示边的顶点对(或序偶)是有序的,则称G为有向图。在有向图中代表边的顶点对通常用尖括号括起来,用以表示一条有向边(又称为弧),如<i,j>表示从顶点i到顶点j的一条边。
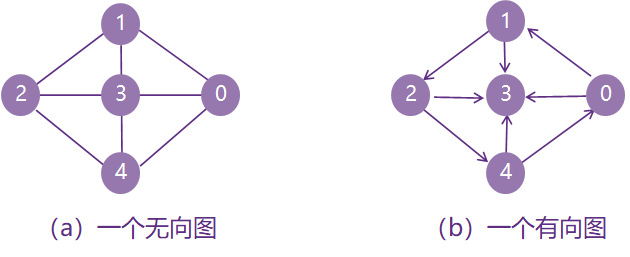
多重图:重复出现一条边,如一个无向图中顶点1和2之间出现两条或两条以上的边。

(2)图的基本术语
邻接点: 在一个无向图中,若存在一条边(i,j),则称顶点i和顶点j为该边的两个端点,并称它们互为邻接点,即顶点i是顶点j的一个邻接点,顶点j也是顶点i的一个邻接点。
起始端点(起点)和终止端点(终点):在一个有向图中,若存在一条边

顶点的度:在无向图中,顶点所关联的边的数目。
入度:在有向图中,以顶点i为终点的入边的数目。
出度:以顶点i为起点的出边的数目。
顶点的度:一个顶点的入度与出度的和为该顶点的度。
完全无向图:每两个顶点之间都存在着一条边。含有n个顶点的完全无向图有n(n-1)/2条边。
完全有向图:每两个顶点之间都存在着方向相反的两条边。含有n个顶点的完全有向图包含有n(n-1)条边。

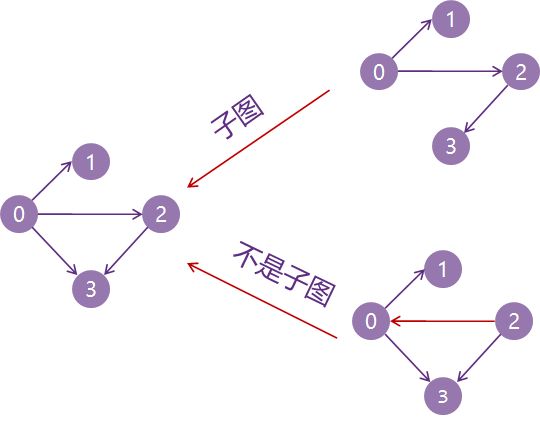
子图:设有两个图G=(V,E)和G'=(V',E'),若V'是V的子集,且E'是E的子集,则称G'是G的子图。
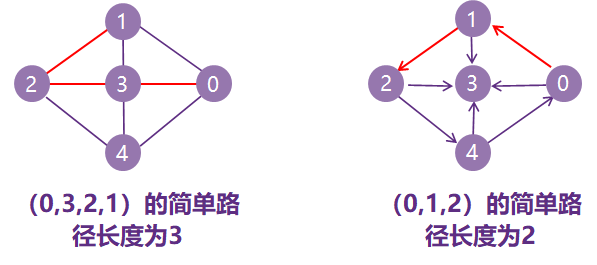
路径:在一个图G=(V,E)中,从顶点i到顶点j的一条路径是一个顶点序列
路径长度:是指一条路径上经过的边的数目。
简单径路:若一条路径上除开始点和结束点可以相同外,其余顶点均不相同,则称此路径为简单径路。
回路或环:若一条路径上的开始点与结束点为同一个顶点,则此路径被称为回路或环。
简单回路或简单环:开始点与结束点相同的简单路径被称为简单回路或简单环。

连通:在无向图G中,若从顶点i到顶点j有路径,则称顶点i和顶点j是连通的。
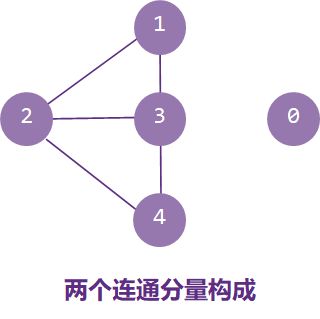
连通图与非连通图:若图G中任意两个顶点都连通,则称G为连通图,否则称为非连通图。
连通分量:无向图G中的极大连通子图称为G的连通分量。显然,任何连通图的连通分量只有一个即本身,而非连通图有多个连通分量。
强连通图:若图G中的任意两个顶点i和j都连通,即从顶点i到顶点j和从顶点j到顶点i都存在路径,则称图G是强连通图。
强连通分量:有向图G中的极大强连通子图称为G的强连通分量。显然,强连通图只有一个强连通分量即本身,非强连通图有多个强连通分量。一般地单个顶点自身就是一个强连通分量。
权:图中每一条边都可以附有一个对应的数值,这种与边相关的数值称为权。权可以表示从一个顶点到另一个顶点的距离或花费的代价。
带权图:边上带有权的图称为带权图,也称作网。

2.2 图的存储结构
(1)邻接矩阵
邻接矩阵是表示顶点之间邻接关系的矩阵。设G=(V,E)是含有n(设n>0)个顶点的图,各顶点的编号为0~n-1,则G的邻接矩阵数组A是n阶方阵。
如果G是不带权图,则:


如果G是带权图,则:


const int MAXV=100; //图中最多的顶点数
const int INF=0x3f3f3f3f; //用INF表示∞
class MatGraph //图邻接矩阵类
{
public:
int edges[MAXV][MAXV]; //邻接矩阵数组,假设元素为int类型
int n,e; //顶点数,边数
string vexs[MAXV]; //存放顶点信息
//图的基本运算算法
}
(2)邻接表存储方法
对图中每个顶点i建立一个单链表,将顶点i的所有邻接点链起来。

图的邻接表存储方法是一种顺序分配与链式分配相结合的存储方法。每个单链表上添加一个表头结点(表示顶点信息)。并将所有表头结点构成一个数组,下标为i的元素表示顶点i的表头结点。

class AdjGraph //图邻接表类
{
public:
HNode adjlist[MAXV]; //头结点数组
int n,e; //顶点数,边数
AdjGraph() //构造函数
{ for (int i=0;inextarc;
while (p!=NULL) //释放adjlist[i]的所有边结点空间
{ delete pre;
pre=p; p=p->nextarc; //pre和p指针同步后移
}
delete pre;
}
}
}
//图的基本运算算法
};
邻接表的特点:
- 邻接表表示不唯一。
- 对于有n个顶点和e条边的无向图,其邻接表有n个表头结点和2e个边结点;对于有n个顶点和e条边的有向图,其邻接表有n个表头结点和e个边结点。显然,对于边数目较少的稀疏图,邻接表比邻接矩阵要节省空间。
- 对于无向图,顶点i(0≤i≤n-1)对应的单链表的边结点个数正好是顶点i的度。
- 对于有向图,顶点i(0≤i≤n-1)对应的单链表的边结点个数仅仅是顶点i的出度。顶点i的入度是邻接表中所有adjvex值为i的边结点个数。
- 用邻接表存储图时,确定任意两个顶点之间是否有边相连的时间为O(m)(m为最大顶点出度,m
逆邻接表: 在有向图中,adjlist[i]的单链表只存放了顶点 i 的出边,所以不便找入边,逆邻接表在有向图的邻接表中将adjlist[i]的单链表的出边改为入边。

(3)简化的连接表
推荐表达类型,节约空间
直接用两个数组表示邻接表,头结点数组为head。边结点数组edges为ENode类型,该类型包含adjvex、weight和next成员变量,其中head[i]表示顶点i的单链表(head[i]=-1表示顶点i没有出边)。

int head[MAXV]; //头结点数组
struct Edge //边结点类型
{ int adjvex; //邻接点
int weight; //权值
int next; //下一个边结点在edges数组中的下标
} edges[MAXE]; //边结点数组
int n; //顶点数
int cnt; //edges数组元素个数
void init() //初始化
{ cnt=0; //cnt从0开始
memset(head,0xff,sizeof(head)); //所有元素初始化为-1
}
void addedge(int u,int v,int w) //添加一条有向边:w
{ edges[cnt].adjvex=v; //该边插入到edges数组末尾
edges[cnt].weight=w;
edges[cnt].next=head[u]; //将edges[cnt]边结点插入到head[u]的表头
head[u]=cnt;
cnt++; //edges数组元素个数增1
}
【题1】LeetCode997:找到小镇的法官
小镇里有 n 个人,按从 1 到 n 的顺序编号。传言称,这些人中有一个暗地里是小镇法官。
如果小镇法官真的存在,那么:
- 小镇法官不会信任任何人。
- 每个人(除了小镇法官)都信任这位小镇法官。
- 只有一个人同时满足属性 1 和属性 2 。
给你一个数组 trust ,其中 trust[i] = [ai, bi] 表示编号为 ai 的人信任编号为 bi 的人。 如果小镇法官存在并且可以确定他的身份,请返回该法官的编号;否则,返回 -1 。
示例 1:
输入:n = 2, trust = [[1,2]]
输出:2
示例 2:
输入:n = 3, trust = [[1,3],[2,3]]
输出:3
提示:
1 <= n <= 10000 <= trust.length <= 104trust[i].length == 2trust中的所有trust[i] = [ai, bi]互不相同ai != bi1 <= ai, bi <= n
题解:
本题需要用到有向图中节点的入度和出度的概念。在有向图中,一个节点的入度是指向该节点的边的数量;而一个节点的出度是从该节点出发的边的数量。
题干描述了一个有向图。每个人是图的节点,trust的元素 trust[i]是图的有向边,从 trust[i][0]指向 trust[i][1]。我们可以遍历 trust,统计每个节点的入度和出度,存储在 inDegrees和outDegrees中。
根据题意,在法官存在的情况下,法官不相信任何人,每个人(除了法官外)都信任法官,且只有一名法官。因此法官这个节点的入度是 n−1, 出度是 0。
我们可以遍历每个节点的入度和出度,如果找到一个符合条件的节点,由于题目保证只有一个法官,我们可以直接返回结果;如果不存在符合条件的点,则返回 −1。
class Solution {
public:
int findJudge(int n, vector>& trust) {
vector inDegrees(n + 1);
vector outDegrees(n + 1);
for (auto& edge : trust) { // 遍历数组的快速方法
int x = edge[0], y = edge[1];
++inDegrees[y];
++outDegrees[x];
}
for (int i = 1; i <= n; ++i) {
if (inDegrees[i] == n - 1 && outDegrees[i] == 0) {
return i;
}
}
return -1;
}
}; 2.3 图的遍历
从给定图中任意指定的顶点(称为初始点)出发,按照某种搜索方法沿着图的边访问图中的所有顶点,使每个顶点仅被访问一次,这个过程称为图遍历。
为了避免同一个顶点被重复访问,可设置一个访问标志数组visited,初始时所有元素置为0,当顶点i访问过时,该数组元素visited[i]置为1。
根据遍历方式的不同,图的遍历方法有两种:一种是深度优先遍历(DFS)方法;另一种是广度优先遍历(BFS)方法。

(1)深度优先遍历
int visited[MAXV]; //全局数组
void DFS(AdjGraph& G,int v) //深度优先遍历(邻接表)
{ cout << v << " "; //访问顶点v
visited[v]=1; //置已访问标记
ArcNode*p=G.adjlist[v].firstarc; //p指向顶点v的第一个邻接点
while (p!=NULL)
{ int w=p->adjvex; //邻接点为w
if (visited[w]==0) DFS(G,w); //若w顶点未访问,递归访问它
p=p->nextarc; //p置为下一个邻接点
}
}(2)广度优先遍历
//广度优先遍历(邻接表)
void BFS(AdjGraph& G,int v)
{ int visited[MAXV];
memset(visited,0,sizeof(visited)); //初始化visited数组
queue qu; //定义一个队列
cout << v << " "; //访问顶点v
visited[v]=1; //置已访问标记
qu.push(v); //顶点v进队
while (!qu.empty()) //队列不空循环
{ int u=qu.front(); qu.pop(); //出队顶点u
ArcNode* p=G.adjlist[u].firstarc; //找顶点u的第一个邻接点
while (p!=NULL)
{ if (visited[p->adjvex]==0) //若u的邻接点未访问
{ cout << p->adjvex << " "; //访问邻接点
visited[p->adjvex]=1; //置已访问标记
qu.push(p->adjvex); //邻接点进队
}
p=p->nextarc; //找下一个邻接点
}
}
}
//广度优先遍历(邻接矩阵)
void BFS(MatGraph& g,int v)
{ int visited[MAXV];
memset(visited,0,sizeof(visited)); //初始化visited数组
queue qu; //定义一个队列
cout << v << " "; //访问顶点v
visited[v]=1; //置已访问标记
qu.push(v); //顶点v进队
while (!qu.empty()) //队列不空循环
{ int u=qu.front(); qu.pop(); //出队顶点u
for (int i=0;i并且顶点i未访问
{ cout << i << " "; //访问邻接点i
visited[i]=1; //置已访问标记
qu.push(i); //邻接点i进队
}
}
}
} 【题2】LeetCode100:岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
示例1 :
输入:grid = [ ["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"] ]
输出:1
示例 2:
输入:grid = [ ["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"] ]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
题解:
方法一:深度优先搜索
我们可以将二维网格看成一个无向图,竖直或水平相邻的 111 之间有边相连。为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 111,则以其为起始节点开始进行深度优先搜索。在深度优先搜索的过程中,每个搜索到的 111 都会被重新标记为 000。最终岛屿的数量就是我们进行深度优先搜索的次数。
class Solution {
private:
void dfs(vector>& grid, int r, int c) {
int nr = grid.size();
int nc = grid[0].size();
grid[r][c] = '0';
if (r - 1 >= 0 && grid[r-1][c] == '1') dfs(grid, r - 1, c);
if (r + 1 < nr && grid[r+1][c] == '1') dfs(grid, r + 1, c);
if (c - 1 >= 0 && grid[r][c-1] == '1') dfs(grid, r, c - 1);
if (c + 1 < nc && grid[r][c+1] == '1') dfs(grid, r, c + 1);
}
public:
int numIslands(vector>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
dfs(grid, r, c);
}
}
}
return num_islands;
}
}; 方法二:广度优先搜索
同样地,我们也可以使用广度优先搜索代替深度优先搜索。为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则将其加入队列,开始进行广度优先搜索。在广度优先搜索的过程中,每个搜索到的 1都会被重新标记为 0。直到队列为空,搜索结束。最终岛屿的数量就是我们进行广度优先搜索的次数。
class Solution {
public:
int numIslands(vector>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
grid[r][c] = '0';
queue> neighbors;
neighbors.push({r, c});
while (!neighbors.empty()) {
auto rc = neighbors.front();
neighbors.pop();
int row = rc.first, col = rc.second;
if (row - 1 >= 0 && grid[row-1][col] == '1') {
neighbors.push({row-1, col});
grid[row-1][col] = '0';
}
if (row + 1 < nr && grid[row+1][col] == '1') {
neighbors.push({row+1, col});
grid[row+1][col] = '0';
}
if (col - 1 >= 0 && grid[row][col-1] == '1') {
neighbors.push({row, col-1});
grid[row][col-1] = '0';
}
if (col + 1 < nc && grid[row][col+1] == '1') {
neighbors.push({row, col+1});
grid[row][col+1] = '0';
}
}
}
}
}
return num_islands;
}
}; 【题3】LeetCode1971:寻找图中是否存在路径
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。请你确定是否存在从顶点 source 开始,到顶点 destination 结束的 有效路径 。
给你数组 edges 和整数 n、source 和 destination,如果从 source 到 destination 存在 有效路径 ,则返回 true,否则返回 false 。
示例 1:

输入:n = 3, edges = [[0,1],[1,2],[2,0]], source = 0, destination = 2
输出:true
解释:存在由顶点 0 到顶点 2 的路径:( 0 → 1 → 2 )(0 → 2)
示例 2:

输入:n = 6, edges = [[0,1],[0,2],[3,5],[5,4],[4,3]], source = 0, destination = 5
输出:false
解释:不存在由顶点 0 到顶点 5 的路径.
提示:
1 <= n <= 2 * 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ui, vi <= n - 1ui != vi0 <= source, destination <= n - 1- 不存在重复边
- 不存在指向顶点自身的边
题解:
方法一:广度优先搜索
使用广度优先搜索判断顶点 source 到顶点 destination的连通性,需要我们从顶点 source开始按照层次依次遍历每一层的顶点,检测是否可以到达顶点 destination。遍历过程我们使用队列存储最近访问过的顶点,同时记录每个顶点的访问状态,每次从队列中取出顶点 vertex时,将其未访问过的邻接顶点入队列。
初始时将顶点 source设为已访问,并将其入队列。每次将队列中的节点 vertex出队列,并将与 vertex相邻且未访问的顶点 next入队列,并将 next设为已访问。当队列为空或访问到顶点 destination时遍历结束,返回顶点 destination的访问状态即可。
class Solution {
public:
bool validPath(int n, vector>& edges, int source, int destination) {
vector> adj(n);
for (auto &&edge : edges) {
int x = edge[0], y = edge[1];
adj[x].emplace_back(y);
adj[y].emplace_back(x);
}
vector visited(n, false);
queue qu;
qu.emplace(source);
visited[source] = true;
while (!qu.empty()) {
int vertex = qu.front();
qu.pop();
if (vertex == destination) {
break;
}
for (int next: adj[vertex]) {
if (!visited[next]) {
qu.emplace(next);
visited[next] = true;
}
}
}
return visited[destination];
}
}; 方法二:深度优先搜索
source,destination的连通性,需要从顶点 source\开始依次遍历每一条可能的路径,判断可以到达顶点 destination,同时还需要记录每个顶点的访问状态防止重复访问。
首先从顶点 source开始遍历并进行递归搜索。搜索时每次访问一个顶点 vertex 时,如果 vertex等于 destination则直接返回,否则将该顶点设为已访问,并递归访问与 vertex相邻且未访问的顶点 next。如果通过 next的路径可以访问到 destination,此时直接返回 true,当访问完所有的邻接节点仍然没有访问到 destination,此时返回 false。
class Solution {
public:
bool dfs(int source, int destination, vector> &adj, vector &visited) {
if (source == destination) {
return true;
}
visited[source] = true;
for (int next : adj[source]) {
if (!visited[next] && dfs(next, destination, adj, visited)) {
return true;
}
}
return false;
}
bool validPath(int n, vector>& edges, int source, int destination) {
vector> adj(n);
for (auto &edge : edges) {
int x = edge[0], y = edge[1];
adj[x].emplace_back(y);
adj[y].emplace_back(x);
}
vector visited(n, false);
return dfs(source, destination, adj, visited);
}
};
