代谢物常见的ID号你都搞明白了吗?
代谢物常见的ID号有好几种,今天和大家一起来整理一下代谢物常见的ID号。
首先我们列一个清单(使用频率较高的代谢物ID):
CAS Registry Number
KEGG ID
Pubchem CID
HMDB ID
SMILES
InChI
InChIKey
01
CAS Registry Number
CAS Registry Number是我们向供应商采购代谢物的关键依据(以保障买到正确的代谢物)。CAS Registry Numberd的本质是代谢物到美国化学学会CAS注册数据库注册获得的注册号。
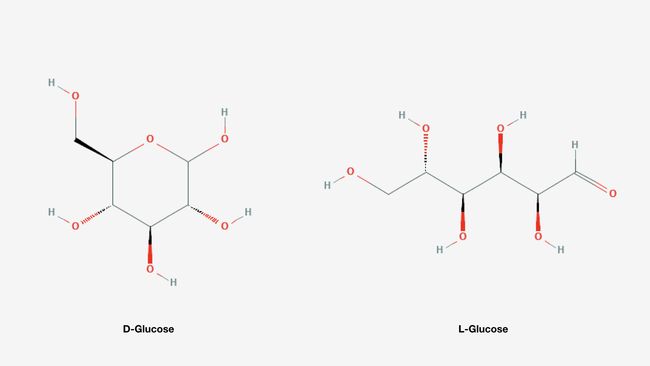
CAS Registry Number的格式为“[0-9]{2-7}-[0-9]{2}-[0-9]”,第一部分2至7位数字、第二部分2位数字为顺序号,第三部分一位数字为根据前两部分数字计算得到的校验码。比如:D-Glucose的CAS Registry Number为50-99-7;L-Glucose的CAS Registry Number为921-60-8。
https://www.cas.org/support/documentation/chemical-substances/faqs
02
KEGG ID
KEGG ID是KEGG: Kyoto Encyclopedia of Genes and Genomes数据库对代谢物建立的编号,该数据库包含了丰富的代谢物功能注释信息(尤其是代谢通路信息)。目前KEGG数据库收录的Compound数量约为19000个,其中约15000个ID对应唯一的代谢物结构,其余ID对应含部分相同子结构的一类代谢物结构。
KEGG ID的格式为“C[0-9]{5}”,“C”代表Compound的,后面五位数字为顺序号。比如:D-Glucose的KEGG ID为C00031;L-Glucose KEGG未收录。
https://www.genome.jp/kegg/
03
Pubchem CID
Pubchem CID是NCBI: National Center for Biotechnology Information数据库的子库Pubchem 数据库对代谢物建立的编号。Pubchem目前收录了近一亿个Compound的全面信息(物理、化学、生物特性等),是最大的开源化合物库。
Pubchem CID的格式为单纯的数字,也就是顺序号。比如:D-Glucose的Pubchem CID为5793;L-Glucose的Pubchem CID为10954115。
https://pubchem.ncbi.nlm.nih.gov
04
HMDB ID
HMDB ID是HMDB:The Human Metabolome Database数据库对代谢物建立的编号,该数据包含了丰富的代谢物来源和分布信息(尤其是代谢物相关疾病信息)。目前HMDB数据库收录的Compound数量约为120000个。
HMDB ID的数据格式发生过一次调整:新版的HMDB ID格式为“HMDB[0-9]{7}”,“HMDB”+7位数的顺序号;旧版的HMDB ID格式为“HMDB[0-9]{5}”,“HMDB”+5位数的顺序号。老版的已有HMDB ID号在HMDB和原有五位数的顺序号间添加00升级为新版的HMDB ID,新收录的代谢物只编写新版HMDB ID。比如:D-Glucose的HMDB ID为HMDB0000122;L-Glucose HMDB未收录。
http://www.hmdb.ca
05
SMILES
SMILES:The Simplified Molecular-inout Line-entry System 是一种线性描述代谢物结构的字符串。SMILES的本质是使用文本记录原子(节点)和键(边)从而记录代谢物结构(图)。
往往使用B、C、N、O、P、S、Cl、Br等字母来表示原子;使用.、-、=、#、$等符号来表示键;使用 ( ) 来表示分支。一个代谢物结构往往可以书写为多个SMILES,但是一个SMILES只会表示一个确定的代谢物结构。使用canonicalization 算法生成canonical SMILES可以保证一个代谢物结构只能书写为一个canonical SMILES。比如:D-Glucose的canonical SMILES为“C(C1C(C(C(C(O1)O)O)O)O)O”;L-Glucose的canonical SMILES为“C(C(C(C(C(C=O)O)O)O)O)O”。
http://opensmiles.org/opensmiles.html
06
InChI
InChI:The IUPAC International Chemical Identifier是一种用于描述代谢物结构信息的新型文本。InChI由国际理论(化学)与应用化学联合会和美国国家标准与技术研究院共同开发。InChI在设计之初就保证了InChI和代谢物结构的一一对应关系。InChI将化学结构信息拆分为不同的特征层(化学式层、连接层、电荷层、同位素层等)来分开描述以方便不同的使用需求。
InChI的格式为“InChI=1S/化学式层/原子连接层/氢原子层/其他层(可省略)”。其中“InChI=”表明ID类型,“1”为版本号,“S”为标准的InChI之意,化学式层、原子连接层和氢原子层必需包含其余层可以省略。比如:D-Glucose的InChI为“InChI=1S/C6H12O6/c7-1-2-3(8)4(9)5(10)6(11)12-2/h2-11H,1H2/t2-,3-,4+,5-,6?/m1/s1”;L-Glucose的InChI为“InChI=1S/C6H12O6/c7-1-3(9)5(11)6(12)4(10)2-8/h1,3-6,8-12H,2H2/t3-,4+,5+,6+/m1/s1”。
https://www.inchi.info
07
InChIKey
InChIKey由InChI衍生而来。InChIKey是InChI的一种“加密”形式,是固定长度的一串字符。
InChIKey的格式为“[A-Z]{14}-[A-z]{11}-[A-Z]{1}”,第一部分14个字母基于连接层和质子层、第二部分的前9个字母基于其余层、第二部分的后两个字母基于标准/非标准特征使用SHA-256编码,第三部分的唯一字母描述(去)质子层。比如:D-Glucose的InChIKey为“WQZGKKKJIJFFOK-GASJEMHNSA-N”;L-Glucose的InChIKey为“GZCGUPFRVQAUEE-VANKVMQKSA-N”。
https://www.inchi.info/inchikey_overview_en.html
可以根据InChI直接计算得到InChIKey;
由InChIKey得到InChI需要查表;
10亿之一的概率一个InChIKey会对应一个以上的InChI。
总结

CAS Registry Number、KEGG ID、PubChem CID和HMDB ID是数据库依赖的ID类型。
1.代谢物结构和ID之间没有内在的联系;
2.不能通过ID直接阅读(解析)出代谢物的结构;
3.不能由代谢物的结构直接编写出ID;
4.仅数据库管理者可以编写ID;
5.代谢物结构和ID之间的联系通过数据库提供的对应表记录;
6.不能确保ID和代谢物结构的一一对应。
SMILES和InChI是和结构强相关的ID类型。
1.熟悉规则的人或者程序可以直接阅读SMILES和InChI获得代谢物的结构而不用依赖数据库(表);
2.熟悉规则的人或者程序可以直接为结构确定的代谢物编写SMILES和InChI;
3.按照规则任何人都可以编写ID;
4.代谢物结构和ID之间的联系通过规则建立;
5.Canonical SMILES和InChI可以做到ID和代谢物结构的一一对应。
建议优先使用SMILES、InChI这种和结构强相关的ID。不同数据库之间做ID转换的时候,应通过代谢物的结构来做确认