Redis笔记+Lua+Redisson分布式锁
前言
仅记录学习笔记,如有错误欢迎指正。
最近打算重新整理一下笔记,好好回顾一下之前学的东西。争取在6月份之前整理完毕,加油加油。
一、Redis
String(512M),hash,list,set,zset5种数据类型
Redis的持久化
RDB:
指定的时间间隔内生成数据集的时间点快照,但是一旦redis宕机,最后一次的数据就无法保存。
将某个时间点上数据库的状态保存在一个压缩的二进制文件中,通过它可以还原这个时候数据库的状态。
AOF:
根据保存服务器所执行的写命令来保存数据
然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
默认设置为 everysec 即使奔溃也只丢失1s的数据 always太消耗性能了 no不开启
新增RBD-AOF混合持久化
既可以快速加载又能避免丢失过多数据。
主从复制:
因为redis读写都在一台服务器上,访问量大时会有延时,所以采取一个主服务器专门去写,从服务器去读。
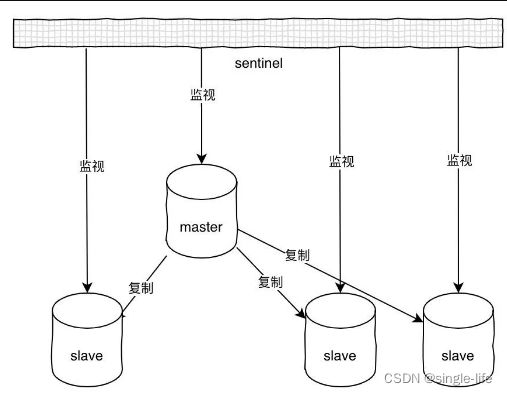
哨兵模式(sentinel):
防止主服务器宕机,系统无法运行,采取投票的操作,选择一个从服务器变为主服务器。支持集群。
- 每隔10s对master发出命令,获取master和它的slave的所有信息
- 当master有新的slave的时候,sentinel哨兵也会和它们建立连接,每隔10s,更新master的信息。
- sentinel 每隔1s对所有服务器发送ping命令,在其配置时间连续返回无效回应,则被标记下线状态。
- 选出领头的sentinel(需要一半的sentinel同意),在下线的master对应的slave选择一个成为master
- 让所有的slave从新的master复制数据(主写从读啊)
- 把原来的master变为slave,这样它恢复过来就变成了slave
使用redis可能出现的问题:
缓存雪崩:
举例: 假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。
解决办法:可以给缓存设置不同的缓存时间,更新数据使用互斥锁或者通过双缓存在避免缓存雪崩。
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透:(针对value,查询缓存不存在的数据)
举例:对于系统A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
比如。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。
解决办法:
-
在接口做校验
-
存null值(缓存击穿加锁)
-
布隆过滤器拦截: 将所有可能的查询key 先映射到布隆过滤器中,查询时先判断key是否存在布隆过滤器中,存在才继续向下执行,如果不存在,则直接返回。布隆过滤器将值进行多次哈希bit存储,布隆过滤器说某个元素在,可能会被误判。布隆过滤器说某个元素不在,那么一定不在。
缓存击穿:
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,
大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
解决方法:
- 加锁更新,当发现查询的时候,缓存没有,对其加锁,先从数据库查出来写入缓存,再返回给用户,之后就可从缓存读取了。
- 把热key的过期时间存入value中,异步的方式刷新过期时间,防止过期。
怎么解决Redis和数据库数据不一致问题
异步更新缓存(基于订阅binlog的同步机制):
1)读Redis:热数据基本都在Redis
2)写MySQL:增删改都是操作MySQL
3)更新Redis数据:MySQ的数据操作binlog,来更新到Redis
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
Redis的过期策略
- 惰性删除 当我们查询key的时候才对它进行检测,到达过期时间就删除,缺点是不查询就无法删除已经过期的key。
- 定期删除 redis每隔一段时间就对数据库做一次检查,删除过期的key,不可能对所有key轮询,随机抽取key来检查。
Redis内存淘汰机制:(过期key没能删除)
-
volatile-lru( less recently used):从已设置过期时间的key中,移除最少使用的key淘汰。
-
volatile-ttl( time to live):从已设置过期时间的key中,移除即将过期的key
-
volatile-random:从已设置过期时间的key中,随机移除key
-
allkeys-lru:对所有key,移除最少使用的key淘汰
-
allkeys-random:对所有key,随机移除key
-
noeviction :不移除任何key,当内存到达阈值时,新写入的操作返回报错消息。
Redis主从复制原理(实现高可用)
- slave发送psync(同步命令)到master
- master接收到后,生成RDB文件
- 把新接收到的写的命令存入缓存(生成文件期间)
- 把RDB文件发送到slave,slave清空自己的数据,执行
- slave再去执行缓存中的写入命令,达到数据一致的情况
Redis的事务
通过MUlTI,EXEC,WATCH(乐观锁),来实现事务机制。
- 服务器收到客户端请求,事务以MUlTI开始
- 如果客户端处于事务状态,则会把事务放入队列中返回客户端QUEUED,反正就执行这个命令
- 当收到EXEC命令时,WATCH命令监视整个事务中的key是否有被修改,如果有则返回空到客户端表失败。
- 否则redis会遍历整个事务队列,执行队列中保存的所有命令,最后返回结果给客户端。
Redis如何做大量数据插入?
Redis2.6开始redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
redis是单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。
这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
使用Redis做过异步队列吗,是如何实现的?
使用list类型保存数据信息,rpush生产消息,lpop消费消息,当lpop没有消息时,可以sleep一段时间,然后再检查有没有信息,如果不想sleep的话,可以使用blpop, 在没有信息的时候,会一直阻塞,直到信息的到来。redis可以通过pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
在做消息导出的时候,来一个就保存一个导出消息在list里面,通知给前台,前台可以实时查看新消息。查看后返回已读状态到数据库。
Redis如何实现延时队列?
使用sortedset,使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。
Redis回收进程如何工作的?
- 一个客户端运行了新的命令,添加了新的数据。
- Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
- 一个新的命令被执行,等等。
- 所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
Redis回收使用的是LRU算法!
Redis6.0之前单线程的工作模式:(多路复用)
也是为什么redis单线程还会有这么快的速度!
-
多路I/O复用模型是利用 select、poll、epoll 可以同时监听多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
-
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量
对于一个请求操作,Redis主要做3件事情:从客户端读取数据、执行Redis命令、回写数据给客户端(如果再准确点,其实还包括对协议的解析)。
所以主线程其实就是把所有操作的这3件事情,串行一起执行,因为是基于内存,所以执行速度非常快:
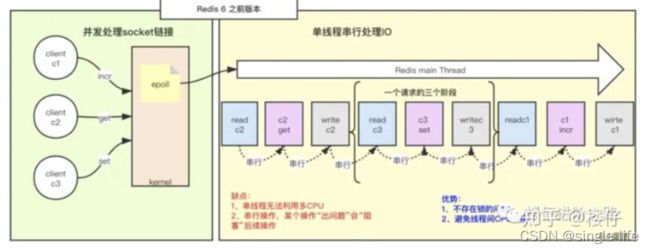
优点:不存在锁的问题;没有线程间的cpu切换
缺点:单线程无法利用多cpu,串行操作,可能会有阻塞情况出现。
Redis6.0之后多线程的工作模式:(多线程处理io,单线程串行处理计算)
Redis多线程的优化思路:因为网络I/O在Redis执行期间占用了大部分CPU时间,所以把网络I/O部分单独抽离出来,做成多线程的方式。
这里所说的多线程,其实就是将Redis单线程中做的这两件事情“从客户端读取数据、回写数据给客户端”(也可以称为网络I/O),处理成多线程的方式,但是“执行Redis命令”还是在主线程中串行执行,这个逻辑保持不变。
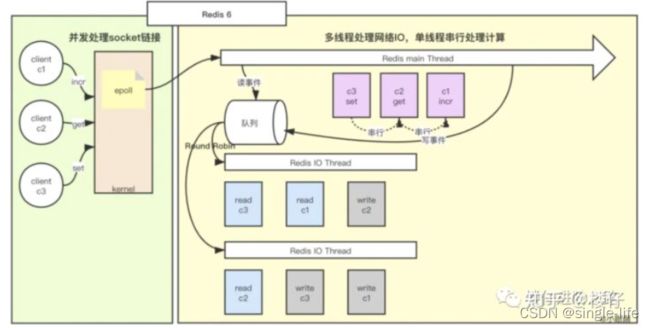
流程为:主线程执行请求入队列 -> I/O线程并行进行网络读 -> 主线程串行执行Redis命令 -> I/O线程并行进行网络写 -> 主线程清空队列,并接收下一批请求。
优点: 提高响应速度,充分使用CPU
缺点: 增加了代码复杂性
Redisson
数据分片:Redisson通过自身的分片算法,将一个大集合拆分为若干个片段(默认231个,分片数量范围是3 - 16834),然后将拆分后的片段均匀的分布到集群里各个节点里,保证每个节点分配到的片段数量大体相同。
让数据不再保存在一个槽里,而是均匀的的分布在整个集群里。
优势:.
1.单个数据结构可以充分利用整个集群内存资源,而不是被某一个节点的内存限制。
2.将单个数据结构分片以后分布在集群中不同的节点里,不仅可以大幅提高读写性能,
还能够保证读写性能随着集群的扩张而自动提升,方便拓展。
故障转移
在集群中,A向B发送ping消息,B若是没有再规定时间相应,A就会把B标记为疑似下线状态,并把这个消息发送给其他节点,若是有半数的节点都标记B为pfail,则B变为下线状态,此时发生故障转移,在保存数据多的从节点选择一个为主节点,让他接管这个下线的slot,和哨兵类似,基于Raft协议进行选举。
Lua实现分布式锁:
在传播数据到lua脚本之前,Redis判断之前的操作是否执行了随机和写的操作,这样保证了不同的服务器之间的数据一致。
贴一下加锁的脚本:

解释:
KEYS[1]:表示你加锁的那个key,比如说
RLock lock = redisson.getLock(“myLock”);
ARGV[1]:表示锁的有效期,默认30s
ARGV[2]:表示表示加锁的客户端ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
ARGV[3] 为当前加锁次数 第一次为1,重入为2
解锁思路:
1.接受redis传来的参数
2.判断是否是自己的锁,是则删掉
3.返回结果值

如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。
watch dog自动延期机制:
意思是默认为加锁30秒,在20s的时候,如果业务没有执行完,锁没有被释放,watch dog会给锁延期,重置为30s
释放。watch dog 每隔10s进行检查一次。
缺陷:最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master 的 slave实例。 但是这个过程中一旦发生redis master宕机,主从切换,redis slave变为了redis master。接着就会导致,客户端2来尝试加锁的时 候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。此时就会导致多个客户端对一个分布式锁完成了加锁。这时系统在业务上一定会出现问题,导致脏数据的产生。