大数据 - Spark系列《五》- Spark常用算子
Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
目录
5.1. 转换算子
5.1.1. map
5.1.2. flatMap
5.1.3 filter
5.1.4groupBy
5.1.5mapPartitionWithIndex
5.1.6 sortBy
5.1.7 distinct
5.1.8 mapPartitions
5.1.9 groupByKey
5.1.10reduceByKey
5.1.11交集差集并集笛卡尔积
5.1.12 zip算子
5.1.13 join算子
5.2 行动算子
5.2.1reduce
5.2.2aggregate
5.2.3 foreachPartition
5.2.4 其他行动算子举例
前言
创建好RDD以后,就可以根据自己的需求编写处理逻辑!在RDD上就可以调用处理数据的方法(算子) ,
算子分为两种:
-
rdd.算子 ---> 返回新的RDD 这样的算子叫转换算子
-
rdd.算子--->不返回新的RDD 为行动算子 , 触发RDD加载数据 ,触发计算
(行动算子一定触发计算, 特殊转换算子可能触发计算)
5.1. 转换算子
使用和scala的集合方法是一致的
5.1.1. map
1. 功能
用于对 RDD 中的每个元素进行映射处理,并返回处理后的结果。
-
调用后 返回的新的RDD的分区数和父RDD的分区数默认是一致的
-
repartition(2) 方法可以修改分区个数
-
RDD编程和本地scala集合编程几乎一样 , 在底层的运行上是不一样的 (分布式并行计算)
package com.doit.day0201
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/4
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test06 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Seq(1, 2, 3, 4, 5, 6, 7, 8)).repartition(3)
// 过滤出偶数
val rdd2 = rdd1.map(e=>e*10)
val rdd3 = rdd2.map(e=>e+1).repartition(2)
println(rdd1.getNumPartitions)//3
println(rdd2.getNumPartitions)//3 新的RDD的分区数和父RDD的分区数默认是一致的
println(rdd3.getNumPartitions)//2 repartition(2) 方法可以修改分区个数
sc.stop()
}
}2. 原理:
底层使用迭代器迭代数据使用传入的函数对数据一一处理, 将处理后的结果返回
多了分区 多了并行的封装, 实现了分布式运行任务
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
// 对函数做了封装 cleanF 的计算逻辑还是我们传入的f计算逻辑
val cleanF = sc.clean(f) // 闭包检测 是否可以序列化
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}1) 闭包序列化检查
在 map 方法中,首先调用了 sc.clean(f) 方法,该方法用于对传入的函数 f 进行序列化,并进行闭包检查。这是因为在分布式环境中,需要确保传入的函数能够在远程节点正确地执行,因此需要对函数进行序列化和闭包检查。
2) 封装任务
接下来,map 方法创建一个新的 MapPartitionsRDD 实例,并传入了一个匿名函数作为参数。该匿名函数表示对每个分区的数据进行处理的逻辑。在这个匿名函数中,调用了 iter.map(cleanF) 方法,对分区中的每个元素应用传入的函数 f 进行处理。
3) 并行计算
最后,MapPartitionsRDD 实例将这个处理逻辑封装成并行任务,并根据 RDD 的分区数将任务分配到不同的机器上执行。这样就实现了分布式的并行计算。
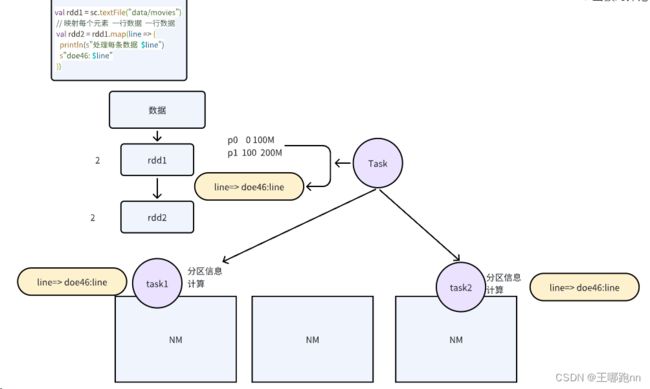
val bean = User()
// 映射每个元素 一行数据 一行数据
val rdd2 = rdd1.map(line => {
bean // 闭包引用
println(s"处理每条数据 $line")
s"doe46: $line"
})当在分布式环境中使用Spark进行数据处理时,通常会遇到需要序列化的对象。
bean 对象是一个 User 类的实例,它是一个 case class。对于 case class,默认情况下是自带序列化支持的,因此不需要额外的操作。
如果 bean 是一个普通的 class,而不是 case class,并且没有实现 Serializable 接口,那么在将其用于 Spark RDD 的操作时会报错,因为 Spark 需要将这个对象序列化并在远程节点上进行传输。解决方法通常有两种:
1. 让类实现 Serializable 接口:
class User extends Serializable {
// 类的定义
}2. 使用 case class: case class 默认是实现了 Serializable 接口的,所以无需额外的操作。

注意:
算子中的代码并不是在main线程中执行的 , 而是在远端
算子中引用的外部变量 ,闭包
算子中的代码会被封装成并行任务, 根据分区个数分配到不同的机器上实例化运行
在封装任务时, 会进行函数的闭包检测 保证序列化成功
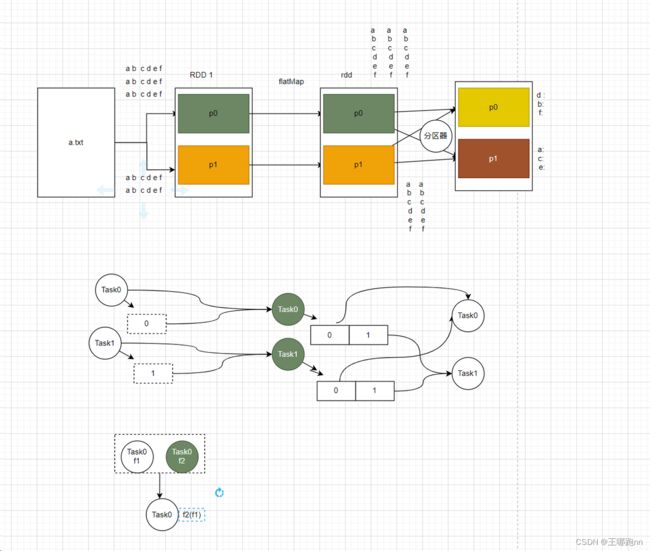
5.1.2. flatMap
完成数据的一对多的处理映射, 输入一条数据 ,处理后返回多个数据或者1个,或者没有
每个元素 ----> 返回集合 集合中可以有多个元素 , 1个元素 ,没有元素 真正输出时,自动的输出集合的每个元素
测试一:直接对字符串进行压平
package com.doit.day0201
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/5
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("hello aaa", "hello bbb"))
rdd1.flatMap(line=>line).foreach(println)
}
}结果:(字符串被压平成了一个个单个字符)

测试二:使用"-"对字符串进行切割
package com.doit.day0201
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/5
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("hello aaa", "hello bbb"))
//rdd1.flatMap(line=>line).foreach(println)
rdd1.flatMap(_.split("-")).foreach(println)
}
}结果:(由于每个字符串中并没有”-“,所以出来的就是一整个字符串作为一行

测试三:使用空格进行切割
package com.doit.day0201
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/5
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("hello aaa", "hello bbb"))
//rdd1.flatMap(line=>line).foreach(println)
//rdd1.flatMap(_.split("-")).foreach(println)
rdd1.flatMap(_.split("\\s+")).foreach(println)
}
}结果:(出来的是一个个单词)

5.1.3 filter
每个元素 ----> 条件判断 --->条件为true的元素留下
package com.doit.day0201
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/5
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test08 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("hello aaa", "hello bbb", "hello bac"))
val rdd2 = rdd1.flatMap(_.split("\\s+"))
rdd2.filter(e=>true).foreach(println) //留下所有元素
rdd2.filter(e=>{!e.startsWith("h")}).foreach(println) //只留下以h开头的单词
sc.stop()
}
}
多个行动算子上都使用了一个计算而来的RDD .这个RDD 会多次计算创建 ! 效率低 , 计算重复
可以将这个RDD缓存起来 rdd2.cache() ; 减少计算次数
5.1.4groupBy
按照指定的key(属性分组) ,可能会产生Shuffle
-
上下有任务
-
上下游任务之间分区间的数据分发, 数据的分发规则由分区器决定 ;默认分区器HashPartitioner
分区器: 决定了上下游任务之间分区间的数据分发规则
分区: 并行计算的单元 [数据信息, 计算逻辑等]
对数据进行分组 (对数据进行分区) , 一般会Shuffle
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/6
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: 计算每个城市下每种商品类别的总金额
*/
object Test01 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 读取数据文件,创建RDD
val rdd1 = sc.textFile("data/orders.txt")
// 将每行数据映射为元组(订单ID, 金额, 城市)
val rdd2 = rdd1.map(line=>{
val arr = line.split(",")
val oid = arr(0)
val money = arr(1).toDouble
val city = arr(2)
(oid,money,city)
})
// 按城市分组,得到一个元组,其中键为城市,值为包含订单信息的迭代器
val rdd3 = rdd2.groupBy(_._3)
// 对每个城市的订单信息进行处理,计算总金额,并输出结果
rdd3.map(tp=>{
val city = tp._1
val sum = tp._2.map(_._2).sum // 计算每个城市的总金额
(city,sum)
}).foreach(println)
sc.stop()
}
}
结果:

5.1.5mapPartitionWithIndex
类似mapPartitions,不同之处在于func可以接收到每个元素所属分区号
1. 方法格式
def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false): RDD[U]2.参数说明
-
f: 一个函数,接受两个参数:分区索引(Int)和一个迭代器(Iterator[T]),返回一个迭代器(Iterator[U])。这个函数将被应用于RDD的每个分区。 -
preservesPartitioning: 布尔类型,指示输出RDD是否保留原始RDD的分区方式,默认为false。
3. 功能描述
mapPartitionsWithIndex函数对RDD的每个分区都调用一次指定的函数。该函数是在每个分区的数据上运行的,因此可以在该函数内部访问分区的所有元素。此函数的返回值是一个迭代器,其中包含了对分区数据进行处理后得到的结果。
package com.doit.day0201
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/5
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: 使用Spark进行基本的RDD操作,并添加了一些注释说明
*/
object Test09 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
//.set("spark.default.parallelism", "8")
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 从文件中读取数据创建RDD
val rdd1 = sc.textFile("data/a.txt")
// 对RDD中的每一行数据进行分词,并将分词结果扁平化成单词的RDD
val rdd2: RDD[String] = rdd1.flatMap(_.split("\\s+"))
// 输出RDD的分区数
println(rdd2.getNumPartitions)
// 将RDD中的每个分区的数据与分区索引拼接成新的RDD
val rdd4 = rdd2.mapPartitionsWithIndex((p, iter) => {
iter.map(e => p + ": " + e)
})
// 遍历并打印新生成的RDD中的每个元素
rdd4.foreach(println)
// 对RDD进行分组操作,以单词作为key,相同单词的数据分到同一个组
val rdd3: RDD[(String, Iterable[String])] = rdd2.groupBy(e => e)
// 输出RDD的分区数
println(rdd3.getNumPartitions)
// 将RDD中的每个分区的数据与分区索引拼接成新的RDD
val rdd5 = rdd3.mapPartitionsWithIndex((p, iter) => {
iter.map(tp => p + ":" + tp._1)
})
// 遍历并打印新生成的RDD中的每个元素
rdd5.foreach(println)
}
}
结果:

5.1.6 sortBy
1. 按指定字段排序
对数据进行排序 , 能做到全局有序
函数 : f=>K 根据K的进行排序
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/6
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: 对RDD进行mapPartitionsWithIndex和sortBy操作,并输出结果区间有序
*/
object Test02 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 读取数据文件,创建RDD
val rdd1 = sc.textFile("data/orders.txt")
// 将每行数据映射为元组(订单ID, 金额, 城市)
val rdd2 = rdd1.map(line=>{
val arr = line.split(",")
val oid = arr(0)
val money = arr(1).toDouble
val city = arr(2)
(oid,money,city)
})
// 对RDD进行mapPartitionsWithIndex操作,输出结果区间有序
rdd2.mapPartitionsWithIndex((p,iter)=>{
iter.map(e=>p+":"+e)
}).foreach(println)
// 对RDD进行按订单ID降序排序操作
val rdd3 = rdd2.sortBy(_._1,false)
// 对排序后的RDD进行mapPartitionsWithIndex操作,输出结果区间有序
rdd3.mapPartitionsWithIndex((p,iter)=>{
iter.map(e=>p+":"+e)
}).foreach(println)
// 关闭SparkContext
sc.stop()
}
}

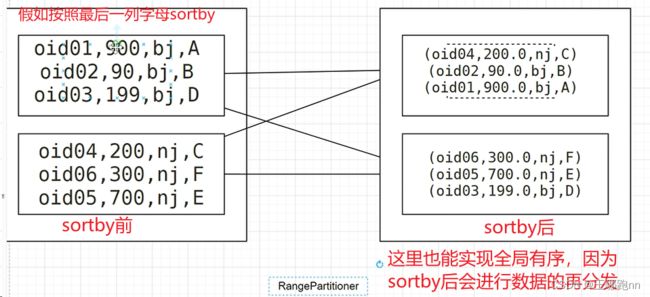
2. 支持自定义比较函数
如果排序的属性是自定义的类型比如 ordersTp.sortBy(bean=>bean) OrdersBean
1) OrdersBean本身是可排序的
2) 比较器 指定排序规则 灵活
方式1 重新排序方法
case class OrdersBean(oid:Int,money:Double,city:String) extends Ordering{
override def compare(ordersBean: OrdersBean):Int={
//城市升序,oid降序
if(city.compareTo(ordersBean.city)==0){
ordersBean.oid.compareTo(oid)
}else{
city.compareTo(ordersBean.city)
}
}
}
-----------------------------------------------------------------------
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/6
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test03 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("data/orders.txt")
val rdd2 = rdd1.map(line=>{
val arr = line.split(",")
val oid = arr(0)
val money = arr(1).toDouble
val city = arr(2)
OrdersBean(oid,money,city)
})
//按照钱的降序排列
//rdd2.sortBy(_.money,false)
//按照oid升序排列
//rdd2.sortBy(_.oid)
//按照iid升序,钱升序
//rdd2.sortBy(bean=>(bean.oid,bean.money))
//按ordersBean重写后的规则排序
//rdd2.sortBy(bean=>bean).foreach(println)
rdd2.sortBy(bean=>bean)
.mapPartitionsWithIndex((p,iter)=>{iter.map(e=>s"${p}:"+e)})
.foreach(println)
sc.stop()
}
}结果:

方式2 比较器
自定义bean本身不需要修改
case class OrdersBean(oid:String , money:Double , city:String)package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
/**
* @日期: 2024/2/6
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test03 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("data/orders.txt")
val rdd2 = rdd1.map(line => {
val arr = line.split(",")
val oid = arr(0)
val money = arr(1).toDouble
val city = arr(2)
OrdersBean(oid, money, city)
})
//按照钱的降序排列
//rdd2.sortBy(_.money,false)
//按照oid升序排列
//rdd2.sortBy(_.oid)
//按照iid升序,钱升序
//rdd2.sortBy(bean=>(bean.oid,bean.money))
//按ordersBean重写后的规则排序
//rdd2.sortBy(bean=>bean).foreach(println)
implicit val ordering = new Ordering[OrdersBean] {
override def compare(x:OrdersBean,y:OrdersBean): Int = {
//城市升序,oid降序
if (x.city.compareTo(y.city) == 0) {
y.oid.compareTo(x.oid)
} else {
x.city.compareTo(y.city)
}
}
}
rdd2.sortBy(bean => bean)
.mapPartitionsWithIndex((p, iter) => {
iter.map(e => s"${p}:" + e)
})
.foreach(println)
sc.stop()
}
}5.1.7 distinct
针对数据进行去重操作
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/7
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test04 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val rdd = sc.parallelize(List("a", "b", "c", "d", "e", "a"))
println(rdd.getNumPartitions)
println(rdd.collect().toList)
val res = rdd.distinct(2)
println(res.getNumPartitions)
println(res.collect().toList)
sc.stop()
}
}答案:

5.1.8 mapPartitions
map方法映射一条数据 , 本方法映射的整个分区的数据
在数据库里面创建orders表:
CREATE TABLE orders (
oid VARCHAR(10),
money double,
city VARCHAR(2)
);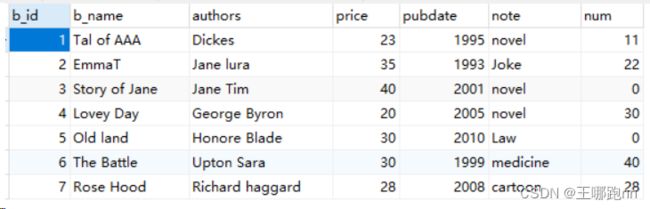
练习:将orders.txt里面的数据一条条插入order表里面
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
object Test05 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 读取文本文件并创建RDD
val rdd1 = sc.textFile("data/orders.txt")
// 对RDD进行转换,将每行数据拆分为数组,并将数组中的元素映射为元组
val rdd2 = rdd1.map(line => {
val arr = line.split(",")
val oid = arr(0)
val money = arr(1).toDouble
val city = arr(2)
(oid, money, city)
})
// 在RDD上执行操作,将数据插入MySQL数据库表中,并计算插入成功的记录数量
println(rdd2.map(tp => { //每条数据获取一次链接
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day02_test02_company", "root", "123456")
val ps = conn.prepareStatement("insert into orders values (?,?,?)")
ps.setString(1, tp._1)
ps.setDouble(2, tp._2)
ps.setString(3, tp._3)
ps.execute()
}).count())
// 在RDD上执行操作,使用mapPartitions方法将数据批量插入MySQL数据库表中,并计算插入成功的记录数量
println(rdd2.mapPartitions(iters => { //每个分区获取一次链接
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day02_test02_company", "root", "123456")
val ps = conn.prepareStatement("insert into orders values (?,?,?)")
iters.map(tp => {
ps.setString(1, tp._1)
ps.setDouble(2, tp._2)
ps.setString(3, tp._3)
ps.execute()
})
}).count())
// 停止SparkContext对象
sc.stop()
}
}
foreachPartition 行动算子直接触发执行
------------------------------------------------------------------------------------
ordersTp.foreachPartition(iters => { // 每个分区
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day02_test02_company", "root", "123456")
val ps = conn.prepareStatement("insert into orders values (?,?,?)")
iters.foreach(tp => {
ps.setString(1, tp._1)
ps.setDouble(2, tp._2)
ps.setString(3, tp._3)
ps.execute()
})
})5.1.9 groupByKey
处理的数据类型K-V的RDD
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
object Test06 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 读取文本文件并创建RDD
val rdd1 = sc.textFile("data/a.txt")
// 将每行文本按空格拆分,并扁平化为单词RDD
val rdd2 = rdd1.flatMap(_.split("\\s+"))
// 将每个单词映射为 (单词, 1) 的键值对RDD
val rdd3 = rdd2.map(tp => {
(tp, 1)
})
// 按单词进行分组,得到 (单词, Iterable[1]) 的键值对RDD
val rdd4 = rdd3.groupByKey()
// 对每个单词的 Iterable[1] 进行求和,得到 (单词, 出现次数总和) 的键值对RDD
val rdd5 = rdd4.map(tp=>{
val word = tp._1
val sum = tp._2.sum
(word,sum)
})
// 打印每个单词及其出现次数总和
rdd5.foreach(println)
// 停止SparkContext对象
sc.stop()
}
}代码:

5.1.10reduceByKey
处理的数据类型K-V的RDD
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/7
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test08 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("data/a.txt")
val rdd2 = rdd1.flatMap(_.split("\\s+"))
val rdd3 = rdd2.map(tp => {
(tp, 1)//单词,1 (a,1) (b,1) (c,1)
})
val rddd4 = rdd3.reduceByKey(_ + _) //分组,组内聚合 a <1,1,1,1>
rddd4.foreach(println)
}
}
5.1.11交集差集并集笛卡尔积
package com.doit.day0208
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/8
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test01 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val ls1=List(1,3,5,7,9)
val ls2=List(1,2,4,6,8)
//两个RDD的泛型一致
val u1: Seq[Int] =ls1.union(ls2)
println(u1.toList)//List(1, 3, 5, 7, 9, 1, 2, 4, 6, 8)
val rdd1 = sc.makeRDD(ls1)
val rdd2 = sc.makeRDD(ls2)
rdd1.union(rdd2).foreach(println)//1, 3, 5, 7, 9, 1, 2, 4, 6, 8
println("--------------")
//差集 数据类型一致 在rdd1中出现在rdd2中没有出现的元素
println(rdd1.subtract(rdd2).collect().toList) //List(3, 5, 7, 9)
//交集 在两个RDD中都出现的元素
println(rdd1.intersection(rdd2).collect().toList)//List(1)
// 4 笛卡尔积 返回关联后的结果 join
println(rdd1.cartesian(rdd2).collect().toList)//List((1,1), (1,2), (1,4), (1,6), (1,8), (3,1), (3,2), (3,4), (3,6), (3,8), (5,1), (5,2), (5,4), (5,6), (5,8), (7,1), (7,2), (7,4), (7,6), (7,8), (9,1), (9,2), (9,4), (9,6), (9,8))
}
}5.1.12 zip算子
zip算子用于将两个RDD组合成key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
package com.doit.day0208
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/8
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test02 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val ls1=List(1,3,5,7,9)
val ls2=List(2,4,6,8)
val rdd1 = sc.makeRDD(ls1,2)
val rdd2 = sc.makeRDD(ls2,2)
val rdd3 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
val rdd4 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 3)
val tuple1: Array[(Int, String)] = rdd1.zip(rdd3).collect()
println(tuple1.toList)//List((1,A), (3,B), (5,C), (7,D), (9,E))
val tuple2= rdd3.zip(rdd1).collect()
println(tuple2.toList)//List((A,1), (B,3), (C,5), (D,7), (E,9))
val tuple3= rdd4.zip(rdd1).collect()
println(tuple3.toList)
//java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions
//如果两个RDD分区数不同,则抛出异常
val tuple3= rdd3.zip(rdd2).collect()
println(tuple3.toList)
//java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions
//如果两个RDD元素格式不同,则抛出异常
}
}5.1.13 join算子
统计订单数据 : 统计每个用户的订单金额信息
用户数据 关联 订单数据
按照用户分组
统计订单总额 总个数 均价
//orders.txt
oid13,900,bj,A,1
oid14,90,bj,B,1
oid15,300,nj,F,1
oid16,700,nj,E,2
oid17,199,bj,D,3
oid18,200,nj,C,4
//user.txt
1,鹿晗
2,吴亦凡
3,江拥杰
4,段海涛
5,孙健package com.doit.day0208
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/8
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: 统计订单数据: 统计每个用户的订单金额信息 name,总额,个数,均价
*/
object Test03 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 读取订单数据和用户数据
val rdd1 = sc.textFile("Data/join/orders.txt")
val rdd2 = sc.textFile("Data/join/user.txt")
// 将订单数据映射为键值对 (id, line)
val rdd3 = rdd1.map(line => {
val arr = line.split(",")
val id = arr(4)
(id, line)
})
// 将用户数据映射为键值对 (id, name)
val rdd4 = rdd2.map(line => {
val arr = line.split(",")
val id = arr(0)
val name = arr(1)
(id, name)
})
// 对订单数据和用户数据进行连接
val rdd5: RDD[(String, (String, String))] = rdd3.join(rdd4)
// 统计每个用户的订单金额信息
val rdd6: RDD[(String, Iterable[String])] = rdd5.map(tp => {
val name = tp._2._2
val arr = tp._2._1.split(",")
(name, arr(1))
}).groupByKey()
// 计算总额、个数和均价,并输出结果
rdd6.map(tp=>{
val name = tp._1
val num = tp._2.size
val sum = tp._2.map(p => p.toDouble).sum
(name,sum,num,sum/num)
}).foreach(println)
// 关闭SparkContext
sc.stop()
}
}
结果:

5.2 行动算子
5.2.1reduce
行动算子 直接返回聚合结果
返回的结果类型和输入的数据类型一致
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/7
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List("a", "b", "c", "d", "e"), 2)
// _ 前一个元素 _ 拼接符 _ 后一个元素
println(rdd.reduce((str1, str2) => {
str1 + "_" + str2
}))
sc.stop()
}
}结果:
![]()
5.2.2aggregate
聚合算子 ,输入数据类型和返回数据类型可以不一致
aggregate 是 Spark 中用于聚合数据的一个高级函数,它允许用户在 RDD 上执行聚合操作,并且比常规的 reduce 和 fold 方法更加灵活。aggregate 方法接受三个参数:初始值、分区内聚合函数和分区间聚合函数。
def aggregate[U](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U其中:
-
zeroValue是一个初始值,它将作为每个分区的第一个聚合操作的初始值。 -
seqOp是一个函数,用于在每个分区上聚合数据。它接受两个参数,第一个参数是初始值或上一次聚合操作的结果,第二个参数是 RDD 中的元素。 -
combOp是一个函数,用于将每个分区的结果进行合并。它接受两个参数,表示两个分区的聚合结果,然后将它们合并为一个结果。
工作流程:
-
Spark 将每个分区的数据与初始值一起传递给
seqOp函数,然后在每个分区上执行聚合操作,得到每个分区的局部结果。 -
Spark 将所有分区的局部结果与初始值一起传递给
combOp函数,然后在 driver 端执行聚合操作,得到最终的全局结果。
package com.doit.day0206
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/7
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test09 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
// 计算每个分区的元素和,并将结果与初始值相加
/**
* 分区0 2d+1+2=5d
* 分区1 2d+3+4+5=14
* 2.0 + 5.0 + 14.0 = 21.0
*/
val rdd2: Double = rdd1.aggregate(2d)(_ + _, _ + _)
println(rdd2)
sc.stop()
}
}结果:

5.2.3 foreachPartition
上面的mapPartition例子也可以用foreachPartition实现
foreachPartition 行动算子直接触发执行
------------------------------------------------------------------------------------
ordersTp.foreachPartition(iters => { // 每个分区
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/day02_test02_company", "root", "123456")
val ps = conn.prepareStatement("insert into orders values (?,?,?)")
iters.foreach(tp => {
ps.setString(1, tp._1)
ps.setDouble(2, tp._2)
ps.setString(3, tp._3)
ps.execute()
})
})5.2.4 其他行动算子举例
package com.doit.day0208
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/8
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: Spark RDD行动算子示例
*/
object Test05 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 设置日志级别为WARN,减少不必要的输出信息
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// 创建两个列表
val ls1 = List(1, 7, 3, 5, 9)
val ls2 = List(2, 4, 6, 8)
// 创建两个RDD,分别将列表分布在两个分区中
val rdd1 = sc.makeRDD(ls1, 2)
val rdd2 = sc.makeRDD(ls2, 2)
// 使用行动算子进行操作
// 获取第一个元素
println(rdd1.first()) //1
// 获取前3个元素,并转换为列表
println(rdd1.take(3).toList) //1,7,3
// 获取前3个元素,并按升序排序后转换为列表
println(rdd1.takeOrdered(3).toList) //1,3,5
// 将所有元素收集到本地内存集合中(慎用,可能会占用大量内存)
println(rdd1.collect().toList)//1,7,3,5,9
// 获取RDD中的最小值
println(rdd1.min()) //1
// 获取RDD中的最大值
println(rdd1.max()) //9
// 获取RDD中所有元素的总和
println(rdd1.sum()) //25
// 迭代遍历RDD中的每个元素并打印
rdd1.foreach(println)//1,7,3,5,9
// 获取RDD中元素的个数
println(rdd1.count()) //5
// 关闭SparkContext
sc.stop()
}
}