keepalived
文章目录
- 一、Keepalived 高可用概述
-
- VRRP原理
- 二、Keepalived高可用安装配置
-
- 安装keepalived
- 配置master
- 配置backup
- 对比master与Backup的keepalived配置区别
- 启动Master和Backup节点的keepalived
- 三、高可用keepalived抢占式与非抢占式
- 四、高可用keepalived故障脑裂
-
- 脑裂故障原因
- 脑裂故障现象
- 解决脑裂故障方案
- 五、高可用keepalived与nginx
- 六、集群和分布式
-
- 集群 Cluster
- 分布式系统
- 集群和分布式
- 集群设计原则
- 集群设计实现
-
- 基础设施层面
- 业务层面
- LB Cluster 负载均衡集群
-
- 按实现方式划分
- 基于工作的协议层次划分
- 负载均衡的会话保持
- HA 高可用集群实现
一、Keepalived 高可用概述
就是对负载均衡器(lb)做主从,
一般是指2台机器启动着完全相同的业务系统,当有一台机器down机了,另外一台服务器就能快速的接管,对于访问的用户是无感知的。
硬件通常使用 F5
软件通常使用 keepalived
keepalived软件是基于VRRP协议实现的,VRRP虚拟路由冗余协议,主要用于解决单点故障问题
VRRP原理
-
VRRP协议是一种容错的主备模式的协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代替出现故障的路由器进行工作,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
-
虚拟路由器:VRRP组中所有的路由器,拥有虚拟的IP+MAC(00-00-5e-00-01-VRID)地址
-
主路由器:虚拟路由器内部通常只有一台物理路由器对外提供服务,主路由器是由选举算法产生,对外提供各种网 络功能。
-
备份路由器:VRRP组中除主路由器之外的所有路由器,不对外提供任何服务,只接受主路由的通告,当主路由器挂掉之后,重新进行选举算法接替master路由器。
-
选举机制
- 优先级
- 抢占模式下,一旦有优先级高的路由器加入,即成为Master
- 非抢占模式下,只要Master不挂掉,优先级高的路由器只能等待
-
三种状态
- Initialize状态:系统启动后进入initialize状态
- Master状态
- Backup状态
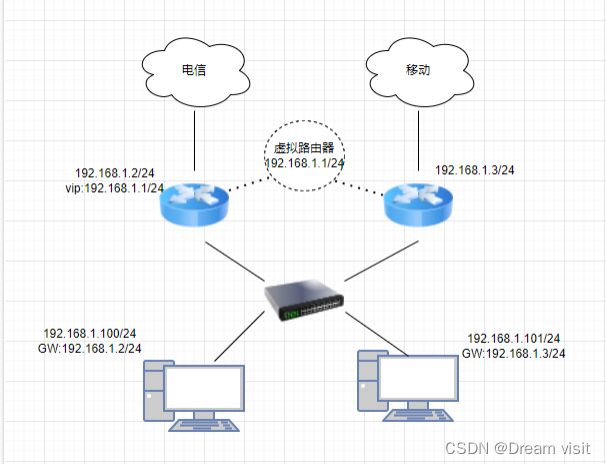
拓扑:

模拟R3为外网,R1,R2为你的两台网关路由器
R1
R1(config-if)#int e0/0
R1(config-if)#ip add 100.13.13.1 255.255.255.0
R1(config-if)#no sh
R1(config)#int e0/1
R1(config-if)#ip add 192.168.1.2 255.255.255.0
R1(config-if)#no sh
R1(config-if)#exit
R1(config)#access-list 1 per 192.168.1.0 /24
R1(config)#ip nat in so li 1 int e0/0 ov
R1(config)#int e0/0
R1(config-if)#ip nat out
R1(config-if)#int e0/1
R1(config-if)#ip nat in
R1(config)#ip route 0.0.0.0 0.0.0.0 100.13.13.3
R2
R2(config)#int e0/0
R2(config-if)#ip add 100.23.23.2 255.255.255.0
R2(config-if)#no sh
R2(config-if)#int e0/1
R2(config-if)#ip add 192.168.1.3 255.255.255.0
R2(config-if)#no sh
R2(config)#access-list 1 per 192.168.1.0 /24
R2(config)#ip nat in so li 1 int e0/0 ov
R2(config)#int e0/0
R2(config-if)#ip nat out
R2(config-if)#int e0/1
R2(config-if)#ip nat in
R2(config)#ip route 0.0.0.0 0.0.0.0 100.23.23.3
R3
R3(config)#int e0/0
R3(config-if)#ip add 100.13.13.3 255.255.255.0
R3(config-if)#no sh
R3(config-if)#int e0/1
R3(config-if)#ip add 100.23.23.3 255.255.255.0
R3(config-if)#no sh
R3(config-if)#int lo0
R3(config-if)#ip add 3.3.3.3 255.255.255.0
测试网络连通性
R1#ping 3.3.3.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds:
.!!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 1/1/2 ms
R2#ping 3.3.3.3
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 3.3.3.3, timeout is 2 seconds:
.!!!!
Success rate is 100 percent (4/5), round-trip min/avg/max = 1/1/1 ms
SW 配置dhcp:
Switch>en
Switch#conf t
Switch(config)#int vlan 1
Switch(config-if)#ip add 192.168.1.254 255.255.255.0
Switch(config-if)#no sh
Switch(config)#ip dhcp pool cisco
Switch(dhcp-config)#network 192.168.1.0 /24
Switch(dhcp-config)#default-router 192.168.1.1
Switch(dhcp-config)#ip dhcp excluded-address 192.168.1.1 192.168.1.100
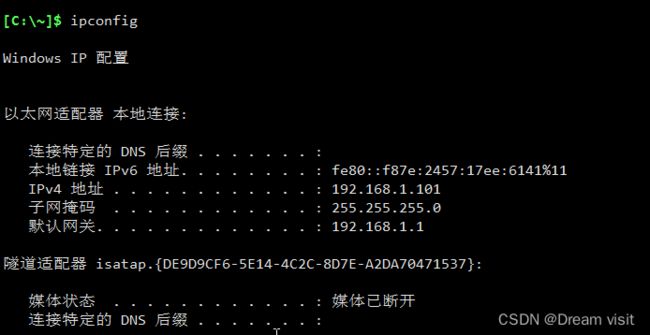
开启vrrp:
R1(config)#int e0/1
R1(config-if)#vrrp 1 ip 192.168.1.1
R2(config)#int e0/1
R2(config-if)#vrrp 1 ip 192.168.1.1
pc:
ping 192.168.1.1
arp -a
查看vrrp竞选规则
R1#show vrrp br
Interface Grp Pri Time Own Pre State Master addr Group addr
Et0/1 1 100 3609 Y Backup 192.168.1.3 192.168.1.1
R2#show vrrp br
Interface Grp Pri Time Own Pre State Master addr Group addr
Et0/1 1 100 3609 Y Master 192.168.1.3 192.168.1.1
R1(config)#int e0/1
R1(config-if)#vrrp 1 priority 110
#R1手动提升优先级
R1#show vrrp br
Interface Grp Pri Time Own Pre State Master addr Group addr
Et0/1 1 110 3570 Y Master 192.168.1.2 192.168.1.1
测试:
pc:
ping 3.3.3.3 -t
R1(config)#int e0/1
R1(config-if)#sh
R1(config-if)#int e0/0
R1(config-if)#sh
#这种情况比较坑,不会发现断了,就没有自动切换,可以利用track追踪的方式去降低优先级来实现切换主备
R1(config)#track 1 interface e0/0 line-protocol
R1(config-track)#int e0/1
R1(config-if)#vrrp 1 track 1 decrement 50
#惩罚优先级下降50
pc:
tacert 3.3.3.3
R1(config-if)#int e0/0
R1(config-if)#no sh
R1(config-if)#sh
同理也可以给R2配置上
R2(config)#track 1 interface e0/0 line-protocol
R2(config-track)#int e0/1
R2(config-if)#vrrp 1 track 1 decrement 50
二、Keepalived高可用安装配置
安装keepalived
[root@lb01 ~]# yum install -y keepalived
[root@lb02 ~]# yum install -y keepalived
配置master
- 找到配置文件
[root@lb02 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
- 修改配置
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
global_defs { #全局配置
router_id lb01 #标识身份->名称
}
vrrp_instance VI_1 {
state MASTER #标识角色状态
interface ens33 #网卡绑定接口
virtual_router_id 50 #虚拟路由id
priority 150 #优先级
advert_int 1 #监测间隔时间
#use_vmac #使用虚拟mac地址,因为路由问题,可能导致原本的IP不可用
authentication { #认证
auth_type PASS #认证方式
auth_pass 1111 #认证密码
}
virtual_ipaddress {
192.168.175.100 #虚拟的VIP地址
}
}
配置backup
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.175.100
}
}
对比master与Backup的keepalived配置区别
| Keepalived配置区别 | Master节点配置 | Backup节点配置 |
|---|---|---|
| route_id(唯一标识) | router_id lb01 | router_id lb02 |
| state(角色状态) | state MASTER | state BACKUP |
| priority(竞选优先级) | priority 150 | priority 100 |
启动Master和Backup节点的keepalived
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# systemctl enable keepalived
ip a #观察虚拟ip有没有
[root@lb02 ~]# systemctl start keepalived
[root@lb02 ~]# systemctl enable keepalived
三、高可用keepalived抢占式与非抢占式
- 由于节点1的优先级高于节点2,所以VIP在节点1上面,记得关闭防火墙selinux,否则会发现两个上都有vip
[root@lb01 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
- 关闭节点1的keepalived
[root@lb01 ~]# systemctl stop keepalived
- 节点2联系不上节点1,主动接管VIP
[root@lb02 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
- 此时重新启动Master上的keepalived,会发现VIP被强行抢占
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
- 配置非抢占式
- 两个节点的state都必须配置为BACKUP
- 两个节点都必须加上配置 nopreempt
- 其中一个节点的优先级必须要高于另外一个节点的优先级。
- 两台服务器都角色状态启用nopreempt后,必须修改角色状态统一为BACKUP,唯一的区分就是优先级。
Master配置
vrrp_instance VI_1 {
state BACKUP #修改为BACKUP
priority 150
nopreempt #加上这行
}
Backup配置
vrrp_instance VI_1 {
state BACKUP
priority 100
nopreempt #加上这行
}
systemctl restart keepalived
- 通过windows的arp去验证,是否会切换MAC地址
# 当前master在lb01上
[root@lb01 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
# windows查看mac地址
C:\Users\Aaron>arp -a |findstr 192.168.175.100
192.168.175.100 00-0c-29-bb-9a-49 动态
- 关闭lb01的keepalive
[root@lb01 ~]# systemctl stop keepalived
- lb02接管vIP
[root@lb02 ~]# ip addr |grep 192.168.175.100
inet 192.168.175.100/32 scope global ens33
- 再次查看windows的mac地址
C:\Users\Aaron>arp -a |findstr 192.168.175.100
192.168.175.100 00-0c-29-bb-9a-bb 动态
- 看到的是两次mac地址发生了变化,因为虚拟机的bug,无法实现ma地址不变,正常情况下开启use_vmac使用虚拟的mac地址后mac地址不会发生改变
四、高可用keepalived故障脑裂
由于某些原因,导致两台keepalived高可用服务器在指定时间内,无法检测到对方的心跳,各自取得资源及服务的所有权,而此时的两台高可用服务器又都还活着。
脑裂故障原因
- 服务器网线松动等网络故障
- 服务器硬件故障发生损坏现象而崩溃
- 主备都开启firewalld防火墙
脑裂故障现象
- 正常情况下backup以监听为主,所以抓包会看到只有master在发送vrrp的数据包

- 打开设备的防火墙,查看抓包情况,可以看到两台设备认为自己是master

[root@lb01 ~]# ip a |grep 192.168.175.100
inet 192.168.175.100/24 scope global secondary ens33
[root@lb02 ~]# ip a |grep 192.168.175.100
inet 192.168.175.100/24 scope global secondary ens33
解决脑裂故障方案
- 如果发生闹裂,则随机kill掉一台即可
- 在backup上编写检测脚本, 测试如果能ping通master并且backup节点还有vIP的话则认为产生了脑裂
[root@lb02 ~]# vim check_split_brain.sh
#!/bin/sh
vip=192.168.175.100
lb01_ip=192.168.175.10
while true;do
ping -c 2 $lb01_ip &>/dev/null
if [ $? -eq 0 -a `ip add|grep "$vip"|wc -l` -eq 1 ];then
echo "ha is split brain.warning."
# systemctl stop keepalived
else
echo "ha is ok"
fi
sleep 5
done
测试:
在lb02运行好脚本后再打开lb02的防火墙,这时与lb01连接不上发生脑裂,脚本开始报错
五、高可用keepalived与nginx
Nginx默认监听在所有的IP地址上,VIP会飘到一台节点上,相当于那台nginx多了VIP这么一个网卡,所以可以访问到nginx所在机器
但是…如果nginx宕机,会导致用户请求失败,但是keepalived没有挂掉不会进行切换,所以需要编写一个脚本检测Nginx的存活状态,如果不存活则kill掉keepalived
- 先给两台机器都装上nginx
yum install -y epel-release
yum install -y nginx
systemctl enable nginx --now
lb01:
echo "in lb01" > /usr/share/nginx/html/index.html
lb02:
echo "in lb02" > /usr/share/nginx/html/index.html
访问192.168.175.100的效果就是in lb01,但是如果关闭lb01的keepalived,就变成in lb02
但是如果nginx挂了,网页将会无法正常访问
- 用脚本解决nginx挂了vip没有切换的问题
[root@lb01 ~]# vim check_web.sh
#!/bin/sh
nginxpid=$(ps -C nginx --no-header|wc -l)
#1.判断Nginx是否存活,如果不存活则尝试启动Nginx
if [ $nginxpid -eq 0 ];then
systemctl start nginx
sleep 3
#2.等待3秒后再次获取一次Nginx状态
nginxpid=$(ps -C nginx --no-header|wc -l)
#3.再次进行判断, 如Nginx还不存活则停止Keepalived,让地址进行漂移,并退出脚本
if [ $nginxpid -eq 0 ];then
systemctl stop keepalived
fi
fi
[root@lb01 ~]# watch -n 5 "sh /root/check_web.sh"
六、集群和分布式
系统性能扩展方式:
- Scale UP:垂直扩展,向上扩展,增强,性能更强的计算机运行同样的服务,成本高。
- Scale Out:水平扩展,向外扩展,增加设备,并行地运行多个服务调度分配问题,Cluster
垂直扩展不再提及:
- 随着计算机性能的增长,其价格会成倍增长
- 单台计算机的性能是有上限的,不可能无限制地垂直扩展
- 多核CPU意味着即使是单台计算机也可以并行的。
集群 Cluster
Cluster:集群,为解决某个特定问题将多台计算机组合起来形成的单个系统
Cluster分为三种类型:
-
LB:Load Balancing,负载均衡。调度负载,按照算法调度。
-
HA:High Availiablity,高可用,避免SPOF(single Point Of failure)(单点失败)
- MTBF:Mean Time Between Failure 平均无故障时间
- MTTR:Mean Time To Restoration( repair)平均恢复前时间
- A=MTBF/(MTBF+MTTR) (0,1):99%,99.5%,99.9%,99.99%,99.999%
-
HPC:High-performance computing,高性能 www.top500.org
分布式系统
分布式存储: Ceph,GlusterFS,FastDFS,MogileFS
分布式计算:hadoop,Spark
分布式常见应用
分布式应用-服务按照功能拆分,使用微服务
分布式静态资源–静态资源放在不同的存储集群上
分布式数据和存储–使用key-value缓存系统
分布式计算–对特殊业务使用分布式计算,比如Hadoop集群
集群和分布式
集群:同一个业务系统,部署在多台服务器上。集群中,每一台服务器实现的功能没有差别,数据和代码都是一样的
分布式:一个业务被拆成多个子业务,或者本身就是不同的业务,部署在多台服务器上。分布式中,每一台服务器实现的功能是有差别的,数据和代码也是不一样的,分布式每台服务器功能加起来,才是完整的业务。
分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
对于大型网站,访问用户很多,实现一个群集,在前面部署一个负载均衡服务器,后面几台服务器完成同一业务。如果有用户进行相应业务访问时,负载均衡器根据后端哪台服务器的负载情况,决定由给哪一台去完成响应,并且一台服务器垮了,其它的服务器可以顶上来。分布式的每一个节点,都完成不同的业务,如果一个节点垮了,那这个业务可能就会失败。
集群设计原则
可扩展性—集群的横向扩展能力。小型机横向扩展小,面临淘汰
可用性—无故障时间(SLA)
性能—访问响应时间
容量—单位时间内的最大并发吞吐量(C10K 并发问题) 。LVS内核级,并发好。
集群设计实现
基础设施层面
提升硬件资源性能—从入口防火墙到后端web server均使用更高性能的硬件资源
多域名—DNS 轮询A记录解析。指向不同IP 访问入口增多
多入口—将A记录解析到多个公网IP入口
多机房—同城+异地容灾
CDN(Content Delivery Network)—基于GSLB(Global Server Load Balance)实现全局负载均衡,如:DNS
就近分配地址,提高效率
业务层面
分层:安全层、负载层、静态层、动态层、(缓存层、存储层)持久化与非持久化
分割:基于功能分割大业务为小服务
分布式:对于特殊场景的业务,使用分布式计算
LB Cluster 负载均衡集群
按实现方式划分
-
硬件(大公司)
- F5 Big-IP
- Citrix Netscaler
- A10
-
软件(小公司)
- lvs:Linux Virtual Server,阿里四层SLB (Server Load Balance)使用下四层功能:物理层 数据链路层
- nginx:支持七层调度,阿里七层SLB使用Tengine
- haproxy:支持七层调度
- ats:Apache Traffic Server,yahoo捐助给apache
- perlbal:Perl 编写
- pound
基于工作的协议层次划分
-
传输层(通用):DNAT和DPORT
- LVS:Linux Virtual Server
- nginx:stream
- haproxy:mode tcp
-
应用层(专用):针对特定协议,常称为 proxy server
- http:nginx, httpd, haproxy(mode http), …
- fastcgi:nginx, httpd, …
- mysql:mysql-proxy, …
负载均衡的会话保持
-
session sticky:同一用户调度固定服务器
- Source IP:LVS sh算法(对某一特定服务而言)
- Cookie
-
session replication:每台服务器拥有全部session
- session multicast cluster (内存消耗大)
-
session server:专门的session服务器
-
Memcached,Redis (只放session,共享)也存在单点失败,即也要做集群哨兵机制
HA 高可用集群实现
keepalived:vrrp协议
Ais:应用接口规范
heartbeat
cman+rgmanager(RHCS)
coresync_pacemaker