flink on yarn
文章目录
-
- 使用
-
- flink sql client on yarn
-
- session 模式
- Per-Job Cluster 模式
- flink run
- flink run application -t yarn-application
-
- 配置任务退出时保留Checkpoint
- 从外部checkpoint恢复应用
- 资料
使用
安装完hadoop 3.3.4之后,启动hadoop、yarn
将flink 1.14.6上传到各个服务器节点,解压
flink sql client on yarn
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/overview/

Application Mode
为每一个应用启动一个集群,应用运行在JM上(由JM来执行应用中的main()方法),应用结束,集群关闭。
为每个应用程序创建一个集群可以看作是创建一个仅在特定应用程序的作业之间共享的会话集群,并在应用程序完成时关闭。
在应用粒度上提供了与Per-Job Mode一样的资源隔离和负载均衡保证。
与Per-Job(已弃用)模式相比,Application Mode允许提交包含多个作业的应用程序。作业执行的顺序不受部署模式的影响,但是会受启动作业的调用方式影响。调用execute(),一个作业会被阻塞,直到上一个作业完成后,才会开始。
executeAsync()是非阻塞的,上一个作业未结束时,当前作业也可以执行。
Per-Job Mode (Flink 1.15 中已弃用)
依赖外部资源管理框架(比如Yarn),为每一个应用启动一个集群。这个集群仅服务于该应用,应用结束,集群占用的资源也将被释放
Session Mode
会话模式假定一个已经在运行的集群并使用该集群的资源来执行任何提交的应用程序。在同一(会话)集群中执行的应用程序使用并因此竞争相同的资源。这样做的好处是您无需为每个提交的作业支付启动完整集群的资源开销。但是,如果其中一个作业行为不当或导致 TaskManager 崩溃,则在该 TaskManager 上运行的所有作业都将受到故障的影响。这除了对导致失败的作业产生负面影响外,还意味着一个潜在的大规模恢复过程,所有重新启动的作业同时访问文件系统并使其对其他服务不可用。此外,让一个集群运行多个作业意味着 JobManager 有更多的负载
Flink sql client 1.14中可以使用session 模式和per-job模式,application 模式暂时还不支持
session 模式
Session 模式下,需要先执行一下命令启动 Yarn Session
./bin/yarn-session.sh -d
-d为后台运行
Yarn Session 启动成功后,会创建一个/tmp/.yarn-properties-root文件,记录最近一次提交到 Yarn 的 Application ID,执行以下命令启动 SQL 客户端命令行界面,后续指定的 Flink SQL 会提交到之前启动的 Yarn Session Application。
./bin/sql-client.sh embedded -s yarn-session
可以执行以下命令停止当前启动的 Yarn Session。
cat /tmp/.yarn-properties-root | grep applicationID | cut -d'=' -f 2 | xargs -I {} yarn application -kill {}
Per-Job Cluster 模式
Per-Job Cluster 模式无需提前启动集群,可以在启动 SQL 客户端命令行界面,设置execution.target,后续提交的每一个 Flink SQL 任务将会作为独立的任务提交到 Yarn。
./bin/sql-client.sh embedded
Flink SQL> set execution.target=yarn-per-job;
[INFO] Session property has been set.
也可以通过在flink-conf.yaml文件预定义配置改参数。
# flink-conf.yaml
execution.target: yarn-per-job
flink run
官方文档
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/resource-providers/yarn/
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
发现提示说找不到yarn相关的class
于是在系统环境变量中配置
export HADOOP_CLASSPATH=`hadoop classpath`
这个变量是通过执行hadoop classpath这个shell命令来获取hadoop环境变量,所以需要设置好hadoop的系统环境变量
# hadoop home
export HADOOP_HOME=/opt/hadoop/hadoop-3.3.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
# flink
export HADOOP_CLASSPATH=`hadoop classpath`
继续执行命令
./bin/flink run -t yarn-per-job --detached ./examples/streaming/TopSpeedWindowing.jar
又出现如下报错
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloade r.check-leaked-classloader'.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ens ureInner(FlinkUserCodeClassLoaders.java:164)
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.get Resource(FlinkUserCodeClassLoaders.java:183)
at org.apache.hadoop.conf.Configuration.getResource(Configuration.java:2830)
at org.apache.hadoop.conf.Configuration.getStreamReader(Configuration.java:3104)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3063)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:3036)
at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2914)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2896)
at org.apache.hadoop.conf.Configuration.get(Configuration.java:1246)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1863)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1840)
at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183)
at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145)
at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)
解决方法:
禁用类加载器检查
./bin/flink run -t yarn-per-job --detached
-Dclassloader.check-leaked-classloader=false
./examples/streaming/TopSpeedWindowing.jar
问题原因:https://blog.csdn.net/weixin_52918377/article/details/123551809
查看yarn,可以看到两次提交的任务,上面的异常好像不会影响任务运行

flink run application -t yarn-application
作用:已yarn-application mode向yarn提交应用
完整命令:
./bin/flink run-application -t yarn-application \
-Dclassloader.check-leaked-classloader=false \
-c com.delta.java.cdc.Demo_Postgresql_CDC \
/opt/flink/jar/stream-computing-1.0-SNAPSHOT.jar
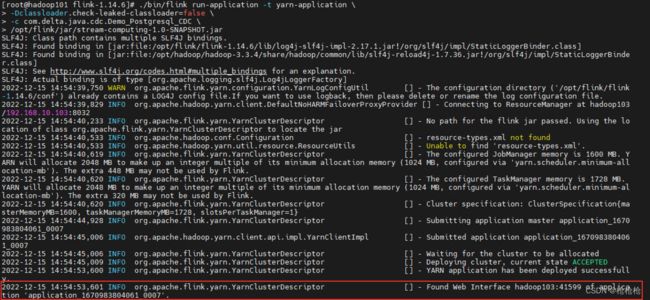
在最后一行可以看到应用的容器ID和对应的应用web 页面
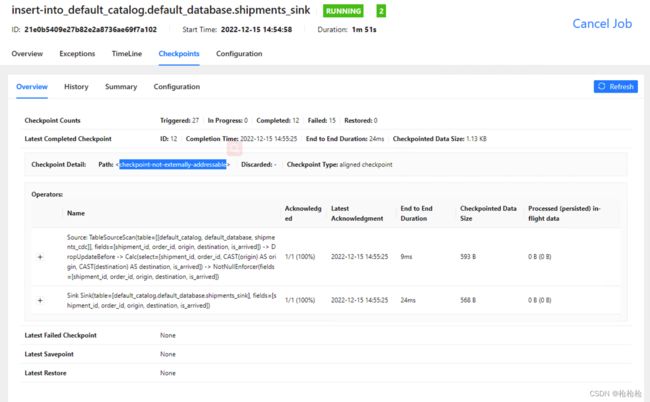
checkpoint mode默认是Exactly once
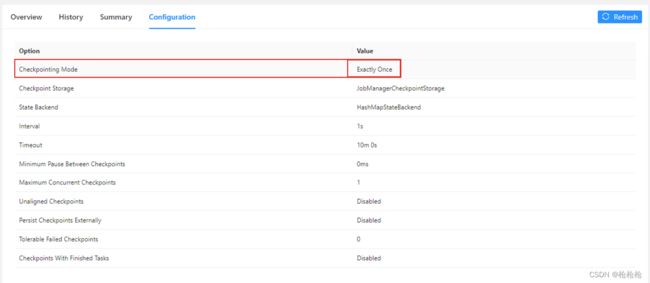
配置任务退出时保留Checkpoint
在代码中添加
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
设置stateBackend为FsStateBackend,并设置hdfs路径
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:8020/flink/checkpoints",true));
再次提交任务,可以看到外部checkpoint路径

checkpoint storage已经切换到FsStateBackend
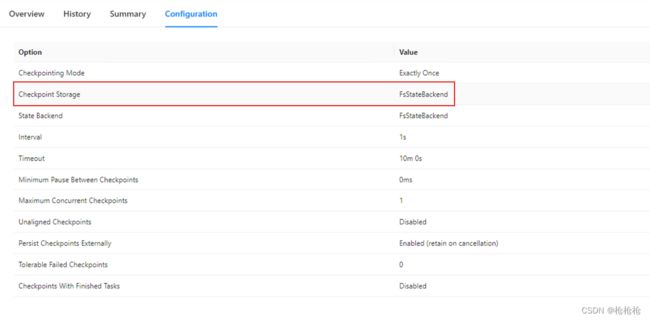
从外部checkpoint恢复应用
避免再次全量拉取源表数据
使用-s 参数指定要恢复的checkpoint 或 savepoint路径
./bin/flink run-application -t yarn-application \
-Dclassloader.check-leaked-classloader=false \
-s hdfs://hadoop101:8020/flink/checkpoints/c48cad7406f6e90c750f3b305efc6fa0/chk-2939 \
-c com.delta.java.cdc.Demo_Postgresql_CDC \
/opt/flink/jar/stream-computing-1.0-SNAPSHOT.jar \
--labbel-prefix shipments_cdc_demo_2
任务重新启动后可以看到如下的信息
chk-[num]是随着checkpoint的不断进行,逐渐递增的
目前来看,checkpoint的路径和应用的对应关系需要手动寻找,后期可以考虑在路径中根据应用的类别添加一些内容,方便快速区分路径

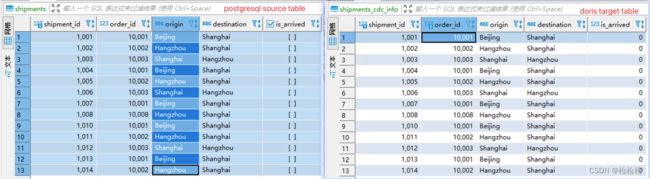
查看数据库表,通过在postgresql source table中进行增删改操作,均自动同步到了doris targe table中
实验目的达成
资料
FLINK-状态管理-配置checkpoint
flink 命令行提交jar时,传入自定义的参数或配置文件,任务运行时获取参数
Flink提交jar(带依赖)出现找不到类NoClassDefFoundError+ClassNotFoundException、类冲突NoMatching…,的解决办法
flink State 和 checkpoint,重启策略 原理详解
【Flink系列一】Flink开启Checkpoint,以及从Checkpoint恢复