高性能异步io机制:io_uring
io_uring 是 linux 内核 5.10 引入的异步 io 接口。相比起用户态的DPDK、SPDK,io_uring 作为内核的一部分,通过 mmap 的方式实现用户和内核共享内存,并基于 memory barrier 在这块内存上实现了两个无锁环形队列: submission queue ring(sq) 和 completion queue ring(cq)。 sq 用于用户程序向内核提交 IO 任务,内核执行完成的任务会放入cq,用户程序从 cq 获取结果。在提交任务和返回任务结果时,用户程序和内核共用环形队列中的数据,不再需要额外的数据拷贝。此外,io_uring 还提供了两种轮询 Polling 模式,可以避免提交任务时的系统调用,以及io完成后的中断通知。
1、性能测试
1.1、FIO
iops 是指单位时间内系统能处理的I/O请求数量,用于存储设备性能测试。这里我们使用硬盘性能辅助测试工具 FIO,来直观感受异步 io: io_uring 的性能优势。
# 安装 fio
sudo apt install fio
# 运行方式
fio job_file需要通过编写一个配置文件来预定义 FIO 将要以什么样的模式来执行任务。
FIO 的基本参数:
- rw readwrite:定义 IO 类型。随机读 randread、随机写 randwrite、顺序读 read、顺序写 write、顺序读写 rw readwrite ,随机混合读写 randrw
- bs, blocksize:IO 的块大小。默认 4k
- size: IO 传输的数据大小
- ioengine:IO 引擎。同步模式psync、异步模式io_uring
- iodepth:I/O 引擎若使用异步模式,保持队列深度
- direct: 是否使用非缓冲 io ,默认 false 缓冲 io
编写的 posix.fio 配置文件如下
[global]
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
runtime=10
bs=16K
size=16384
iodepth=64
rw=randwrite
filename=Cat
ioengine=io_uring
[test]
stonewall
description="variable bs"实验结果:iops:psync 8k, io_uring 19.0k,由此可以看出异步 io 的性能优势。
1.2、rust_echo_benc
服务器性能测试方法
- 连接数
- 每个请求连接的大小
- 持续时间
epoll 与 io_uring 事件的区别
- epoll 设置完后,不更改。
- io_uring 设置一次,触发一次。
接下来,进行同步 epoll 与异步 io_uring 服务器的测试对比,代码见 liburing 测试代码
# 安装 rust_echo_benc
git clone https://github.com/haraldh/rust_echo_bench.git
cargo run --release
# 测试
cargo run --release -- --address "127.0.0.1:9999" --number 1000 --duration 60 --length 512实验结果:在网络 io 方面,io_uring并不明显。在磁盘 io 方面,io_uring 具有一定的优势。
2、io_uring
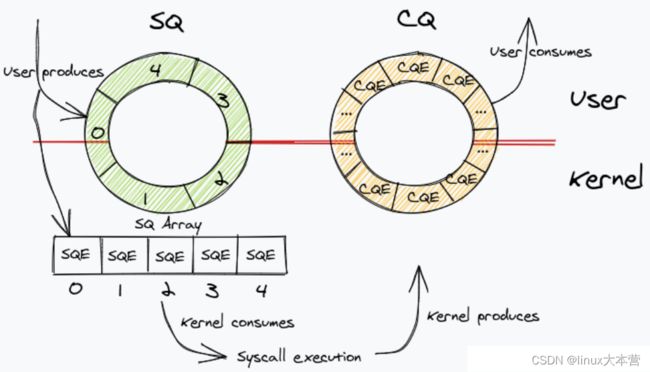
io_uring 提供了三个系统调用接口 io_uring_setup、io_uring_enter、io_uring_register
2.1、io_uring_setup
在 kernel 中创建:
- 提交队列 SQ:里面每一项是 sqe(submission queue event),描述1个任务
- 完成队列 CQ:里面每一项是 cqe(completion queue event),描述1个任务返回结果
- 提交队列项 SQEs 数组(Submission Queue Entries)
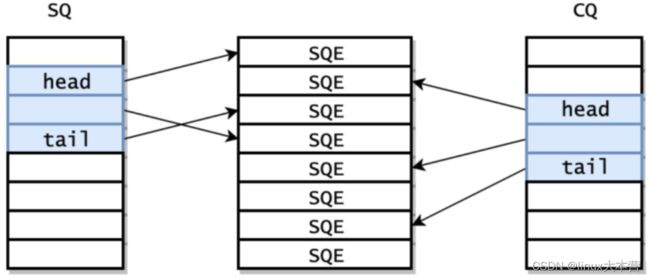
SQ 和 CQ 采用 Ringbuffer 的结构,有 head 和 tail 两个成员,head = tail 时队列为空。每个节点保存的是 SQEs 数组的偏移量,实际的请求保存在 SQEs 数组中,这样就可以批量提交一组 SQEs 上不连续的请求。SQ 和 CQ 本身没有提供锁等同步机制,向 SQ中放入 sqe,从 CQ 中取出 cqe,都需要通过 memory barrier 来实现。
函数返回1个 fd 用于 io_uring 管理。用户将 fd 以 mmap 的方式映射到内存,实现了用户态和内核态的共享内存。
/*
- 参数1 entries:期望的 sq 长度。默认cq长度是sq的两倍
- 参数2 params: 配置io_uring,内核返回的 sq/cq 配置信息也通过它带回来
*/
int io_uring_setup(unsigned entries, struct io_uring_params *params)
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 resv[5];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};相关视频推荐
io管理只有epoll吗,io_uring是不是更好的选择
linux多线程之epoll原理剖析与reactor原理及应用
epoll实战揭秘-支撑亿级IO的底层基石
学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

2.2、io_uring_enter
调用时,执行两个操作
- 提交 IO 请求:把 sqe 的索引尾插到 SQ 中,调用io_uring_enter提交到内核
- 等待 IO 完成:内核将完成的 IO 放到 CQ 中,用户轮询 CQ 来等待结果
/*
- 参数1 fd:io_uring_setup返回的fd
- 参数2 to_submit: 一次提交多少个 sqe 到内核
- 参数3 min_complete: 要求内核至少等待min_complete个任务完成再返回
- 参数4 flags:接口控制行为,IORING_ENTER_GETEVENTS
*/
int io_uring_enter(unsigned int fd, u32 to_submit, u32 min_complete, u32 flags);2.3、io_uring_register
注册用于异步 I/O 的文件或用户缓冲区
对于文件, 保持内核长时间持有该文件的索引。每次通过 sqe 向内核传递一个 fd,内核都需要通过 fd 找到对应的文件索引,完成该sqe 处理后,则将该索引释放。对于高 iops 的场景,这个开销会拖慢请求的速度。通过预先注册一组已经打开的文件。
对于缓冲区,保持内存的长期映射。内核在读写前进行page map,读写完成后,执行unmap。类似的,通过预注册,来避免多次的 map 和 unmap。
/*
- 参数1 fd:io_uring_setup返回的fd
- 参数2 opcode: 注册类型。
文件类型: IORING_REGISTER_FILES;
用户缓冲类型 buffer: IORING_REGISTER_BUFFERS
- 参数3 arg:
文件类型: 指向一个fd数组;
用户缓冲类型:指向一个struct iovec的数组。
- 参数4 nr_args:arg数组的长度
*/
int io_uring_register(unsigned int fd, unsigned int opcode,
void *arg, unsigned int nr_args);2.4、使用方法:cat 程序为例
接下来,基于 io_uring 的系统调用接口进行封装,实现自定义的 uring_cat 程序
// gcc -o uring_cat uring_cat.c
// ./uring_cat filename
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define URING_QUEUE_DEPTH 1024
#define BLOCK_SZ 1024
// sqring
struct app_io_sq_ring {
unsigned *head;
unsigned *tail;
unsigned *ring_mask;
unsigned *ring_entries;
unsigned *flags;
unsigned *array;
};
// cqring
struct app_io_cq_ring {
unsigned *head;
unsigned *tail;
unsigned *ring_mask;
unsigned *ring_entries;
struct io_uring_cqe *cqes;
};
// 提交器: cq, sq, sqe
struct submitter {
int ring_fd;
struct app_io_sq_ring sq_ring;
struct app_io_cq_ring cq_ring;
struct io_uring_sqe *sqes;
};
-------------------
struct file_info {
off_t file_sz;
struct iovec iovecs[];
};
-------------------
// 利用系统调用执行 io_uring_setup 流程
// 1、int 0x80 中断信号
// 2、mv arg1, eax
// 3、mv arg2, ebx
// 4、call sys_call_table: sys_call_table[__NR_io_uring_setup]
int io_uring_setup(unsigned entries, struct io_uring_params *p)
{
return (int) syscall(__NR_io_uring_setup, entries, p);
}
int io_uring_enter(int ring_fd, unsigned int to_submit,
unsigned int min_complete, unsigned int flags)
{
return (int) syscall(__NR_io_uring_enter, ring_fd, to_submit, min_complete,
flags, NULL, 0);
}
int app_setup_uring(struct submitter *s) {
struct io_uring_params p;
memset(&p, 0, sizeof(p));
// 创建sq, cq, sqes
s->ring_fd = io_uring_setup(URING_QUEUE_DEPTH, &p);
if (s->ring_fd < 0) return -1;
// 获取初始的sq,cq的大小,sq_off, cq_off起始偏移地址
int sring_sz = p.sq_off.array + p.sq_entries * sizeof(unsigned);
int cring_sz = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe);
// io_uring特性:IORING_FEAT_SINGLE_MMAP:内核通过一次mmap完成sq, cq的映射
// 即sq,cq共用1块内存,则两者大小必须设置相同
if (p.features & IORING_FEAT_SINGLE_MMAP) {
if (cring_sz > sring_sz) {
sring_sz = cring_sz;
}
cring_sz = sring_sz;
}
// 1、将 sq 的映射到用户空间,sq_ptr 指向sq首地址
void *sq_ptr = mmap(0, sring_sz, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE,
s->ring_fd, IORING_OFF_SQ_RING);
if (sq_ptr == MAP_FAILED) return -1;
// 2、将 cq 的映射到用户空间,cq_ptr 指向cq首地址
void *cq_ptr;
// 若共用一块内存,则两个指针指向相同
if (p.features & IORING_FEAT_SINGLE_MMAP) {
cq_ptr = sq_ptr;
} else {
// 若使用两块内存,则重新对cq进行mmap,
cq_ptr = mmap(0, sring_sz, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE,
s->ring_fd, IORING_OFF_CQ_RING);
if (cq_ptr == MAP_FAILED) return -1;
}
struct app_io_sq_ring *sring = &s->sq_ring;
struct app_io_cq_ring *cring = &s->cq_ring;
sring->head = sq_ptr + p.sq_off.head;
sring->tail = sq_ptr + p.sq_off.tail;
sring->ring_mask = sq_ptr + p.sq_off.ring_mask;
sring->ring_entries = sq_ptr + p.sq_off.ring_entries;
sring->flags = sq_ptr + p.sq_off.flags;
sring->array = sq_ptr + p.sq_off.array;
// 3、将 seqs 映射到用户空间
s->sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe),
PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, s->ring_fd, IORING_OFF_SQES);
if (s->sqes == MAP_FAILED) {
return 1;
}
cring->head = cq_ptr + p.cq_off.head;
cring->tail = cq_ptr + p.cq_off.tail;
cring->ring_mask = cq_ptr + p.cq_off.ring_mask;
cring->ring_entries = cq_ptr + p.cq_off.ring_entries;
cring->cqes = cq_ptr + p.cq_off.cqes;
return 0;
}
off_t get_file_size(int fd) {
struct stat st;
if(fstat(fd, &st) < 0) {
perror("fstat");
return -1;
}
if (S_ISBLK(st.st_mode)) {
unsigned long long bytes;
if (ioctl(fd, BLKGETSIZE64, &bytes) != 0) {
perror("ioctl");
return -1;
}
return bytes;
} else if (S_ISREG(st.st_mode))
return st.st_size;
return -1;
}
void output_to_console(char *buf, int len) {
while (len--) {
fputc(*buf++, stdout);
}
}
void read_from_cq(struct submitter *s) {
struct file_info *fi;
struct app_io_cq_ring *cring = &s->cq_ring;
struct io_uring_cqe *cqe;
unsigned head = *cring->head;
while (1) {
//read_barrier();
if (head == *cring->tail) break;
cqe = &cring->cqes[head & *s->cq_ring.ring_mask];
fi = (struct file_info*)cqe->user_data;
if (cqe->res < 0) {
fprintf(stderr, "Error: %d\n", cqe->res);
}
int blocks = fi->file_sz / BLOCK_SZ;
if (fi->file_sz % BLOCK_SZ) blocks ++;
int i = 0;
while (++i < blocks) {
output_to_console(fi->iovecs[i].iov_base, fi->iovecs[i].iov_len);
printf("------------------------i : %d, blocks: %d\n", i, blocks);
}
head ++;
printf("head: %d, tail: %d, blocks: %d\n",
head, *cring->tail, blocks);
}
*cring->head = head;
printf("exit read_from_cq\n");
//write_barrier();
}
int submit_to_sq(char *file_path, struct submitter *s) {
int filefd = open(file_path, O_RDONLY);
if (filefd < 0) {
return -1;
}
struct app_io_sq_ring *sring = &s->sq_ring;
off_t filesz = get_file_size(filefd);
if (filesz < 0) return -1;
off_t bytes_remaining = filesz;
int blocks = filesz / BLOCK_SZ;
if (filesz % BLOCK_SZ) blocks ++;
struct file_info *fi = malloc(sizeof(struct file_info) + sizeof(struct iovec) * blocks);
if (!fi) return -2;
fi->file_sz = filesz;
unsigned current_block;
while (bytes_remaining) {
off_t bytes_to_read = bytes_remaining;
if (bytes_to_read > BLOCK_SZ) bytes_to_read = BLOCK_SZ;
fi->iovecs[current_block].iov_len = bytes_to_read;
void *buf;
if (posix_memalign(&buf, BLOCK_SZ, BLOCK_SZ)) {
return 1;
}
fi->iovecs[current_block].iov_base = buf;
current_block ++;
bytes_remaining -= bytes_to_read;
}
unsigned next_tail = 0, tail = 0, index = 0;
next_tail = tail = *sring->tail;
next_tail ++;
index = tail & *s->sq_ring.ring_mask;
struct io_uring_sqe *sqe = &s->sqes[index];
sqe->fd = filefd;
sqe->flags = 0;
sqe->opcode = IORING_OP_READV;
sqe->addr = (unsigned long)fi->iovecs;
sqe->len = blocks;
sqe->off = 0;
sqe->user_data = (unsigned long long)fi;
sring->array[index] = index;
tail = next_tail;
if (*sring->tail != tail) {
*sring->tail = tail;
}
int ret = io_uring_enter(s->ring_fd, 1, 1, IORING_ENTER_GETEVENTS);
if (ret < 0) {
return 1;
}
return 0;
}
int main(int argc, char *argv[]) {
struct submitter *s = malloc(sizeof(struct submitter));
if (!s) {
perror("malloc");
return -1;
}
memset(s, 0, sizeof(struct submitter));
// 1、setup
if (app_setup_uring(s)) return 1;
int i = 1;
for (i = 1;i < argc;i ++) {
// 2、submit
if (submit_to_sq(argv[i], s)) {
//fprintf(stderr, "Error reading file\n");
return 1;
}
read_from_cq(s);
}
return 0;
} 3、liburing
由于 io_uring 使用起来比较麻烦,作者封装了 io_uring 接口,创作了 liburing 库。
# 安装 liburing
git clone https://github.com/axboe/liburing.git
./configure
make && make install3.1、liburing api
// 初始化io_uring,内部调用io_uring_setup
int io_uring_queue_init_params(unsigned entries, struct io_uring *ring,
struct io_uring_params *p);
// 提交 sq 到内核,内核完成后移动到 cq,内部调用 io_uring_enter
// 1、提交io请求:将sqe的偏移信息加入到sq,提交sq到内核,不阻塞等待其完成
// 2、等待io完成:内核在io完成后,自动将sqe的偏移信息加入到cq
int io_uring_submit(struct io_uring *ring);
// 等待io完成,获取cqe
// 阻塞等待
unsigned io_uring_peek_batch_cqe(struct io_uring *ring,
struct io_uring_cqe **cqes, unsigned count);
// 不阻塞等待
int io_uring_wait_cqes(struct io_uring *ring, struct io_uring_cqe **cqe_ptr,
unsigned wait_nr, struct __kernel_timespec *ts,
sigset_t *sigmask);
// 轮询 cq 队列,将 cq 队首后移动 nr 个
static inline void io_uring_cq_advance(struct io_uring *ring, unsigned nr)
// 和libaio封装的io_prep_writev一样
static inline void io_uring_prep_writev(struct io_uring_sqe *sqe, int fd,const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 和libaio封装的io_prep_readv一样
static inline void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd, const struct iovec *iovecs, unsigned nr_vecs, off_t offset)
// 销毁 io
void io_uring_queue_exit(struct io_uring *ring);3.2、测试代码
利用 liburing 编写的简单测试 iouring_server
// gcc -o iouring_server iouring_server.c -luring
#include
#include
#include
#include
#include
#include
#define ENTRIES_LENGTH 4096
#define MAX_CONNECTIONS 1024
#define BUFFER_LENGTH 1024
char buf_table[MAX_CONNECTIONS][BUFFER_LENGTH] = {0};
// 传递的事件
enum {
READ,
WRITE,
ACCEPT,
};
// 连接信息
struct conninfo {
int connfd; // fd
int type; // 事件类型
};
void set_read_event(struct io_uring *ring, int fd, void *buf, size_t len, int flags) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
// io_uring 读事件
io_uring_prep_recv(sqe, fd, buf, len, flags);
struct conninfo ci = {
.connfd = fd,
.type = READ
};
memcpy(&sqe->user_data, &ci, sizeof(struct conninfo));
}
void set_write_event(struct io_uring *ring, int fd, const void *buf, size_t len, int flags) {
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
// io_uring 写事件
io_uring_prep_send(sqe, fd, buf, len, flags);
struct conninfo ci = {
.connfd = fd,
.type = WRITE
};
memcpy(&sqe->user_data, &ci, sizeof(struct conninfo));
}
void set_accept_event(struct io_uring *ring, int fd,
struct sockaddr *cliaddr, socklen_t *clilen, unsigned flags) {
// 获取 sq 队列的空 sqe
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
// io_uring的accept事件:将fd放入到sqe里
io_uring_prep_accept(sqe, fd, cliaddr, clilen, flags);
// 用于回调函数
struct conninfo ci = {
.connfd = fd,
.type = ACCEPT
};
memcpy(&sqe->user_data, &ci, sizeof(struct conninfo));
}
int main() {
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
if (listenfd == -1) return -1;
struct sockaddr_in servaddr, clientaddr;
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY);
servaddr.sin_port = htons(9999);
if (-1 == bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr))) {
return -2;
}
listen(listenfd, 10);
struct io_uring_params params;
memset(¶ms, 0, sizeof(params));
// 初始化队列,内部调用io_uring_setup
struct io_uring ring;
io_uring_queue_init_params(ENTRIES_LENGTH, &ring, ¶ms);
socklen_t clilen = sizeof(clientaddr);
set_accept_event(&ring, listenfd, (struct sockaddr*)&clientaddr, &clilen, 0);
while (1) {
// 封装 io_uring_enter
// 1、提交io请求:将sqe的偏移信息加入到sq,提交sq到内核,不阻塞等待其完成
// 2、等待io完成:内核在io完成后,自动将sqe的偏移信息加入到cq
io_uring_submit(&ring);
// 从获取 cqe 的两种方式
// 1、阻塞等待io完成,获取 cqe
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring, &cqe);
// 2、不阻塞等待io完成,没有cqe返回错误,获取 cqe
struct io_uring_cqe *cqes[10];
int cqecount = io_uring_peek_batch_cqe(&ring, cqes, 10);
int i = 0;
unsigned count = 0;
for (i = 0; i < cqecount; ++i) {
cqe = cqes[i];
count ++;
struct conninfo ci;
memcpy(&ci, &cqe->user_data, sizeof(ci));
if (ci.type == ACCEPT) {
int connfd = cqe->res;
char *buffer = buf_table[connfd];
set_read_event(&ring, connfd, buffer, 1024, 0);
// io_uring 设置一次,触发一次
set_accept_event(&ring, listenfd, (struct sockaddr*)&clientaddr, &clilen, 0);
} else if (ci.type == READ) {
int bytes_read = cqe->res;
if (bytes_read == 0) {
close(ci.connfd);
} else if (bytes_read < 0) {
} else {
char *buffer = buf_table[ci.connfd];
set_write_event(&ring, ci.connfd, buffer, bytes_read, 0);
}
} else if (ci.type == WRITE) {
char *buffer = buf_table[ci.connfd];
set_read_event(&ring, ci.connfd, buffer, 1024, 0);
}
}
// cq队列一次轮询完成后,因为cqe的取出,需要调整队首的位置,以便下次使用
io_uring_cq_advance(&ring, count);
}
}