51-24 BEVFormer、BEVFormer v2,Occupancy占用网络灵感源泉 论文精读
今天要读论文的是BEVFormer,有人说这是新一代自动驾驶感知融合的基石,有人说是后续Occupancy Network占用网络工作的灵感源泉。我们从题目《通过时空transformer从多摄像头图像中学习BEV表示》来看,这应该是BEV开山之作LSS论文的姊妹篇。
本文以BEVFormer为主,同时介绍改进版BEVFormer v2。
论文和代码地址

论文题目:Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
论文地址:https://arxiv.org/abs/2203.17270
代码地址:https://github.com/zhiqi-li/BEVFormer
BEVFormer 是一个纯视觉方案,基本上奠定了当前自动驾驶纯视觉感知基本框架:
- 一个核心:纯视觉;
- 两个策略:将 Attention 应用于时间与空间维度;
- 三个节约:Attention 计算简化,特征映射简化,粗粒度特征空间;
- 框架结构:时间+空间+DeformableAttention。
具体说来主要有以下几个特点:
- Backbone Network,利用 ResNet101+ FPN 提取环视图像的多尺度特征;
- Encoder model,包括 Temporal Self-Attention 和 Spatial Cross-Attention 两个模块,完成环视图像特征向 BEV 特征的建模;
- Decoder model,利用类似 Deformable DETR,完成 3D 目标检测、分类和定位任务;
- Loss,Focal Loss 分类损失 + L1 Loss 回归损失。
本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队整理编辑。如有错误,欢迎在评论区指正。
Abstract
3D视觉感知任务,包括基于多摄像头图像的3D目标检测和地图分割,对于自动驾驶系统至关重要。在这项工作中,我们提出了一个名为BEVFormer的新框架,该框架使用时空transformer学习统一的BEV表示,以支持多个自动驾驶感知任务。简而言之,BEVFormer通过预定义的网格形状的BEV查询来利用空间和时间信息。为了聚合空间信息,我们设计了spatial cross-attention,即每个BEV查询从摄像机视图感兴趣的区域中提取空间特征。对于时间信息,我们提出了temporal self-attention来循环融合历史BEV信息。我们的方法在nuScenes测试集上的NDS度量方面达到了最新的56.9%,比之前的SOTA高9.0分,与基于lidar的基线的性能相当。我们进一步表明,BEVFormer在低能见度条件下显著提高了物体的速度估计和召回率的准确性。
Introduction
3D空间中的感知对于自动驾驶、机器人等各种应用至关重要。尽管基于激光雷达的方法取得了显著进展,但近年来,基于相机的方法引起了广泛关注。除了部署成本低之外,与基于激光雷达的同行相比,相机在检测远距离物体和识别基于视觉的道路元素(例如,红绿灯、停止线)方面具有可取的优点。
自动驾驶中对周围场景的视觉感知有望根据多个摄像头给出的2D线索预测3D边界框或语义图。最直接的解决方案是基于单目框架和跨相机后处理。该框架的缺点是,它单独处理不同的视图,无法跨相机捕获信息,导致性能和效率低下。
作为单目框架的替代方案,一个更统一的框架是从多摄像机图像中提取整体表示。鸟瞰图(BEV)是周围场景的常用表示,因为它清楚地显示了物体的位置和规模,适合于各种自动驾驶任务,如感知和规划。尽管先前的地图分割方法证明了BEV的有效性,但在3D对象检测方面,基于BEV的方法没有显示出与其他范式相比的显著优势。根本原因是3D对象检测任务需要强大的BEV特征来支持精确的3D边界框预测,但从2D平面生成BEV是不合适的。生成BEV特征的流行BEV框架基于深度信息,但这种范式对深度值或深度分布的准确性很敏感。因此,基于BEV的方法的检测性能会受到复合误差的影响,不准确的BEV特征会严重损害最终性能。
我们有动机设计一种不依赖于深度信息的BEV生成方法,该方法可以自适应地学习BEV特征,而不是严格依赖于3D先验。Transformer使用注意力机制来动态聚合有价值的特性,在概念上满足了我们的需求。使用BEV特征执行感知任务的另一个动机是BEV是连接时间和空间空间的理想桥梁。对于人类的视觉感知系统来说,时间信息在推断物体的运动状态和识别被遮挡物体方面起着至关重要的作用,许多视觉领域的工作已经证明了使用视频数据的有效性。然而,现有的最先进的多摄像头3D目标检测方法很少利用时间信息。最大的挑战是自动驾驶是时间关键的,而且场景中的物体变化很快,因此简单地叠加跨时间戳的BEV特征会带来额外的计算成本和干扰信息,这可能不是理想的。受递归神经网络(RNN)的启发,我们利用BEV特征递归地传递从过去到现在的时间信息,这与RNN模型的隐藏状态具有相同的精神。
为此,我们提出了一种基于transformer的BEV编码器,称为BEVFormer,它可以有效地聚合来自多相机视图的时空特征和历史BEV特征。由BEVFormer生成的BEV特征可以同时支持多种3D感知任务,如3D目标检测和地图分割,这对自动驾驶系统具有重要价值。
如图1所示,BEVFormer包含三个关键设计:
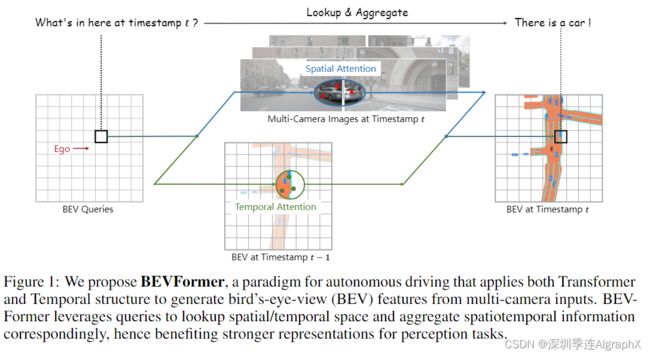
1)网格状BEV查询,通过注意机制灵活融合时空特征;
2)spatial cross-attention模块,聚合多相机图像的空间特征;
3)temporal self-attention模块,从历史BEV特征中提取时间信息,有利于运动目标的速度估计和严重遮挡目标的检测。同时带来可忽略不计的计算开销。借助BEVFormer生成的统一特征,该模型可以与不同的任务头(如Deformable DETR和mask decoder)协作,进行端到端的3D目标检测和地图分割。
我们的主要贡献如下:
我们提出了BEVFormer,一个时空转换编码器,将多相机和/或时间戳输入投影到BEV表示。通过统一的BEV特征,我们的模型可以同时支持多个自动驾驶感知任务,包括3D目标检测和地图分割。
我们设计了可学习的BEV查询以及空间交叉注意层和时间自注意层,分别从交叉摄像机和历史BEV中查找空间特征和时间特征,然后将它们聚合成统一的BEV特征。
我们在多个具有挑战性的基准上评估了BEVFormer,包括nuScenes和Waymo。与现有技术相比,我们的BEVFormer实现了更好的性能。例如,在参数和计算开销相当的情况下,BEVFormer在nuScenes测试集上达到56.9%的NDS,比之前的最佳检测方法DETR3D高出9.0分(56.9% vs. 47.9%)。对于地图分割任务,我们也实现了最先进的性能,在最具挑战性的车道分割上,我们比Lift-Splat高出5.0分以上。
我们希望这个简单而强大的框架可以作为后续3D感知任务的新基线。
Related Work
Transformer-based 2D perception
最近,一个新的趋势是使用transformer来重新制定检测和分割任务。DETR使用一组对象查询直接由cross-attention decoder生成检测结果。然而,DETR的主要缺点是训练时间长。可变形DETR通过提出可变形的注意力解决了这个问题。与DETR中的vanilla全局注意不同,变形注意与局部感兴趣区域相互作用,只对每个参考点附近的K个点进行采样并计算attention结果,从而提高了效率,显著缩短了训练时间。可变形注意机制的计算公式为:

Camera-based 3D Perception
以前的3D感知方法通常独立执行3D物体检测或地图分割任务。对于3D目标检测任务,早期的方法类似于二维检测方法,通常是基于2D边界框来预测3D边界框。FCOS3D采用一种先进的二维探测器FCOS,直接预测每个物体的三维边界框。DETR3D将可学习的3D查询投影到2D图像中,然后对相应的特征进行采样,进行端到端的3D边界盒预测,无需NMS后处理。另一种解决方案是将图像特征转换为BEV特征,从自上而下的角度预测3D边界框。方法利用深度估计或分类深度分布的深度信息将图像特征转换为BEV特征。OFT和ImVoxelNet将预定义的体素投影到图像特征上,以生成场景的体素表示。最近,M2BEV进一步探索了基于BEV特征同时执行多个感知任务的可行性。实际上,从多相机特征生成BEV特征在地图分割任务中得到了更广泛的研究。一种简单的方法是通过逆透视映射(Inverse perspective Mapping, IPM)将透视视图转换为BEV。此外,Lift-Splat基于深度分布生成BEV特征。还有方法利用多层感知器学习从视角到BEV的转换。PYVA提出了一种将前视单眼图像转换为BEV的交叉视图转换器,但这种范式不适合基于全局关注机制计算成本的多相机特征融合。除了空间信息外,前人的研究还通过叠加多个时间戳的BEV特征来考虑时间信息。叠加BEV特征限制了在固定时间内可用的时间信息,带来了额外的计算成本。本文提出的时空transformer在考虑时空线索的基础上生成当前时间的BEV特征,并通过RNN的方式从之前的BEV特征中获取时间信息,计算成本很小。
BEVFormer
将多摄像头图像特征转换为鸟瞰(BEV)特征可以为各种自动驾驶感知任务提供统一的周围环境表示。在这项工作中,我们提出了一个新的基于transformer的BEV生成框架,该框架可以通过注意机制有效地聚合来自多视图摄像机的时空特征和历史BEV特征。
Overall Architecture
如图2所示,BEVFormer有6层编码器,除了BEV查询、空间交叉注意和时间自注意三种定制设计外,每一层都遵循transformer的常规结构。

具体来说,BEV查询是网格状的可学习参数,旨在通过注意机制从多摄像头视图中查询BEV空间中的特征。空间交叉注意和时间自注意是与BEV查询一起工作的注意层,用于根据BEV查询查找和聚合来自多相机图像的空间特征以及来自历史BEV的时间特征。在推理过程中,在时间点t,我们向骨干网络(如ResNet-101)提供多摄像机图像,得到不同摄像机视图的特征![]() ,其中
,其中![]() 为第i个视图的特征,Nview为摄像机视图总数。同时,我们保留了前时间戳t−1的BEV特征Bt−1。在每个编码器层中,我们首先使用BEV queries Q通过时间自关注从先前的BEV特征Bt−1中查询时间信息。然后,我们使用BEV查询Q通过空间交叉注意从多摄像头特征Ft中查询空间信息。经过前馈网络后,编码器层输出细化后的BEV特征,作为下一编码器层的输入。经过6层编码器叠加,得到当前时间点t统一的BEV特征Bt。以BEV特征Bt为输入,三维检测头和地图分割头对三维边界框、语义地图等感知结果进行预测。
为第i个视图的特征,Nview为摄像机视图总数。同时,我们保留了前时间戳t−1的BEV特征Bt−1。在每个编码器层中,我们首先使用BEV queries Q通过时间自关注从先前的BEV特征Bt−1中查询时间信息。然后,我们使用BEV查询Q通过空间交叉注意从多摄像头特征Ft中查询空间信息。经过前馈网络后,编码器层输出细化后的BEV特征,作为下一编码器层的输入。经过6层编码器叠加,得到当前时间点t统一的BEV特征Bt。以BEV特征Bt为输入,三维检测头和地图分割头对三维边界框、语义地图等感知结果进行预测。
BEV Queries
我们预定义一组网格形可学习参数Q∈Rh×w×c作为BEVFormer的查询,h, w为BEV平面的空间形状。其中,位于Q的p = (x, y)处的查询Qp∈R1×c负责BEV平面中相应的网格单元区域。BEV平面中的每个网格单元对应于实际尺寸为 s 米。在默认情况下,BEV特征的中心对应于ego汽车的位置。按照惯例,我们在将BEV查询Q输入到BEVFormer之前,为其添加了可学习的位置嵌入。
(备注:BEV 平面,以自车为中心的栅格化二维平面,h、w是BEV的栅格尺寸,论文中把BEV平面中的栅格叫做2D参考点(2D reference points)。BEV 感知空间,把BEV平面在z轴方向选取Nref个3D参考点进行扩展,表示车辆周围有限空间,譬如在nuScenes数据集中,表示是以Lidar作为中心点,前后各51.2m、左右各51.2m、向上3m、向下5m的矩形空间。BEV Queries是预定义的一组栅格形(grid-shaped)可学习参数,它是对上述 BEV 感知空间的特征描述,可以理解为学习完成后的 BEV features)
Spatial Cross-Attention
由于多摄像头3D感知(包含Nview摄像头视图)的大输入规模,标准多头注意力的计算成本非常高。因此,我们开发了基于可变形attention的空间交叉注意,这是一种资源高效的注意层,其中每个BEV查询Qp仅与相机视图中感兴趣的区域交互。然而,可变形注意力最初是为2D感知设计的,因此需要对3D场景进行一些调整。
如图2 (b)所示,我们首先将BEV平面上的每个查询提升为柱状查询,从柱状查询中采样Nref 3D参考点,然后将这些点投影到2D视图中。对于一个BEV查询,投影的2D点只能落在一些视图上,而其他视图不会被击中。这里,我们称hit视图为Vhit。之后,我们将这些2D点作为query Qp的参考点,并从这些参考点周围的hit视图Vhit中采样特征。最后,我们对采样特征进行加权求和,作为空间交叉注意的输出。空间交叉注意(SCA)过程可表述为:
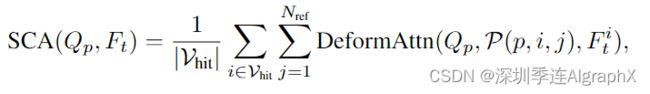
其中i为摄像机视图索引,j为参考点索引,Nref为每个BEV查询的总参考点。F它是第i个摄像机视图的特征。对于每个BEV查询Qp,我们使用投影函数P(P, i, j)来获得第i个视图图像上的第j个参考点。接下来,我们介绍了如何从投影函数P中获取视图图像上的参考点。我们首先计算出Q的查询Qp (atp = (x, y))对应的真实世界位置(x ', y ')。
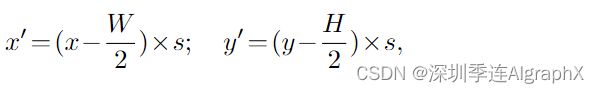
式中,h、w为BEV查询的空间形状,s为BEV网格的分辨率大小,(x’,y’)为ego车位置为原点的坐标。在3D空间中,位于(x ', y ')的物体将出现在z轴上的z '高度。所以我们预先定义了一组锚高度{![]() ,以确保我们能够捕捉到出现在不同高度的轨迹。这样,对于每个查询Qp,我们得到一个参考3D Pillar (x ', y ', z ' j)。最后,我们通过摄像机的投影矩阵将三维参考点投影到不同的图像视图中,可以写成:
,以确保我们能够捕捉到出现在不同高度的轨迹。这样,对于每个查询Qp,我们得到一个参考3D Pillar (x ', y ', z ' j)。最后,我们通过摄像机的投影矩阵将三维参考点投影到不同的图像视图中,可以写成:
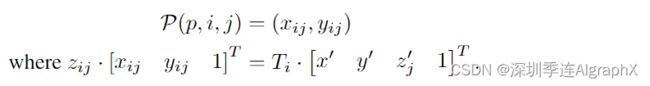
式中,P(P, i, j)为第i个视图上的2D点由第j个3D点(x ', y ', z ' j)投影而来,Ti∈R为第i个摄像机的已知投影矩阵。
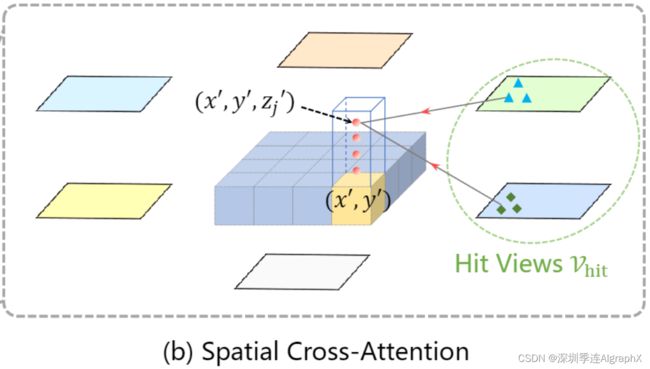
(备注:利用Temporal Self-Attention 模块输出的 bev_query,Spatial Cross-Attention需要计算bev_query、ref_point、value等几个参数。参数ref_point,这个ref_3d坐标点是基于 BEV 空间产生的3D pillar点,沿着 z 轴方向上人为选择了 4 个坐标点。如上图)
Temporal Self-Attention
除了空间信息外,时间信息对于视觉系统理解周围环境也至关重要。例如,在没有时间线索的情况下推断移动物体的速度或从静态图像中检测高度遮挡的物体是具有挑战性的。为了解决这个问题,我们设计了时间自关注,它可以通过结合历史BEV特征来表示当前环境。
给定当前时间戳t的BEV查询Q和时间戳t−1保存的历史BEV特征Bt−1,我们首先根据自我运动将Bt−1与Q对齐,使同一网格上的特征对应于相同的现实世界位置。在这里,我们将对齐的历史BEV特征Bt−1表示为B‘t−1。然而,从t−1到t,可移动的物体在现实世界中以不同的偏移量移动。在不同时间,构建相同目标的精确关联是一个挑战。因此,我们通过时间自注意(temporal self-attention, TSA)层对特征之间的这种时间联系进行建模,可以写成如下:

其中,Qp表示位于p = (x, y)处的BEV查询。此外,与普通的可变形注意不同,时间自注意中的偏移量∆p是通过Q和B 't−1的连接来预测的。特别地,对于每个序列的第一个样本,将时间自注意退化为不含时间信息的自注意,其中我们用重复的BEV查询{Q, Q}替换BEV特征{Q, B 't−1}。与简单地叠加BEV相比,我们的时间自我注意可以更有效地模拟长时间依赖性。BEVFormer从之前的BEV特征中提取时间信息,而不是从多个叠加的BEV特征中提取时间信息,因此需要较少的计算成本和较少的干扰信息。
(备注:Temporal Self-Attention 模块需要计算 bev_query、bev_pos、prev_bev、ref_point、value等5个重要参数,以及内部参数 Offset、Weights、 Sample Location)
Deformable attention
为增加理解,编者增加这部分内容。
内容摘自商汤、中科大、香港中文大学的工作,DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION。

Deformable Attention模块,还可以很方便的处理多尺度特征。

同时支持加多头注意。
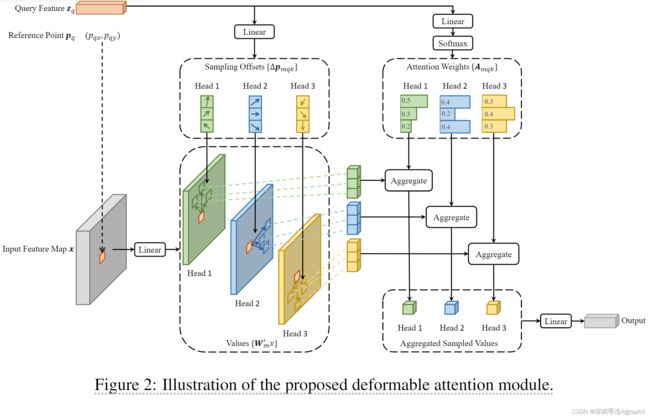
在本文中,可变形注意力模块试图克服基于Transformer注意力的一个问题,因为后者查看所有可能的空间位置。受可变形卷积的启发,可变形注意力模块只关注参考点周围的一小组关键采样点,而不考虑特征图的空间大小。
传统 attention module,每Query 都会和所有的Key做attention,而Deformable Attention Module 只使用固定的一小部分 Key与Query去做attention,所以收敛时间会缩短。
在本文中,假设原始数据集nuScenes有6个摄像头,在计算ego vehicle左前方某个目标BEV特征时,只需要attention车前方和左中间几个摄像头,而不需要关注车右后方摄像头数据。对于每个query,仅在全局位置中采样部分位置(左前方)key,并且value也是基于这些位置进行采样得到,最后将这个左前方局部特征和注意力权重作用在对应的value上。
Applications of BEV Features
由于BEV特征Bt∈Rh×w ×c是一个多功能的2D特征图,可用于各种自动驾驶感知任务,因此3D物体检测和地图分割任务头可以在2D感知方法的基础上进行少量修改。对于3D物体检测,我们基于2D检测器Deformable DETR设计了端到端的3D检测头。改进包括使用单尺度BEV特征Bt作为解码器的输入,预测3D边界盒和速度而不是2D边界盒,并且仅使用L1损失来监督3D边界盒回归。使用检测头,我们的模型可以端到端预测3D边界盒和速度,而无需NMS后处理。对于地图分割,我们基于二维分割方法Panoptic SegFormer设计了地图分割头。由于基于BEV的地图分割与常见的语义分割基本相同,我们使用掩码解码器和类固定查询来针对每个语义类别,包括汽车、车辆、道路(可行驶区域)和车道。
Implementation Details
训练阶段。对于时间戳t的每个样本,我们从过去2秒的连续序列中随机抽取另外3个样本,这种随机抽样策略可以增强自我运动的多样性。我们将这四个样本的时间戳分别表示为t−3,t−2,t−1和t。对于前三个时间戳的样本,它们负责循环生成BEV特征{Bt−3,Bt−2,Bt−1},该阶段不需要梯度。对于时间戳t−3的第一个样本,没有先前的BEV特征,时间自注意退化为自注意。在时刻t,模型同时基于多摄像头输入和之前的BEV特征Bt−1生成BEV特征Bt,使得Bt包含了跨越四个样本的时空线索。最后,我们将BEV特征Bt输入到检测和分割头中,并计算相应的损失函数。
推理阶段。在推理阶段,我们按时间顺序评估视频序列的每一帧。将前一个时间戳的BEV特征保存下来并用于下一个时间戳,这种在线推理策略时间效率高,符合实际应用。虽然我们利用了时间信息,但我们的推理速度仍然与其他方法相当。
Experiments
两种数据集测试结果
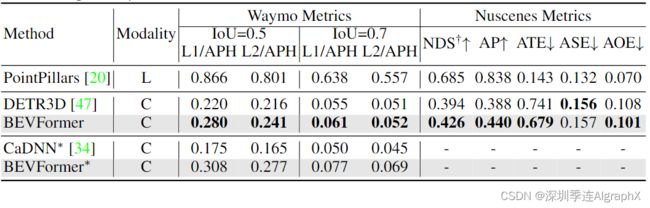
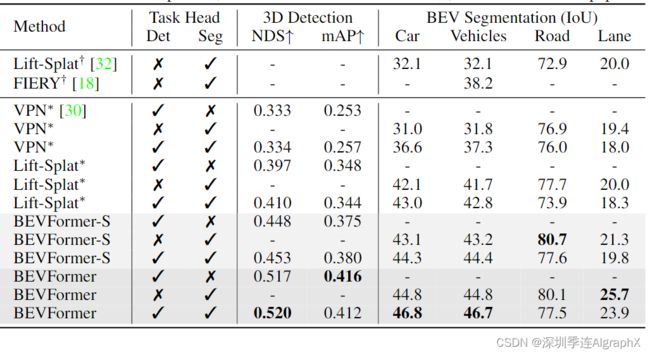
目标检测和语义分割任务表现
效果可视化

Discussion and Conclusion
在这项工作中,我们提出了BEVFormer从多摄像机输入生成鸟瞰图特征。BEVFormer可以有效地聚合时空信息,生成强大的BEV特征,同时支持3D检测和地图分割任务。目前,基于摄像机的方法与基于激光雷达的方法在效果和效率上还有一定的差距。从二维信息中准确推断三维位置仍然是基于相机的方法长期存在的挑战。
BEVFormer证明了使用多摄像头输入的时空信息可以显著提高视觉感知模型的性能。BEVFormer所展示的优势,如更准确的速度估计和对低可见物体的更高召回率,对于构建更好、更安全的自动驾驶系统乃至未来至关重要。我们相信BEVFormer只是更强大的视觉感知方法的一个基线,基于视觉感知系统仍有巨大的潜力有待探索。
BEVFormer V2

论文题目:BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision.
为了进一步提升BEVFormer的性能,BEVformer v2应运而生。
Abstract
We present a novel bird's-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones. Existing state-of-theart BEV detectors are often tied to certain depth pretrained backbones like VoVNet, hindering the synergy between booming image backbones and BEV detectors. To address this limitation, we prioritize easing the optimization of BEV detectors by introducing perspective view supervision. To this end, we propose a two-stage BEV detector, where proposals from the perspective head are fed into the bird's-eye-view head for final predictions. To evaluate the effectiveness of our model, we conduct extensive ablation studies focusing on the form of supervision and the generality of the proposed detector. The proposed method is verified with a wide spectrum of traditional and modern image backbones and achieves new SoTA results on the large-scale nuScenes dataset. The code shall be released soon.
改变1,BEVFormer V2版本通过引入透视图监督来优化BEV检测器,为此提出了一种two-stage BEV检测器,将透视头预测结果输入鸟瞰图头进行最终预测。
Overall Architecture
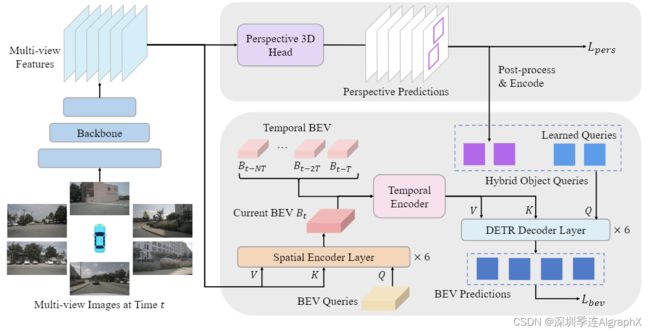
Overall architecture of BEVFormer v2
图像主干生成多视图图像的特征。透视 3D 头进行透视图预测,然后将其编码为对象查询。BEV 头是 encoder-decoder 编码器-解码器结构。空间编码器通过聚合多视图图像特征,时间编码器收集历史特征。解码器将混合对象查询作为输入,并根据 BEV 特征进行最终的 BEV 预测。整个模型用两个检测头的两个损失项 Lpers 和 Lbev 进行训练。
BEVFormer v2 主要由五个组件组成:
图像主干、透视 3D 检测头、空间编码器、改进的时间编码器和 BEV 检测头。
与原始 BEVFormer 相比,除空间编码器外,所有组件都进行了更改。具体来说,BEVFormer v2 中使用的所有图像主干网络都没有与任何自动驾驶数据集或深度估计数据集进行预训练。引入了透视 3D 检测头来促进 2D 图像主干网络的适应并为 BEV 检测头生成对象建议。采用一种新的时间BEV 编码器来更好地结合长期时间信息。BEV检测头现在接受一组混合对象查询作为输入。我们将第一阶段建议和学习到的对象查询结合起来,形成第二阶段的新混合对象查询。
Perspective Supervision
们首先分析了鸟瞰模型的问题,以解释为什么需要额外的监督。
典型的BEV模型维护附加的网格形特征到 BEV 平面,其中每个网格从多视图图像的相应 2D 像素的特征聚合 3D 信息。它根据BEV特征预测目标对象的3D边界框,我们将这种对BEV特征施加的监督命名为BEV监督。以BEVformer为例,它使用 encoder-decoder 结构来生成和利用BEV特征。编码器使用一组 3D 参考点在 BEV 平面上分配每个网格单元,并将它们投影到多视图图像上作为 2D 参考点。之后,它对二维参考点周围的图像特征进行采样,并利用空间交叉注意将它们聚合到BEV特征中。解码器是一个可变形的DETR头,它使用少量固定数量的对象查询预测BEV坐标中的3D边界框。下图显示了 3D-to-2D 视图转换和 DETR 头引入的 BEV 监督的两个潜在问题:
相对于图像特征,监督是隐含的。损失直接应用于 BEV 特征,而在 3D 到 2D 投影和图像特征的注意力采样后变为间接。
相对于到图像特征,监督是稀疏的。对象查询关注的少量 BEV 网格有助于损失。因此,只有这些网格的2D参考点周围的稀疏像素才能获得监督信号。
因此,在训练过程中出现了不一致性,BEV检测头非常依赖于图像特征中包含的3D信息,但关于如何编码这些信息,它为骨干网络提供的指导严重不足。
以前的 BEV 方法不会严重遭受这种不一致的影响,甚至可能没有意识到这个问题。这是因为它们的主干要么具有相对较小的尺度,要么已经在具有单目检测头的 3D 检测任务上进行了预训练。
与 BEV 头相比,透视 3D 头对图像特征进行逐像素预测,为适应 2D 图像主干提供了更丰富的监督信号。我们将对图像特征施加的这种监督定义为透视监督。
如下图所示,与 BEV 监督不同,透视检测的损失直接、密集地作应用于图像特征。透视监督显性地引导主干感知 3D 场景并提取有用信息,例如对象的深度和方向,克服了 BEV 监督的缺点,因此在使用现代图像主干训练 BEV 模型时是必不可少的。
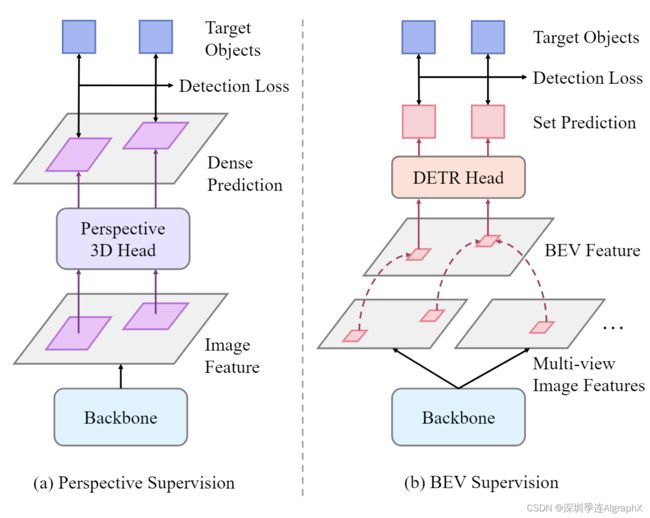
透视检测器的监督信号密集且直接指向图像特征,而BEV检测器的监督信号稀疏且间接。
Perspective Loss
如上一阶段分析的那样,透视监督是优化BEV模型的关键。在BEVformer v2中,我们通过辅助透视损失引入透视监督。
具体来说,在主干上构建了一个透视 3D 检测头来检测透视图中的目标对象。我们采用类似FCOS3D的检测头,预测3D边界框的中心位置、大小、方向和投影中心度。该头部的检测损失,表示为透视损失Lpers,作为BEV 损失 Lbev 的补充,便于骨干的优化。整个模型使用总目标进行训练。
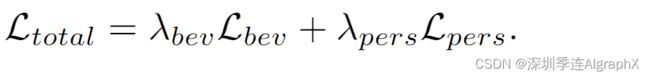
Ravamped Temporal Encoder
BEVFormer使用循环时间自注意来合并历史BEV特征。但是时间编码器未能利用长时间信息,简单地将循环步骤从 4 增加到 16 不会产生额外的性能提升。
我们使用简单的变形和连接策略为 BEVFormer v2 重新设计时间编码器。
给定不同帧 k 处的BEV 特征 Bk,我们首先根据帧 t 和帧 k 之间的参考帧变换矩阵 Tkt= [R|t] ∈ SE3 将 Bk 双线性变换到当前帧中。然后,我们将之前的 BEV 特征与通道维度上的当前 BEV 特征连接起来,并使用残差块进行降维。为了保持与原始设计相似的计算复杂度,我们使用了相同数量的历史BEV特征,但增加了采样间隔。除了受益于长期时间信息外,新的时间编码器还解锁了在离线3D检测设置中利用未来BEV特征的可能性。
Two-stage BEV Detector
尽管联合训练两个检测头提供了足够的监督,但我们分别从不同的视图获得两组检测结果。我们没有对BEV头部进行预测,丢弃透视头部的预测,或者通过NMS启发式地结合两组预测,而是设计了一种新的结构,将两个头部集成到两阶段预测管道中,即两阶段BEV检测器。BEV头中的对象解码器,DETR解码器,使用一组学习嵌入作为对象查询,它通过训练学习目标对象可能的位置。然而,随机初始化的嵌入需要很长时间来学习适当的位置。此外,在推理过程中,学习到的对象查询对于所有图像都是固定的,这可能不够准确,因为对象的空间分布可能会有所不同。为了解决这些问题,先用后处理方法过滤透视检测头的预测结果,然后融合到decoder的对象查询中,形成two stage过程。这些混合对象查询提供了高分(概率)的候选位置,使得 BEV 头在第二阶段更容易捕获目标对象。需要注意的是,第一阶段的建议不一定来自透视检测器,例如,从另一个BEV检测器中,但实验表明,只有透视图的预测有助于第二阶段的BEV head。
Decoder with Hybrid Object Queries
为了将第一阶段的建议融合到第二阶段的对象查询中,BEVformer v2中对基于BEVFormer中使用的可变形DETR解码器进行修改。这个解码器由交替堆叠的多个自注意力和交叉注意力层组成。
交叉注意层cross-attention layer是一个可变形注意模块,包含三个输入。
1)Content queries,query 特征以产生采样偏移量和注意力权重。
2)Reference points,,value 特征上的2D点,作为每个查询的采样参考。
3)Value features,要注意的 BEV features。
在原始 BEVFormer 中,内容查询是一组学习嵌入,参考点使用来自一组学习位置嵌入的线性层进行预测。在BEVformer v2中,我们从透视检测头获得建议,并通过后处理选择其中的一部分。如下图所示,BEV 平面上的投影框中心点用作每张图像参考点,并与位置嵌入生成每个数据集组合。每幅图像参考点直接标示为物体在BEV平原上的可能位置,使得解码器更容易检测目标对象。然而,由于遮挡或透视头部可能无法检测到一小部分对象或者出现在两个相邻视图的边界。为了避免缺少这些对象,我们还保留了原始的每个数据集参考点,通过学习空间先验来捕获它们。
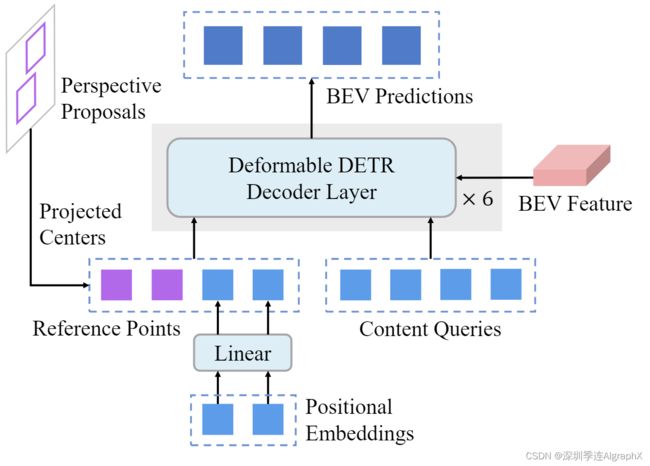
The decoder of the BEV head in BEVFromer v2。
第一阶段建议的投影中心被用作每个图像的参考点(紫色的),它们与跨数据集学习的内容查询和位置嵌入(蓝色的)结合起来作为混合对象查询。
本文中,作者说交叉注意层cross-attention layer是一个可变形注意模块,包含三个输入Content queries,Reference points和Value features。The cross-attention layer is a deformable attention module that takes the following three elements as input。再借用Deformable attention原始架构图,简要说明对照情况。
1)Content queries,对应Query feature Zq。
2)Reference points,对应Reference point Pq。
3)Value features,对应Input feature Max x。
https://arxiv.org/abs/2211.10439 BEVFormer V2
https://arxiv.org/pdf/2203.17270.pdf BEVFormer V1