现代化C#代码-第四部分:类型

目录 (Table of Contents)
Introduction
介绍
Background
背景
Classic Type Systems
经典类型系统
Dissecting C#'s Type System
剖析C#的类型系统
-
Generating Iterators
生成迭代器
Discards
舍弃
Handling Asynchronous Code
处理异步代码
Pattern Matching
模式匹配
Nullable Types
可空类型
The Modern Way
现代方式
Outlook
外表
Conclusion
结论
Points of Interest
兴趣点
History
历史
介绍 (Introduction)
In the recent years, C# has grown from a language with exactly one feature to solve a problem to a language with many potential (language) solutions for a single problem. This is both, good and bad. Good, because it gives us as developers freedom and power (without compromising backwards compatibility) and bad due to the cognitive load that is connected with making decisions.
近年来,C#已从一种具有仅一种功能的语言发展为一种能够解决问题的语言,现已发展成具有针对单个问题的许多潜在(语言)解决方案的语言。 这是好事,也是坏事。 好的,因为它为我们作为开发人员提供了自由和权力(不影响向后兼容性),而由于与决策相关的认知负担而给我们带来了不利。
In this series, we want to explore what options exist and where these options differ. Surely, some may have advantages and disadvantages under certain conditions. We will explore these scenarios and come up with a guide to make our life easier when renovating existing projects.
在本系列文章中,我们想探讨存在哪些选项以及这些选项的不同之处。 当然,在某些情况下,某些方法可能具有优点和缺点。 我们将探索这些场景,并提出一个指南,以使我们在改造现有项目时的生活更加轻松。
This is part IV of the series. You can find Part I, Part II, as well as Part III on CodeProject.
这是本系列的第四部分。 您可以在CodeProject上找到第一部分 , 第二部分以及第三部分 。
背景 (Background)
In the past, I've written many articles particularly targeted at the C# language. I've written introduction series, advanced guides, articles on specific topics like async / await or upcoming features. In this article series, I want to combine all the previous themes in one coherent fashion.
过去,我写过许多专门针对C#语言的文章。 我已经写了介绍系列 , 高级指南 ,关于异步/等待或即将发布的功能等特定主题的文章。 在本系列文章中,我想以一种连贯的方式将所有先前的主题进行组合。
I feel it's important to discuss where new language features shine and where the old - let's call them established - ones are still preferred. I may not always be right (especially, since some of my points will surely be more subjective / a matter of taste). As usual, leaving a comment for discussion would be appreciated!
我觉得重要的是讨论新的语言功能在哪里闪闪发光,旧的语言功能在哪里-我们称之为成熟的-仍然是首选。 我可能并不总是正确的(特别是,因为我的某些观点肯定会更加主观/关于品味的问题)。 和往常一样,留下评论进行讨论将不胜感激!
Let's start off with some historic context.
让我们从一些历史背景开始。
经典类型系统 (Classic Type Systems)
Historically, types have been introduced to tell developers how many bytes by an allocation will be reserved. Additionally, simple things such as additions could then be also figured out by the compiler. Earlier, in pure assembler, developers had to decide what operation fits to the given values. Now, the compiler was capable of knowing that not only 4 bytes have been reserved by the two values, but also that they should be treated like integers. An Int32 addition would apply.
从历史上看,已经引入类型来告诉开发人员分配将保留多少字节。 另外,编译器也可以找出简单的事情,例如添加。 此前,在纯汇编程序中,开发人员必须决定哪种操作适合给定的值。 现在,编译器能够知道这两个值不仅保留了4个字节,而且还应将它们视为整数。 一个Int32加法将适用。
Later on, the need to introduce custom types was communicated. The first structures have been born. While standard operations (from a machine point of view) may not make much sense, the allocation and structure (hence the name) was key. Not only could we have "names" (usually erased at compile-time, i.e., only known to the compiler for convenience of the developer), but all the parts have been properly specified by position and type.
后来,传达了引入自定义类型的需求。 最初的结构已经诞生。 尽管从机器的角度来看标准操作可能没有多大意义,但是分配和结构 (因此而得名)才是关键。 我们不仅可以拥有“名称”(通常在编译时将其删除,即,为方便开发人员,编译器才知道),而且所有部分均已通过位置和类型正确指定。
With the introduction of object-oriented programming and its first interpretations, we have seen much more importance on the concept of types (mostly associated then with classes) and their relations to functions (then called methods). The relevance of type information inspection / access at runtime increased leading to capabilities like reflection. While classic native systems usually have very limited runtime capabilities (e.g., C++), managed systems appeared with vast possibilities (e.g., JVM or .NET).
随着面向对象程序设计的引入及其最初的解释,我们已经看到了类型(主要是与类相关联)及其与函数的关系(后来称为方法)的重要性。 类型信息检查/访问在运行时的相关性增加,导致诸如反射的功能。 尽管经典的本机系统通常具有非常有限的运行时功能(例如C ++),但是托管系统的出现却具有很大的可能性(例如JVM或.NET)。
Now one of the issues with this approach today is that many types are no longer originally coming from the underlying system - they come from deserialization of some data (e.g., incoming request to a web API). While the basic validation and deserialization could be coming from a type defined in the system, usually it comes just from a derivation of such a type (e.g., omitting certain properties, adding new ones, changing types of certain properties, ...). As it stands, duplication and limitations arise when dealing with such data. Hence, the need for dynamic programming languages, which offer more flexibility in that regard - at the cost of type safety for development.
现在,如今使用这种方法的问题之一是,许多类型最初不再来自底层系统,它们来自一些数据的反序列化(例如,对Web API的传入请求)。 虽然基本的验证和反序列化可能来自系统中定义的类型,但通常仅来自这种类型的派生(例如,省略某些属性,添加新属性,更改某些属性的类型等)。 就目前而言,处理此类数据时会出现重复和限制。 因此,需要动态编程语言,它需要在这方面提供更大的灵活性-以开发的类型安全为代价。
Every problem has a solution and in the last 10 years, we've seen new love for the type systems and type theory appearing all over the place. Popular languages such as TypeScript bring the results of years of research and other (more exotic) programming languages to the mainstream. Hopefully, some of the more classic and historic programming languages are also able to learn from these advancements.
每个问题都有解决方案,在过去的十年中,我们看到了对类型系统和类型理论的新热爱。 诸如TypeScript之类的流行语言将多年研究的结果和其他(更具异国情调的)编程语言带入了主流。 希望一些更经典和历史性的编程语言也能够从这些进步中学到东西。
剖析C#的类型系统 (Dissecting C#'s Type System)
This could also be called .NET's type system, however, while there is certainly some common base layer coming from .NET many constructs and possibilities just come from the language. In a different aspect, if we look how F# uses .NET's type system, we know that there is no natural limitation given by .NET - the system can bend and extended by a far margin.
这也可以称为.NET的类型系统,但是,尽管肯定有一些来自.NET的通用基础层,但许多构造和可能性仅来自该语言。 在另一个方面,如果我们看看F#如何使用.NET的类型系统,我们就会知道.NET没有自然的限制-系统可以弯曲和扩展很远。
C# likes to work with a static type system. And the word static here means something. Let's pretend we have the following type:
C#喜欢使用静态类型系统。 静态这个词在这里意味着某些东西。 假设我们具有以下类型:
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime Birthday { get; set; }
}
What if we want to enforce all properties to be optional? Well, actually in some sense, they are already as no one forces us to set them. But let's pretend nullable types have been introduced in this article already (they will be later) and what we are after is something like:
如果我们要强制所有属性为可选属性怎么办? 好吧,实际上在某种意义上,它们已经没有人强迫我们设置它们了。 但是,让我们假设已经在本文中介绍了可空类型(它们将在以后介绍),我们所追求的是:
public class PartialPerson
{
public string? FirstName { get; set; }
public string? LastName { get; set; }
public DateTime? Birthday { get; set; }
}
Now we have an issue. Once the first class changes, we also need to make some change on the second class. What if we could instead write something like:
现在我们有一个问题。 第一堂课更改后,我们还需要对第二堂课进行一些更改。 如果我们可以这样写:
public type PartialPerson = Partial;
That's actually how TypeScript works. In TypeScript, Partial is just an alias for iterating over all properties and putting an optional (?) on every property.
这实际上就是TypeScript的工作方式。 在TypeScript中, Partial只是用于遍历所有属性并在每个属性上放置一个可选( ? )的别名。
Alright, so C# does not like this. C# is more runtime oriented. Hence, we should use reflection for this.
好吧,所以C#不喜欢这样。 C#更加面向运行时。 因此,我们应该对此进行反思。
At runtime, this could look as follows:
在运行时,可能如下所示:
var PartialPersonType = Partial();
where the Partial method could be implemented in a straight forward way.
其中Partial方法可以直接实现的方式。
public static Type Partial()
{
var type = typeof(T);
var builder = GetTypeBuilder();
foreach (var property in type.GetProperties())
{
CreateProperty(builder, property);
}
return builder.CreateType();
}
private static TypeBuilder GetTypeBuilder()
{
var name = $"Partial<{typeof(T).Name}>";
var an = new AssemblyName(name);
var assemblyBuilder = AppDomain.CurrentDomain.DefineDynamicAssembly
(an, AssemblyBuilderAccess.Run);
var moduleBuilder = assemblyBuilder.DefineDynamicModule("MainModule");
return moduleBuilder.DefineType(name,
TypeAttributes.Public |
TypeAttributes.Class |
TypeAttributes.AutoClass |
TypeAttributes.AnsiClass |
TypeAttributes.BeforeFieldInit |
TypeAttributes.AutoLayout,
null);
}
private static void CreateProperty
(TypeBuilder tb, PropertyInfo property, string? ignore = null)
{
var propertyName = property.Name;
var propertyType = property.PropertyType;
var attributes = property.Attributes;
var customAttributes = property.CustomAttributes;
var addNullable = false;
if (propertyType.IsInterface || propertyType.IsClass)
{
// we require the custom attribute
addNullable = true;
}
else if (propertyType.IsValueType &&
(!propertyType.IsGenericType ||
propertyType.GetGenericTypeDefinition() != typeof(Nullable<>)))
{
// for values there is no attribute but the Nullable type
// we only apply it if its not yet wrapped in such a type
propertyType = typeof(Nullable<>).MakeGenericType(propertyType);
}
var fieldBuilder = tb.DefineField
("_" + propertyName, propertyType, FieldAttributes.Private);
var propertyBuilder = tb.DefineProperty(propertyName, attributes, propertyType, null);
foreach (var customAttribute in customAttributes)
{
// Append all custom attributes (as beforehand) except the Nullable one
if (customAttribute.Constructor.ReflectedType.Name != "NullableAttribute")
{
AppendAttribute(customAttribute, propertyBuilder);
}
}
// if the nullable attribute should be added we can abuse some magic ...
if (addNullable)
{
var customAttribute =
MethodBase.GetCurrentMethod().GetParameters().Last().CustomAttributes.Last();
AppendAttribute(customAttribute, propertyBuilder);
}
var getPropMthdBldr = tb.DefineMethod("get_" + propertyName,
MethodAttributes.Public | MethodAttributes.SpecialName |
MethodAttributes.HideBySig, propertyType, Type.EmptyTypes);
var getIl = getPropMthdBldr.GetILGenerator();
getIl.Emit(OpCodes.Ldarg_0);
getIl.Emit(OpCodes.Ldfld, fieldBuilder);
getIl.Emit(OpCodes.Ret);
var setPropMthdBldr = tb.DefineMethod("set_" + propertyName,
MethodAttributes.Public | MethodAttributes.SpecialName |
MethodAttributes.HideBySig,
null, new[] { propertyType });
var setIl = setPropMthdBldr.GetILGenerator();
var modifyProperty = setIl.DefineLabel();
var exitSet = setIl.DefineLabel();
setIl.MarkLabel(modifyProperty);
setIl.Emit(OpCodes.Ldarg_0);
setIl.Emit(OpCodes.Ldarg_1);
setIl.Emit(OpCodes.Stfld, fieldBuilder);
setIl.Emit(OpCodes.Nop);
setIl.MarkLabel(exitSet);
setIl.Emit(OpCodes.Ret);
propertyBuilder.SetGetMethod(getPropMthdBldr);
propertyBuilder.SetSetMethod(setPropMthdBldr);
}
private static void AppendAttribute
(CustomAttributeData customAttribute, PropertyBuilder propertyBuilder)
{
var args = customAttribute.ConstructorArguments.Select(m => m.Value).ToArray();
var cab = new CustomAttributeBuilder(customAttribute.Constructor, args);
propertyBuilder.SetCustomAttribute(cab);
}
While it's certainly possible to create types on the fly as shown, the fact remains that this is a runtime mechanism. As such, many of the potential use cases for type transformation are either a lot harder to accomplish, or impossible.
虽然可以如图所示即时创建类型,但事实是这是一种运行时机制。 这样,许多潜在的类型转换用例要么很难完成,要么不可能。
There are, however, community projects such as Fody to manipulate assemblies and / or IL code for adding such things already at compile-time. The major issue with these is the compiler assistance / tooling. It's often not so easy to see what's really going on.
但是,存在诸如Fody之类的社区项目来操纵程序集和/或IL代码,以在编译时添加此类内容。 这些方面的主要问题是编译器帮助/工具。 要了解实际情况通常并不容易。
现代方式 (The Modern Way)
A type remains a type. But wait! There is a little bit more to it. We have a lot of capabilities that either come with C# directly, with .NET, or are given by the ecosystem. In this section, we'll try to explore all of them.
类型仍然是类型。 可是等等! 还有更多的东西。 我们有很多功能,这些功能要么直接与C#一起提供,要么与.NET一起提供,或者由生态系统提供。 在本节中,我们将尝试探索所有这些。
Actually, while many of the syntax used in C# directly goes to some IL code or code constructs, some (mostly newer, but also as we will see really old) parts of C# tend to work closely together with the type system on a natural level. They either use existing interfaces, types, or other elements - sometimes creating new types without us even realizing. We already saw for instance classes for delegates (e.g., a Func) or local functions being created. Let's see what else is available!
实际上,尽管C#中使用的许多语法直接用于某些IL代码或代码构造,但C#的某些部分(大部分是更新的,但正如我们将看到的很旧)往往会在自然层次上与类型系统紧密配合。 他们使用现有的接口,类型或其他元素-有时甚至在我们没有意识到的情况下创建新类型。 我们已经看到例如代表的类(例如, Func )或正在创建的局部函数。 让我们看看还有什么可用的!
生成迭代器 (Generating Iterators)
Since the first versions of C#, we are able to generate types on the fly. Using yield, we have the power to start our own iterator. Such an iterator is represented by a type that implements the IEnumerable interface. It turns out that the only thing to do here is to somehow create an IEnumerator instance. All the logic (and state) is then contained in the IEnumerator instance.
从C#的第一个版本开始,我们能够即时生成类型。 使用yield ,我们可以启动自己的迭代器。 这样的迭代器由实现IEnumerable接口的类型表示。 事实证明,这里要做的唯一事情就是以某种方式创建IEnumerator实例。 然后,所有逻辑(和状态)都包含在IEnumerator实例中。
Let's first code our own implementation. What we want is an enumerable of the first three numbers (1, 2, 3).
首先让我们编写自己的实现代码。 我们想要的是前三个数字(1、2、3)的可枚举。
class MyEnumerable : IEnumerable
{
public IEnumerator GetEnumerator() => new MyIterable();
IEnumerator IEnumerable.GetEnumerator() => this.GetEnumerator();
class MyIterable : IEnumerator
{
public int Current => current;
object IEnumerator.Current => current;
private int current = 0;
public void Dispose() {}
public bool MoveNext() => ++current < 4;
public void Reset() => current = 0;
}
}
The C# language has plenty of nice features to deal with enumerators. Certainly, the most used is the foreach loop construct:
C#语言具有许多不错的功能来处理枚举器。 当然,最常用的是foreach循环构造:
var enumerable = new MyEnumerable();
foreach (var item in enumerable)
{
item.Dump(); // 1, 2, 3
}
Obviously, this one is just syntax sugar for the following code:
显然,这只是以下代码的语法糖:
var enumerable = new MyEnumerable();
var iterable = enumerable.GetEnumerator();
while (iterable.MoveNext())
{
var item = iterable.Current;
item.Dump();
}
A quick comparison at the MSIL code confirms this quite easily. The implicit version using the foreach loop looks as follows:
快速比较MSIL代码可以很容易地确认这一点。 使用foreach循环的隐式版本如下所示:
IL_0000: nop
IL_0001: newobj UserQuery+MyEnumerable..ctor
IL_0006: stloc.0 // enumerable
IL_0007: nop
IL_0008: ldloc.0 // enumerable
IL_0009: callvirt UserQuery+MyEnumerable.GetEnumerator
IL_000E: stloc.1
IL_000F: br.s IL_0021
IL_0011: ldloc.1
IL_0012: callvirt System.Collections.Generic.IEnumerator.get_Current
IL_0017: stloc.2 // item
IL_0018: nop
IL_0019: ldloc.2 // item
IL_001A: call LINQPad.Extensions.Dump
IL_001F: pop
IL_0020: nop
IL_0021: ldloc.1
IL_0022: callvirt System.Collections.IEnumerator.MoveNext
IL_0027: brtrue.s IL_0011
IL_0029: leave.s IL_0036
IL_002B: ldloc.1
IL_002C: brfalse.s IL_0035
IL_002E: ldloc.1
IL_002F: callvirt System.IDisposable.Dispose
IL_0034: nop
IL_0035: endfinally
IL_0036: ret
For comparison, the explicit version compiles to be:
为了进行比较,显式版本编译为:
IL_0000: nop
IL_0001: newobj UserQuery+MyEnumerable..ctor
IL_0006: stloc.0 // enumerable
IL_0007: ldloc.0 // enumerable
IL_0008: callvirt UserQuery+MyEnumerable.GetEnumerator
IL_000D: stloc.1 // iterable
IL_000E: br.s IL_0020
IL_0010: nop
IL_0011: ldloc.1 // iterable
IL_0012: callvirt System.Collections.Generic.IEnumerator.get_Current
IL_0017: stloc.2 // item
IL_0018: ldloc.2 // item
IL_0019: call LINQPad.Extensions.Dump
IL_001E: pop
IL_001F: nop
IL_0020: ldloc.1 // iterable
IL_0021: callvirt System.Collections.IEnumerator.MoveNext
IL_0026: stloc.3
IL_0027: ldloc.3
IL_0028: brtrue.s IL_0010
IL_002A: ret
Since the IEnumerator implements the IDisposable interface, we should have also disposed the resource correctly. The foreach syntax does that for us. Another reason for always using the generated code - it just makes our life easier by doing the right things without us having to remember.
由于IEnumerator实现了IDisposable接口,因此我们也应该正确配置资源。 foreach语法为我们做到了。 始终使用生成的代码的另一个原因-通过做正确的事情而无需记住就可以使我们的生活变得更轻松。
Still, it's not the foreach part that strikes us, but rather the generation of the class for the IEnumerable / IEnumerator implementation.
仍然,不是让我们感到foreach的是foreach部分,而是IEnumerable / IEnumerator实现的类的生成。
Let's use the yield keyword to do that.
让我们使用yield关键字执行此操作。
static IEnumerable GetNumbers()
{
var current = 0;
while (++current < 4)
{
yield return current;
}
}
The interesting thing is that this small piece of code already represents the full iterator as specified above. The C# compiler generates all the necessary types for us to make it work. The usage is also the same, except that instead of an explicit constructor call (new MyEnumerable()) we just call the function (GetNumbers()). Great!
有趣的是,这小段代码已经代表了上面指定的完整迭代器。 C#编译器会生成所有必需的类型,以使我们能够正常工作。 除了使用显式构造函数调用( new MyEnumerable() )之外,我们仅调用函数( GetNumbers() ),用法也相同。 大!
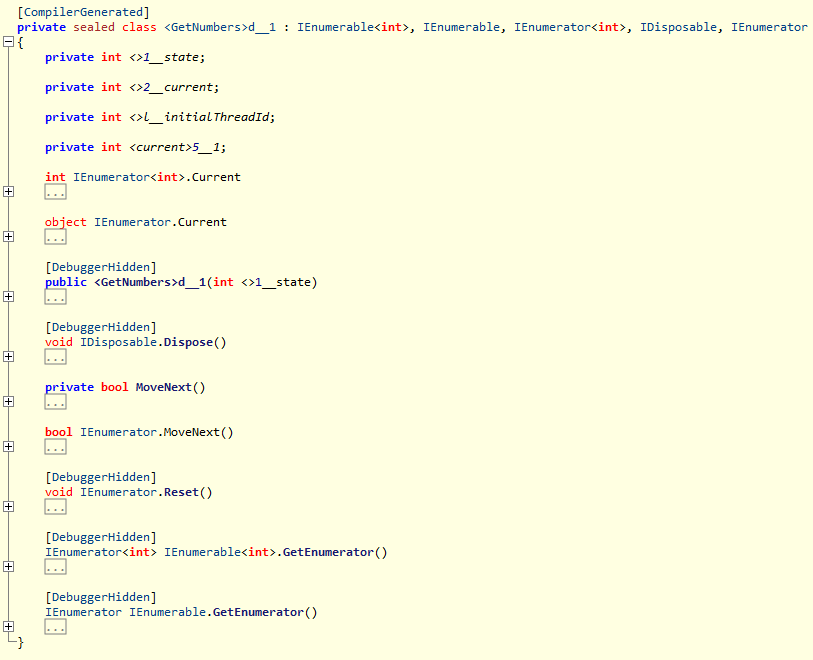
Let's recap what's so great about iterators.
让我们回顾一下迭代器的优点。
| Useful for | Avoid for |
|---|---|
|
|
| 对...有用 | 避免 |
|---|---|
|
|
舍弃 (Discards)
The C# compiler imposes quite some restrictions on the developer. Some of these restrictions are included to safeguard against obvious errors, while others are included to shield the user from running potentially useless code. One of these restrictions forbids to use certain expressions without assignment.
C#编译器对开发人员施加了很多限制。 这些限制中的一些限制用于防止明显的错误,而其他一些限制则用于防止用户运行可能无用的代码。 这些限制之一禁止使用某些表达式而不进行赋值。
Consider the following code:
考虑以下代码:
static void Main()
{
2 + 3;
}
Now that's a strange code. It would compute the result of 2 + 3 but it would not do anything with it. In a nutshell, either the compiler would optimize this statement away or we would just waste some CPU cycles.
现在,这是一个奇怪的代码。 它将计算2 + 3的结果,但不会执行任何操作。 简而言之,要么编译器会优化该语句,要么我们只会浪费一些CPU周期。
Personally, I think it's a strange restriction. Yes, the code above would be useless, but since C# allows operator overloading, there could be scenarios where simple add expressions would actually have meaningful side effects.
我个人认为这是一个奇怪的限制。 是的,上面的代码没有用,但是由于C#允许运算符重载,因此在某些情况下,简单的add表达式实际上会产生有意义的副作用。
A scenario where the (negative or annoying) implications of this design choice can be seen more practically is a simple nullability test.
可以更实际地看到此设计选择的(负面或烦人)含义的场景是一个简单的可空性测试。
static void Run(Action action)
{
action ?? throw new ArgumentNullException(nameof(action));
action();
}
This could will not work. Instead, the following does:
这可能行不通。 而是,执行以下操作:
static void Run(Action action)
{
(action ?? throw new ArgumentNullException(nameof(action)))();
}
Call expressions are considered okay by design. Obviously, the side-effect tendency of method calls was regarded very high - especially with respect to the "improbable" rating of operators.
设计上认为调用表达式还可以。 显然,方法调用的副作用趋势非常高-特别是对于操作员的“不可能”等级。
We would, however, still like to keep version 1 as its more readable. For this reason, i.e., to mitigate the consequences of this historic design choice, a special kind of construct was introduced: Discards.
但是,我们仍然希望保持版本1的可读性。 因此,为了减轻这种历史性设计选择的后果,引入了一种特殊的构造:丢弃。
The idea behind discards is simple: Introduce a special variable called _ that can always be assigned to. It can never be read - it is a write-only variable that will be optimized away by the compiler anyway.
丢弃背后的想法很简单:引入一个始终可以分配给的特殊变量_ 。 它永远不会被读取-这是一个只写变量,无论如何编译器都会对其进行优化。
Using this variable, we can come back to version 1:
使用此变量,我们可以回到版本1:
static void Run(Action action)
{
_ = action ?? throw new ArgumentNullException(nameof(action));
action();
}
That _ is a special kind of construct can be seen on multiple occasions. Let's say we have multiple of these checks:
_是一种特殊的构造,可以在多种场合看到。 假设我们有多项检查:
static void Run(Action action, T arg)
where T : class
{
_ = action ?? throw new ArgumentNullException(nameof(action));
_ = arg ?? throw new ArgumentNullException(nameof(arg));
action(arg);
}
Obviously, the type of action and arg will most likely be different. In any case, the assignment is accepted. The same can be done with unnecessary out parameters:
显然, action和arg的类型很可能会不同。 无论如何,都可以接受分配。 可以使用不必要的out参数完成相同的操作:
if (int.TryParse(str, out _))
{
// parsed successfully, but we don't care about the result
}
Another useful instance is to "fire and forget" tasks. Earlier, I usually introduced an extension method that looks as follows:
另一个有用的实例是“解雇”任务。 之前,我通常介绍一种扩展方法,如下所示:
public static class TaskExtensions
{
public static void Forget(this Task task)
{
// Empty on purpose; maybe log something?
}
}
The advantage was that now I could quite easily inform the C# compiler that a used task has been unused on purpose:
好处是,现在我可以很容易地通知C#编译器故意不使用过的任务:
public Task StartTask()
{
// ...
}
public void OnClick()
{
StartTask().Forget();
}
Using discards, we don't need extra extension methods to transport such information. Also, users already know what "will happen" to the task (hint: the answer is nothing).
使用丢弃,我们不需要额外的扩展方法来传输此类信息。 而且,用户已经知道任务将“发生”什么(提示:答案是“无”)。
public void OnClick()
{
_ = StartTask();
}
We will also use discards in the pattern matching section.
我们还将在模式匹配部分中使用丢弃。
| Useful for | Avoid for |
|---|---|
|
|
| 对...有用 | 避免 |
|---|---|
|
|
处理异步代码 (Handling Asynchronous Code)
We already touched the topic of asynchronous code briefly in the previous section. Since .NET 4, we have the Task type, which is quite handy to tame multiple streams of work. Together with the task parallel library (TPL) and async / await (C# 5 / .NET 4.5), we have a powerful toolbelt that only improved over the years.
在上一节中,我们已经简短地涉及了异步代码的主题。 从.NET 4开始,我们有了Task类型,可以轻松处理多个工作流。 与任务并行库(TPL)和异步/等待(C#5 / .NET 4.5)一起,我们拥有了功能强大的工具带,这些工具带仅在过去几年中得到了改进。
But why does async / await require a specific version of .NET? Isn't this just a language feature? Like always (e.g., interpolated strings, tuples) if we require a specific version of the base class library (BCL), we immediately know that some code is generated which uses the types from the BCL. In case of a method being decorated as async, it will generate a new class implementing the IAsyncStateMachine interface.
但是,为什么async / await需要特定版本的.NET? 这不只是一种语言功能吗? 像往常一样(例如,内插字符串,元组),如果我们需要特定版本的基类库(BCL),我们立即知道会生成一些使用BCL类型的代码。 如果方法装饰为async ,它将生成一个实现IAsyncStateMachine接口的新类。
The IAsyncStateMachine interface looks as follows:
IAsyncStateMachine接口如下所示:
public interface IAsyncStateMachine
{
void MoveNext();
void SetStateMachine(IAsyncStateMachine stateMachine);
}
Interesting enough, it has a MoveNext method just like the IEnumerator interface. In fact, we could use a specialized version of an IEnumerator to write our own async / await implementation. Coming from JavaScript, we know that generators (the JavaScript name for the enumerator / yield syntax sugar) have been (ab)used to introduce async / await capabilities before the feature arrived in the language. Even today, polyfills still use this (or fall back even one level before that in case generators are not available).
有趣的是,它具有IEnumerator接口一样的MoveNext方法。 实际上,我们可以使用IEnumerator的专用版本来编写我们自己的async / await实现。 来自JavaScript,我们知道在特性到达语言之前,已经(不赞成)使用生成器(枚举器JavaScript名称/ yield语法糖)来引入async / await功能。 即使在今天,polyfills仍使用此填充(或在生成器不可用的情况下,甚至再降一级)。
Let's look at a simple example of a method using async and await:
让我们看一个使用async和await的方法的简单示例:
async static Task Run(Func action)
{
await action();
}
This little snippet generated a class to look as follows:
这个小片段生成了一个类,如下所示:

In MSIL, the generated class is then used in the given Run method:
在MSIL中,然后在给定的Run方法中使用生成的类:
IL_0000: newobj UserQuery+d__1..ctor
IL_0005: stloc.0
IL_0006: ldloc.0
IL_0007: ldarg.0
IL_0008: stfld UserQueryd__1.action
IL_000D: ldloc.0
IL_000E: call System.Runtime.CompilerServices.AsyncTaskMethodBuilder.Create
IL_0013: stfld UserQuery+d__1.<>t__builder
IL_0018: ldloc.0
IL_0019: ldc.i4.m1
IL_001A: stfld UserQuery+d__1.<>1__state
IL_001F: ldloc.0
IL_0020: ldfld UserQuery+d__1.<>t__builder
IL_0025: stloc.1
IL_0026: ldloca.s 01
IL_0028: ldloca.s 00
IL_002A: call System.Runtime.CompilerServices.AsyncTaskMethodBuilder.Start<d__1>
IL_002F: ldloc.0
IL_0030: ldflda UserQuery+d__1.<>t__builder
IL_0035: call System.Runtime.CompilerServices.AsyncTaskMethodBuilder.get_Task
IL_003A: ret
In short, we instantiate the generated class, store the used arguments (captures) and set the state to be used within the async state machine. The static Create method of the async task method builder is used to construct the associated builder state. Then we run the async task method builder to construct us a task for this. Finally, we return the Task property from the builder.
简而言之,我们实例化生成的类,存储使用的参数(捕获)并设置要在异步状态机内使用的状态。 异步任务方法构建器的静态Create方法用于构建关联的构建器状态。 然后,我们运行异步任务方法构建器以为此构造一个任务。 最后,我们从构建器返回Task属性。
Needless to say, a simpler version of the code above would have been:
不用说,上面代码的简单版本是:
static Task Run(Func action)
{
return action();
}
These two variants are not exactly equivalent. Beforehand, we returned a newly generated task, "wrapping" the original task. Now, we return the original one. Performance-wise, they are certainly not the same. In this version, we omit a full class generation. Also, the MSIL for running the method is super short in comparison:
这两个变体并不完全等效。 事先,我们返回了一个新生成的任务,“包装”了原始任务。 现在,我们返回原始的。 在性能方面,它们肯定是不同的。 在此版本中,我们省略了完整的类生成。 同样,用于运行该方法的MSIL相较而言非常短:
IL_0000: nop
IL_0001: ldarg.0
IL_0002: callvirt System.Func.Invoke
IL_0007: stloc.0
IL_0008: br.s IL_000A
IL_000A: ldloc.0
IL_000B: ret
Obviously, we would only use async methods if we have multiple awaits or complicated structures (e.g., only await in a certain if block). In any other case, we should try to go with something lighter. Both, compile-time and runtime will thank us with faster execution.
显然,如果我们有多个await或复杂的结构(例如,仅在某个if块中await ),我们将仅使用async方法。 在任何其他情况下,我们都应尝试轻一些。 编译时和运行时都将感谢我们更快的执行速度。
This is even more true for wrapping standard items in a task. Consider we create a class that implements an interface demanding the following method:
对于将标准项目包装在任务中的情况更是如此。 考虑我们创建一个实现需要以下方法的接口的类:
public Task GetNameAsync()
{
// ...
}
If we already know the name, we could return it directly, but how to wrap it in a task? The simplest case is decorating the method with async, but instead, we could also use Task.FromResult:
如果我们已经知道名称 ,则可以直接将其返回,但是如何将其包装在任务中呢? 最简单的情况是用async装饰方法,但是,我们也可以使用Task.FromResult :
public Task GetNameAsync() => Task.FromResult("constant name");
As a rule of thumb, always look for non-generated solutions first.
根据经验,请始终先寻找非生成的解决方案。
At this point, we could write about certain benefits, e.g., when to use ConfigureAwait(false) and all the things we are allowed to do with async / await these days (e.g., in try-catch blocks), but I feel that many articles (including my own) did that already. Instead, I want to touch the topic of iterator awaits.
在这一点上,我们可以写一些好处,例如,什么时候使用ConfigureAwait(false)以及这些天允许我们使用async / await做的所有事情(例如,在try - catch块中),但是我觉得很多文章(包括我自己的文章)已经做到了。 相反,我想触摸等待迭代器的主题。
Before C# 8, we had no good way of dealing with asynchronous streams. Awaiting the stream is equivalent to only reacting when the stream has finished. The alternative is to await until the first data comes from the stream. This, however, also does not solve the issue as data is not present. What we want is an implicit loop that may await until certain chunks of data are available. The loop ends when the stream is finished.
在C#8之前,我们没有处理异步流的好方法。 等待流等同于仅在流完成时做出React。 另一种选择是等待直到第一个数据来自流。 但是,由于不存在数据,因此这也不能解决问题。 我们想要的是一个隐式循环,该循环可能要await某些数据块可用为止。 流结束时,循环结束。
All this sounds like a boost in the iterator. Again, the following is not the solution:
所有这些听起来都像是在促进迭代器。 同样,以下不是解决方案:
foreach (var item in await GetItems())
{
// ...
}
Potentially, we could wrap the stream resulting in:
潜在地,我们可以包装流,从而导致:
foreach (var getNextItem in GetItems())
{
var item = await getNextItem();
// ...
}
But if there is no next item? We now place a callback. If there is none, we could either receive null or throw an exception. Both scenarios have clear drawbacks. Hence, let's go with a custom data type.
但是,如果没有下一项? 现在,我们放置一个回调。 如果不存在,我们可能会收到null或引发异常。 两种情况都有明显的缺点。 因此,让我们来看一个自定义数据类型。
foreach (var getNextItem in GetItems())
{
var state = await getNextItem();
if (state.Finished)
{
break;
}
var item = state.Current;
// ...
}
It's still all a bit messy, especially from a boilerplate point of view. Thus, we now have await foreach. This one can be used in conjunction with the new IAsyncEnumerable interface.
仍然有些混乱,特别是从样板的角度来看。 因此,现在我们await foreach 。 可以将其与新的IAsyncEnumerable接口结合使用。
public async IAsyncEnumerable GetNumbersAsync()
{
var current = 0;
while (++current < 4)
{
await Task.Delay(500);
yield return current;
}
}
I want to spare you now the details how this is generated (and what is exactly generated), but you can guess it's similar to the structures we inspected beforehand. In the end, it's just the state machine of async / await combined with the iterator.
现在,我想为您提供有关如何生成(以及确切生成的内容)的详细信息,但是您可以猜测它与我们之前检查的结构类似。 最后,它只是async / await与迭代器结合的状态机。
That all of this is similar can be seen directly by inspecting the async enumerable - we see that this is quite like a "normal" enumerable. It just is now dependent on an async enumerator called IAsyncEnumerator (who would have guessed?):
通过检查async可枚举可以直接看出所有这些相似之处-我们看到这很像一个“普通”可枚举。 现在,它仅依赖于一个称为IAsyncEnumerator的async枚举IAsyncEnumerator (谁会猜到?):
public interface IAsyncEnumerator : IAsyncDisposable
{
T Current { get; }
ValueTask MoveNextAsync();
}
Great, so how's the syntax sugar for this looking like?
太好了,那么语法语法看起来如何呢?
await foreach (var item in GetNumbersAsync())
{
// ...
}
Wonderful, so now also this gap is closed! The async iterator can be super powerful especially for streams of events.
太好了,所以现在这个缝隙也缩小了! async迭代器可能超级强大,尤其是对于事件流。
| Useful for | Avoid for |
|---|---|
|
|
| 对...有用 | 避免 |
|---|---|
|
|
模式匹配 (Pattern Matching)
In recent years, the direction of C# has certainly changed a bit. It picked up more and more functional concepts. One of the more interesting concepts is pattern matching. Pattern matching in C# comes in multiple ways, for instance, in an improved is operator. Officially, they call it a "pattern expression".
近年来,C#的方向肯定发生了变化。 它吸收了越来越多的功能概念。 模式匹配是更有趣的概念之一。 C#中的模式匹配有多种方式,例如,改进的is运算符。 正式地,他们称其为“模式表达”。
Beforehand, we had to use all kinds of different operators to achieve something like a type transformation with a subsequent check. For classes, we could have used as:
事先,我们必须使用各种不同的运算符来实现类似类型转换和后续检查的功能。 对于类,我们可以使用as :
var element = node as IElement;
if (element != null)
{
// ...
}
But with the new power of the is operator, such fragments / temporary variables are no longer necessary. We can just write code that reads well.
但是,借助is运算符的新功能,不再需要此类片段/临时变量。 我们可以编写能读得很好的代码。
if (node is IElement element)
{
// ...
}
Perfect, right? Boring you say. Alright, so maybe the new switch control structure is more for your taste. Personally, I would have liked to see a new match construct, however, I can see why new reserved keywords have been avoided and I like the progressive approach.
完美吧? 无聊的你说。 好吧,所以也许新的switch控制结构更符合您的口味。 就个人而言,我希望看到一个新的match结构,但是,我可以看到为什么避免使用新的保留关键字,并且我喜欢渐进式方法。
switch (node)
{
case IElement element:
// ...
break;
}
Let's inspect the generated MSIL code for this construct:
让我们检查为该构造生成的MSIL代码:
IL_0000: nop
IL_0001: ldarg.1
IL_0002: stloc.3
IL_0003: ldloc.3
IL_0004: stloc.0
IL_0005: ldloc.0
IL_0006: brtrue.s IL_000A
IL_0008: br.s IL_0016
IL_000A: ldloc.0
IL_000B: isinst IElement
IL_0010: dup
IL_0011: stloc.1
IL_0012: brfalse.s IL_0016
IL_0014: br.s IL_0018
IL_0016: br.s IL_001E
IL_0018: ldloc.1
IL_0019: stloc.2 // element
IL_001A: br.s IL_001C
IL_001C: br.s IL_001E
IL_001E: ret
Alright, no magic here. It's pretty much the same as if we write:
好吧,这里没有魔术。 就像我们写的一样:
if (node is IElement)
{
var element = (IElement)node;
// ...
}
There are a few subtle differences though. Most notably, we have an explicit cast in the generated MSIL form. Using the previously mentioned pattern expression, we would be even closer to the MSIL code generated by using the new switch construct. Thus, we can really say switch is purely syntax sugar to avoid repetition.
虽然有一些细微的差异。 最值得注意的是,我们以生成的MSIL形式进行了显式转换。 使用前面提到的模式表达式,我们将更接近使用新的switch构造生成的MSIL代码。 因此,我们可以说switch纯粹是语法糖,以避免重复。
Is it just syntax sugar over pattern expressions? Well, at least, it's nice sweet sugar. Especially, since it comes with extensions. In the context of a switch branch, we can use the when keyword to introduce more conditions.
它只是语法表达式之上的语法糖吗? 好吧,至少,它是很好的甜糖。 特别是,因为它带有扩展名。 在switch分支的上下文中,我们可以使用when关键字引入更多条件。
The C# documentation lists a great example:
C#文档列出了一个很好的示例:
switch (shape)
{
case Square s when s.Side == 0:
case Circle c when c.Radius == 0:
return 0;
case Square s:
return s.Side * s.Side;
case Circle c:
return c.Radius * c.Radius * Math.PI;
}
Wonderful - this way, we avoid complicated constructs that would need to use goto or local functions for avoiding repetitions.
很棒-这样,我们避免了需要使用goto或local函数来避免重复的复杂构造。
The C# team even went one step further. Besides explicit types (which would check if a cast is possible), we can also implicitly use the current type. As usual, var is the keyword that triggers type inference.
C#团队甚至更进一步。 除了显式类型(它将检查是否可以进行强制转换)之外,我们还可以隐式使用当前类型。 像往常一样, var是触发类型推断的关键字。
The official documentation mentions the following example:
官方文档中提到以下示例:
switch (shapeDescription)
{
case "circle":
return new Circle(2);
case "square":
return new Square(4);
case "large-circle":
return new Circle(12);
case var o when (o?.Trim().Length ?? 0) == 0:
return null;
}
Hence, the specific white-space case uses the implicit type for triggering additional checks using when. As an alternative, we could have written case string o when. Nevertheless, var should be preferred as it will also stand the test of time in case of refactoring. Furthermore, it will transport to the reader "hey I don't want to check the casting here, I just want to introduce more conditions". After all, transporting intentions to the reader is important.
因此,特定的空白情况使用when来使用隐式类型来触发其他检查。 作为替代方案,我们可以编写case string o when 。 但是,应首选var因为它在重构的情况下也能经受时间的考验。 此外,它将传送给读者“嘿,我不想在这里检查演员表,我只想介绍更多条件”。 毕竟,将意图传达给读者很重要。
| Useful for | Avoid for |
|---|---|
|
|
| 对...有用 | 避免 |
|---|---|
|
|
可空类型 (Nullable Types)
Finally, something about types! Potentially, the most important change in years (or ever) in C# development has come. Nullable types!
最后,关于类型的事! 潜在地,C#开发年来(或曾经)发生的最重要的变化已经到来。 可空类型!
What? I mean, every class represents a heap allocated object that must be created first and otherwise points to a default address known as "null pointer" or simply null. The null reference exception is potentially the most striking one and it speaks about the age of the language (or framework) that it's not covered by default in the type system. Luckily, there are some pretty smart people in the C# language team and they came up with a solution that is both, progressive and fitting.
什么? 我的意思是,每个类表示必须首先创建否则指向被称为“默认地址堆上分配对象null指针”或干脆null 。 null引用异常可能是最引人注目的异常,它说明了类型系统默认情况下未涵盖的语言(或框架)的时代。 幸运的是,C#语言团队中有一些非常聪明的人,他们提出了既进步又合适的解决方案。
Previously, we just received some type information from the methods we have been calling. An example would be the following code:
以前,我们只是从我们一直在调用的方法中收到一些类型信息。 下面的代码是一个示例:
var element = document.QuerySelector("a");
// element is of IElement, but can it be null ?
With nullable types, every type T is non-null. This is now in alignment to value types, which require a wrapper be (fake) nullable (T? or Nullable). For reference types, no such wrapper exists, however, the information is transported via the metadata instead.
对于可空类型,每个类型T都不为null 。 现在,这与值类型保持一致,这要求包装器(伪)可为空( T?或Nullable )。 对于引用类型,不存在这样的包装器,但是,信息是通过元数据传输的。
Since this is a quite sensitive feature, it needs to be enabled first. The following lines must appear in the csproj file of the project where we want to introduce nullable types.
由于这是一个非常敏感的功能,因此需要首先启用它。 以下行必须出现在我们要引入可为空类型的项目的csproj文件中。
8.0
enable Now instead of returning just the type, we can also decorate it using the question mark to signal a return that is potentially null.
现在,我们不仅可以返回类型,还可以使用问号修饰它,以表示可能为null的返回null 。
var element = document.QuerySelector("a");
// element is of IElement?, we should introduce checks!
The same holds true for method signatures. Let's consider the following signature:
方法签名也是如此。 让我们考虑以下签名:
public void Insert(IElement element);
Using the method with an IElement? instance is not allowed. Instead, we have to introduce type guards.
将方法与IElement?一起使用IElement? 实例是不允许的。 相反,我们必须引入类型保护。
public void InsertMaybe(IElement? element)
{
if (!(element is null))
{
// type transformed to IElement from IElement?
Insert(element);
}
}
Long story short: Nullable makes our life easier by detecting where we require guarding and where not. We should treat nullability violations as errors.
长话短说:Nullable通过检测我们需要保护的地方和不需要保护的地方,使我们的生活更轻松。 我们应该将违反可空性行为视为错误。

Every method that works in the nullable context will be annotated accordingly with a NonNullTypes attribute. In addition, references that are nullable are also explicitly marked as Nullable. As a result, the C# compiler is capable of inferring the correct usage also from third-party libraries or BCL where no source code is given.
在可为空的上下文中工作的每个方法都将相应地使用NonNullTypes属性进行注释。 此外,可为空的引用也明确标记为Nullable 。 结果,C#编译器还能够从没有提供源代码的第三方库或BCL中推断出正确的用法。

Besides the generated metadata, everything stays as usual. There are no MSIL implications. This is just an upgrade for making all applications more robust and better.
除了生成的元数据,其他所有内容都照常进行。 没有MSIL的含义。 这仅仅是使所有应用程序更强大和更好的升级。
| Useful for | Avoid for |
|---|---|
|
|
| 对...有用 | 避免 |
|---|---|
|
|
Important: This is a compile-time only mechanism for reference types (i.e., classes) and has nothing to do with Nullable, which is represents a value type (i.e., structs) that can be assigned null.
重要:这是一种针对引用类型(即类)的仅编译时机制,与Nullable无关,后者表示可以分配为null的值类型(即struct)。
外表 (Outlook)
This has been the last part of the series. It's been a pleasure and a joy to compile this collection together.
这是本系列的最后一部分。 一起汇编此收藏是一种荣幸。
With respect to types, the evolution of C# seems to not have finished yet. Languages such as F# (CLR based) or TypeScript (with JS transpilation) show what is possible and how. We can expect a lot more improvements in the ecosystem to arrive within the next couple of years.
关于类型,C#的发展似乎尚未完成。 F#(基于CLR)或TypeScript(带有JS转译)之类的语言显示了可行的方式。 我们可以预期,在未来几年内,生态系统将会有更多的改善。
结论 (Conclusion)
The evolution of C# has not stopped at the used and generated types. We saw that C# gives us some more advanced techniques to gain flexibility without much help from outside tooling. Nevertheless, the help from external tooling gives us much more possibilities without making many sacrifices.
C#的发展并未停止于使用和生成的类型。 我们看到C#为我们提供了一些更高级的技术,以在没有外部工具太多帮助的情况下获得灵活性。 不过,外部工具的帮助为我们提供了更多的可能性,而无需付出很多牺牲。
Personally, I hope that TypeScript's flexible type system can be used as a role model for bringing some advanced compile-time manipulation, creation, and evaluation of types to our tool belt.
我个人希望TypeScript的灵活类型系统可以用作一个角色模型,以便为我们的工具带带来一些高级的编译时操纵,创建和类型评估。
兴趣点 (Points of Interest)
I always showed the non-optimized MSIL code. Once MSIL code gets optimized (or is even running), it may look a little bit different. Here, actually observed differences between the different methods may actually vanish. Nevertheless, as we focused on developer flexibility and efficiency in this article (instead of application performance), all recommendations still hold.
我总是展示未优化的MSIL代码。 一旦MSIL代码得到优化(甚至正在运行),它看起来可能会有所不同。 在这里,实际观察到的不同方法之间的差异可能会消失。 但是,由于本文重点关注开发人员的灵活性和效率(而不是应用程序性能),因此所有建议仍然有效。
If you spot something interesting in another mode (e.g., release mode, x86, ...), then write a comment. Any additional insight is always appreciated!
如果您发现其他模式(例如发布模式,x86等)中有趣的内容,请写一条注释。 任何其他见解总是感激不尽!
翻译自: https://www.codeproject.com/Articles/5247152/Modernize-Your-Csharp-Code-Part-IV-Types