《C++ Primer Plus》学习笔记 — 基础知识补充
《C++ Primer Plus》学习笔记 — 基础知识补充
- 一、简单输入输出
-
- 1、cin和字符串输入
-
- (1)cin.getline(_Elem* _Str, streamsize _Count)
- (2)cin.get(_Elem* _Str, streamsize _Count)
- (3)cin.get()
- 2、文件尾条件 — EOF
-
- (1)cin.fail() 和 cin.eof()
- (2)cin.clear()
- 3、文件输入输出
-
- (1)ofstream
- (2)istream
- 二、数组和指针
-
- 1、数组和指针的区别
- 2、数组地址和数组名
- 三、左值引用
-
- 1、非const引用作为函数参数
- 2、const引用作为函数参数
- 四、内存模型和名称空间
-
- 1、程序组织的方式
-
- (1)头文件常包含内容
- (2)单独编译和库链接
- 2、存储持续性、作用域和链接性
-
- (1)分类
- (2)自动变量
-
- a. 函数调用时的参数传递
- b.函数调用约定
- (3)静态持续变量
- (4)单定义规则和外部变量访问
- (5)cv限定符
- (6)函数链接性
- (7)语言链接性
- (8)动态内存分配
- 3、名称空间
-
- (1)声明区域和潜在作用域
- (2)namespace的引入
- (3)名称空间的其他特征
- (4)名称空间的用途
- 五、有趣的概念
一、简单输入输出
1、cin和字符串输入
#include 如果输入设置为 “1234 5678”,那么这里打印出来的字符串只有 “1234”。因为 cin 默认使用空白(空格、制表符和换行符)来确定字符串的结束为止。那么如果后续字符串 "5678"会留在队列中。当用户再次调用 cin 时会直接保存到新的变量中。因此我们需要一些其他函数来解决该问题。
(1)cin.getline(_Elem* _Str, streamsize _Count)
按行读取字符串。如果字符串个数大于等于 Count 多出的部分将会被保存在输入队列中,数组的最后一个字符用空字符替代。
#include 这个函数还有一个特点:当读取完一行输入时,会丢弃行尾的换行符,并将空字符放到数组末尾。
(2)cin.get(_Elem* _Str, streamsize _Count)
这个函数的调用方式跟上面的 getline 类似,唯一的区别就是不再舍弃行尾的换行符,而是将其留在输入队列中。
那么问题来了,下一次再调用此函数,读取到的将会是换行符。然后该次调用认为已达到末尾,将返回。而换行符将再一次被保存在输入队列中。因此我们需要该函数的一种变体。
(3)cin.get()
此函数读取、返回并舍弃输入队列中的下一个字符串。
使用 get 相比 getline 可以更清楚的知道输入被写入变量的原因是因为输入已达上限还是遇到行尾。
#include 2、文件尾条件 — EOF
当我们使用控制台程序和用户交互,需要判断用户何时结束此次交互。经常使用的条件即为 EOF ,对应 windows 系统的 Ctrl + z。
(1)cin.fail() 和 cin.eof()
这两个函数用于判断是否读取到 EOF。需要注意的是这两个函数并不是从输入队列中取出下一个字符进行判断。而是判断用户从输入队列中已取出的字符串。
#include (2)cin.clear()
有时我们使用用户输入或者开发者在控制台模拟了 EOF 信号后,还想继续进行输入。但是在输入该信号后,cin 对象会将内部的 eof 标志位置为true。因此不可再继续输入。使用 clear 方法可清理该标志。
3、文件输入输出
(1)ofstream
使用方式类似 cout ,需要注意使用 open() 函数打开文件。操作结束使用 close() 函数关闭文件。
#include (2)istream
使用方式类似 cin ,需要注意使用 open() 函数打开文件并使用 is_open 函数判断文件是否打开成功。操作结束使用 close() 函数关闭文件。
#include 二、数组和指针
1、数组和指针的区别
(1)数组相当于常量指针,其本身不可被修改,而指向的内存可以被修改
(2)对二者使用 sizeof 得到的大小不同:
sizeof(数组) 为数组元素个数 * 每个元素的位数
sizeof(类型) 不同编译器为指针类型所分配的内存大小
2、数组地址和数组名
int array[20]{};
cout << "array = " << array << " &array = " << &array;
![]()
这里虽然打印的结果相同但是其含义却不同,这涉及到了指针变量的复合类型。什么是复合类型?就是一个指针变量的类型包括:
(1)其本身是一个指针类型,占据了一个编译器为指针类型所分配的内存空间。在编译时,按照指针的方式对这个变量进行分析。
(2)其指向的类型,这个属性影响了对指向不同类型变量的指针使用运算符时的不同表现,如对 char* 和 int* 进行打印的不同结果,以及使用 ++ 运算符的不同结果。
上述代码中的数组名 array 表示的数组首元素的地址,即指向一个 Int 变量,而数组的地址 &array 指向的是数组本身,即指向一个 int[20] 类型的变量。
int array[20]{};
cout << "array = " << array << endl;
cout << "array + 2 = " << array + 2 << endl;
cout << "int(array + 2) - int(array) = " << int(array + 2) - int(array) << endl;
cout << "&array = " << &array << endl;
cout << "&array + 2 = " << &array + 2 << endl;
cout << "int(&array + 2) - int(&array) " << int(&array + 2) - int(&array) << endl;
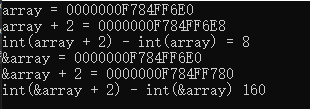
数组地址的赋值:
int array[20]{};
int(*pArrayAddr)[20] = &array;
三、左值引用
1、非const引用作为函数参数
在此情况下,表达式和类型不匹配(即使可以自动转换)的参数是不能作为参数传递给函数的。因为它们都会导致在调用函数的过程中生成临时变量,二者与非 const 引用的声明是不需要同时出现的。
void test(int& _itestPara)
{
_itestPara++;
}
int main()
{
int a = 1;
test(a + 1);
double b = 1.0;
test(b);
return 0;
}
2、const引用作为函数参数
在这种情况下,当实参类型不正确或者正确但不是左值时,仍然可以正确编译并调用函数。但是,调用时会生成临时变量。由于我们这里使用的是 const 引用,表示我们不希望改变参数值。因此生成临时变量就没有什么问题。
#include 左值 可以被引用的数据对象,如变量、数组元素、结构成员、引用和解引用的指针。
非左值 字面常量、包含多项的表达式。
其实左值就是在初始化引用类型变量时可以出现在表达式右边的值。
四、内存模型和名称空间
1、程序组织的方式
头文件:结构声明和函数原型等
源文件:头文件的实现代码
源文件:调用头文件中的方法和属性的代码
(1)头文件常包含内容
函数原型
模板声明
结构或类的声明
常量(#define const)
内联函数声明(可包含定义)
把上述内容声明在头文件的目的是为了让其余源文件可以包含并调用。
那么对于前三项,为什么我们只在头文件中放了声明而非定义呢?我们知道在源文件包含头文件时,在预处理过程中会递归的将包含的内容都放置到包含语句的位置。那么如果有多个文件包含了同一头文件,而该头文件中定义了一个函数或结构,就会出现二义性问题,导致编译不通过。相反,如果我们只是在头文件中包含了结构声明,则是在指导编译器该如何创建对应变量;如果只声明了函数,则是在告诉编译器需要将调用代码跳转到源文件定义处;如果只声明了模板,同样是指导编译器如何生成具体化函数。
对于后两项,它们的链接属性略有不同。简而言之,它们在哪个文件中,就只能作用于当前文件。头文件中的内联函数声明相当于在所有包含该头文件的源文件中都定义了一个内联函数。也就是说其实它们已经不是同一个拷贝了,调用时也不会跳转到相同的地址。
// CLS_ConstTest.h
#pragma once
const int i = 0;
inline void test()
{
int j = 0;
}
class CLS_ConstTest
{
public:
CLS_ConstTest();
};
// CLS_ConstTest.cpp
#include "CLS_ConstTest.h"
#include // main.cpp
#include ![]()
(2)单独编译和库链接
头文件是由预处理器处理的,编译器编译的内容只包含cpp文件。
那么我们知道不同的函数有不同的签名。C++标准并没有对函数签名做出规范。因此不同编译器的库模块和可执行文件之间未必兼容。
2、存储持续性、作用域和链接性
(1)分类
存储持续性:
自动存储持续性 —— 临时变量
静态存储持续性 —— 定义在函数外的变量以及使用static关键字声明的变量
线程存储持续性 —— 与所属线程有相同生命周期的变量,由thread_local修饰
动态存储持续性 —— 使用运算符new分配内存的变量
作用域:
函数、类、文件等
链接性(名称在不同编译单元间的共享):
外部链接性 —— 文件之间可共享
内部链接性 —— 函数之间可共享
无链接性 —— 仅在当前代码块内可访问
针对后两个概念,是以文件为分割线进行分类的。A文件中的变量,其作用域的讨论范围不会超过文件A。根据其链接性的不同,其他文件(如B)可以决定是否导入(即声明)该变量。当被声明之后,该变量在B中可以根据声明的位置确定其作用域。
另外,存储持续性的概念仅对变量生效。作用域的分类对变量有效;但是对于函数,其作用域只能被限定于类或整个文件。
(2)自动变量
自动变量很好理解。我们唯一需要关注的就是,当在内部代码块中声明了和外部代码块某变量名一致的变量时,外部代码块的变量在内部代码块同名变量定义之后不可见,直到离开内部代码块。在C++11之前,auto关键字的唯一作用就是声明一个自动变量,其实就相当于没有用。另外,register关键字的作用也是一样的。
自动变量在运行过程中是存储在栈中的。根据栈的FILO,先声明的变量后被释放。这部分就涉及到了一个有趣的知识,函数调用时的参数传递。
a. 函数调用时的参数传递
以下我们讨论的是x86架构上未开启优化情况下的函数调用方式。其实x64也类似,区别就是x64中传参是参数更多是存放在寄存器中而不是堆栈中。
先来个示例代码:
#include 很明显我们可以看出两个变量的地址距离并不远。我们调试时可以对其进行反汇编,然后对反汇编逐步执行,结合反汇编的代码可以更好的理解参数传递和保存方式(我没学过汇编,半吊子都算不上)。
先看几个汇编的语法:
ebp 扩展基址指针寄存器(extended base pointer) 当前函数栈底指针(大地址)
esp 扩展栈指针寄存器(Extended Stack Pointer) 当前函数栈顶指针(小地址)
mov(dst, src) 将源数据赋值给目标数据
sub(dst, src) 从目标数据中减去源数据的大小
add(dst, src) 从目标数据中加上源数据的大小
push(dst) 变量压栈
eax\ebx\ecx\edx 几个用于存放临时汇编变量(不是我们通常所说的作用域限定在函数内的临时变量)的寄存器

反汇编代码和说明如下(如果用的是vs,有的时候汇编代码中显示的是变量名,如上图的显式符号名不要勾选):
int main()
{
// 以下三行对ebp和esp进行分配。
// 这里 ebp 和 esp 的差值是12。这个数正常情况下是和变量个数及每个变量的字节数一致的。
// 我们这里声明了i,j两个变量,因此应该是8个字节。
// 事实上,把最后一句输出语句去掉这里就变成了8。至于为什么输出语句也占字节,我认为应该是 cout 对象占据的。
00C51050 push ebp
00C51051 mov ebp,esp
00C51053 sub esp,0Ch
00C51056 mov eax,dword ptr ds:[00C55004h]
00C5105B xor eax,ebp
00C5105D mov dword ptr [ebp-4],eax
int i = 0;
00C51060 mov dword ptr [ebp-0Ch],0
int j = 0;
00C51067 mov dword ptr [ebp-8],0
test(i, j);
// 以下四行是函数参数入栈
// 我们开头说过,在函数执行之前就会为定义的变量分配内存,因此现在内存中已经有12个字节的变凉了。
// 那么函数参数想要入栈就要从 esp 开始入栈。
// 同时我们可以看出,入栈的方式就是从原地址 ebp-8 和 ebp-0Ch 的位置复制到寄存器处然后压栈。
00C5106E mov eax,dword ptr [ebp-8]
00C51071 push eax
00C51072 mov ecx,dword ptr [ebp-0Ch]
00C51075 push ecx
// 调用函数。call 指令会同时将下一条指令的地址压入栈中。当函数需要返回时,可以从栈中取址执行。
00C51076 call 00C51000
// 函数已经调用完毕,那么我们就可以把 esp 还原。因为函数的入参所占用的空间已经可以被重写利用了。
00C5107B add esp,8
cout << "i -> " << &i << " j -> " << &j << endl;
...
}
下面看下test函数的反汇编
void test(int _iPara1, int _iPara2)
{
// 这里 esp 和 ebp 和 main 函数中参数压栈后保持一致。但是需要注意,第一个 push 操作会改变 esp 的值
007C1000 push ebp
007C1001 mov ebp,esp
cout << "_iPara1 -> " << &_iPara1 << " _iPara2 -> " << &_iPara2 << endl;
// 理解了我们上面 main 函数的压栈方式,这里 ebp+0Ch ebp+8 就很好理解了,就是去找寻存放在上一个栈顶保存的变量值
007C1003 push 7C16D0h
007C1008 lea eax,[ebp+0Ch]
007C100B push eax
007C100C push 7C3160h
007C1011 lea ecx,[ebp+8]
...
}
00EF104A pop ebp
00EF104B ret
下面画张图描述一下。

b.函数调用约定
上面的行为实则还涉及到了函数调用约定。我们发现参数的入栈顺序和声明顺序正好是相反的;同时,函数返回后,esp的回退是由调用方完成的。这种调用被称为 __cdecl。它也是C++默认的函数调用约定。
调用约定也是和编译器有关的选项。vs的调用约定可以参考参数传递和命名约定。从手册上我们知道还有被调用方清除堆栈的stdcall约定,不过它仅适用于微软。它的好处在于生成的文件大小要小于前者。
(3)静态持续变量
静态持续变量的链接性同样分为三种。首先我们要明确,无论是哪种静态持续变量,其链接性只是代表其可见性的范围。所有的静态持续变量的生存周期都是整个程序运行周期。
int i = 0; // external linkage
static int j = 0; // internal linkage
void func()
{
static int k = 0; // no linkage
}
静态变量的默认赋值初始化由编译器完成,值为0,因此也被称为零初始化的(zero-initialized)变量。当然,用户也可以显式的使用常量表达式初始化和动态初始化静态变量。
int i; // zero initialization
int j = 5; // constant-expression initialization
int k = 5 * calc(); // dynamic initialization
(4)单定义规则和外部变量访问
首先我们先明确声明的分类。C++提供了两种声明:
定义声明 给变量分配内存空间
引用声明 引用已存在的变量,告知编译器该变量的类型及属性
那么什么是单定义规则?相同大小的作用域中,变量还能有一次定义。因此, 如果两个同名变量都具有外部链接性,它们的作用域相当于是整个程序,作用域相同,编译不通过。同时,一个作用域小的变量是可以隐藏一个作用域大的变量的。
那么显然,我们想使用外部文件的外部链接性的变量,需要提供该变量的引用声明。这里需要使用关键字extern。
// TestExtern.h
#pragma once
void testExt();
// TestExtern.cpp
#include "TestExtern.h"
int i;
void testExt()
{
i++;
}
#include ![]()
(5)cv限定符
volatile 告知编译器即使用户代码没有显式的修改修饰的变量,其值也可能发生变化。正常情况下,为了提高访问速度,在相邻几条语句中访问的变量的值将被优化保存到寄存器中。但是使用volatile关键字修饰的变量禁止了这种优化,因为它可能和某个特殊的硬件地址所绑定。
const 唯一需要说明的就是它的链接性为内部链接性。因此对于最开始说的const变量可以声明在头文件我们就能够更好的理解了。如果我们extern关键字修饰const变量,那么其链接性将变为外部链接性。
(6)函数链接性
函数链接性和变量极其类似。回想我们在头文件中定义的函数,如果我们想要使用它们,需要做什么?包含该头文件。这和引用声明完全一致。同时,函数也满足单定义原则。二者的static关键字用法也是一致的。static函数只能被内部使用。
对于内联函数,其链接性为内部的。编译之后生成的中间文件中根本就不存在内联函数声明和定义了了。它们已经被放到调用处了。
(7)语言链接性
C++中默认的语言链接性为C++,即查找和翻译函数名时要把参数类型和顺序带上。然而C语言链接性的函数在编译后生成的函数名只包含函数名称,因为它们不支持重载。如果我们想使用C语言的库文件,在导出接口时,我们可以显式的声明语言链接性:
extern "C" dllTest();
(8)动态内存分配
new作为运算符分配内存我们经常使用。new的第二个作用是作为定位运算符在提前开辟的内存上使用。这种特性可以被用来设置内存管理规程 ,处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
#include ![]()
以上两种new运算都可以重载,可以参考其内部定义方式。
3、名称空间
(1)声明区域和潜在作用域
声明区域:编译器在进入哪部分代码块之前给变量分配空间。
潜在作用域:变量可见的范围。
声明区域 > 潜在作用域
(2)namespace的引入
防止不同头文件中相同变量名。这种情况是很容易出现的。因此在编程时鼓励程序员讲不同模块的外部常量放在不同的名称空间中。
引入名称空间的方法是使用using关键字。
using可以被用作编译指令。这种情况下它和namespace必须结合使用:
using namespace std;
using也可以被用作声明,引入某个名称空间的一个限定名称:
using std::cout;
二者还是有区别的。简而言之。using编译指令引入了整个名称空间,其作用域略大于当前函数,但是又不可被其他函数所见。因此局部变量可以隐藏名称空间内的同名变量。而using声明的变量其作用域等同于临时变量,因此不能再声明同名临时变量。
namespace test
{
int i;
}
int main()
{
using namespace test;
using test::i; // redefinition
int i = 0;
}
(3)名称空间的其他特征
a. 嵌套性,名称空间可以声明内部名称空间。
b. 可以在一个名称空间使用using关键字引入其他名称空间及变量。
c. 可以给名称空间起别名以简化访问。
d. 匿名名称空间,用于内部访问。其链接性为内部。
e. 名称空间中函数的定义和声明同样可以分开放在头文件和源文件中。
f. using声明导入的函数包含所有重载的版本。
namespace
{
int i = 0;
};
namespace namespaceTestForLongName
{
int j = 0;
};
int main()
{
namespace test = namespaceTestForLongName; // c
cout << i; // d
}
(4)名称空间的用途
使用名称空间限定变量范围而非使用全局变量
将全局函数封装到名称空间中防止冲突
五、有趣的概念
副作用 在计算表达式时对某些东西进行了修改。如递增、递减运算符
顺序点 程序执行过程中的一个点,在这里,进入下一步之前将确保对所有的副作用进行了评估。如 , ; || && 等。程序运行到这些符号时,要保证前面的副作用代码都运行完。这也是为什么逻辑运算符能实现短路的效果。