Flink执行流程与源码分析(面试必问,建议收藏)
Flink主要组件

作业管理器(JobManager)
(1) 控制一个应用程序执行的主进程,也就是说,每个应用程序 都会被一个不同的Jobmanager所控制执行
(2) Jobmanager会先接收到要执行的应用程序,这个应用程序会包括:作业图( Job Graph)、逻辑数据流图( ogical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
(3) Jobmanager会把 Jobgraph转换成一个物理层面的 数据流图,这个图被叫做 “执行图”(Executiongraph),包含了所有可以并发执行的任务。Job Manager会向资源管理器( Resourcemanager)请求执行任务必要的资源,也就是 任务管理器(Taskmanager)上的插槽slot。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 Taskmanager上。而在运行过程中Jobmanagera会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(Taskmanager)
(1) Flink中的工作进程。通常在 Flink中会有多个 Taskmanageria运行, 每个 Taskmanageri都包含了一定数量的插槽( slots)。插槽的数量限制了Taskmanageri能够执行的任务数量。
(2) 启动之后, Taskmanager会向资源管理器注册它的插槽;收到资源管理器的指令后, Taskmanageri就会将一个或者多个插槽提供给Jobmanageri调用。Jobmanager就可以向插槽分配任务( tasks)来执行了。
(3) 在执行过程中, 一个 Taskmanagera可以跟其它运行同一应用程序的Taskmanager交换数据。
资源管理器(Resource Manager)
(1) 主要负责管理任务管理器( Task Manager)的 插槽(slot)Taskmanger插槽是 Flink中定义的处理资源单元。
(2) Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如YARNMesos、K8s,以及 standalone部署。
(3) 当 Jobmanager申请插槽资源时, Resourcemanager会将有空闲插槽的Taskmanager?分配给Jobmanager。如果 Resourcemanagery没有足够的插槽来满足 Jobmanager的请求, 它还可以向资源提供平台发起会话,以提供启动 Taskmanager进程的容器。
分发器(Dispatcher)
(1) 可以跨作业运行,它为应用提交提供了REST接口。
(2)当一个应用被提交执行时,分发器就会启动并将应用移交给Jobmanage
(3) Dispatcher他会启动一个 WebUi,用来方便地 展示和监控作业执行的信息。
任务提交流程
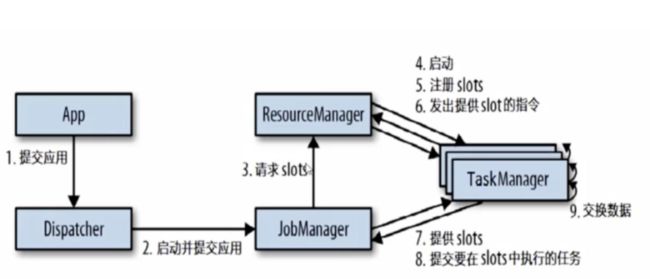
-
提交应用
-
启动并提交应用
-
请求slots
-
任务启动
-
注册slots
-
发出提供slot的指令
-
提供slots
-
提交要在slots中执行的任务
-
交换数据
任务提交流程(YARN)
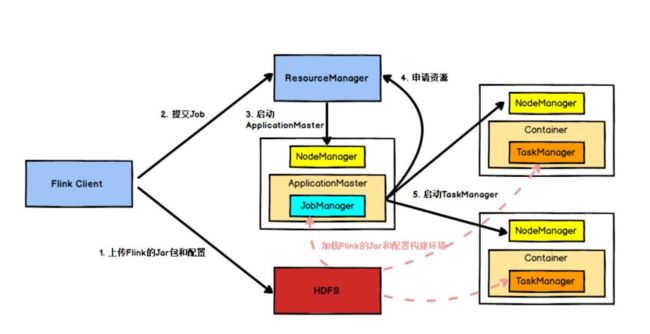
a. Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
b. 随后向 Yarn ResourceManager提交任务ResourceManager分配 Container资源并通知对应的NodeManager启动
c. ApplicationMaster,ApplicationMaster 启动后加载Flink的Jar包和配置构建环境
d. 然后启动JobManager , 之后ApplicationMaster 向ResourceManager 申请资源启动TaskManager
e. ResourceManager 分配 Container 资源后 , 由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
f. NodeManager 加载 Flink 的 Jar 包和配置构建环境并启动 TaskManager
g. TaskManager 启动后向 JobManager 发送心跳包,并等待 JobManager 向其分配任务。
源码分析--集群启动 JobManager 启动分析
JobManager 的内部包含非常重要的三大组件
-
WebMonitorEndpoint
-
ResourceManager
-
Dispatcher
入口,启动主类:StandaloneSessionClusterEntrypoint
// 入 口
StandaloneSessionClusterEntrypoint.main() ClusterEntrypoint.runClusterEntrypoint(entrypoint);
clusterEntrypoint.startCluster();
runCluster(configuration, pluginManager);
// 第一步:初始化各种服务
/**
* 初始化了 主节点对外提供服务的时候所需要的 三大核心组件启动时所需要的基础服务
* 初始化服务,如 JobManager 的 Akka RPC 服务,HA 服务,心跳检查服务,metric service
* 这些服务都是 Master 节点要使用到的一些服务
* 1、commonRpcService: 基于 Akka 的 RpcService 实现。RPC 服务启动 Akka 参与者来接收从 RpcGateway 调用 RPC
* 2、haServices: 提供对高可用性所需的所有服务的访问注册,分布式计数器和领导人选举
* 3、blobServer: 负责侦听传入的请求生成线程来处理这些请求。它还负责创建要存储的目录结构 blob 或临时缓存它们
* 4、heartbeatServices: 提供心跳所需的所有服务。这包括创建心跳接收器和心跳发送者。
* 5、metricRegistry: 跟踪所有已注册的 Metric,它作为连接 MetricGroup 和 MetricReporter
* 6、archivedExecutionGraphStore: 存储执行图ExecutionGraph的可序列化形式。
*/
initializeServices(configuration, pluginManager);
// 创建 DispatcherResourceManagerComponentFactory, 初始化各种组件的
工厂实例
// 其实内部包含了三个重要的成员变量:
// 创建 ResourceManager 的工厂实例
// 创建 Dispatcher 的工厂实例
// 创建 WebMonitorEndpoint 的工厂实例
createDispatcherResourceManagerComponentFactory(configuration);
// 创建 集群运行需要的一些组件:Dispatcher, ResourceManager 等
// 创 建 ResourceManager
// 创 建 Dispatcher
// 创 建 WebMonitorEndpoint
clusterComponent = dispatcherResourceManagerComponentFactory.create(...)
1. initializeServices():初始化各种服务
// 初 始 化 和 启 动 AkkaRpcService, 内 部 其 实 包 装 了 一 个 ActorSystem commonRpcService = AkkaRpcServiceUtils.createRemoteRpcService(...)
// 初始化一个负责 IO 的线程池
ioExecutor = Executors.newFixedThreadPool(...)
// 初始化 HA 服务组件,负责 HA 服务的是:ZooKeeperHaServices haServices = createHaServices(configuration, ioExecutor);
// 初始化 BlobServer 服务端
blobServer = new BlobServer(configuration, haServices.createBlobStore()); blobServer.start();
// 初始化心跳服务组件, heartbeatServices = HeartbeatServices heartbeatServices = createHeartbeatServices(configuration);
// 初始化一个用来存储 ExecutionGraph 的 Store, 实现是:
FileArchivedExecutionGraphStore
archivedExecutionGraphStore = createSerializableExecutionGraphStore(...)
2. createDispatcherResourceManagerComponentFactory(configuration)初始化了多组件的工厂实例
1、DispatcherRunnerFactory,默认实现:DefaultDispatcherRunnerFactory
2、ResourceManagerFactory,默认实现:StandaloneResourceManagerFactory
3、RestEndpointFactory,默认实现:SessionRestEndpointFactory
clusterComponent = dispatcherResourceManagerComponentFactory
.create(configuration, ioExecutor, commonRpcService, haServices,
blobServer, heartbeatServices, metricRegistry,
archivedExecutionGraphStore,
new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService()),
this);
3. 创建 WebMonitorEndpoint
/*************************************************
* 创建 WebMonitorEndpoint 实例, 在 Standalone 模式下:DispatcherRestEndpoint
* 1、restEndpointFactory = SessionRestEndpointFactory
* 2、webMonitorEndpoint = DispatcherRestEndpoint
* 3、highAvailabilityServices.getClusterRestEndpointLeaderElectionService() = ZooKeeperLeaderElectionService
* 当前这个 DispatcherRestEndpoint 的作用是:
* 1、初始化的过程中,会一大堆的 Handler
* 2、启动一个 Netty 的服务端,绑定了这些 Handler
* 3、当 client 通过 flink 命令执行了某些操作(发起 restful 请求), 服务端由 webMonitorEndpoint 来执行处理
* 4、举个例子: 如果通过 flink run 提交一个 Job,那么最后是由 webMonitorEndpoint 中的 JobSubmitHandler 来执行处理
* 5、补充一个:job 由 JobSubmitHandler 执行完毕之后,转交给 Dispatcher 去调度执行
*/
webMonitorEndpoint = restEndpointFactory.createRestEndpoint(
configuration, dispatcherGatewayRetriever, resourceManagerGatewayRetriever,
blobServer, executor, metricFetcher,
highAvailabilityServices.getClusterRestEndpointLeaderElectionService(),
fatalErrorHandler
);
4. 创建 resourceManager
/*************************************************
* 创建 StandaloneResourceManager 实例对象
* 1、resourceManager = StandaloneResourceManager
* 2、resourceManagerFactory = StandaloneResourceManagerFactory
*/
resourceManager = resourceManagerFactory.createResourceManager(
configuration, ResourceID.generate(),
rpcService, highAvailabilityServices, heartbeatServices,
fatalErrorHandler, new ClusterInformation(hostname, blobServer.getPort()),
webMonitorEndpoint.getRestBaseUrl(), metricRegistry, hostname
);
protected ResourceManager createResourceManager(
Configuration configuration,
ResourceID resourceId,
RpcService rpcService,
HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices,
FatalErrorHandler fatalErrorHandler,
ClusterInformation clusterInformation,
@Nullable String webInterfaceUrl,
ResourceManagerMetricGroup resourceManagerMetricGroup,
ResourceManagerRuntimeServices resourceManagerRuntimeServices) {
final Time standaloneClusterStartupPeriodTime = ConfigurationUtils.getStandaloneClusterStartupPeriodTime(configuration);
/*************************************************
* 注释: 得到一个 StandaloneResourceManager 实例对象
*/
return new StandaloneResourceManager(
rpcService,
resourceId,
highAvailabilityServices,
heartbeatServices,
resourceManagerRuntimeServices.getSlotManager(),
ResourceManagerPartitionTrackerImpl::new,
resourceManagerRuntimeServices.getJobLeaderIdService(),
clusterInformation,
fatalErrorHandler,
resourceManagerMetricGroup,
standaloneClusterStartupPeriodTime,
AkkaUtils.getTimeoutAsTime(configuration)
);
}
/**
requestSlot():接受 solt请求
sendSlotReport(..): 将solt请求发送TaskManager
registerJobManager(...): 注册job管理者。 该job指的是 提交给flink的应用程序
registerTaskExecutor(...): 注册task执行者。
**/
public ResourceManager(RpcService rpcService, ResourceID resourceId, HighAvailabilityServices highAvailabilityServices,
HeartbeatServices heartbeatServices, SlotManager slotManager, ResourceManagerPartitionTrackerFactory clusterPartitionTrackerFactory,
JobLeaderIdService jobLeaderIdService, ClusterInformation clusterInformation, FatalErrorHandler fatalErrorHandler,
ResourceManagerMetricGroup resourceManagerMetricGroup, Time rpcTimeout) {
/*************************************************
* 注释: 当执行完毕这个构造方法的时候,会触发调用 onStart() 方法执行
*/
super(rpcService, AkkaRpcServiceUtils.createRandomName(RESOURCE_MANAGER_NAME), null);
protected RpcEndpoint(final RpcService rpcService, final String endpointId) {
this.rpcService = checkNotNull(rpcService, "rpcService");
this.endpointId = checkNotNull(endpointId, "endpointId");
/*************************************************
* 注释:ResourceManager 或者 TaskExecutor 中的 RpcServer 实现
* 以 ResourceManager 为例说明:
* 启动 ResourceManager 的 RPCServer 服务
* 这里启动的是 ResourceManager 的 Rpc 服务端。
* 接收 TaskManager 启动好了而之后, 进行注册和心跳,来汇报 Taskmanagaer 的资源情况
* 通过动态代理的形式构建了一个Server
*/
this.rpcServer = rpcService.startServer(this);
5. 在创建resourceManager同级:启动任务接收器Starting Dispatcher
/*************************************************
* 创建 并启动 Dispatcher
* 1、dispatcherRunner = DispatcherRunnerLeaderElectionLifecycleManager
* 2、dispatcherRunnerFactory = DefaultDispatcherRunnerFactory
* 第一个参数:ZooKeeperLeaderElectionService
* -
* 老版本: 这个地方是直接创建一个 Dispatcher 对象然后调用 dispatcher.start() 来启动
* 新版本: 直接创建一个 DispatcherRunner, 内部就是要创建和启动 Dispatcher
* -
* DispatcherRunner 是对 Dispatcher 的封装。
* DispatcherRunner被创建的代码的内部,会创建 Dispatcher并启动
*/
log.debug("Starting Dispatcher.");
dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner(
highAvailabilityServices.getDispatcherLeaderElectionService(), fatalErrorHandler,
// TODO_ZYM 注释: 注意第三个参数
new HaServicesJobGraphStoreFactory(highAvailabilityServices),
ioExecutor, rpcService, partialDispatcherServices
);
Dispatcher 启动后,将会等待任务提交,如果有任务提交,则会经过submitJob(...)函数进入后续处理。
提交(一个Flink应用的提交必须经过三个graph的转换)
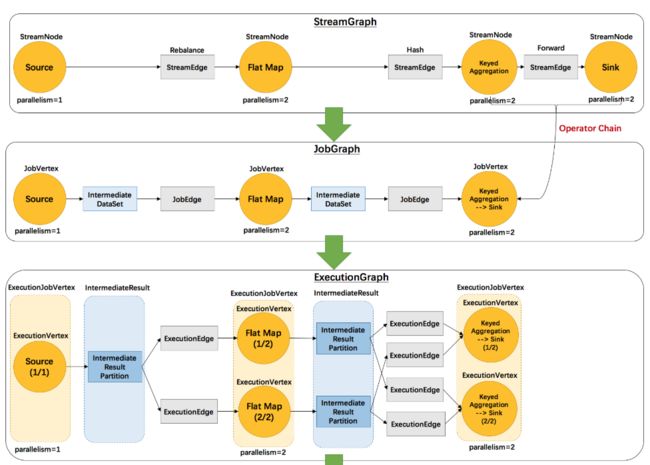
首先看下一些名词
StreamGraph
是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。可以用一个 DAG 来表示),DAG 的顶点是 StreamNode,边是 StreamEdge,边包含了由哪个 StreamNode 依赖哪个 StreamNode。
-
StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
-
StreamEdge:表示连接两个StreamNode的边。

DataStream 上常见的 transformation 有 map、flatmap、filter等(见DataStream Transformation了解更多)。这些transformation会构造出一棵 StreamTransformation 树,通过这棵树转换成 StreamGraph
以map方法为例,看看源码
public SingleOutputStreamOperator map(MapFunction mapper) {
// 通过java reflection抽出mapper的返回值类型
TypeInformation outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
// 返回一个新的DataStream,SteramMap 为 StreamOperator 的实现类
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
public SingleOutputStreamOperator transform(String operatorName, TypeInformation outTypeInfo, OneInputStreamOperator operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// 新的transformation会连接上当前DataStream中的transformation,从而构建成一棵树
OneInputTransformation resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({ "unchecked", "rawtypes" })
SingleOutputStreamOperator returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 所有的transformation都会存到 env 中,调用execute时遍历该list生成StreamGraph
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
map转换将用户自定义的函数MapFunction包装到StreamMap这个Operator中,再将StreamMap包装到OneInputTransformation,最后该transformation存到env中,当调用env.execute时,遍历其中的transformation集合构造出StreamGraph
JobGraph
(1) StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点。

-
将并不涉及到 shuffle 的算子进行合并。
-
对于同一个 operator chain 里面的多个算子,会在同一个 task 中执行。
-
对于不在同一个 operator chain 里的算子,会在不同的 task 中执行。
(2) JobGraph 用来由 JobClient 提交给 JobManager,是由顶点(JobVertex)、中间结果(IntermediateDataSet)和边(JobEdge)组成的 DAG 图。
(3) JobGraph 定义作业级别的配置,而每个顶点和中间结果定义具体操作和中间数据的设置。
JobVertex
JobVertex 相当于是 JobGraph 的顶点。经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
IntermediateDataSet
JobVertex的输出,即经过operator处理产生的数据集。
JobEdge
job graph中的一条数据传输通道。source 是IntermediateDataSet,sink 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
(1) 首先是通过API会生成transformations,通过transformations会生成StreamGraph。
(2)将StreamGraph的某些StreamNode Chain在一起生成JobGraph,前两步转换都是在客户端完成。
(3)最后会将JobGraph转换为ExecutionGraph,相比JobGraph会增加并行度的概念,这一步是在Jobmanager里完成。
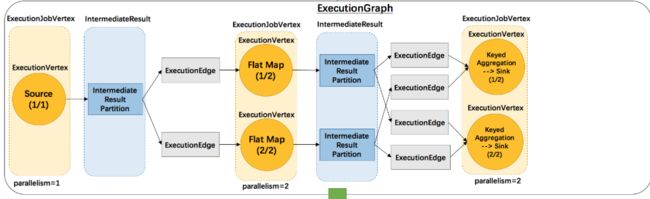
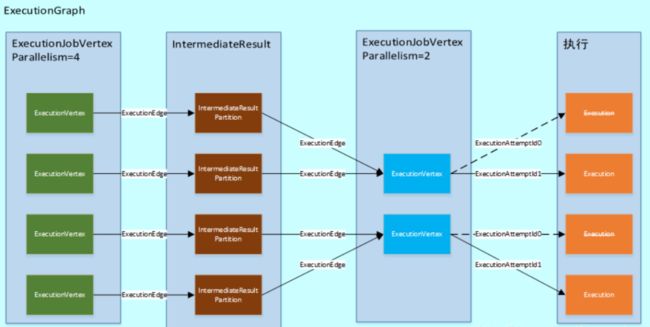
ExecutionJobVertex
ExecutionJobVertex一一对应JobGraph中的JobVertex
ExecutionVertex
一个ExecutionJobVertex对应n个ExecutionVertex,其中n就是算子的并行度。ExecutionVertex就是并行任务的一个子任务
Execution
Execution 是对 ExecutionVertex 的一次执行,通过 ExecutionAttemptId 来唯一标识。
IntermediateResult
在 JobGraph 中用 IntermediateDataSet 表示 JobVertex 的对外输出,一个 JobGraph 可能有 n(n >=0) 个输出。在 ExecutionGraph 中,与此对应的就是 IntermediateResult。每一个 IntermediateResult 就有 numParallelProducers(并行度) 个生产者,每个生产者的在相应的 IntermediateResult 上的输出对应一个 IntermediateResultPartition。IntermediateResultPartition 表示的是 ExecutionVertex 的一个输出分区
ExecutionEdge
ExecutionEdge 表示 ExecutionVertex 的输入,通过 ExecutionEdge 将 ExecutionVertex 和 IntermediateResultPartition 连接起来,进而在不同的 ExecutionVertex 之间建立联系。
ExecutionGraph的构建
-
构建JobInformation
-
构建ExecutionGraph
-
将JobGraph进行拓扑排序,获取sortedTopology顶点集合
// ExecutionGraphBuilder
public static ExecutionGraph buildGraph(
@Nullable ExecutionGraph prior,
JobGraph jobGraph,
...) throws JobExecutionException, JobException {
// 构建JobInformation
// 构建ExecutionGraph
// 将JobGraph进行拓扑排序,获取sortedTopology顶点集合
List sortedTopology = jobGraph.getVerticesSortedTopologicallyFromSources();
executionGraph.attachJobGraph(sortedTopology);
return executionGraph;
}
-
构建ExecutionJobVertex,连接IntermediateResultPartition和ExecutionVertex
//ExecutionGraph
public void attachJobGraph(List topologiallySorted) throws JobException {
for (JobVertex jobVertex : topologiallySorted) {
// 构建ExecutionJobVertex
ExecutionJobVertex ejv = new ExecutionJobVertex(
this,
jobVertex,
1,
maxPriorAttemptsHistoryLength,
rpcTimeout,
globalModVersion,
createTimestamp);
// 连接IntermediateResultPartition和ExecutionVertex
ev.connectToPredecessors(this.intermediateResults);
}
// ExecutionJobVertex
public void connectToPredecessors(Map intermediateDataSets) throws JobException {
List inputs = jobVertex.getInputs();
for (int num = 0; num < inputs.size(); num++) {
JobEdge edge = inputs.get(num);
IntermediateResult ires = intermediateDataSets.get(edge.getSourceId());
this.inputs.add(ires);
int consumerIndex = ires.registerConsumer();
for (int i = 0; i < parallelism; i++) {
ExecutionVertex ev = taskVertices[i];
ev.connectSource(num, ires, edge, consumerIndex);
}
}
}
拆分计划(可执行能力)
// ExecutionVertex
public void connectSource(int inputNumber, IntermediateResult source, JobEdge edge, int consumerNumber) {
final DistributionPattern pattern = edge.getDistributionPattern();
final IntermediateResultPartition[] sourcePartitions = source.getPartitions();
ExecutionEdge[] edges;
switch (pattern) {
// 下游 JobVertex 的输入 partition 算法,如果是 forward 或 rescale 的话为 POINTWISE
case POINTWISE:
edges = connectPointwise(sourcePartitions, inputNumber);
break;
// 每一个并行的ExecutionVertex节点都会链接到源节点产生的所有中间结果IntermediateResultPartition
case ALL_TO_ALL:
edges = connectAllToAll(sourcePartitions, inputNumber);
break;
default:
throw new RuntimeException("Unrecognized distribution pattern.");
}
inputEdges[inputNumber] = edges;
for (ExecutionEdge ee : edges) {
ee.getSource().addConsumer(ee, consumerNumber);
}
}
private ExecutionEdge[] connectPointwise(IntermediateResultPartition[] sourcePartitions, int inputNumber) {
final int numSources = sourcePartitions.length;
final int parallelism = getTotalNumberOfParallelSubtasks();
// 如果并发数等于partition数,则一对一进行连接
if (numSources == parallelism) {
return new ExecutionEdge[] { new ExecutionEdge(sourcePartitions[subTaskIndex], this, inputNumber) };
}
// 如果并发数大于partition数,则一对多进行连接
else if (numSources < parallelism) {
int sourcePartition;
if (parallelism % numSources == 0) {
int factor = parallelism / numSources;
sourcePartition = subTaskIndex / factor;
}
else {
float factor = ((float) parallelism) / numSources;
sourcePartition = (int) (subTaskIndex / factor);
}
return new ExecutionEdge[] { new ExecutionEdge(sourcePartitions[sourcePartition], this, inputNumber) };
}
// 果并发数小于partition数,则多对一进行连接
else {
if (numSources % parallelism == 0) {
int factor = numSources / parallelism;
int startIndex = subTaskIndex * factor;
ExecutionEdge[] edges = new ExecutionEdge[factor];
for (int i = 0; i < factor; i++) {
edges[i] = new ExecutionEdge(sourcePartitions[startIndex + i], this, inputNumber);
}
return edges;
}
else {
float factor = ((float) numSources) / parallelism;
int start = (int) (subTaskIndex * factor);
int end = (subTaskIndex == getTotalNumberOfParallelSubtasks() - 1) ?
sourcePartitions.length :
(int) ((subTaskIndex + 1) * factor);
ExecutionEdge[] edges = new ExecutionEdge[end - start];
for (int i = 0; i < edges.length; i++) {
edges[i] = new ExecutionEdge(sourcePartitions[start + i], this, inputNumber);
}
return edges;
}
}
}
private ExecutionEdge[] connectAllToAll(IntermediateResultPartition[] sourcePartitions, int inputNumber) {
ExecutionEdge[] edges = new ExecutionEdge[sourcePartitions.length];
for (int i = 0; i < sourcePartitions.length; i++) {
IntermediateResultPartition irp = sourcePartitions[i];
edges[i] = new ExecutionEdge(irp, this, inputNumber);
}
return edges;
}
-
返回ExecutionGraph
TaskManager
TaskManager启动
public static void runTaskManager(Configuration configuration, ResourceID resourceId) throws Exception {
//主要初始化一堆的service,并新建一个org.apache.flink.runtime.taskexecutor.TaskExecutor
final TaskManagerRunner taskManagerRunner = new TaskManagerRunner(configuration,resourceId);
//调用TaskExecutor的start()方法
taskManagerRunner.start();
}
TaskExecutor :submitTask()
接着的重要函数是shumitTask()函数,该函数会通过AKKA机制,向TaskManager发出一个submitTask的消息请求,TaskManager收到消息请求后,会执行submitTask()方法。(省略了部分代码)。
public CompletableFuture submitTask(
TaskDeploymentDescriptor tdd,
JobMasterId jobMasterId,
Time timeout) {
jobInformation = tdd.getSerializedJobInformation().deserializeValue(getClass().getClassLoader());
taskInformation = tdd.getSerializedTaskInformation().deserializeValue(getClass().getClassLoader());
TaskMetricGroup taskMetricGroup = taskManagerMetricGroup.addTaskForJob(xxx);
InputSplitProvider inputSplitProvider = new RpcInputSplitProvider(xxx);
TaskManagerActions taskManagerActions = jobManagerConnection.getTaskManagerActions();
CheckpointResponder checkpointResponder = jobManagerConnection.getCheckpointResponder();
LibraryCacheManager libraryCache = jobManagerConnection.getLibraryCacheManager();
ResultPartitionConsumableNotifier resultPartitionConsumableNotifier = jobManagerConnection.getResultPartitionConsumableNotifier();
PartitionProducerStateChecker partitionStateChecker = jobManagerConnection.getPartitionStateChecker();
final TaskLocalStateStore localStateStore = localStateStoresManager.localStateStoreForSubtask(
jobId,
tdd.getAllocationId(),
taskInformation.getJobVertexId(),
tdd.getSubtaskIndex());
final JobManagerTaskRestore taskRestore = tdd.getTaskRestore();
final TaskStateManager taskStateManager = new TaskStateManagerImpl(
jobId,
tdd.getExecutionAttemptId(),
localStateStore,
taskRestore,
checkpointResponder);
//新建一个Task
Task task = new Task(xxxx);
log.info("Received task {}.", task.getTaskInfo().getTaskNameWithSubtasks());
boolean taskAdded;
try {
taskAdded = taskSlotTable.addTask(task);
} catch (SlotNotFoundException | SlotNotActiveException e) {
throw new TaskSubmissionException("Could not submit task.", e);
}
if (taskAdded) {
//启动任务
task.startTaskThread();
return CompletableFuture.completedFuture(Acknowledge.get());
}
最后创建执行Task的线程,然后调用startTaskThread()来启动具体的执行线程,Task线程内部的run()方法承载了被执行的核心逻辑。
Task是执行在TaskExecutor进程里的一个线程,下面来看看其run方法
(1) 检测当前状态,正常情况为CREATED,如果是FAILED或CANCELING直接返回,其余状态将抛异常。
(2) 读取DistributedCache文件。
(3) 启动ResultPartitionWriter和InputGate。
(4) 向taskEventDispatcher注册partitionWriter。
(5) 根据nameOfInvokableClass加载对应的类并实例化。
(6) 将状态置为RUNNING并执行invoke方法。
public void run() {
while (true) {
ExecutionState current = this.executionState;
invokable = loadAndInstantiateInvokable(userCodeClassLoader, nameOfInvokableClass);
network.registerTask(this);
Environment env = new RuntimeEnvironment(. . . . );
invokable.setEnvironment(env);
// actual task core work
if (!transitionState(ExecutionState.DEPLOYING, ExecutionState.RUNNING)) {
}
// notify everyone that we switched to running
notifyObservers(ExecutionState.RUNNING, null);
executingThread.setContextClassLoader(userCodeClassLoader);
// run the invokable
invokable.invoke();
if (transitionState(ExecutionState.RUNNING, ExecutionState.FINISHED)) {
notifyObservers(ExecutionState.FINISHED, null);
}
Finally{
// free the network resources
network.unregisterTask(this);
// free memory resources
if (invokable != null) {
memoryManager.releaseAll(invokable);
}
libraryCache.unregisterTask(jobId, executionId);
removeCachedFiles(distributedCacheEntries, fileCache);总结
整体的流程与架构可能三两张图或者三言两语就可以勾勒出画面,但是背后源码的实现是艰辛的。源码的复杂度和当初设计框架的抓狂感,我们只有想象。现在我们只是站在巨人的肩膀上去学习。
本篇的主题是"Flink架构与执行流程",做下小结,Flink on Yarn的提交执行流程:
1 Flink任务提交后,Client向HDFS上传Flink的Jar包和配置。
2 向Yarn ResourceManager提交任务。
3 ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster。
4 ApplicationMaster启动后加载Flink的Jar包和配置构建环境。
5 启动JobManager之后ApplicationMaster向ResourceManager申请资源启动TaskManager。
6 ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点
7 NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager。
8 TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
大数据左右手
技术如同手中的水有了生命似的,汇聚在了一起。作为大数据开发工作者,致力于大数据技术的学习与工作,分享大数据原理、架构、实时、离线、面试与总结,分享生活思考与读书见解。总有适合你的那一篇。
关注公众号!!!
和我联系吧,加群交流大数据知识,一起成长~~~