otter,阿里巴巴分布式数据库同步系统
微信公众号:大数据左右手
专注于大数据技术,人工智能和编程语言
个人既可码代码也可以码文字。欢迎转发与关注
otter官网介绍项目背景
otter文档地址
https://github.com/alibaba/otter/wiki
otter项目地址
https://github.com/alibaba/otter
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otter4
涉及200+个数据库实例之间的同步
目前同步规模
-
同步数据量6亿
-
文件同步1.5TB(2000w张图片)
-
涉及200+个数据库实例之间的同步
-
80+台机器的集群规模
otter能解决什么
-
异构库同步
a. mysql -> mysql/oracle. (目前开源版本只支持mysql增量,目标库可以是mysql或者oracle,取决于canal的功能) -
单机房同步 (数据库之间RTT < 1ms)
a. 数据库版本升级
b. 数据表迁移
c. 异步二级索引 -
异地机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同步,RTT > 200ms,亮点)
a. 机房容灾 -
双向同步
a. 避免回环算法 (通用的解决方案,支持大部分关系型数据库)https://github.com/alibaba/otter/wiki/Otter%E5%8F%8C%E5%90%91%E5%9B%9E%E7%8E%AF%E6%8E%A7%E5%88%B6
b. 数据一致性算法 (保证双A机房模式下,数据保证最终一致性,亮点)https://github.com/alibaba/otter/wiki/Otter%E6%95%B0%E6%8D%AE%E4%B8%80%E8%87%B4%E6%80%A7
-
文件同步
a. 站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片)
工作原理

原理描述
-
基于Canal开源产品,获取数据库增量日志数据
什么是Canal: 点击了解Canal -
典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上 -
基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作
名词解释
-
Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
-
Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
-
DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
-
DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
-
DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
-
ColumnPair : 定义字段映射关系
-
ColumnGroup : 定义字段映射组
-
Node : 处理同步过程的工作节点,对应一个jvm
otter的S/E/T/L stage阶段模型
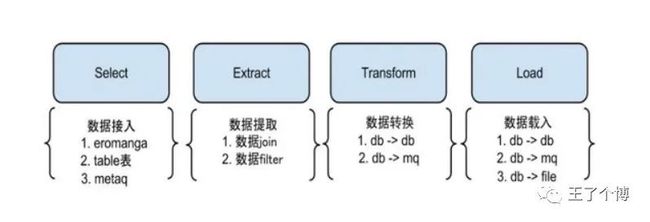
说明:为了更好的支持系统的扩展性和灵活性,将整个同步流程抽象为Select/Extract/Transform/Load,这么4个阶段.
Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
Extract/Transform/Load 阶段:类似于数据仓库的ETL模型,具体可为数据join,数据转化,数据Load的
安装操作
1.Tar包下载
https://github.com/alibaba/otter/releases
manager.deployer-4.2.18.tar.gz
node.deployer-4.2.18.tar.gz
Source code(zip) 或者 Source code(tar.gz) 这里面有你需要的初始化otter manager系统表(otter-manager-schema.sql)
以上三个都要下载
![]()
2.初始化otter manager的系统表结构
-
otter manager依赖于mysql进行配置信息的存储,所以需要预先安装mysql,并初始化otter manager的系统表结构
解压在windows也行,tar.gz上传到集群解压也可以,主要目的是找到otter-manager-schema.sql(/deployer/src/main/resources/sql/otter-manager-schema.sql)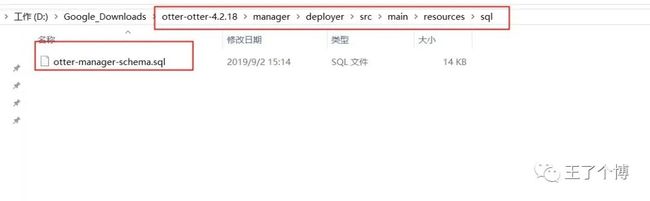
a. 安装mysql
b. 创建otter数据库后,将脚本导进去,初始化otter manager系统表
1source otter-manager-schema.sql
到mysql上去看下执行的效果

3. manager安装
修改manager配置文件
对manager.deployer-4.2.18.tar.gz 解压后,找到conf/otter.properties
改动的是我后面加解释的部分
1## otter manager domain name
2otter.domainName = bigdata101 ##修改为本机的ip
3## otter manager http port
4otter.port = 8099 ##对外访问的端口号
5## jetty web config xml
6otter.jetty = jetty.xml
7
8## otter manager database config
9otter.database.driver.class.name = com.mysql.jdbc.Driver
10otter.database.driver.url = jdbc:mysql://bigdata101:3306/otter ##otter数据的配置
11otter.database.driver.username = root ##数据库的账号
12otter.database.driver.password = root ##数据库的密码
13
14## default zookeeper address
15otter.zookeeper.cluster.default = bigdata101:2181 ##对应集群zk的地址
16## default zookeeper sesstion timeout = 60s
17otter.zookeeper.sessionTimeout = 60000
启动manager
1/manager/bin/startup.sh
启动成功后浏览器访问 http://127.0.0.1:8099 出现otter的页面,初始密码为:admin/admin,目前:匿名用户只有只读查看的权限,登录为管理员才可以有操作权限

关闭manager
1/manager/bin/stop.sh
4. node安装
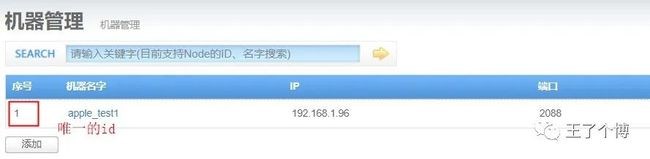
node会受ottermanager进行管理,所以需要预先安装otter manager,完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id
-
添加zookeeper
机器管理→zookeeper管理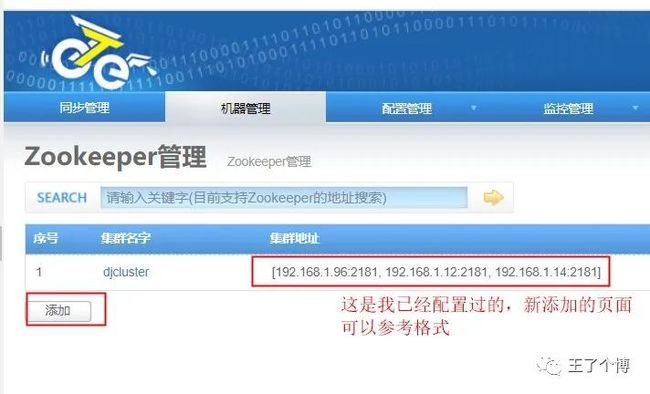
-
添加 node
机器管理→Node管理
-
配置nid
机器添加完成后,跳转到机器列表页面,获取对应的机器序号nid
在 node-deployer/conf 下有nid
把nid配置进去即可(vim)或者
1echo 1 >~/node-deployer/conf/nid
配置otter.properties(位置:/node-deployer/conf/otter.properties)
1## otter node root dir
2otter.nodeHome = /opt/module/otter/node-deployer ## node-deployer绝对路径
3## otter arbitrate & node connect manager config
4otter.manager.address = bigdata101:1099 ## 运行ip地址,我这里通过了地址映射
启动node
1/node-deployer/bin/startup.sh
查看“机器管理-Node管理”页面,对应的节点状态,如果变为了已启动,代表已经正常启动
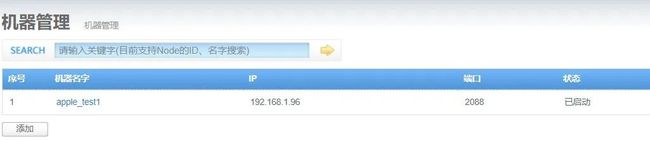
关闭node
1/node-deployer/bin/stop.sh
实战
1. 数据库开启binlog
-
什么是Binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗 。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用MySQLBinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件 -
Binlog的开启
1vi /etc/my.cnf
2
3## 添加
4
5server-id=1
6
7log-bin=mysql-bin
8
9binlog_format=row
10
11binlog-do-db=xx ## 指定数据库
2. 添加canal
Otter使用canal开源产品获取数据库增量日志数据,可以把cannal看作是源库的一个伪slave
原理:canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议,mysql master收到dump请求,开始推送binarylog给slave(也就是canal), canal解析binary log对象
在Otter Manager“配置管理-canal配置”页面点击添加
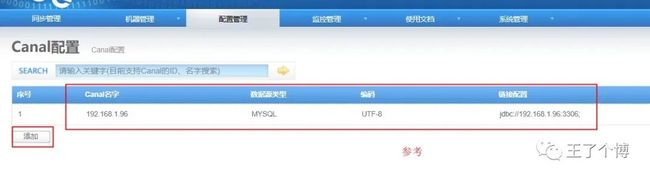
3. 添加数据源 ,源库和目标库的schema需要一致,不然无法执行ddl语句

4. 添加数据表配置
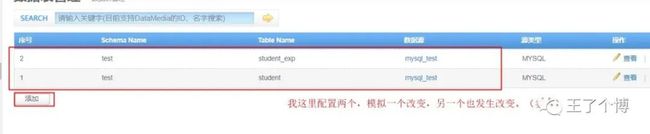
5. 添加一个channel

6. 配置一个pipeline
添加channel成功后,点击Channel名字,进入Pipeline管理页面,添加一个pipeline
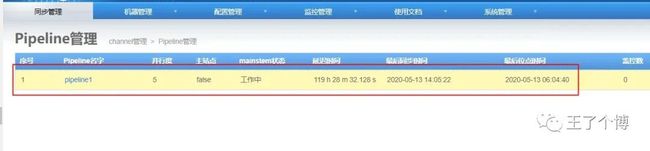
7. 添加映射关系

8. 启用同步
返回Channel管理页面, 点击“启用”,运行状态就变为“运行”

9. 现在可以新增一个表,插入记录,查看数据是否同步过去了
aria2简单介绍
node节点进行跨机房传输时,会使用到HTTP多线程传输技术,目前主要依赖了aria2c做为其下载客户端,所以我们现在需要安装aria2
1解压缩 aria2
2./configure
3
4make
5
6make install
将ariar2c加入path中
1vi /root/.bash_profile
2
3在PATH的末尾加上:/usr/local/bin 分号的作用是与之前的隔开。
4
5source /root/.bash_profile
微信公众号:大数据左右手
人要去的地方,除了远方,还有未来
欢迎关注我,一起学习,一起进步!