STL容器的底层数据结构
本文部分内容转自此博客
目录
-
- vector
- list
- deque
- stack
- queue
- heap
- priority_queue
- set
- map
- multiset/multimap
- 哈希表hashtable (底层数据结构)
- unordered_set
- unordered_map
- unordered_multiset/unordered_multimap
- 各容器的具体用法
- 各容器的详细源码剖析
vector
vector采用的数据结构非常简单:线性连续空间。它以两个迭代器start和finish分别指向配置得来的连续空间中目前已被使用的范围,并以迭代器end_of_storage指向整块连续空间(含备用空间)的尾端。
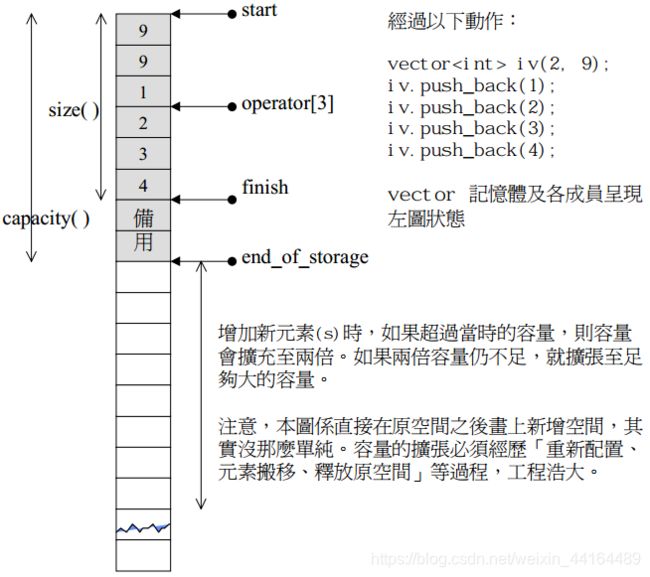
注意:所谓动态增加大小,并不是在原来空间之后接续新空间(因为无法保证原空间之后尚有可供分配的空间),而是以原来大小的的两倍另外分配一块较大空间,然后将原内容拷贝过来,然后才开始在原内容之后构造新元素,并释放原空间。因此,对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效啦。
list
相对于vector的连续线性空间,list就显得复杂许多,它的好处就是插入或删除一个元素,就配置或删除一个元素空间。对于任何位置的元素的插入或删除,list永远是常数时间。
list本身和节点是不同的结构,需要分开设计。以下是STL list的节点node结构:
template <class T>
class __list_node {
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
};
这是一个双向链表
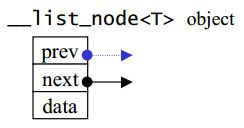
SGI list不仅是一个双向链表,而且是一个环状双向链表。只需一个指针就可遍历整个链表。
deque
deque和vector的最大差异,一在于deque允许常数时间内对起头端进行插入或移除操作,二在于deque没有所谓容量(capacity)概念,因为它是以分段连续空间组合而成,随时可以增加一段新的空间连接起来。
deque由一段一段连续空间组成,一旦有必要在deque的前端或尾端增加新空间,便配置一段连续空间,串接在整个deque的前端或尾端。deque的最大任务,便是在这些分段的连续空间上,维护其整体连续的假象,并提供随机存取的接口,避开了“重新配置、复制、释放”的轮回,代价是复杂的迭代器结构。
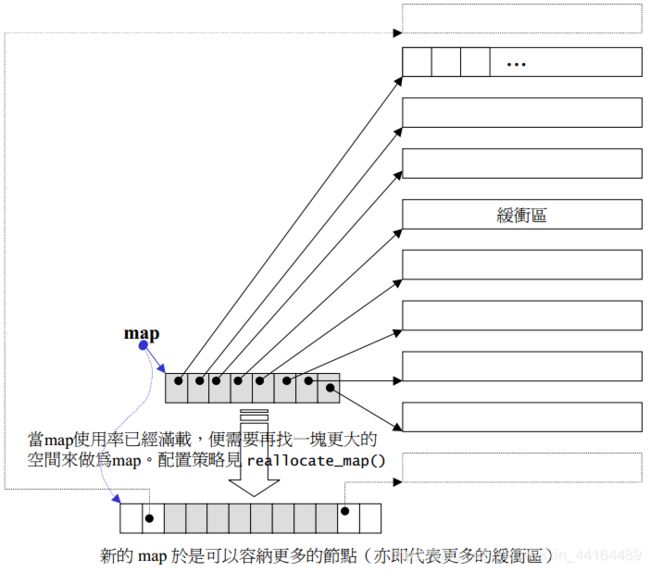
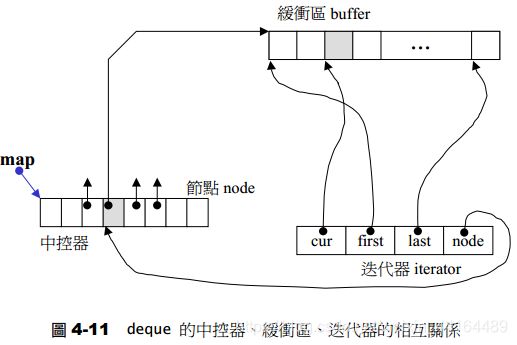
deque迭代器
迭代器首先必须指出分段连续空间在哪里,其次它必须能够判断自己是否已经处在缓冲区的边缘,如果是,一旦前进或后退就必须跳跃下一个缓冲区,为了能够正常跳跃,deque必须随时掌握管控中心。
迭代器结构:
template <class T, class Ref, class Ptr, size_t BufSiz>
struct __deque_iterator { // 未继承 std::iterator
// 保持迭代器的连接
T* cur; // 此迭代器所指之缓冲区的现行( current)元素
T* first; // 此迭代器所指之缓冲区的的头
T* last; // 此迭代器所指之缓冲区的的尾(含备用空间)
map_pointer node; // 指向管控中心
...
};
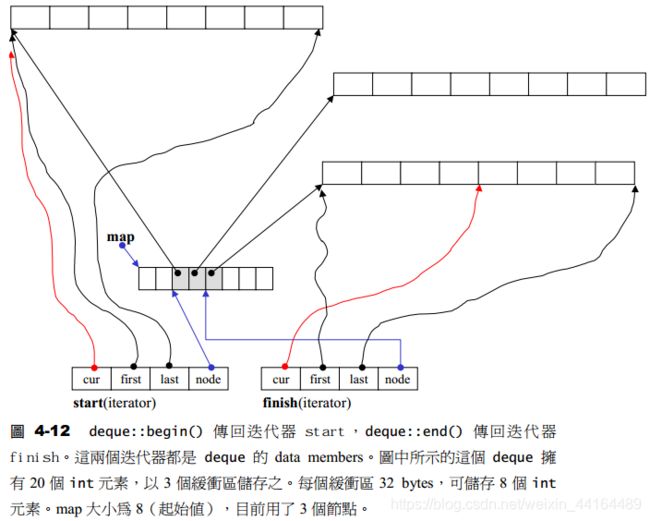
假如deque中已经包含了20个元素了,缓冲区大小为8,则内存布局如下:
注意:deque最初状态(无任何元素)保有一个缓冲区,因此,clear()完成之后回到初始状态,也一样会保留一个缓冲区。
stack
stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口。stack允许增加元素、移除元素、取得最顶端元素。但除了最顶端外,没有任何其他方法可以存取,stack的其他元素,换言之,stack不允许有遍历行为。stack默认以deque为底层容器。

queue
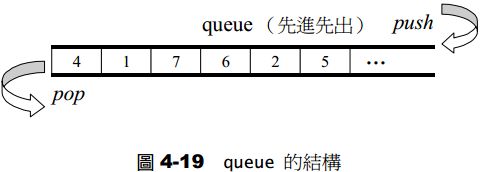
queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口,允许增加元素、移除元素、从最底端加入元素、取得最顶端元素。但除了最底端可以加入、最顶端可以取出外,没有任何其他方法可以存取queue的其他元素,换言之,queue不允许有遍历行为。queue默认以deque为底层容器。
heap
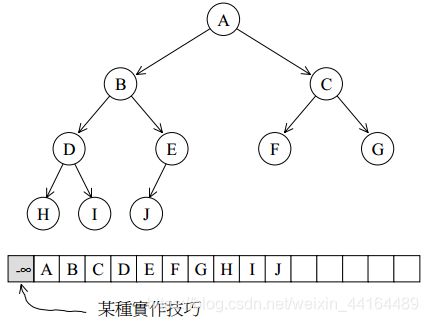
heap并不归属于STL容器组件,它是个幕后英雄,扮演prority queue的助手。priority queue允许用户以任何次序将任何元素推入容器内,但取出时一定是按照优先级最高的元素开始取。binary max heap正好具有这样的特性,适合作为priority queue的底层机制。heap默认建立的是大堆。
heap的相关用法可见博客。
priority_queue
priority_queue是一个拥有权值的queue,它允许加入新元素、移除旧元素、审视元素值等功能。由于是一个queue,所以只允许在底端加入元素,从顶端取出元素,除此之外别无其他存取元素方法。priority_queue内的元素并非按照被推入的顺序排列,而是自动按照元素的权值排列。权值最高者排在前面。
默认情况下priority_queue利用max-heap按成,后者是一个以vector为底层容器的complate binary tree。
priority_queue测试用例:
#include set
set底层是红黑树,set的所有元素都会根据元素的键值自动排序。set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值,set不允许有两个相同的元素。Set元素不能改变,在set源码中,set::iterator被定义为底层TB-tree的const_iterator,杜绝写入操作,也就是说,set iterator是一种constant iterators(相对于mutable iterators)
测试用例(让set从大到小存放元素):
#include map
map底层也是红黑树,map的所有元素都会根据元素的键值自动排序。map的所有元素都是pair,同时拥有实值(value)和键值(key)。pair的第一元素为键值,第二元素为实值。map不允许有两个相同的键值。
如果通过map的迭代器改变元素的键值,这样是不行的,因为map元素的键值关系到map元素的排列规则。任意改变map元素键值都会破坏map组织。如果修改元素的实值,这是可以的,因为map元素的实值不影响map元素的排列规则。因此,map iterator既不是一种constant iterators,也不是一种mutable iterators。
测试用例(map从大到小存放元素):
#include multiset/multimap
multiset的特性以及用法和set完全相同,唯一的差别在于它允许键值重复,因此它的插入操作采用的是底层机制RB-tree的insert_equal()而非insert_unique()。
multimap的特性以及用法和map完全相同,唯一的差别在于它允许键值重复,因此它的插入操作采用的是底层机制RB-tree的insert_equal()而非insert_unique()。
哈希表hashtable (底层数据结构)
二叉搜索树具有对数平均时间表现,但这样的表现构造在一个假设上:输入数据有足够的随机性。hashtable这种结构在插入、删除、查找具有“常数平均时间”,而且这种表现是以统计为基础,不需依赖元素的随机性。
hashtable底层数据结构为分离连接法的hash表,如下所示:
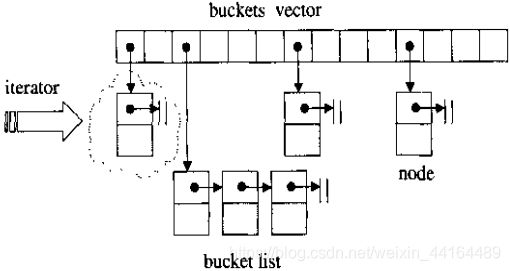
hashtable中的buckets使用的是vector数据结构,当插入一个元素时,找到该插入哪个buckets的插槽,然后遍历该插槽指向的链表,如果有相同的元素,就返回;否则的话就将该元素插入到该链表的头部。(当然,如果是multi版本的话,是可以插入重复元素的,此时插入过程为:当插入一个元素时,找到该插入哪个buckets的插槽,然后遍历该插槽指向的链表,如果有相同的元素,就将新节点插入到该相同元素的后面;如果没有相同的元素,产生新节点,插入到链表头部)
当调用成员函数clear()后,buckets vector并未释放空间,仍保留原来大小,只是删除了buckets所连接的链表。
unordered_set
unordered_set以hashtable为底层结构,运用set,为的是快速搜寻元素。这一点,不论其底层是RB-tree或是hashtable,都可以完成任务,但是,RB-tree有自动排序功能而hashtable没有,即set的元素有自动排序功能而unordered_set没有。
unordered_map
unordered_map以hashtable为底层结构,由于unordered_map所提供的操作接口,hashtable都提供了,所以几乎所有的unordered_map操作行为都是转调用hashtable的操作行为结果。RB-tree有自动排序功能而hashtable没有,反映出来的结果就是,map的元素有自动排序功能而unordered_map没有。
unordered_multiset/unordered_multimap
unordered_multiset的特性与multiset完全相同,唯一的差别在于它的底层机制是hashtable,因此,unordered_multiset的元素是不会自动排序的。
unordered_multimap的特性与multimap完全相同,唯一的差别在于它的底层机制是hashtable,因此,unordered_multimap的元素是不会自动排序的。
各容器的具体用法
见这个链接里的教程。
各容器的详细源码剖析
具体源码剖析可见此博客。