【Python】基础语法
文章目录
- 1 出使Python国
-
- 1.1 Python自述
- 1.2 搭建Python开发环境
- 1.3 Python中的输出函数
- 1.4 转义字符与原字符
- 2 七十二变
-
- 2.1 二进制与字符编码
- 2.2 Python中的标识符与保留字
- 2.3 Python中的变量与数据类型
- 2.4 Python中的注释
- 2.5 行连接符
- 3 算你赢
-
- 3.1 Python的输入函数input()
- 3.2 Python中的运算符
- 3.3 运算符的优先级
- 4 往哪走呢?
-
- 4.1 程序的组织结构
- 4.2 顺序结构
- 4.3 对象的布尔值
- 4.4 分支结构(选择结构)
- 4.5 pass空语句
- 5 转圈圈
-
- 5.1 range()函数的使用
- 5.2 循环结构
- 5.3 流程控制语句
- 5.4 嵌套循环
- 6 一字排开
-
- 6.1 列表的创建与删除
- 6.2 列表的查询操作
- 6.3 列表元素的增、删、改操作
- 6.4 列表元素的排序
- 7 夫妻站
-
- 7.1 什么是字典
- 7.2 字典的原理
- 7.3 字典的创建与删除
- 7.4 字典的常用操作
- 7.5 字典生成式
- 8 是排还是散
-
- 8.1 元组
- 8.2 集合
- 8.3 列表、字典、元组、集合总结
- 9 一串连一串
-
- 9.1 字符串的驻留机制
- 9.2 字符串的常用操作
- 9.3 字符串的比较操作
- 9.4 字符串的切片操作
- 9.5 格式化字符串
-
- 9.5.1 格式化字符串的三种方式
- 9.5.2 填充与对齐
- 9.5.3 数字格式化
- 9.6 字符串的编码转换
- 9.7 可变字符串
- 10 水晶球不调用不动
-
- 10.1 函数的创建和调用
- 10.2 函数的参数传递
-
- 形参:函数说明的位置给出的变量。
- 实参:在函数执行的时候,给函数传递的信息。
- 10.3 函数的返回值
- 10.4 函数的参数定义
- 10.5 变量的作用域
- 10.6 函数的注释
- 10.7 函数的返回值类型
- 10.8 装饰器
- 10.9 迭代器
-
- 获取迭代器:\_\_iter\_\_
- 迭代器功能
- 迭代器特点
- 10.10 生成器
-
- 生成器函数
- 生成器表达式
- lambda表达式
- 10.12 递归函数
- 11 全民来找茬
-
- 11.1 Bug的分类
- 11.3 Python的异常处理机制
- 12 文件操作
-
- 12.1 文件路径
- 12.2 mode
- 12.3 encoding
- 12.4 with上下文管理
- 12.5 文件修改
- 12.6 删除文件
- 12.7 文件重命名
- 12.8 练习
1 出使Python国
1.1 Python自述
-
我为什么值得你拥有?

-
我为什么能成为网红?
我对大数据缝隙、人工智能中至关重要的机器学习、深度学习都提供了大力的支持。
我背后有最最庞大的“代码库”
人们习惯称我为“胶水语言” -
我能帮你做些啥?
抢火车票、数据分析少踩坑、开发网站、开发游戏 -
你需要根据我的发展方向进行自身定位
| 掌握技术 | 职业方向 | |
|---|---|---|
| Web全栈开发方向 | 前端开发 数据库管理 后台框架技术 |
Web全栈开发工程师 |
| 数据科学方向 | 数据库管理 数据分析 数据可视化 能够制作数据看板 实现数据指标监控 |
数据产品经理 量化交易 初级BI商业分析师等 |
| 人工智能方向-机器学习 | 掌握机器学习常用算法思想 能够利用Python建立机器学习模型,对一些应用场景进行智能化 |
数据分析工程师 机器学习算法工程师 搜索算法工程师 推荐算法工程师 |
| 人工智能方向-深度学习 | 掌握深度学习常用框架 可自行搭建图像相关算法,实现图像分类,人脸识别 可自行搭建NLP常见算法,实现文本分类、问答系统等 掌握GAN网络相关算法,实现图像自动上色,图像美化等 |
人工智能工程师 |
- Python简介
我是一个“90后”,我孕育在1989年的圣诞节期间,我的程序员爸爸荷兰人吉多-范罗苏姆,为了打发无趣的圣诞节创造了我,我在1991年正式公布,我的程序员爸爸给我起了个非常吓人的名字叫Python(大蟒蛇),取自于英国20世纪70年代首播的电视喜剧《蒙提-派森的飞行马戏团》(Monty Python’s Flying Circus)。
现在我已经更新到3.0版本了,被大家叫做Python3000,熟悉我的朋友会称我为Py3k,我的爸爸在2020年1月1日,官宣停止了Python2的更新。 - Python特点
跨平台的计算机程序设计语言:把你的想法告诉我,我再以计算机认识的方式告诉它,我是你们之间的交流工具。
解释型语言:我在开发过程中没有编译这个环节,这点和Java不同。
交互式语言:可以在我的提示符>>后直接执行代码
面向对象的语言:在我的世界一切皆对象
1.2 搭建Python开发环境
安装参考:https://blog.csdn.net/weixin_49026134/article/details/120575480
Python安装成功后可以看到4个程序:

1.3 Python中的输出函数
print() 函数功能:向目的地输出内容
- 输出内容:数字、字符串、含有运算符的表达式
- 输出形式:换行、不换行
- 目的地:IDLE、控制台、文件
# 输出内容:数字、字符串、含有运算符的表达式
print(3.1415)
print('HelloWorld')
print(1+2)
# 输出方式:不换行(输出内容在一行当中)
print('HelloWorld', '123')
# 将数据输出在文件中,注意:1.所制定的盘符存在;2.使用file=fp
fp = open('D:/Print.txt', 'a+') # a+表示以读写的方式打开文件。如果文件不存在就创建,文件存在则在原有内容上进行追加。
print('Hello World', file=fp)
fp.close()
1.4 转义字符与原字符
- 常用的转义字符
| 转义字符的分类 | 要表示的字符 | 转义字符 | 备注 |
|---|---|---|---|
| 无法直接表示的字符 | 换行 | \n | newline光标移动到下一行的开头 |
| 回车 | \r | return光标移动到本行的开头 | |
| 水平制表符 | \t | tab键,光标移动到下一组4个空格的开始处 | |
| 退格 | \b | 键盘上的backspace键,回退一个字符 | |
| 在字符串中有特殊用途的字符 | 反斜杠 | \\ | |
| 单引号 | \' | ||
| 双引号 | \" |
- 原字符
不希望字符串中的转义字符起作用,就使用原字符,在字符串之前加上r或R。# 转义字符 print('Hello\nWorld') print('Hello\rWorld') # 注意:什么时候重开一个制表位,取决于\t之前是否占满制表位,占满则重开,不占满就不重新开 print('Hello\tWorld') print('Helloooo\tWorld') print('Hello\bWorld') print('http:\\\\www.baidu.com') print('老师说:\"大家好\"') # 原字符 print(r'Hello\nWorld')
制表位图解:什么时候重开一个制表位,取决于\t之前是否占满制表位,占满则重开,不占满就不重新开

2 七十二变
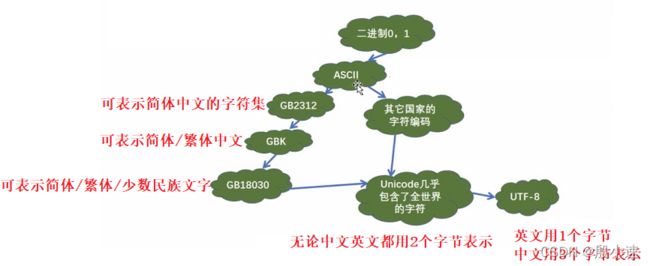
2.1 二进制与字符编码
-
计算机换算单位
8 bit (位) = 1 byte (字节)
1024 byte = 1 KB (千字节)
1024 KB = 1MB (兆字节)
1024 MB = 1 GB (吉字节)
1024 GB = 1 TB (太字节) -
字符编码
# chr(i):返回整数i所对应的Unicode字符。
print(chr(0b100111001011000)) # 0b 表示二进制
print(chr(0o47130)) # 0o表示八进制
print(chr(20056)) # 十进制
print(chr(0x4e58)) # 0x 表示十六进制
# ord(): 是chr()函数(对于8位的ASCII字符串)或unichr()函数(对于Unicode对象)的配对函数,以一个字符(长度为1的字符串)作为参数,返回对应的ASCII/Unicode数值。
print(ord('乘'))
2.2 Python中的标识符与保留字
- 保留字
查看python的保留字:import keyword print(keyword.kwlist) - 标识符
定义:变量、函数、类、模块和其他对象起的名字就叫标识符。
命名规则:- 可以使用字母、数字、下划线
- 不能以数字开头
- 不能是保留字
- 严格区分大小写
2.3 Python中的变量与数据类型
- 变量组成
标识(id):标识对象所存储的内存地址,使用内置函数id(obj)来获取
类型(type):表示对象的数据类型,使用内置函数type(obj)来获取
值(value):表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出name = 'Bob' print('标识:', id(name)) print('类型:', type(name)) print('值:', name) - 常用的数据类型
| 类型 | 简写 | 取值 |
|---|---|---|
| 整数类型 | int | 98 |
| 浮点数类型 | float | 3.14159 |
| 布尔类型 | bool | True/False |
| 字符串类型 | str | ‘人生苦短,我用Python’ |
1 整数类型
英文为integer,简写为int,可以表示正数,负数和零。
整数的不同进制表示方式:十进制(默认的进制),二进制(以0b开头),八进制(以0o开头),十六进制 (以0x开头)
print('十进制:', 119)
print('二进制:', 0b100111010)
print('八进制:', 0o1771)
print('十六进制:', 0x1f)
2 浮点数类型
浮点数由整数部分和小数部分组成。
浮点数存储不精确:使用浮点数进行计算时,可能会出现小数位数不确定的情况,如:print(1.1+2.2) # 输出:3.3000000000000003
解决方案:导入模块decimal
a = 3.14159
print(a, type(a))
print(1.1+2.1)
print(1.1+2.2)
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))

3 布尔类型
用来表示真或假的值。
布尔值可以转换为整数:True>>1, False>>0
b1, b2 = True, False
print(b1, type(b1), b2, type(b2))
# 布尔值可以转成整数计算
print(b1 + 1) # True表示1
print(b2 + 1) # False表示0
4 字符串类型
字符串又被称为不可变的字符序列。
可以用单引号‘ ’,双引号“ ”,三引号‘’‘ ‘’’或““” “””来定义。
单引号和双引号定义的字符串必须在一行。
三引号定义的字符串可以分布在连续的行。
str1 = '人生苦短,我用Python'
str2 = "人生苦短,我用Python"
str3 = '''人生苦短,
我用Python'''
str4 = """人生苦短,
我用Python"""
print(str1, type(str1))
print(str2, type(str2))
print(str3, type(str3))
print(str4, type(str4))
- 数据类型转换
将不同数据类型的数据拼接在一起。name = '张三' age = 20 # print('我叫' + name + ',今年' + age + '岁') # 当将str类型与int类型进行连接时会报错。解决方案:类型转换! print('我叫' + name + ',今年' + str(age) + '岁')函数名 作用 注意事项 举例 str() 将其他数据类型转成字符串 也可以用引号转换 str(123)
‘123’int() 将其他数据类型转成整数 1. 文字类和小数类字符串,无法转成整数
2. 浮点数转成整数,抹零取整int(‘123’)
int(9.8)float() 将其他数据类型转成浮点数 1. 文字类无法转成浮点数
2. 整数转成浮点数,末尾为.0float(‘9.8’)
float(9)a, b, c, d, e = 10, 200.20, False, 'Hello', '2.22' print(type(a), type(b), type(c), type(d), type(e)) # 转成str sa, sb, sc, sd, se = str(a), str(b), str(c), str(d), str(e) print(sa, sb, sc, sd, se, type(sa), type(sb), type(sc), type(sd), type(se)) # 转成int: 文字类和小数类字符串,无法转成整数 ia, ib, ic = int(a), int(b), int(c) print(ia, ib, ic, type(ia), type(ib), type(ic)) # 转成float: 文字类无法转成浮点数 fa, fb, fc, fe = float(a), float(b), float(c), float(e) print(fa, fb, fc, fe, type(fa), type(fb), type(fc), type(fe)) # 注意:int()转成整数直接舍弃小数,若考虑四舍五入,用round() print(int(3.56) # 3 print(rount(3.56) # 4
2.4 Python中的注释
类型:
- 单行注释:以#开头,直到换行结束
- 多行注释:并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释
- 中文编码声明注释:在文件开头加上中文声明注释,用以指定源码文件的编码格式
# coding:gbk,# -*- coding:utf-8 -*-
2.5 行连接符
使用\行连接符,将一行比较长的程序分为多行。

3 算你赢
3.1 Python的输入函数input()
- 介绍
作用:接受来自用户的输入
返回值类型:输入值得类型为str
值的存储:使用=对输入的值进行存储 - 基本使用
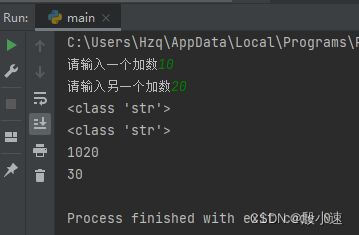
执行结果如下:# 从键盘中输入两个整数,并计算它们的和 a = input('请输入一个加数') b = input('请输入另一个加数') print(type(a)), print(type(b)) #注意:返回值类型为str print(a + b) #字符串类型+号表示拼接 print(int(a) + int(b))
3.2 Python中的运算符
-
算术运算符
标准算术运算符:加(+),减(-),乘(*),除(/), 整除(//)
取余运算符:%
幂运算符:**print(1+1) # 加法 print(1-1) # 减法 print(2*2) # 乘法 print(9/4) # 除法 print(2**3) # 幂运算 print(9//4) # 取整 print(-9//-4) print(9//-4) # 取整:一正一负向下取整 print(-9//4) print(9%4) # 取余 print(-9%-4) print(9%-4) # 取余:一正一负要公式:余数=被除数-除数*商 9-(-4)*(-3)=-3 print(-9%4) # -9-4*(-3)=3 divmod(13,3) #(4,1) divmod()函数返回一个(商,余数)的元组 -
赋值运算符
标识:=
执行顺序:从右到左
支持链式赋值:a=b=c=10
支持参数赋值:+=, -=, *=, /=, //=, %=
支持系列解包赋值:a,b,c=10,20,30# 解包赋值应用:实现两个变量值的交换,不需要中间变量! a,b=10,20 print('交换之前:', a, b) a,b=b,a print('交换之后:', a, b) -
比较运算符
对变量或表达式的结果进行大小、真假等比较。
大于(>),小于(<),大于等于(>=),小于等于(<=),不等于(!=),等于( == )is 与 == 的区别:
is用于判断两个变量引用的对象是否是同一个,即比较对象的内存地址id
== 用于判断两个变量引用对象的值是否相等,默认调用对象的__eq__()方法
is运算符比 == 效率高,在变量和None进行比较时,应使用isa = 10 b = 10 print('a==b?', a==b) print('a is b?', a is b) l1 = [1, 2, 3] l2 = [1, 2, 3] print('l1==l2?', l1==l2) print('l1 is l2?', l1 is l2)运行结果如下:

-
布尔运算符
对于布尔值之间的运算。
and:当两个运算数为True时,运算结果才为True
or:只要有一个运算数为True,运算结果就位True
not:若运算数为True(False),则运算结果为False(True)
in, not in -
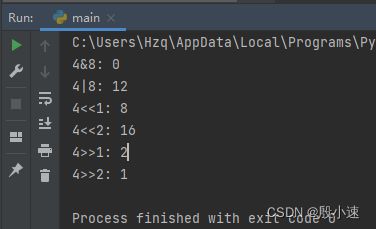
位运算符
将数据转成二进制进行计算。
位与&:对应数位都是1,结果数位才是1,否则为0
位或|:对应数位都是0,结果数为才是0,否则为1
左移位运算符<<:高位溢出舍弃,低位补0
右移位运算符>>:低位溢出舍弃,高位补0print('4&8:', 4&8) print('4|8:', 4|8) print('4<<1:', 4<<1) print('4<<2:', 4<<2) print('4>>1:', 4>>1) print('4>>2:', 4>>2)运行结果如下:

3.3 运算符的优先级
有括号先算括号里面的。

4 往哪走呢?
4.1 程序的组织结构
任何简单或复杂的算法都可以由顺序结构、选择结构和循环结构这三种基本结构组合而成。
4.2 顺序结构
程序从上到下顺序地执行代码,中间没有任何的判断和跳转,直到程序结束。
4.3 对象的布尔值
Python一切皆对象,所有对象都有一个布尔值。
获取对象的布尔值:使用内置函数bool()。
以下对象的布尔值为False,其它对象的布尔值均为True:
- False
- 数值0
- None
- 空字符串
- 空列表
- 空元组
- 空字典
- 空集合
print(bool(False))
print(bool(0))
print(bool(0.0))
print(bool(None))
# 空字符串
print(bool(''))
print(bool(""))
# 空列表
print(bool([]))
print(bool(list()))
# 空元组
print(bool(()))
print(bool(tuple()))
# 空字典
print(bool({}))
print(bool(dict()))
# 空集合
print(bool(set()))
4.4 分支结构(选择结构)
程序根据判断条件的布尔值选择性地执行 部分代码。明确地让计算机知道在什么条件下,该去做什么。
- 单分支if结构
中文语义:如果…就…
语法结构:if 条件表达式: 条件执行体 - 双分支if…else结构
中文语义:如果…就…否则就…
语法结构:if 条件表达式: 条件执行体1 else: 条件执行体2 - 多分支if…elif…else结构
中文语义:成绩是在90分以上吗?成绩是在80-90分之间吗?成绩是在60-80之间吗?成绩是在60分以下吗?
语法结构:if 条件表达式1: 条件执行体1 elif 条件表达式2: 条件执行体2 elif 条件表达式n: 条件执行体n [else:] 条件执行体n+1 - if语句的嵌套
语法结构:if 条件表达式1: if 内层条件表达式1 内层条件执行体1 else: 内层条件执行体2 else: 条件执行体 - 条件表达式
条件表达式是if…else的简写
语法结构:x if 判断条件 else y
运算规则:如果判断条件的布尔值为True,条件表达式的返回值为x,否则条件表达的返回值为y(条件判断为True,执行前边的代码;条件判断为False,执行后边的代码)# 从键盘录入2个整数,比较两个整数的大小 a = int(input('Please enter the 1st integer:')) b = int(input('Please enter the 2rd integer:')) # if a>=b: # print(a, '>=', b) # else: # print(a, '<', b) print(str(a)+'>='+str(b) if a>=b else str(a)+'<'+str(b))
4.5 pass空语句
语句什么都不做,只是一个占位符,用在语法上需要语句的地方。
什么时候使用:先搭建语法结构,还没想好代码怎么写的时候。
哪些语句一起使用:
- if语句的条件执行体
- for-in语句的循环体
- 定义函数时的函数体
5 转圈圈
5.1 range()函数的使用
内置函数range():用于生成一个整数序列,起始值默认为0,步长默认为1。
创建range对象的三种方式:

返回值是一个迭代器对象。
range类型的优点:不管range对象表示的整数序列有点多长,所有range对象占用的内存空间都是相同的,因为仅仅需要存储start, stop和step,只有当用到range对象时,才会去计算序列中的相关元素。
in和not in判断整数序列中是否存在(不存在)指定的整数。
r1 = range(10) # 默认start=0, step=1
print(r1) # 输出:range(10)
print(list(r1)) # 用于查看range对象中的整数序列
r2 = range(1, 10) # 指定起始值,默认step=1
print(list(r2))
r3 = range(1, 10, 2) # 指定起始值和步长
print(list(r3))
print(10 in r1)
print(0 not in r2)
5.2 循环结构
反复做同一件事情的情况,成为循环。
- while循环
用于次数不固定的循环。
语法结构:
选择结构的if与循环结构while的区别:while 条件表达式: 条件执行体(循环体)- if是判断一次,条件为True执行一次
- while是判断N+1次,条件为True执行N次
四步循环法:初始化变量 >> 条件判断 >> 条件执行体(循环体) >> 改变变量a = 1 if a<10: print(a) a+=1 b = 1 while b<10: print(b) b+=1# 计算1-100之间的偶数和 '''初始化变量''' a = 0 sum = 0 '''条件判断''' while a <= 100: '''条件执行体(循环体)''' # if a%2 == 0: if not (a % 2): sum += a '''改变变量''' a += 1 print('1-100之间的偶数和为:', sum) # 计算1-100之间的奇数和 a = 0 sum = 0 while a <= 100: if a % 2: sum += a a += 1 print('1-100的奇数和为:', sum) - for-in循环
in表达从(字符串、序列等)中依次取值,又称遍历。
for-in遍历的对象必须是可迭代对象(字符串、序列等),用于遍历可迭代对象。
语法结构:
循环体内不需要访问自定义变量,可以将自定义变量替代为下划线。for 自定义的变量 in 可迭代对象: 循环体
练习题:# for-in遍历的对象必须是可迭代对象——字符串 for item in 'Python': print(item) # for-in遍历的对象必须是可迭代对象——序列,range()生成一个整数序列 for i in range(1, 10): print(i) # 如果在循环体中不需要使用到自定义变量,可将自定义变量写为"_" for _ in range(3): print('人生苦短,我用Python')# 输出100-999之间的每个水仙花数(153=3*3*3+5*5*5+1*1*1) for i in range(100, 1000): sigle = i % 10 # 个位数=数除以10取余 ten = i // 10 % 10 # 十位数=数除以10取整后再除以10取余 hundred = i //100 # 百位数=数除以100取整 if i == sigle**3 + ten**3 + hundred**3: print(i)
5.3 流程控制语句
- break语句
用于退出当前循环结构,通常与分支结构if一起使用。# 从键盘上输入密码,最多录入3次,如果正确就结束 # for-in循环 for i in range(3): pwd = input('Please enter your password') if pwd == '666666': print('Password correct!') break else: print('Password incorrect!') # while循环 i = 0 while i < 3: pwd = input('Please enter your password') if pwd == '666666': print('Password correct!') break else: print('Password incorrect!') i += 1 - continue语句
用于结束当前循环,进入下一次循环,通常与分支结构中的if一起使用。# 输出1-50之间所有是5的倍数 for i in range(1, 51): # if i % 5 != 0: if i % 5: continue else: print(i) - else语句
与else语句搭配使用的三种情况:

# 从键盘上输入密码,最多录入3次,如果正确就结束 # for-in循环 for i in range(3): pwd = input('Please enter your password') if pwd == '666666': print('Password correct!') break else: print('Password incorrect!') else: print('Oops, wrong password three times.') # while循环 i = 0 while i < 3: pwd = input('Please enter your password') if pwd == '666666': print('Password correct!') break else: print('Password incorrect!') i += 1 else: print('Oops, wrong password three times.')
5.4 嵌套循环
循环结构中嵌套了另外的完整的循环结构,其中内层循环做为外层循环的循环体执行。
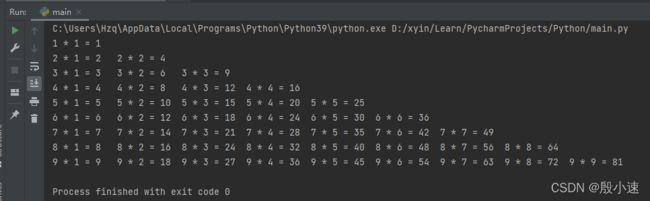
# 输出九九乘法表
for i in range(1, 10):
for j in range(1, 1+i):
print(i, '*', j, '=', i*j, end='\t') # 不换行输出
print() #换行输出
- 二重循环中的break和continue
只控制本层循环。
# 流程控制语句break和continue在二重循环中的使用
for i in range(5): # 代表外层循环要执行5次
for j in range(1, 11):
if j%2 == 0:
break
print(j)
for i in range(5): # 代表外层循环要执行5次
for j in range(1, 11):
if j%2 == 0:
continue
print(j, end='\t')
print()
6 一字排开
- 列表的特点
列表元素按顺序有序排序;
索引映射唯一个数据;
列表可以存储重复数据;
任意数据类型混存;
根据需要动态分配和回收内存;
6.1 列表的创建与删除
- 列表的创建
使用中括号
调用内置函数list()
列表生成式:生成列表的公式
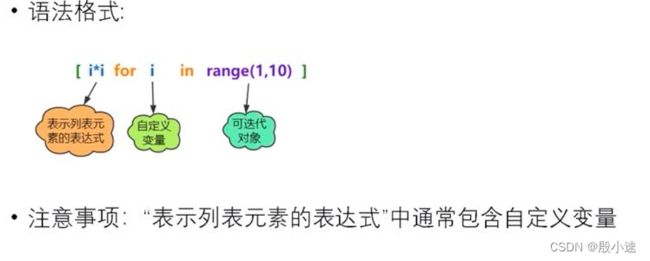
# 1. 中括号 lst1 = ['Hello', 'World', 100] # 2. list() lst2 = list(['Hello', 'World', 100]) # 3. 列表生成式 lst = [i for i in range(10)] print(lst) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] lst2 = [i*i for i in range(1, 10)] print(lst2) # [1, 4, 9, 16, 25, 36, 49, 64, 81] lst3 = [i*2 for i in range(5) if i%3==0] print(lst3) # [0, 6] - 列表的删除
del 列表名
6.2 列表的查询操作
-
查询元素索引——index()
如果列表中存在N个相同的元素,只返回相同元素中的第一个元素的索引;
如果查询的元素在列表中不存在,则会抛出ValueError;
可以在指定的start和stop之间进行查找;lst = ['Hello', 'World', 100, 'Hello'] print(lst.index('Hello')) # 0 print(lst.index('hello')) # ValueError print(lst.index('Hello', 1, 4)) # 3 -
获取单个元素——[索引]
正向索引从0到N-1;
逆向索引从-N到-1;
指定索引不存在,抛出indexError;lst = ['Hello', 'World', 100, 'Hello'] print(lst[2]) # 100 print(lst[-2]) # 100 print(lst[100]) # IndexError -
获取多个元素——切片
语法格式:列表名[start: stop: step]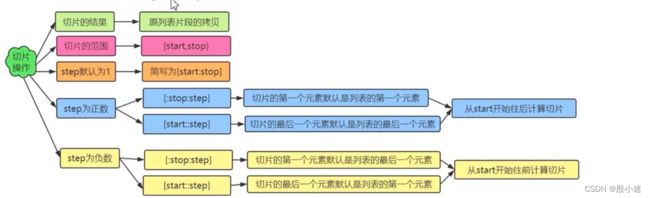
lst = [10, 20, 30, 40, 50, 60, 70, 80] print('原列表:', id(lst)) lst2 = lst[1:6] print('切的列表:', id(lst2)) # 原列表片段的拷贝 print(lst[1:6:2]) # [20, 40, 60] print(lst[:6:2]) # [10. 30. 50] print(lst[1::2]) # [20, 40, 60, 80] print(lst[::-1]) # [80, 70, 60, 50, 40, 30, 20, 10] print(lst[7::-1]) # [80, 70, 60, 50, 40, 30, 20, 10] print(lst[6:0:-2]) # [70, 50, 30] print(lst[6::-2]) # [70, 50, 30, 10] -
获取指定元素在列表中出现的次数——count()
lst = [1,2,3,3,2,2,1] print(lst.count(1)) # 2 -
判断指定元素在列表中是否存在
元素 in 列表名元素 not in 列表名 -
列表元素的遍历
lst = [10, 20, 'python'] # 第一种: for item in lst: print(item) # 第二种: for i in range(len(lst)): item = lst[i] print(item)
6.3 列表元素的增、删、改操作
- 列表元素的增加操作
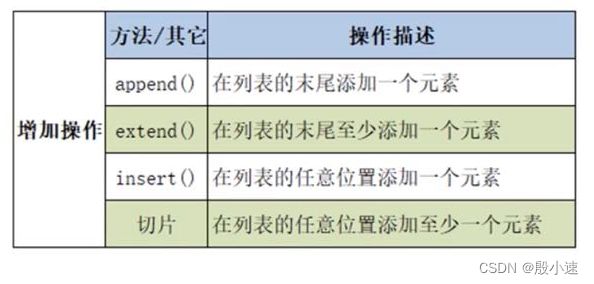
lst = [10, 'python'] print('原始列表:', lst, id(lst)) lst.append(100) print('append之后:', lst, id(lst)) lst2 = ['Hello', 'World'] lst.append(lst2) print('append添加lst2:', lst) # [10, 'python', 100, ['Hello', 'World']] lst.extend(lst2) print('extend添加lst2:', lst) # [10, 'python', 100, ['Hello', 'World'], 'Hello', 'World'] lst.insert(1, 90) print('insert操作之后:', lst) # [10, 90, 'python', 100, ['Hello', 'World'], 'Hello', 'World'] lst3 = [True, False, 'hi'] lst[1:] = lst3 print(lst) # [10, True, False, 'hi'] lst[1:3] = lst3 print(lst) # [10, True, False, 'hi', 'hi'] - 列表元素的删除操作
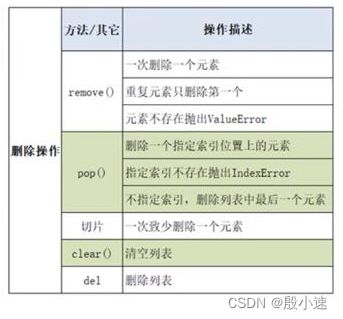
lst = [10, 20, 30, 40, 50, 60, 30] lst.remove(30) print(lst) # [10, 20, 40, 50, 60, 30] lst.pop(1) print(lst) # [10, 40, 50, 60, 30] lst.pop() print(lst) # [10, 40, 50, 60] # 切片操作删除至少一个元素,将产生一个新的列表对象, 原列表不变 new_lst = lst[1:3] print('原列表:', lst) print('切片后的新列表:', new_lst) # [40, 50] # 不产生新的列表对象,而是删除原列表中的内容 lst[1:3] = [] print(lst) # [10, 60] lst.clear() print(lst) # [] del lst print(lst) # name 'lst' is not defined - 列表元素的修改操作
为指定索引的元素赋予一个新值;
为指定的切片赋予一个新值;lst = [10, 20, 30, 40] lst[1] = 100 print(lst) # [10, 100, 30, 40] lst[1:3]=[300, 400, 500, 600] print(lst) # [10, 300, 400, 500, 600, 40]
6.4 列表元素的排序
常见的两种方式:
(1)调用sort()方法,列表中的所有元素按照从小到大的顺序进行排序,可以指定reverse=True,进行降序排序。对原列表进行操作。
(2)调用内置函数sorted(),可以指定reverse=True,进行降序排序。产生新列表,原列表不发生改变。
lst = [10, 40, 100, 93, 66]
print('排序前的列表', lst, id(lst))
lst.sort() # sort()默认升序排序,不产生新列表
print('排序后的列表', lst, id(lst))
lst.sort(reverse=True) # reverse=True 降序排序
print(lst)
new_lst = sorted(lst) # sorted()默认升序排序,产生新列表,原列表不变
print('原列表:', lst)
print('新列表:', new_lst)
desc_lst = sorted(lst, reverse=True) # reverse=True 降序排序
print('降序排序:', desc_lst)
7 夫妻站
7.1 什么是字典
Python内置的数据结构之一,与列表一样是一个可变序列(可以增删改)。
以键值对的方式存储数据,字典是一个无序的序列。
- 字典的特点
字典中的所有元素都是一个key-value对,key不允许重复,value可以重复;
字典中的元素是无序的;
字典中的key必须是不可变对象;
字典也可以根据需要动态地伸缩;
字典会浪费较大的内存,是一种空间换时间的数据结构;
7.2 字典的原理
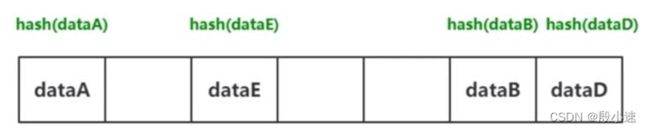
- 字典示意图
往字典当中进行存储数据的时候,需要经过一个叫hash()函数的工序,把键放到hash()函数中计算存储位置。所以位置不是根据放的先后顺序得来的,而是经过hash()函数计算得来的。所以键必须是不可变序列(字符串,整数序列)。

- 字典的实现原理
与查字典类似,查字典是先根据部首或拼音查找对应的页码,Python中的字典是根据key查找value所在的位置。
7.3 字典的创建与删除
-
字典的创建
使用花括号:scores = {'张三':100, '李四': 60}
使用内置函数dict():scores = dict(张三=100, 李四=60)
使用字典生成式 -
字典的删除
del scores
7.4 字典的常用操作
-
字典中元素的获取
[key]:scores['张三']
get(key)方法:scores.get('张三')
[]取值和get()取值区别:- []如果字典不存在指定的key,抛出keyError异常;
- get()方法取值,如果字典不存在指定的key,并不会抛出keyError而是返回None,可以通过参数设置默认的value,以便指定的key不存在时返回。
scores = {'张三':100, '李四': 60} print(scores['张三']) # 100 print(scores.get('张三')) # 100 # print(scores['王五']) # KeyError print(scores.get('王五')) # None print(scores.get('王五', 99)) # 99, 99是王五不存在时提供的默认值 print(scores.get('李四', 99)) # 60 -
key的判断
in:指定的key在字典中存在返回True
not in:指定的key在字典中不存在返回True -
字典元素的删除
删除指定元素:del scores['张三'],scores.pop['张三']
清空字典所有元素:scores.clear() -
字典元素的新增
scores['王五'] = 85 # 王五是新的键 -
字典元素的修改
scores['王五'] = 77 # 对已有键王五的修改 -
获取字典视图的三个方法
keys(): 获取字典中所有key
values(): 获取字典中所有value
items(): 获取字典中所有key, value对# 获取所有的keys scores = {'张三':100, '李四': 60} keys = scores.keys() print(keys) # dict_keys(['张三', '李四']) print(type(keys)) #print(list(keys)) # ['张三', '李四'], 将所有的keys组成的视图转成列表 # 获取所有的values values = scores.values() print(values) # dict_values([100, 60]) print(type(values)) # print(list(values)) # [100, 60] # 获取所有的键值对 items = scores.items() print(items) # dict_items([('张三', 100), ('李四', 60)]) print(type(items)) # print(list(items)) # [('张三', 100), ('李四', 60)], 转换之后的列表元素是由元组组成 -
字典元素的遍历
scores = {'张三':100, '李四': 60} for item in scores: print(item, scores[item], scores.get(item)) # 注意item输出的是键
7.5 字典生成式
- 内置函数zip()
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表。
items = ['Fruits', 'Books', 'Others']
prices = [96, 78, 85]
lst = zip(items, prices)
print(lst) # 8 是排还是散
8.1 元组
-
什么是元组
Python内置的数据结构之一,是一个不可变序列。不可变序列与可变序列
不可变序列:没有增、删、改的操作;如:字符串、元组
可变序列:可以对序列进行增、删、改操作,对象地址不发生更改;如:列表、字典# 可变序列 lst = [10,20] print('原序列及id:', lst, id(lst)) lst.append(30) print('修改后的序列及id', lst, id(lst)) # 不可变序列 s = 'hello' print('原字符串及id:', s, id(s)) s = s + ' world' print('修改后的字符串及id:', s, id(s))问:为什么要将元组设计为不可变序列?
答:在多任务环境下,同时操作对象时不需要加锁,因此,在程序中尽量使用不可变序列。
注意事项:元组中存储的是对象的引用
a)如果元组中的对象本身是不可变对象,则不能再引用其他对象;
b)如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变;t = (10, [20, 30], 'hello') print(t, type(t)) print(t[0], type(t[0]), id(t[0])) print(t[1], type(t[1]), id(t[1])) print(t[2], type(t[2]), id(t[2])) # 尝试将t[1]修改为100 # t[1] = 100 # print(id(t[1])) # TypeError,元组不允许修改元素 # 由于[20, 30]是列表,列表是可变序列,所以可以向列表中添加元素,而列表的内存地址不变 t[1].append(100) print(t[1], id(t[1])) t[1][0] = 200 print(t[1], id(t[1])) -
元组的创建方式
使用小括号:t = ('Python', 'hello', 90)(小括号可省略)
使用内置函数tuple():t = tuple(('Python', 'hello', 90))
只包含一个元组的元组需要使用逗号和小括号:t = (10, )t1 = (1, 2, 3) print(t1, type(t1)) # (1, 2, 3)t2 = 1, 2, 3 # 省略了小括号 print(t2, type(t2)) # (1, 2, 3) t3 = tuple((1, 2, 3)) print(t3, type(t3)) # (1, 2, 3) t4 = (1) # 如果元组中只有一个元素,都好不能省 print(t4, type(t4)) # 1 t4 = (1,) print(t4, type(t4)) # (1,) -
元组的遍历
t = ('python', 'hello', 99) for item in t: print(item) -
元组的技巧
可以自动进行解包/解构,前面的变量和后面解包出来的数据量必须一致。如:t = 1, 2 t1, t2 = t print(t1, t2) # 1 2
8.2 集合
- 什么是集合
Python语言提供的内置数据结构。
与列表、字典一样都属于可变类型的序列。
集合是没有value的字典。
set集合通常用来去除重复数据:s = set(数据)
- 集合的创建
使用花括号{}:s = {'Python', 'hello', 90}
使用内置函数set():s = set(['Python', 'hello', 90])
使用集合生成式s = {'Python', 'hello', 90, 90} # 集合中的元素不允许重复 print(s, type(s)) # {'hello', 'Python', 90}s1 = set(range(6)) print(s1, type(s1)) # {0, 1, 2, 3, 4, 5} s2 = set(['Python', 'hello', 90]) # 将列表类型的元素转成集合中的元素 print(s2, type(s2)) # {'hello', 'Python', 90} s3 = set(('Python', 'hello', 90)) # 将元组类型的元素转成集合中的元素 print(s3, type(s3)) # {'hello', 'Python', 90} s4 = set('Python') # 将字符串序列转成集合中的元素 print(s4, type(s4)) # {'n', 'y', 'P', 'o', 't', 'h'} s5 = {} # 不可以使用{}定义空集合,默认类型是dict print(s5, type(s5)) # {} s6 = set() # 使用set()定义空集合 print(s6, type(s6)) # set() - 集合的相关操作
集合元素的判断:in or not in
集合元素的新增:.add() # 一次添加一个元素.update() #至少添加一个元素
集合元素的删除:.remove() #一次删除一个指定元素,如果指定元素不存在抛出KeyError.discard() #一次删除一个指定元素,如果指定元素不存在不抛出异常.pop() #一次只删除一个任意元素.clear() #清空集合s = {1, 2, 3} # 判断 print(1 in s) # True print(4 not in s) # True # 增 s.add(4) print(s) # {1, 2, 3, 4} s.update([5, 6, 7]) print(s) # {1, 2, 3, 4, 5, 6, 7} s.update((8, 9)) print(s) # {1, 2, 3, 4, 5, 6, 7, 8, 9} s.update({10}) print(s) # {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} # 删 # s.remove(11) # 11不存在,抛错KeyError s.remove(1) print(s) # {2, 3, 4, 5, 6, 7, 8, 9, 10} s.discard(11) # 11不存在,不抛异常 s.discard(2) print(s) # {3, 4, 5, 6, 7, 8, 9, 10} # s.pop(10) # pop方法不能添加参数,抛错TypeError。 s.pop() print(s) # 用于删除任意一个元素 s.clear() print(s) # set() - 集合间的关系
两个集合是否相等:==!=
一个集合是否是另一个集合的子集:.issubset()
一个集合是否是另一个集合的超集:.issuperset()
两个集合是否没有交集:.isdisjoint()# 两个集合是否相等: 元素相同就相等 s = {1,2,3} s2 = {2,3,1} print(s == s2) # True print(s != s2) # False # 一个集合是否是另一个集合的子集 s1 = {1, 2, 3, 4} s2 = {2, 3, 4} s3 = {3, 4, 5} print(s2.issubset(s1)) # True, s2是s1的子集 print(s3.issubset(s1)) # False, s3不是s1的子集 # 一个集合是否是另一个集合的超集 print(s1.issuperset(s2)) # True, s1是s2的超集 print(s1.issuperset(s3)) # False, s1不是s3的超集 # 两个集合是否没有交集 print(s2.isdisjoint(s3)) # False, s2和s3有交集 - 集合的数学操作
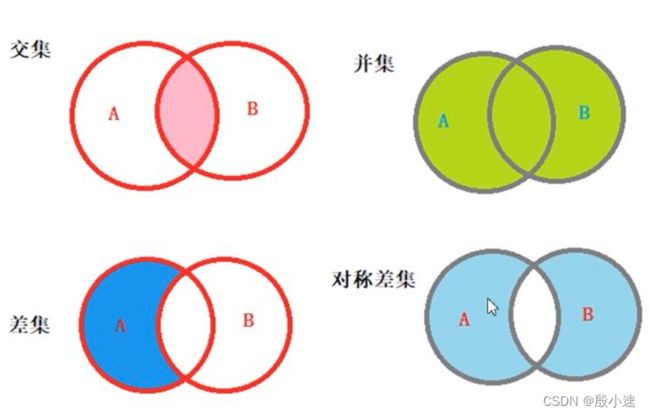
交集:.intersection()或&
并集:.union()或|
差集:.difference()
对称差集:.symmetric_difference()或^
s1 = {10, 20, 30, 40} s2 = {20, 30, 40, 50, 60} # 交集 print(s1.intersection(s2)) # {40, 20, 30} print(s1 & s2) # {40, 20, 30} # 并集 print(s1.union(s2)) # {40, 10, 50, 20, 60, 30} print(s1 | s2) # {40, 10, 50, 20, 60, 30} # 差集 print(s1.difference(s2)) # {10} # 对称差集 print(s1.symmetric_difference(s2)) # {50, 10, 60} print(s1 ^ s2) # {50, 10, 60} - 集合生成式
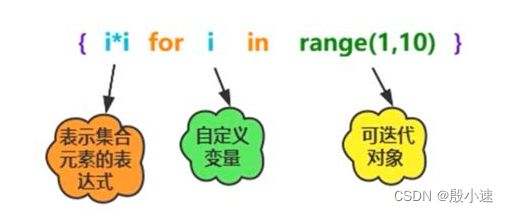
用于生成集合的公式。
将{}修改为[]就是列表生成式。
没有元组生成式。
s = {i*i for i in range(10)} print(s)
8.3 列表、字典、元组、集合总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表(list) | 可变 | 可重复 | 有序 | [] |
| 元组(tuple) | 不可变 | 可重复 | 有序 | () |
| 字典(dict) | 可变 | key不可重复 value可重复 |
无序 | {key:value} |
| 集合(set) | 可变 | 不可重复 | 无序 | {} |
9 一串连一串
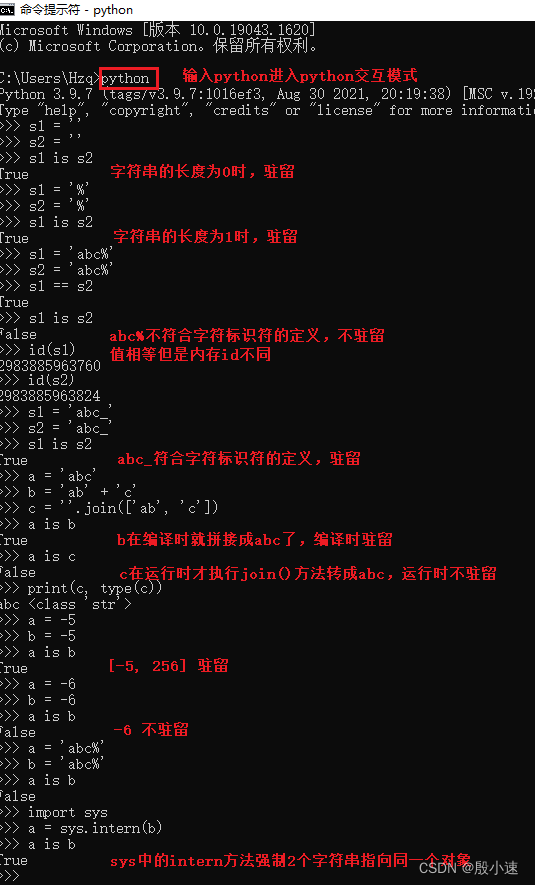
9.1 字符串的驻留机制
-
字符串
基本数据类型,是一个不可变的字符序列。 -
驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。a = 'Python' b = "Python" c = '''Python''' print(a, id(a)) # 三个id相同 print(b, id(b)) print(c, id(c))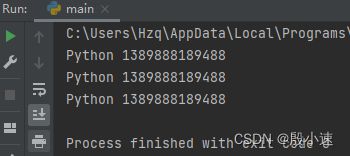
-
驻留机制的几种情况(交互模式)
- 字符串的长度为0或1时;
- 字符标识符的字符串(仅含下划线、字母和数字);
- 字符串只在编译时进行驻留,而非运行时;
- [-5, 256]之间的整数数字;
sys中的intern方法强制2个字符串指向同一个对象;
Pycharm对字符串进行了优化处理(只要内容相同就进行驻留)。
-
字符串驻留机制的优缺点
当需要值相同的字符串时,可以直接从字符串池里拿出来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是比较影响性能的。
在需要进行字符串拼接时建议使用str类型的join方法,而非+。因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一次对象,效率比用+效率高。import time time1 = time.time() #起始时间 a = '' for i in range(1000000): a = a + 'sxy' # 使用+进行字符串拼接 time2 = time.time() #终止时间 print('运算时间:' + str(time2-time1)) time3 = time.time() ls = [] for i in range(1000000): ls.append('sxy') b =''.join(ls) # 使用join()方法进行字符串拼接 time4 = time.time() print('运算时间:' + str(time4-time3)) ''' 运算时间:0.41166019439697266 运算时间:0.09092330932617188 '''
9.2 字符串的常用操作
-
字符串的查询操作
方法 作用 s.index(substr) 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError s.rindex(substr) 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError s.find(substr) 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 s.rfind(substr) 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 s.startswith(substr) 判断是否以指定子串substr开头 s.endswith(substr) 判断是否以指定子串substr结尾 s.count(substr) 查找子串substr出现的次数 s = 'hello, hello' print(s.index('lo')) # 3 # print(s.index('a')) # ValueError print(s.rindex('lo')) # 10 print(s.find('lo')) # 3 print(s.find('a')) # -1 print(s.rfind('lo')) # 10 print(s.startswith('hel')) # True print(s.endswith('loo')) # False print(s.count('hello') # 2原理图:

-
字符串的大小写转换操作
转换之后会产生一个新对象,即使值一样,不驻留!方法 作用 s.upper() 把字符串中所有字符都转成大写字母 s.lower() 把字符串中所有字符都转成小写字母 s.swapcase() 把字符串中所有大写字母转成小写字母,把所有小写字母都转成大写字母 s.capitalize() 把第一个字符转换为大写,把其余字符转换为小写 s.title() 把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写 s = 'hello, python' print(s.upper()) # HELLO, PYTHON b = s.lower() print(b) # hello, python print(b == s) # True:b和s值相等 print(b is s) # False:b和s内容id不相等,转换产生新对象 s2 = 'hello, Python' print(s2.swapcase()) # HELLO, pYTHON print(s2.capitalize()) # Hello, python print(s2.title()) # Hello, Python -
字符串的内容对齐操作

s = 'Hello, Python' # 居中对齐 print(s.center(20, '*')) # ***Hello, Python**** print(s.center(20)) # Hello, Python print(s.center(6, '*')) # Hello, Python 设置宽度<实际宽度,返回原字符串 # 左对齐 print(s.ljust(20, '*')) # Hello, Python******* print(s.ljust(20)) # Hello, Python print(s.ljust(6, '*')) # Hello, Python # 右对齐 print(s.rjust(20, '*')) # *******Hello, Python print(s.rjust(20)) # Hello, Python print(s.rjust(6, '*')) # Hello, Python print(s.zfill(20)) # 0000000Hello, Python print(s.zfill(6)) # Hello, Python print('-1230'.zfill(8)) # -0001230 -
字符串的劈分操作
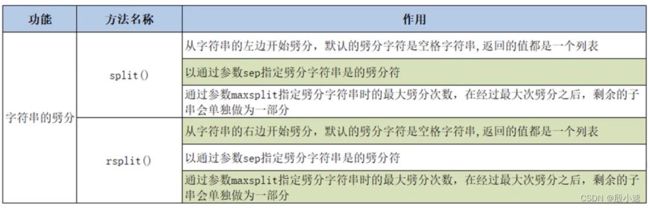
s= 'hello world Python' lst = s.split() print(lst) # ['hello', 'world', 'Python'] s1 = 'hello|world|Python' print(s1.split(sep='|')) # ['hello', 'world', 'Python'] print(s1.split(sep='|', maxsplit=1)) # ['hello', 'world|Python'] print(s.rsplit()) # ['hello', 'world', 'Python'] print(s1.rsplit(sep='|')) # ['hello', 'world', 'Python'] print(s1.rsplit(sep='|', maxsplit=1)) # ['hello|world', 'Python'] -
字符串的判断操作
方法 作用 s.isidentifier() 判断字符串是不是合法的标识符 s.isspace() 判断字符串是否全部由空白字符组成(回车、换行、水平制表符) s.isalpha() 判断字符串是否全部由字母组成(含汉字) s.isdigit() 判断字符串是否全部由十进制的数字组成,缺点:无法判断小数 s.isdecimal() 判断字符串是否全部由十进制的数字组成 s.isnumeric() 判断字符串是否全部由数字组成(含罗马数字、中文数字) s.isalnum() 判断字符串是否全部由字母和数字组成 # 是否是合法的标识符 print('hello,python'.isidentifier()) # False, 逗号不是合法的标识符 print('hello_123'.isidentifier()) # True print('张三'.isidentifier()) # True # 是否全部有空字符组成 print('\t\n\r'.isspace()) # True # 是否全部由字母组成 print('abc'.isalpha()) # True print('壹二'.isalpha()) # True print('张三_123'.isalpha()) # False # 是否全部由十进制的数字组成 print('123'.isdigit()) # True print('123四'.isdigit()) # False print('ⅣⅥ'.isdigit()) # False # 是否全部由数字组成 print('123'.isnumeric()) # True print('123四壹'.isnumeric()) # True print('ⅣⅥ'.isnumeric()) # True # 是否全部由字母和数字组成 print('123abc'.isalnum()) # True print('张三123'.isalnum()) # True print('abc!'.isalnum()) # False -
字符串的其他操作
方法 作用 s.replace(substr, newstr, time) 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串
可以通过第3个参数指定最大替换次数
该方法返回替换后得到的字符串,替换前的字符串不发生变化symbio.join(iter_obj) 利用指定符号symbio将列表、元组或字符串序列中的字符串合并成一个字符串 s.strip() 去掉字符串左右两端的空白 s = 'hello, Python' print(s.replace('Python', 'Java')) # hello, Java s1 = 'hello, Python, Python, Python' print(s1.replace('Python', 'Java', 2)) # hello, Java, Java, Python lst = ['hello', 'Java', 'Python'] print('|'.join(lst)) # hello|Java|Python print(''.join(lst)) # helloJavaPython t = ('hello', 'Java', 'Python') print(''.join(t)) # helloJavaPython print('*'.join('Python')) # P*y*t*h*o*n print(' a b c '.strip()) # a b c
9.3 字符串的比较操作
运算符:>, >=, <, <=, ==, !=
比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再比较较。
比较原理:两个字符进行相比时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用chr时指定ordinal value可以得到其对应的字符。
注意:a==b比较的是字符串a和b的值是否相等;a is b比较的是a和b内存地址id是否相等。
print('apple' > 'app') # True
print('apple' > 'banana') # False
print(ord('a'), ord('b')) # 97 98
print(chr(97), chr(98)) # a b
9.4 字符串的切片操作
字符串时不可变序列。切片操作将产生新的对象。
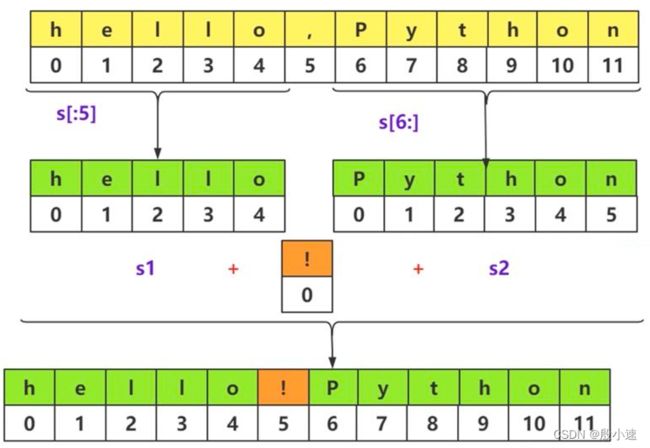
s = 'hello,Python'
s1 = s[:5]
print(s1)
s2 = s[6:]
print(s2)
s3 = '!'
new_str = s1 + s3 + s2
print(new_str)
9.5 格式化字符串
9.5.1 格式化字符串的三种方式
- %作占位符

- {}作占位符,通过{}和:来代替%

- 使用f字符
name = '张三'
age = 20
print('我叫%s, 今年%d岁。' % (name, age)) # 我叫张三, 今年20岁。
print('我叫{0},今年{1}岁,我真的叫{0}'.format(name, age)) # 我叫张三,今年20岁,我真的叫张三
print('我叫{name},今年{age}岁,我真的叫{name}'.format(age=20, name='张三'))
print(f'我叫{name},今年{age}岁。') # 我叫张三,今年20岁
# 表示宽度
print('%d' % 99) # 99
print('%10d' % 99) # 99, 10表示宽度,一共是10位
print('hellohello') # hellohello
# 表示精度
print('%f' % 3.1415926) # 3.141593
print('%.3f' % 3.1415926) # 3.142, .3表示小数点后3位
# 同时表示宽度和精度
print('%10.3f' % 3.1415926) # 3.142 总宽度为10,小数点后3位
# {}占位符表示宽度和精度
print('{}'.format(3.1415926)) # 3.1415926
print('{0:.3}'.format(3.1415926)) # 3.14, .3表示一共3位
print('{:.3f}'.format(3.1415926)) # 3.142, .3f表示小数点后3位
print('{:10.3f}'.format(3.1415926)) # 3.142,3f,10表示一共10位,3位是小数
9.5.2 填充与对齐
填充常跟对齐一起使用。
^、<、>分别是居中、左对齐、右对齐,后面带宽度。
:号后面带填充的字符,只能是一个字符,不指定的话默认使用空格填充。
print('{:10}'.format('22')) # 22 字符串默认左对齐
print('{:10}'.format(22)) # 22 数字默认右对齐
print('{:>10}'.format('22')) # 22 右对齐,默认空格填充
print('{:*^10}'.format('22')) # ****22**** 居中对齐,*填充
print('我是{0},我的幸运数字是{1:*>8}'.format('Bob', 7)) # 我是Bob,我的幸运数字是*******7
9.5.3 数字格式化
浮点数通过f,整数通过d进行格式化。
a = '我是{0},我的存款有{1:.2f}'
print(a.format('Bob', 888888.6666)) # 我是Bob,我的存款有888888.67
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| +3.142 | {:+.3f} | +3.15 | 带符号保留小数点后三位 |
| 3.1415926 | {:.0f} | 3 | 不带小数(四舍五入) |
| 3 | {:0>2d} | 03 | 数字补零(填充左边,宽度为2) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:10d} | 13 | 数字默认右对齐,宽度为10 |
| 135 | {:*<10d} | 135******* | 左对齐,宽度为10,*号填充 |
9.6 字符串的编码转换
- 为什么需要字符串的编码转换
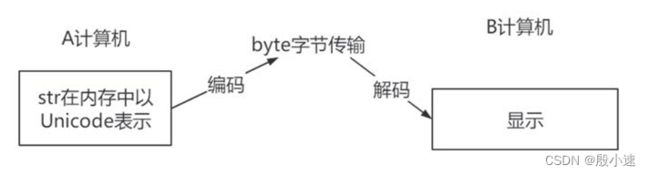
- 编码与解码的方式
编码:将字符串转换为二进制数据(bytes)
解码:将bytes类型的数据转换成字符串类型s = '天涯共此时' # 编码 # 在GBK编码格式中,一个中文占两个字节 print(s.encode(encoding='GBK')) # b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1', b表示二进制 # 在UTF-8编码格式中,一个中文占三个字节 print(s.encode(encoding='UTF-8')) # b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6' # 解码 # byte代表一个二进制数据(字节类型的数据) byte = s.encode(encoding='GBK') print(byte.decode(encoding='GBK')) # 天涯共此时 byte = s.encode(encoding='UTF-8') print(byte.decode(encoding='UTF-8')) # 天涯共此时
9.7 可变字符串
在Python中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,只能创建新的字符串对象。但是,经常我们确实需要原地修改字符串,可以使用io.StringIO对象或array模块。
import io
s = 'hello.txt'
sio = io.StringIO(s)
print(sio) # sio 可变对象
print(sio.getvalue()) # hello.txt 取值
sio.seek(7) # seek:指针移动到指定位置
sio.write('g') # write:将指针位置上的字符修改成g
print(sio.getvalue()) # hello.tgt
10 水晶球不调用不动
10.1 函数的创建和调用
-
什么是函数
执行特定任务以完成特定功能的一段代码。 -
为什么需要函数
复用代码
隐藏实现细节
提高可维护性
提高可读性便于调试 -
函数的创建和调用
# 函数的创建 def 函数名([输入参数]): 函数体 [return xxx] # 函数的调用 函数名([实际参数]) -
函数名是什么?
函数名本质上就是一个变量!后面带括号,函数名()表示调用。def fn(): print('fn') def gn(): print('gn') fn() # fn fn = gn fn() # gndef fn(an): an() def gn(): def inner(): print('hello') return inner def hn(): def inner(): print('python') return inner fn(gn()) # hello fn(hn()) # pyhton
10.2 函数的参数传递
形参:函数说明的位置给出的变量。
(1)位置参数:以逗号隔开各个变量
(2)默认值参数:在函数声明的时候,给出一个默认值,该值如果在调用时没有给内容,默认值生效;默认值参数必须跟在位置参数后面。
(3)动态传参:在形参上,可以使用*来动态接收所有的位置参数,接收到的内容自动组织成元组;可以使用**来动态接收所有的关键字参数,接收到的内容自动组织成字典。混搭的顺序为:位置参数 > *args > 默认值参数 > **kwargs
(4)def func(*args, **kwargs): # 无敌传参
def eat(*food): # *表示动态接收位置参数,参数名是food,接收到的参数是元组
print(food)
eat('螺蛳粉') # ('螺蛳粉',)
lst = ['螺蛳粉, 手抓饼']
eat(*lst) # 把列表打散成位置参数传递,结果为:('螺蛳粉, 手抓饼',)
# 以下函数的输出结果为:
def func(a, b, c, *args, d=5, e=6, **kwargs):
print('a:', a)
print('b:', b)
print('c:', c)
print('*args:', args)
print('d:', d)
print('e:', e)
print('**kwargs:', kwargs)
func(1, 2, 3, 4, 5, 6, 7, 8) # a: 1;b: 2;c: 3;*args: (4, 5, 6, 7, 8);d: 5;e: 6;**kwargs: {}
func(1, 2, 3, d=4, e=5, m=6, p=7, q=8) # a:1, b:2, c:3, *args:(), d:4, e:5, **kwargs:{'m':6, 'p':7, 'q':8}
func(b=1, c=2, a=3, d=4, e=5, m=6, p=7, q=8) # a:3, b:1, c:2, *args:(), d:4, e:5, **kwargs:{'m':6, 'p':7, 'q':8}
实参:在函数执行的时候,给函数传递的信息。
(1)位置参数:在执行时,按照参数的排列位置,给形参传递数据。
(2)关键字参数:按照形参的名字给形参传递数据。
(3)可以混搭:位置参数必须写在关键字参数前面。在实参上,可以使用*打散一个列表(元组,集合,字符串)成位置参数进行传递;可以使用**打散一个字典成关键字参数进行传递。
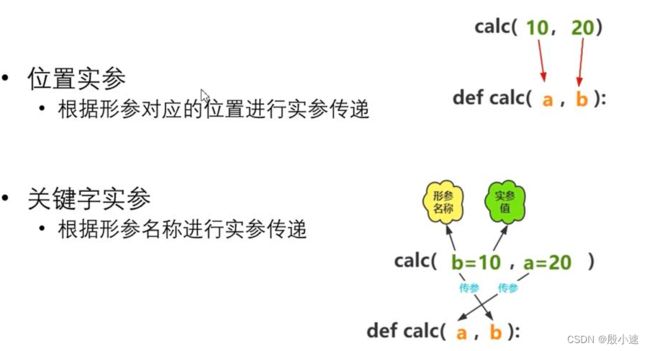
注意:在函数调用过程中,进行参数的传递。如果参数是不可变对象(字符串,元组),在函数体的修改不会影响实参的值!如果是可变对象,在函数体的修改会影响实参的值!
def func(arg1, arg2):
print('arg1 =', arg1)
print('arg2 =', arg2)
arg1 = 100
arg2.append(10)
print('arg1 =', arg1)
print('arg2 =', arg2)
n1 = 11
n2 = [22, 33, 44]
print('n1 =', n1) # n1 = 11
print('n2 =', n2) # n2 = [22, 33, 44]
func(n1, n2) # 位置传参:n1是不可变对象,函数体中arg1的修改不会影响n1的值;n2是可变对象,函数体重arg2的修改会影响n2的值
print('n1 =', n1) # n1 = 11
print('n2 =', n2) # n2 = [22, 33, 44, 10]
10.3 函数的返回值
- 如果函数没有返回值(函数执行完毕后不需要给调用处提供数据),return可以省略不写;
- 函数的返回值如果只有1个,直接返回类型;如果是多个值,返回元组类型,配合python的解构,可以直接得到多个变量。
def func(num): odd = [] # 存奇数 even = [] # 存偶数 for i in num: if i%2: odd.append(i) else: even.append(i) return odd, even lst = [10, 29, 34, 23, 44, 53, 55] print(func(lst)) # ([29, 23, 53, 55], [10, 34, 44]) - 函数执行过程中,如果执行到了return,函数就回停止。
10.4 函数的参数定义
- 默认值参数
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参。def func(a, b=10): print(a, b) func(100) # 100 10 func(10, 20) # 10 20 - 个数可变的位置参数
在定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数。
使用*定义个数可变的位置参数。
结果为一个元组。def func(*args): print(args) func(1) # (1,) func(1, 2) # (1, 2) - 个变可变的关键字形参
在定义函数时,可能无法事先确定传递的关键字实参的个数时,使用可变的关键字形参。
使用**定义个数可变的关键字形参。
结果为一个字典。def func(**kwargs): print(kwargs) func(a=10) # {'a': 10} func(a=20, b=30, c=40) # {'a': 20, 'b': 30, 'c': 40} - 函数的参数总结
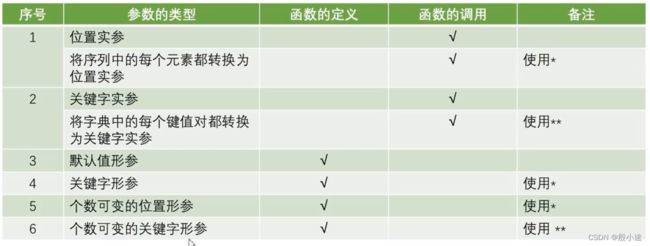
def func(a, b, c): # a,b,c在函数的定义处,所以是形参 print('a = ', a) print('b = ', b) print('c = ', c) func(1, 2, 3) # 位置实参传递 lst = [10, 20, 30] func(*lst) # 在函数调用时,将列表中的每个元素都转换为位置实参传入 func(a=100, c=300, b=200) # 关键字实参传递 dic = {'a':1000, 'b':2000, 'c':3000} func(**dic) # 在函数调用时,将字典中的键值对都转换为关键字实参传入 - 函数定义时的形参的顺序问题
def func(a, b, *, c, d, **kwargs) # c d 只能采用关键字实参传递 pass def func1(*args, **kwargs): pass def func2(a, b=10, *args, **kwargs): pass
10.5 变量的作用域
局部变量:在函数内定义并使用的变量,只在函数内部有效,局部变量使用global声明,这个变量就会成全局变量。
全局变量:函数体外定义的变量,可用作于函数内外。
def func(a, b):
global c # 局部变量使用global声明,就变成全局变量
c = a + b
print(c)
func(1, 2) # 3
name = '张三' # name的作用域为函数内部和外部都可以使用,全局变量
print(name) # 张三
def func2():
print(name)
func2() # 张三
注意:
-
如果想在局部修改全局变量的值,在局部使用global可以引入全局变量;如果不修改全局变量,就不需要加global。
a = 10 b = 100 def func(): # 需求:必须要改变外面的变量值,需要使用global关键字来引入全局变量 global a a += 10 # b += 10 # 报错 b = 200 print('函数内部a:', a) print('函数内部b:', b) func() print('函数外部a:', a) print('函数外部b:', b)结果如下:

-
如果想在局部找外层局部的变量,需要用nonlocal进行引入;如果不修改,就不需要加nonlocal。
c = 1000 def func(): a = 10 # 局部变量 b = 100 def inner(): nonlocal a # 引入当前函数外层的局部变量 a += 10 # 修改局部变量 b = 200 def triple(): nonlocal a nonlocal b # 取外层(inner)的b,外层没有b再往外(func)继续找b # nonlocal c # 报错:只能在局部找b,无法取全局变量
10.6 函数的注释
def calculate(a, b):
"""
计算器,帮你计算a+b的结果
:param a: 第一个数的值
:param b: 第二个数的值
:return: 返回a+b的结果
"""
return a + b
10.7 函数的返回值类型
a :int 描述a的类型是int
-> int 描述函数的返回值类型是int
在写代码的时候,可以让编辑器有类型的提示。a.弹窗显示int函数
def calculate(a: int, b: int) -> int:
"""
计算器,帮你计算a+b的结果
:param a: 第一个数的值
:param b: 第二个数的值
:return: 返回a+b的结果
"""
return a + b
print(calculate(1, 1))
10.8 装饰器
在不改变原有函数的基础上给函数增加新的功能。
通用装饰器的写法:
def wrapper(fn): # wrapper:装饰器的名字;fn:被装饰的函数
# inner:被返回的函数,用来替代原函数
def inner(*args, **kwargs): # *args, **kwargs给原函数同样的参数配置
r = fn(*args, **kwargs) # fn()运行原函数,r是原函数的返回值
return r # 把原函数运行的结果反馈给调用方,在调用方看来,得到的结果依然是原函数的结果
return inner # 用来替代原函数
def func():
pass
func = wrapper(func) # 可以用python的语法糖替代
func()
@wrapper
def gn():
pass
gn()
例子:
def wrapper(fn): # fn是你要装饰的函数(你要给谁增加新功能)
def inner(*args, **kwargs): # inner可以接受所有的参数
print("开挂")
r = fn(*args, **kwargs)
print("关挂")
return r # 返回结果
return inner # 最关键的一句话
def computer_game(gameName):
print(f"端游:{gameName}游戏中...")
computer_game = wrapper(computer_game) # computer_game变成wrapper里的inner
computer_game('LOL') # inner()
@wrapper
def mobile_game(gameName):
print(f"手游:{gameName}游戏中...")
mobile_game('王者荣耀')
结果如下:

-
同一个函数被多个装饰器装饰——按照就近原则去解读
def wrapper1(fn): def inner(*args, **kwargs): print("wrapper1-before") r = fn(*args, **kwargs) print("wrapper1-after") return r return inner def wrapper2(fn): def inner(*args, **kwargs): print("wrapper2-before") r = fn(*args, **kwargs) print("wrapper2-after") return r return inner @wrapper2 @wrapper1 def target(): print("目标函数") target()结果如下:

-
带参数的装饰器
# 解决玩不同游戏开不同的外挂 def gua_outer(name): def gua(fn): def inner(*args, **kwargs): print(f"开启{name}外挂") r = fn(*args, **kwargs) print("关闭外挂") return r return inner return gua @gua_outer('饕餮') def dnf(): print("玩DNF") @gua_outer('耄耋') def lol(): print("玩lol") dnf() lol()结果如下:

10.9 迭代器
统一了一些数据类型的循环方式:list, dict, set, tuple, str
获取迭代器:__iter__
lst = [1, 2, 3]
print(lst.__iter__()) # list_iterator
dict = {'a':1, 'b':2, 'c':3}
print(dict.__iter__()) # dict_keyiterator
s = {1, 2, 3}
print(s.__iter__()) # set_iterator
t = (1, 2, 3)
print(t.__iter__()) # tuple_iterator
str = '123'
print(str.__iter__()) # str_ascii_iterator
迭代器功能
所有的迭代器都可以执行一个__next__的功能,意思是从迭代器中获取到下一个数据。想象成手枪,每次扣动扳机,相当于一次__next__()
- 区分可迭代对象 & 迭代器:
如果一个数据有__iter__ ,我们称之为可迭代对象(list, dict, set, tuple, str)
如果一个数据有__next__,我们称之为迭代器(list_iterator, dict_keyiterator, set_iterator, tuple_iterator, str_ascii_iterator)
迭代器特点
-
只能向前,不能反复。
-
只能使用一次,一旦取完最后一个结果,继续取会报错StopIteration。
lst = [1, 2, 3] lst_iter = lst.__iter__() # 获取迭代器 print(lst_iter.__next__()) # 1 print(lst_iter.__next__()) # 2 print(lst_iter.__next__()) # 3 print(lst_iter.__next__()) # 取完了再取报错:StopIteration def func(data): it = data.__iter__() while 1: try: print(it.__next__()) except StopIteration as e: # 当报错(StopIteration)之后,自动运行except中的代码 print('获取数据结束!') break func('123') # 结果如下: ''' 1 2 3 获取数据结束! ''' -
特别省内容(结合生成器来看) 。
lst = [] for item in range(999): lst.append(item) # 后续操作 for item in lst: print(item) def func(): for i in range(999): yield i gen = func() # 生成器(记录步骤和代码),本质是迭代器,可以用for循环 # 使用上是一样的,但节省了内存 for item in gen: print(item) -
惰性机制(必须调用__next__)才会获取数据。
10.10 生成器
生成器函数
函数中如果包含了yield,通过yield来返回数据的话,这个函数就是生成器函数。
def func():
yield 111
特点:函数名() 此时不是在运行函数,而是在创建生成器。
生成器的本质是一个迭代器,迭代器是可迭代的,所有生成器可以使用for循环。
# 普通函数
def gn():
print('hello')
return 123
g = gn()
print(g)
# 生成器函数
def func():
print('hello')
yield 123
print('Python')
yield 456
y = func() # 创建了一个生成器
print(y) # generator object
r1 = y.__next__() # 才会让生成器开始干活,执行到下一个yield为止,生成器的本质是迭代器
print('r1:', r1)
r2 = y.__next__()
print('r2:', r2)
结果如下:

生成器表达式
- 推导式:(注意:没有元组推导式,因为元组不能增删改!)
列表推导式:[结果 for循环 if条件]
字典推导式:{key:value for循环 if条件]
集合推导式:{key for循环 if条件} - 生成器表达式:
(结果 for循环 if条件)
# 从1-100之间筛选出能被13整除的数
lst = [i for i in range(1, 101) if i % 13 == 0] # 浪费内存
print(lst) # [13, 26, 39, 52, 65, 78, 91]
genexpr = (i for i in range(1, 101) if i % 13 == 0) # generator 节省内存
print(genexpr) # at 0x00000244BF27C040>
for item in genexpr:
print(item) # 依次换行输出:13, 26, 39, 52, 65, 78, 91
print(list(genexpr)) # [] 因为genexpr生成器本质是迭代器,其特点是一次性的,取完了就没了!!
def func():
print(111)
yield 222
g = func() # g 是一个生成器
g1 = (i for i in g) # g1也是一个生成器
g2 = (i for i in g1) # g2也是一个生成器
# 以下输出结果分别是??
print(list(g2)) # 111 [222]
print(list(g1)) # []
print(list(g)) # []
lambda表达式
用一句话表示一个简单的函数:lambda 参数1, 参数2: 返回值
func = lambda a, b: a + b
r = func(1, 2)
print(r) # 3
结合内置函数一起使用:
-
filter(函数, 可迭代对象):筛选函数。内部会把可迭代对象的每一个元素进行迭代,分别执行函数,把元素传递给函数做参数,根据函数的返回值决定最终的结果是保留还是剔除。
# 筛选出2个字的球类运动 lst = ['足球', '篮球', '乒乓球', '高尔夫球'] # 原始方法: def func(item): return len(item) == 2 f = filter(func, lst) print(list(f)) # ['足球', '篮球'] # lambda: f = filter(lambda x: len(x) == 2, lst) print(list(f)) # ['足球', '篮球'] -
map(函数, 可迭代对象):映射函数。内部自动把可迭代对象的每一个元素传递给函数做参谋,回收函数的返回值。
# 给列表中的每个元素都加上100后输出 lst = [1, 2, 3] m = map(lambda x: x + 100, lst) print(list(m)) # [101, 102, 103] -
sorted(可迭代对象,key, reverse):排序函数。执行过程,把可迭代对象的内容传递给key做参数,根据key函数执行的结果进行排序;reverse:是否逆转。
# 根据字数倒序排列 lst = ['足球', '篮球', '乒乓球', '高尔夫球'] r = sorted(lst, key=lambda x: len(x), reverse=True) print(r) # ['高尔夫球', '乒乓球', '足球', '篮球']
10.12 递归函数
- 什么是递归函数
如果在一个函数的函数体内调用了该函数本身,这个函数就称为递归函数。 - 递归的组成部分
递归调用与递归终止条件 - 递归的调用过程
每递归调用一次函数,都会在栈内存分配一个栈帧;
每执行完一次函数,都会释放相应的空间。 - 递归的优缺点
优点:思路和代码简单
缺点:占用内存多,效率低下
# 使用递归来计算阶乘
def fac(n):
if n == 1:
return 1
else:
return n * fac(n-1)
print(fac(6)) # 720
# 斐波那契数列 1 1 2 3 5 ...
def fib(n):
if n == 1:
return 1
if n ==2:
return 1
else:
return fib(n-1) + fib(n-2)
# 斐波那契数列第6位上的数字
print(fib(6)) # 8
# 输出斐波那契数列前6位的数字
for i in range(1, 7):
print(fib(i))
11 全民来找茬
11.1 Bug的分类
- 粗心导致的语法错误 SyntaxError
自查宝典:- 漏了末尾的冒号,如if语句,循环语句,else子句等;
- 缩进错误,该缩进的没缩进,不该缩进的瞎缩进;
- 把英文符号写成中文符号,比如:引号、冒号、括号;
- 字符串拼接时,把字符串和数字拼在一起;
- 没有定义变量,比如:while循环条件的变量;
- “==”比较运算符和“=”赋值运算符的混用;
# 语法错误 age = input('请输入你的年龄:') if age >= 18: print('成年人,做事需要负法律责任了') # input返回值为str类型,str与int类型无法进行比较,解决方法法: age = input('请输入你的年龄:') if int(age) >= 18 print('成年人,做事需要负法律责任了') - 知识点不熟练导致得错误
索引越界问题IndexError
append()方法的使用掌握不熟练# 索引越界 lst = [1, 2, 3] print(lst[3]) # IndexError # 列表的索引是从0开始的,解决方法: lst = [1, 2, 3] print(lst[2]) # append使用不当 lst=[] lst = append(1, 2, 3) print(lst) # append是列表的方法,且每次只能加1个元素。解决方法: lst = [] lst.append(1) lst.append(2) lst.append(3) print(lst) - 思路不清导致得问题
解决方案:使用print()函数;使用#暂时注释部分代码 - 被动掉坑
程序逻辑没有错,只是因为用户错误操作或者一些“列外情况”而导致得程序崩溃。
解决方案:Python提供了异常处理机制,可以在异常出现时即时捕获,然后内部“消化”,让程序继续运行。
11.3 Python的异常处理机制
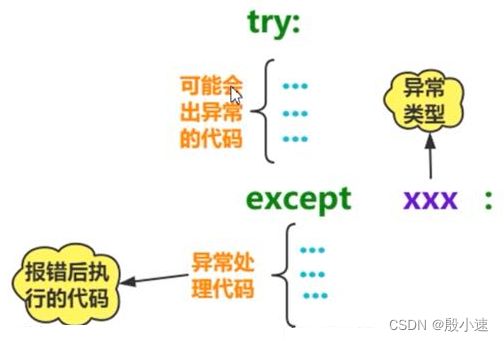
try:
a = int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
print('%d/%d =' % (a, b), result)
except ZeroDivisionError:
print('除数不能为0!')
- 多个except结构
捕获异常的顺序按照先子类后父类的顺序,为了避免遗漏可能出现的异常,可以在最后增加BaseException。try: a = int(input('请输入第一个整数:')) b = int(input('请输入第二个整数:')) result = a/b print('%d/%d =' % (a, b), result) except ZeroDivisionError: print('除数不能为0!') except ValueError: print('只能输入数字!') except BaseException as e: print(e)
12 文件操作
打开文件之后,会根据你给的mode的不同进行不同的文件操作。
语法:open(文件路径, mode=“你要干啥”, encoding="文件的编码格式")
12.1 文件路径
- 相对路径
在python中,相对路径是以当前正在运行的py文件做基准。如果在相同的文件夹内,可以直接使用 ./xx/xxx.txt;如果不在当前文件夹内,可以使用 ../ 返回上一层文件夹。 - 绝对路径
在磁盘根目录开始查找,如:C:/File/xxx.txt
12.2 mode
-
r, read
r模式下,只能读不能写。open的时候,文件必须存在,否则报错。
读取文本文件的方式:f = open ("Test_doc.txt", mode="r", encoding="utf-8") # 方法一:可以一次性读取所有内容,不推荐!内容太大等待会很久,内存会炸! content = f.read() print(content) # 方法二;逐行获取数据 for line in f: line = line.strip() #去掉空白,后续对line进行操作就没有\n干扰 print(line) -
w, write
w模式下,只能写不能读。每次open的时候都会清空文件,如果文件不存在,则会创建新文件(不包括文件夹)。f = open("Test_doc.txt", mode="w", encoding="utf-8") f.write("Hello Python!") f.write("\n") f.write("Hello Python!") f.write("\n") # f.read() #运行此行代码报错:io.UnsupportedOperation: not readable -
a, append
a模式下,追加写,不能读。在文件的末尾追加内容。f = open ("Test_doc.txt", mode="a", encoding="utf-8") f.write("Welcome to Python world!\n") -
b, bytes
b模式与r/b模式结合使用rb/wb,处理的是字节/非文本文件(如:图片、压缩包、exe、excel、mp3、mp4)。b模式下不能给encoding参数。f = open("pic.jpg", mode="rb") content = f.read() print(content)输出如下:

12.3 encoding
不论是读取还是写入文本内容,是需要编码(encode)或者解码(decode)来操作的,open函数自动帮你完成这个过程,但是需要你来指定具体的编码格式是什么。传递的参数,大概率是UTF-8或者GBK
12.4 with上下文管理
f = open()函数需要手动关闭连接,with open()函数自动帮你完成关闭的操作。
语法:with open() as f: f.xxx
12.5 文件修改
思路如下:
- 读取文件的内容(逐行读取)
- 调整要修改的内容
- 把内容写入到新文件中
- 整个过程完毕之后,硬盘上会有两个文件
- 删除原来的文件,把新文件的名字修改为原来的文件名
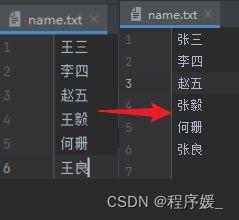
实例: 将name.txt文件下王性的名字改为张性。
import os
with open("name.txt", mode="r", encoding="utf-8") as f1, open("name_副本.txt", mode="w", encoding="utf-8") as f2:
for line in f1:
line = line.strip()
if line.startswith("王"):
line = "张" + line[1:]
f2.write(line + "\n")
# 删除文件
os.remove("name.txt")
# 重命名文件
os.rename("name_副本.txt", "name.txt")
结果如下:
12.6 删除文件
借助os模块来完成:os.remove("file_name.txt")
12.7 文件重命名
借助os模块来完成:os.rename("old_file_name.txt", "new_file_name.txt")
12.8 练习
练习题1:把pic.jpg复制到D盘根目录下。
with open("pic.jpg", mode="rb") as f1, open("D:/pic.jpg", mode="wb") as f2:
content = f1.read()
f2.write(content)
练习题2:将列表中的值逐一写入文本中。
lst = ['早上好', '下午好', '晚上好']
# 错误写法:此写法最后文件中只会有列表中的最后一个值,原因:w模式下,每执行一次open()都会清空文件再写入
for item in lst:
with open("lst.txt", mode='w', encoding="utf-8") as f:
f.write(item + "\n")
# 正确写法1:只open一次
with open("lst.txt", mode='w', encoding="utf-8") as f:
for item in lst:
f.write(item + "\n")
# 正确写法2:使用a追加写模式
for item in lst:
with open("lst.txt", mode='a', encoding="utf-8") as f:
f.write(item + "\n")