mysq开启慢查询日志,对慢查询进行优化
1.创建实验的环境
创建对应的数据库,然后写脚本向数据库中写入400万条的数据
//创建实验用的数据库
CREATE DATABASE jsschool;
//使用当前数据库
USE jsschool;
//创建学生表
CREATE TABLE student (
sno VARCHAR(20) PRIMARY KEY COMMENT '学生编号',
sname VARCHAR(20) NOT NULL COMMENT '学生姓名',
ssex VARCHAR(10) NOT NULL COMMENT '学生性别',
sbirthday DATETIME COMMENT '学生生日',
class VARCHAR(20) COMMENT '学生班级'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
//创建教师表
CREATE TABLE teacher (
tno VARCHAR(20) PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师姓名',
tsex VARCHAR(10) NOT NULL COMMENT '教师性别',
tbirthday DATETIME COMMENT '教师生日',
prof VARCHAR(20) NOT NULL COMMENT '教师职称',
depart VARCHAR(20) NOT NULL COMMENT '教师院系'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
//创建课程表
CREATE TABLE course (
cno VARCHAR(20) PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名称',
tno VARCHAR(20) NOT NULL COMMENT '外键教师编号',
FOREIGN KEY(tno) REFERENCES teacher(tno)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
//创建分数表
CREATE TABLE score (
sno VARCHAR(20) NOT NULL COMMENT '学生编号',
cno VARCHAR(20) NOT NULL COMMENT '课程编号',
degree DECIMAL COMMENT '成绩',
FOREIGN KEY(sno) REFERENCES student(sno),
FOREIGN KEY(cno) REFERENCES course(cno)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
编写脚本向数据库中写入400万条数据,大概花费一晚上左右
import pymysql
if __name__ == '__main__':
db = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='123456', db='jsschool')
cursor = db.cursor()
#sql = "SELECT * FROM `student` WHERE `class`=%s"
#values = ("51",)
sql = "INSERT INTO `student`(`sno`, `sname`, `ssex`, `sbirthday`, `class`) VALUES (%s, %s, %s,%s,%s)"
no_num = 202
class_num = 62
for i in range(4000000):
no_num += 1
no = str(no_num)
name = "李" + str(i)
class_num += 1
classvaule = str(class_num)
values = (no, name, "男", "1995-06-25", classvaule)
cursor.execute(sql, values)
db.commit()
print(i)
db.close()2.开启慢查询日志,记录执行慢的sql语句
执行语句,查询是否开启了慢查询
show variables like 'slow_query%';
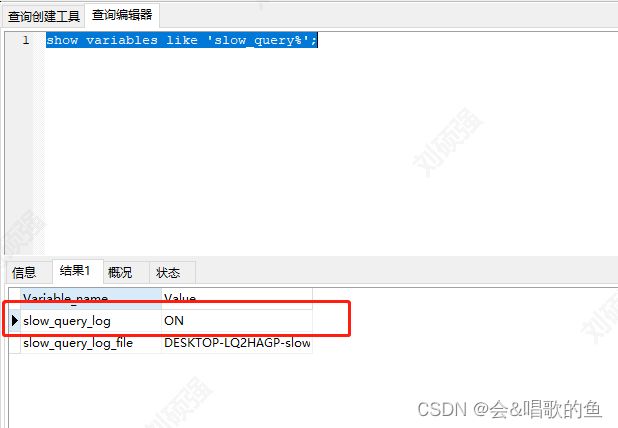
ON 则表示已经开启了
打开配置文件,在你安装的mysql目录下面 MySQL\MySQL Server 8.0
表示是否开启慢查询 1表示开启
slow-query-log=1
存放慢查询的日志的目录
slow_query_log_file="DESKTOP-LQ2HAGP-slow.log"
慢查询的阈值,超过了多少实际需要记录
long_query_time=2

重启mysql服务
使用cmd 命令
net stop mysql net start mysql
或者直接找到mysql服务,手动点击重启
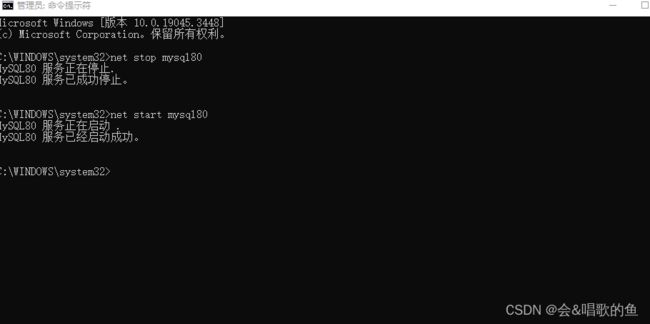
笔者电脑里服务名是mysql80
输入查询语句进行测试
这里只是为了进行相应的测试,同样的如果你的项目代码和mysql数据库进行交互的时候,存在慢查询的语句,也会被保存下来
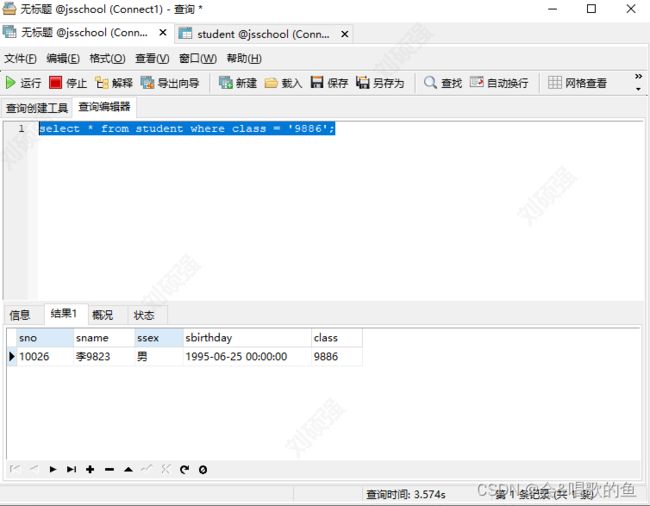
打开慢查询日志,查看是否记录
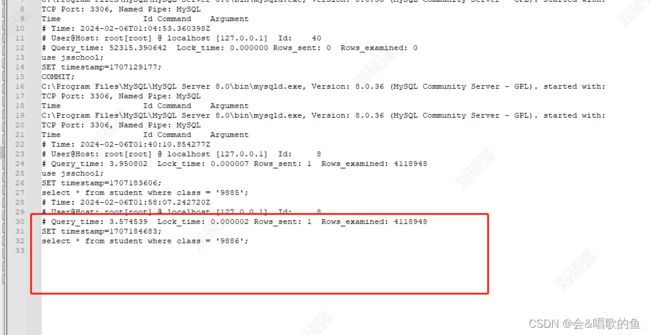
3.对慢查询语句进行优化
3.1使用索引对慢查询进行优化
给student表的class字段增加索引
alter table student add index indx_class (class);
没加索引之前,每次查询需要3s
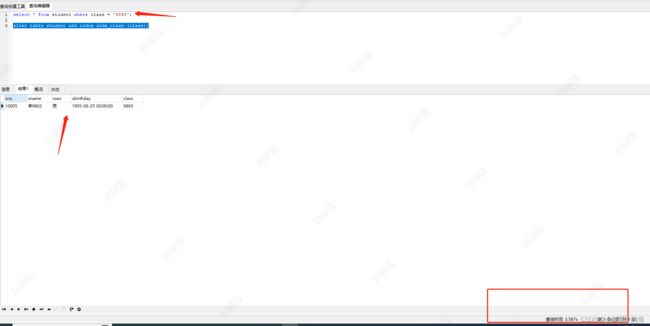
加索引后,效果明显

3.2索引失效的情况
3.2.1查询的时候使用 or 可能导致索引失效
select * from student where class = '9896' or sname = '李9836';
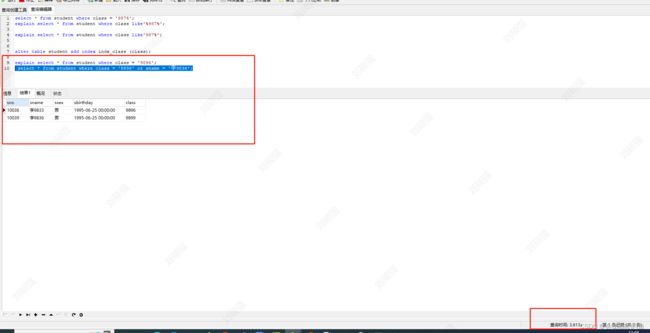
sname字段没有加索引,查询sname字段的时候还是会进行全表扫描
3.2.2使用like通配符导致的索引失效
select * from student where class like'%987';

select * from student where class like'987%';

通过对比可以发现,通配符放置到前面,会导致索引失效
3.2.3不满足索引的最左匹配原则
MySQl建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了(a)、(a,b)、(a,b,c)三个索引。
如果此时a字段上没有增加索引,则会导致索引失效
建立起class 和 sname 的联合索引
alter table student add index indx_class_name (class,sname);
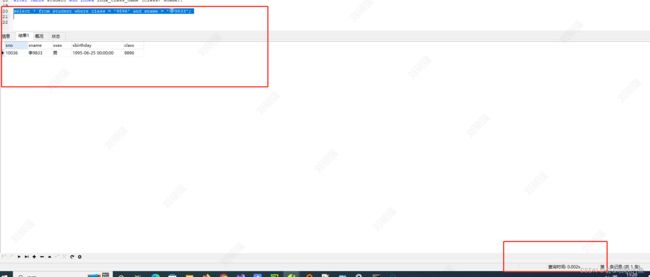
联合查询
select * from student where class = '9896' and sname = '李9833';
能看到索引是生效了
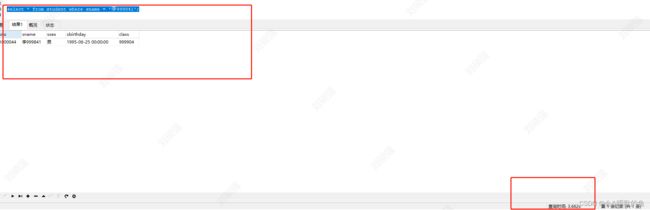
select * from student where sname = '李999841';
单独查询使用过滤条件,sname能看到索引已经失效了,
3.2.4索引字段上使用了 != 或者<> 的符号
select * from student where class != '9687'

这种情况下使用索引 和不适用索引,都是一样的慢的,索引要尽量避免使用不等于符号
4.对数据库结构进行优化,来针对慢查询
1.让表的结构尽量满足三大范式
2.如果是因为表的数据过多了可以考虑进行分库,分表