JAVA面试题分享四百六十一:Mysql中EXISTS与IN有哪些使用差异?
目录
IN与EXISTS基本概念与用法
IN子查询
EXISTS子查询
结论
验证
IN小表,EXISTS小表
IN大表,EXISTS大表
数据量以及索引对`IN`与`EXISTS性能的影响
数据量的影响
索引的影响:
在数据库查询优化中,查询效率直接关系到应用程序性能。其中,IN和EXISTS是两种常见的子查询操作符,广泛应用于SQL查询语句,但它们在执行效率上有所不同。
本文深入探讨IN和EXISTS的工作原理,以及在何种情境下选择更为合适。通过对这两种操作符的详细分析,揭示它们在实际应用中的优缺点,一起了解如何在数据库查询中灵活运用IN和EXISTS,以优化查询语句的执行。
IN与EXISTS基本概念与用法
IN子查询
在MySQL中,当使用IN子查询时,主查询(外表)中的每一行都会与子查询(内表)的结果集进行比较。先执行子查询生成一个临时表,然后主查询取出对应的字段值,系统会遍历子查询结果集,检查这个字段值是否存在于子查询结果集中。如果存在,则该行满足条件,会被加入到最终的查询结果中。例如:
SELECT * FROM t_order where customer_no in (SELECT customer_no FROM t_customer WHERE country = 'US');
在这个例子中,对于t_order表中的每一行,MySQL会查看t_customer表中是否存在与其customer_no相匹配的记录。如果t_customer表中有任何行的customer_no与t_order表中当前行的customer_no相同,那么这一行就会被包含在最终查询结果中。
IN子查询的效率通常在子查询结果集较小的情况下较高,因为它需要处理并可能缓存整个子查询结果。
EXISTS子查询
EXISTS子查询则是用于判断关联性,它并不关心子查询返回的具体数据值,而只关注是否存在匹配的行。对于主查询表中的每一行,执行内部的EXISTS子查询。当EXISTS子查询找到一行或多行符合WHERE条件的记录时,立即返回真(TRUE)。这个TRUE值会导致外层查询的那一行被纳入最终结果中,因为WHERE EXISTS条件为真。一旦EXISTS子查询找到匹配项,它就不需要继续查找剩余的记录了,即实现了所谓的“短路”或“早期终结”。例如:
SELECT * FROM t_order torder WHERE EXISTS(SELECT 1 FROM t_customer tcustomer WHERE tcustomer.customer_no = torder.customer_no AND tcustomer.country = 'US');
在这个例子中,只要t_customer表中存在至少一条记录,其customer_no与t_order表中的当前行customer_no相符,MySQL就认为EXISTS条件为真,并将当前的t_order表行作为结果返回。无论t_customer表有多少其他相关记录,都不再影响此条目是否被选中。EXISTS在子查询表大但只需验证是否存在对应关系时更高效,它支持“短路”机制,一旦找到匹配项就结束子查询,不必遍历完整个子查询表。
结论
MySQL中的IN语句是把外表和内表作HASH连接,而EXISTS语句是对外表作LOOP循环,每次LOOP循环再对内表进行查询,单纯的理解EXISTS比IN语句的效率要高的说法其实是不准确的,要区分情景:
-
如果查询的两不表大小相当,那么用
EXISTS和IN差别不大。 -
如果两个表中一个较小,一个是大表,则子查询表大的用
EXISTS,子查询表小的用IN。
验证
下面我们来通过实际案例去验证数据量和索引对IN与EXISTS子查询性能的影响。
我们创建两张表:
-- t_order
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order`(
id bigint UNSIGNED AUTO_INCREMENT COMMENT '自增主键'
PRIMARY KEY,
`order_no` varchar(16) NOT NULL DEFAULT '' COMMENT '订单编号',
`customer_no` varchar(16) NOT NULL DEFAULT '' COMMENT '客户编号',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='测试订单表';
-- t_customer
DROP TABLE IF EXISTS `t_customer`;
CREATE TABLE `t_customer`(
id bigint UNSIGNED AUTO_INCREMENT COMMENT '自增主键'
PRIMARY KEY,
`customer_no` varchar(16) NOT NULL DEFAULT '' COMMENT '客户编号',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
)ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='测试订单客户表';
我们通过Python脚本往t_order中插入100万条数据,t_customer中插入1万条数据。
案例sql:
SELECT * FROM t_order where customer_no in (SELECT customer_no FROM t_customer WHERE country = 'US');
SELECT * FROM t_order torder WHERE EXISTS(SELECT 1 FROM t_customer tcustomer WHERE tcustomer.customer_no = torder.customer_no AND tcustomer.country = 'US');
案例执行建立在没有加索引情况下进行。
IN小表,EXISTS小表
我们在执行上面两条sql时会发现IN查询的速度远远高于EXISTS。
SELECT * FROM t_order where customer_no in (SELECT customer_no FROM t_customer WHERE country = 'US');
SELECT * FROM t_order torder WHERE EXISTS(SELECT 1 FROM t_customer tcustomer WHERE tcustomer.customer_no = torder.customer_no AND tcustomer.country = 'US');
我们先看两个sql的执行计划:
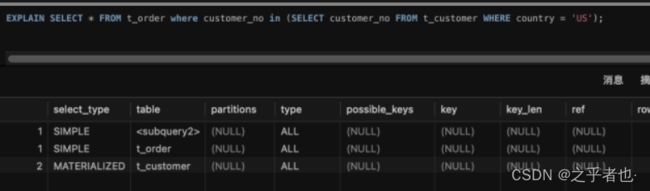
本案例中IN查询的SQL执行了近5秒。
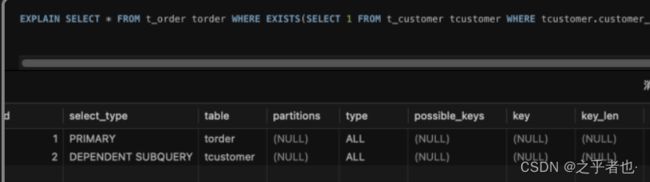
本案例中EXISTS查询的SQL执行了超过5分钟。
从上述执行计划中,我们可以看到IN查询和EXISTS查询在没有索引的情况下都进行了全表扫描:
-
IN查询:
-
主查询对
t_order表进行了全表扫描(ALL),由于没有索引,MySQL需要遍历1005915行数据。 -
子查询对
t_customer表也进行了全表扫描(MATERIALIZED),查找国家为'US'的客户编号。该表大小较小,有1000行数据。
-
-
EXISTS查询:
-
主查询同样对
t_order表进行了全表扫描(ALL),同理,无索引导致效率较低。 -
子查询对
t_customer表进行了全表扫描(DEPENDENT SUBQUERY),并且根据WHERE条件过滤出与主查询关联的数据。
-
虽然两者都未使用索引,但根据执行计划中的rows值,IN查询的子查询涉及的数据量要远小于主查询涉及的数据量。具体来说,在IN查询中,子查询只需要处理1000行数据,并将结果用于筛选主查询中的1005915行数据。而在EXISTS查询中,子查询虽然只返回1.00(几乎为1)个匹配记录,但它需要针对每一行主查询的结果进行检查,总共要处理1005915次。
因此,在这种情况下,IN查询的效率高于EXISTS查询的原因主要是子查询数据集大小的不同以及子查询对主查询的影响程度。尽管两个查询都没有利用到索引优化,但在实际执行时,IN查询所需的计算量相对较小,故其性能优于EXISTS查询。
IN大表,EXISTS大表
我们再次变更一下sql,让子查询是大表,观察一下他们的执行情况。即sql:
SELECT * FROM t_customer WHERE customer_no IN (SELECT customer_no FROM t_order);
SELECT * FROM t_customer tcustomer WHERE EXISTS(SELECT 1 FROM t_order torder WHERE tcustomer.customer_no = torder.customer_no);
我们再次查看sql的执行计划:
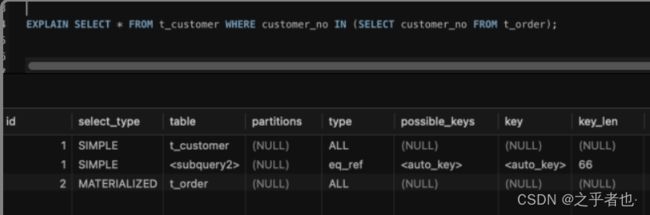
执行IN查询语句时花费2秒。
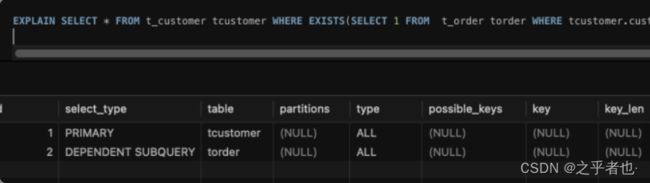
执行EXISTS查询花费0.25秒。
由此可以看出EXISTS查询的效率远高于IN查询,我们结合执行计划进行分析:
-
IN查询:
-
主查询(`t_customer`)由于没有索引,MySQL需要对整个表进行全表扫描,涉及行数为1000行。
-
子查询(`t_order`)同样进行了全表扫描,涉及行数为1005915行。虽然子查询的结果通过自动生成的临时键与主查询关联,并且对于每一个主查询中的`customer_no`,子查询都能很快找到对应的记录(rows值为1),但由于子查询的数据量巨大,所以整体查询效率不高。
-
-
EXISTS查询:
-
主查询(`t_customer`)仍然进行了全表扫描,涉及行数为1000行。
-
子查询(`t_order`)也是全表扫描,但关键在于它是“DEPENDENT SUBQUERY”,这意味着它会依赖于外部查询(即主查询)的每一行结果来决定是否执行。尽管子查询需要处理1005915行数据,但由于其是根据主查询的每一条`customer_no`逐个检查是否存在匹配项,因此当遇到第一条不满足条件的`customer_no`时,就可以立即停止对子查询中剩余行的处理。这导致了在实际执行过程中,可能只需要检查一部分`t_order`表的数据即可完成所有主查询记录的验证,从而提高了查询效率。
-
在这个案例中,因为主查询表(t_customer)较小,而子查询表(t_order)较大,EXISTS查询能够在较早阶段停止不必要的计算,使得整体查询效率优于IN查询。
数据量以及索引对`IN`与`EXISTS性能的影响
在MySQL中,IN和EXISTS子查询的性能很大程度上取决于内外表的数据量以及相关的索引设置。
数据量的影响
-
对于
IN子查询:当内表(子查询结果集)较小且数据能够被有效索引时,IN通常表现良好。如果内表很大,即使有索引,由于需要生成并存储完整的子查询结果集以供主查询进行比对,因此随着内表记录数的增长,性能会逐渐下降。 -
对于
EXISTS子查询:当外层主查询表较大,而内表虽大但匹配条件的行数较少时,EXISTS的优势更加明显。因为它仅需找到一个匹配项就可以立即结束内部循环,返回真值,无需遍历整个内表。当内表数据量巨大但能快速定位到满足条件的少数行时,EXISTS相比IN更高效。
索引的影响:
-
对于
IN子查询:如果IN子查询中的字段具有有效的索引,可以减少内表的全表扫描,转而通过索引查找,显著提高查询效率。尤其是覆盖索引(索引包含了查询所需的所有列),可以直接从索引中获取信息,避免回表操作。 -
对于
EXISTS子查询:对于EXISTS子查询,同样要求相关联的字段上有合适的索引。例如,在上面的例子中,若t_customer的customer_no字段有索引,那么在执行WHERE tcustomer.customer_no = torder.customer_no时,可以通过索引快速定位匹配记录,从而加速子查询的执行过程。
在决定使用IN还是EXISTS时,首先应考虑的是内外表的数据规模以及关联字段上的索引情况。若内表较小或子查询结果集易于通过索引优化,IN可能是更好的选择。若关注是否存在关联关系且内表虽大但能满足条件的行数有限,同时外层主查询表可能更大,则EXISTS可能提供更高的查询性能。
当然最佳实践是结合实际业务需求、数据分布特点以及数据库统计信息,通过分析SQL执行计划来确定最合适的查询策略,并根据实际情况调整表结构和索引设计。