科研论文的数据格式
正确的数据格式是进行数据分析的基础,最近SPSSAU后台收到了很多小伙伴的提问——什么样的数据格式才能进行分析?某某方法的数据格式应该是怎样的?为什么我上传数据后没有显示?针对小伙伴们有关数据格式的提问,今天将论文写作各个模块中,具有代表性的分析方法的数据格式进行一个汇总说明,帮助大家更好的完成数据整理和分析工作。
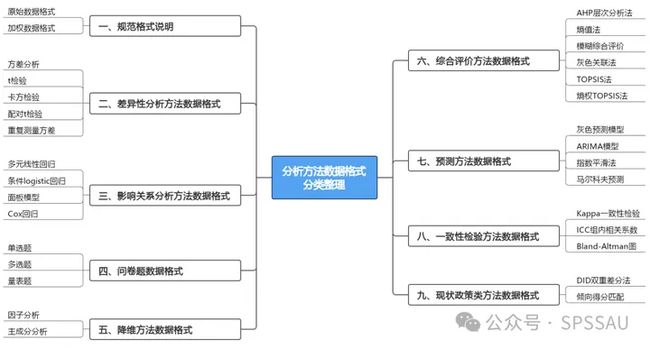
接下来从以上提到的九个方面进行介绍。
一、规范格式说明
1、原始数据格式
我们在进行数据分析时,最常见的数据格式是原始数据格式。
下图是一份常见的原始数据,它的特点是:一行代表一个样本,一列代表一个属性(变量)。
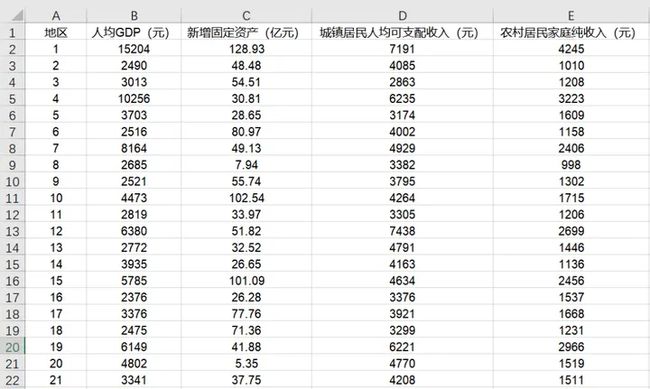
原始数据格式的特点:调查有多少样本,就需要录入多少行数据;如果调查了500个样本,那么就需要录入500行数据。每一行代表每个样本收集的所有数据,每一列代表每个属性(变量)的所有数据。
绝大多数分析方法都是使用原始数据格式上传分析的,例如30多种回归模型、主成分分析、因子分析、聚类分析等。
2、加权数据格式
除原始数据格式外,还有一些分析方法还会使用到加权数据格式,在医学/实验研究中,很多时候只有汇总数据,即带加权项的数据,如卡方检验等。下图为卡方检验的加权数据,加权数据格式的特点是:基本只针对全部为定类数据的研究时使用,且只提供汇总数据,不提供原始数据。

在进行数据分析时,单单掌握原始数据格式和加权数据格式还是不够的,因为每一种分析方法对应的数据类型与数据格式都不尽相同,只有将数据整理成分析方法要求的格式才能正常使用软件进行对应的分析,从而得到正确的分析结果。
接下来从几个方面介绍一些典型的分析方法的数据格式。
二、差异性分析方法数据格式
毕业论文常用的差异性分析方法有方差分析、t检验、卡方检验,一些代表性分析方法数据格式如下说明。
1、方差分析、t检验
方差分析和t检验都是常见研究不同组别之间差异性的方法,比如不同学历时收入的差异。那么数据中就一定要包括不同组别X(如学历)和分析项Y(如收入)。
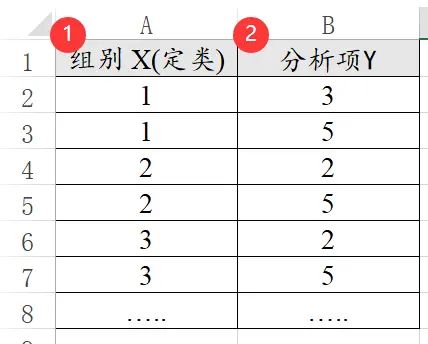
有时候只有分析项(比如3个分析项),但是现在希望对比这3个分析项的差异,那么就需要对数据进行改造,自己加入一列‘组别’,然后把数据重叠起来得到分析项Y,类似如下图:

提示:方差分析(单因素方差)与t检验的区别在于t检验只能对比两类数据之间的差异,而方差分析可对比多组数据之间的差异,但二者数据格式类似。
2、卡方检验
卡方检验用于研究X与Y之间的差异性,并且X与Y均为定类数据。使用SPSSAU中的卡方检验进行研究时,支持常规数据格式和加权数据格式两种形式。常规数据格式适用于原始数据,加权数据格式适用于只有汇总数据的情况。
加权数据格式说明如下:比如下图中X有2种情况,Y有3个情况,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;相当于总共有170个样本。整理为加权格式即只需要录入6行即可。

除了卡方检验外,还有一些方法支持加权数据格式,如下:
- 【可视化】词云
- 【问卷研究】对应分析
- 【实验/医学研究】卡方检验
- 【实验/医学研究】Kappa
- 【实验/医学研究】配对卡方
- 【实验/医学研究】Poisson回归
- 【实验/医学研究】Ridit分析
- 【实验/医学研究】卡方拟合优度
- 【实验/医学研究】Poisson检验
3、配对t检验
配对数据的格式比较特殊,例如研究实验组与对照组之间的差异,常见的配对数据研究方法比如配对样本t检验、配对卡方、配对样本Wilcoxon检验等。数据格式如下图:

配对数据一般是在实验时使用,而且配对数据的特点为:行数一定完全相等并且只有两列。
如果研究数据的行数不相等,那可能不是配对数据,如果还想对比差异,可能需要使用独立t 检验。
4、重复测量方差
重复测量数据是指同一批样本(病例)在不同的时间点测量了多次数据,因此重复测量数据的特殊之处在于一定会有ID号(即样本或者病例号),以及时间点数据。
如下图:同一个ID会有多个时间点的数据,比如下面有12个样本(12个ID号),并且测量5个时间点。那么就一定会有12*5=60行数据。同一个ID号会重复5次,同一个时间点会重复12次。

三、影响关系分析方法数据格式
影响关系研究时,最常用的方法就是各类回归分析。绝大多数回归分析的数据格式都是原始数据格式(即一列代表一个指标,一行代表一个样本),但也有些比较特殊的。
1、多元线性回归
多元线性回归分析用于研究自变量X对因变量Y的影响关系情况,通常自变量个数不止一个,数据格式如下:
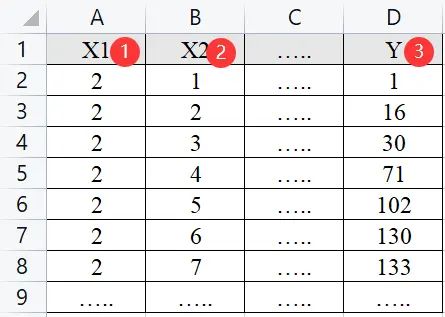
2、条件logit回归
条件logit(logistic)回归时,配对编号ID用于标识ID,而且是配对,因此一个ID会出现多次,比如1:1配对,那么1个ID就会出现2次(1:2配对时,1个ID就会出现3次);因变量Y一定只能包括数字0和1,类似数据格式如下图:

3、面板模型
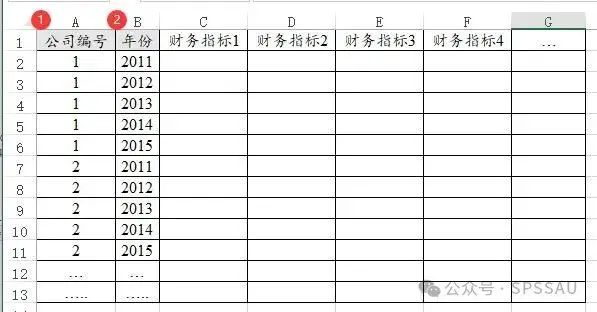
面板模型是针对面板数据进行分析,面板数据是一种特殊的数据格式。比如当前研究100家公司5年的财务数据。100家公司,每家5年,最终会有100*5=500行数据。
使用SPSSAU进行分析时,‘个体ID’就是下图中的‘公司编号’,‘时间’就是下图中的‘年份’。‘公司编号’一般是指上市公司的股票代码,也或者只是个编号均可;‘年份’一般是指年或者时间点。‘公司编号’和‘年份’两项共同用于告诉系统当前为面板数据,通常无其它意义。
4、Cox回归
Cox回归生存分析时,因变量包括两项,分别是Y1生成时间和Y2生存状态,Y2生存状态一定只能包括2个数字分别是0和1,至于X或分层项的数据特征不固定,分层项在分析时为可选,没有也没关系,类似数据格式如下图:

四、问卷题数据格式
问卷的数据格式比较特殊,如果是通过问卷星/问卷网/腾讯问卷在网上收集的问卷,可以直接下载CSV格式或者SPSS格式,下载后直接上传到SPSSAU系统进行分析。具体网上问卷下载以及上传方法可以参考帮助手册说明:SPSSAU上传数据
下面对线下收集的纸质问卷需要整理的数据格式进行说明,包括常见的单选、多选、量表题的数据格式。
1、单选题
单选题一列代表一个指标,一行代表一个样本,数字代表被选项。例如下图样本1代表性别为选项2(女士),年龄为选项4(41-50岁)。

如何上传带‘数据标签’的数据文档?如果说希望上传数据的时候直接上传数据标签,而不是通过“数据处理->数据标签”单独设置。那么可以在上传的EXCEL工作里面包括两个工作表名称,第1个是‘data’,第2个是‘tags’。‘data’里面放数据,‘tags’里面放置标签,标签的格式说明如下图示:一共包括ABC共3列,分别是‘标题’、‘数字’和‘标签’:

2、多选题
在问卷研究时会使用到多选题,多选题的数据格式比较特殊,一列代表一个多选题的选项。比如一个多选题有4个选项,那么其数据中就会有4列,分别代表4个选项。而且使用数字1表示选中,数字0表示没有选中。如下图:

3、量表题
量表题与单选题类似,如下图:

五、降维方法数据格式
常用的数据降维方法(信息浓缩)主要是因子分析和主成分分析。
因子分析&主成分分析
因子分析和主成分分析时,一列标识1个指标,一行为1个样本;如果为面板数据,比如100家公司每家公司10年,那么就会有100*10=1000个样本,可能需要单独两列分别是公司名和年份来标识面板格式而已,但因子分析与主成分分析并不区分是否面板数据,只针对指标进行分析即可,另一般分析样本量需要超出分析项(指标)的5倍,类似数据格式如下图:

如果为面板数据,比如100家公司每家公司10年,那么就会有100*10=1000个样本,可能需要单独两列分别是公司名和年份来标识面板格式而已,但因子分析和主成分分析并不区分是否面板数据,只针对指标进行分析即可。
六、综合评价方法数据格式
毕业论文写作进行综合评价时通常包括两大方面:权重计算和综合评价。权重计算最常用方法有AHP层次分析法、熵值法;综合评价常用方法有模糊综合评价、灰色关联法、TOPSIS法和熵权TOPSIS法。分别进行说明。
1、AHP层次分析法
AHP层次分析法的数据格式(即判断矩阵)最为特殊,如下图,研究人员可修改指标项名称,以及白色单元格内的数字即可。判断矩阵是 ‘ 下三角 ’ 完全对称矩阵,因此 ‘ 白色 ’ 底纹处的信息变化时, ‘ 蓝色 ’ 背景的信息会自动变化。

2、熵值法
熵值法用于指标的权重情况。1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。

如果是面板数据希望进行熵值法,其数据格式如下图所示,比如有100家公司分别5年的指标数据,那么一共就有100*5=500行数据。数据格式上需要如此,但在分析时只需要放入‘指标列’数据即可。

3、模糊综合评价
模糊综合评价是对具有多种属性的事物,综合各因素作出一个总体评价。上传的数据一般包括三个部分:指标项、指标项权重、评价项,数据格式如下图:

指标项:为参与评价的考核指标,1行放1个。
指标项权重:如果说各个指标项有着自己的权重,那么就需要单独用一列表示 ‘ 指标项权重值’ ,如果没有此数据,则默认各个指标的权重完全一致。
评价项:是指类似于{优秀,良好,一般,差} 或{非常满意,满意,一般,不满意,非常不满意}这样的评价标准,1列放1个评价项。
4、灰色关联法
灰色关联法研究数据之间的关联程度,即特征序列与母序列的关联性情况。母序列单独使用一列标识,每个特征序列都使用1列标识。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。

5、TOPSIS法&熵权TOPSIS法
TOPSIS法和熵权TOPSIS法用于研究指标与理想解的接近度情况。1个指标占用1列数据,1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。

七、预测方法数据格式
1、灰色预测模型
灰色预测GM(1,1)模型通常针对数量非常少的样本进行预测,如果数据带有时间项,其并不纳入分析项中,但自己整理数据时一般需要将数据依次按时间排序好,然后录入数据,类似数据格式如下图:

2、ARIMA模型&指数平滑法
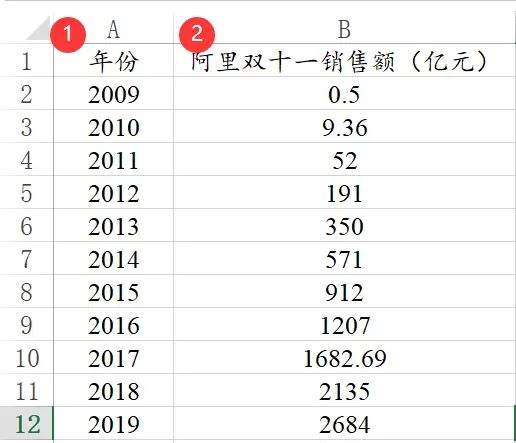
ARIMA模型和指数平滑法是针对时间序列数据进行研究,时间序列的格式包括时间和实际分析项共两列。比如下图中年份就是时间项,“阿里双十一销售额(亿元)”就是实际分析项。
3、马尔科夫预测
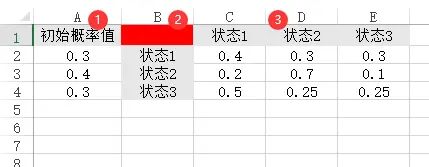
如果是马尔可夫预测,通常包括两个数据,分别是‘初始概率值’和‘状态转移矩阵’。‘初始概率值’放在A列中。‘状态转移矩阵’是n*n矩阵格式,其从B列开始放入,并且B1这个单元格一定是空着的。类似如下图所示:
八、一致性检验方法数据格式
一致性检验用于判断不同的模型或者分析方法在产出结果上是否具有一致性、模型的结果与实际结果是否具有一致性等。常用方法有Kappa一致性检验、ICC组内相关系数、Bland-Altman图等。
1、Kappa一致性检验
Kappa一致性检验数据格式上,SPSSAU支持‘加权’和‘不加权’两种格式。如果是‘加权’格式如下图:A列和B列分别代表2个措施(医生),单独用一列标识对应医生诊断的病例数量。‘加权’格式时,一定需要把权重加权项放入对应的框中才可以。如果是‘不加权’格式,那么没有权重列。只需要两列原始数据即可。

2、ICC组内相关系数
ICC组内相关系数通常可用于重测信度分析等,比如有3个医生对于5个病人的智商打分一致性。那么需要有3个医生的数据,1个医生为1列即可,其格式类似于配对数据,如下图所示:

3、Bland-Altman图
例如当前有医生使用两种方法分别做一项实验,现需要对第1种和第2种方法共两种方法的测量数据进行一致性检验;如果有分组数据,例如研究不同性别,此时只需要把性别group放入对应框中即可,数据格式如下:

九、现状政策类方法数据格式
1、DID双重差分法
如果是进行双重差分DID分析,那么Treated地区(0代表A类地区即控制组,1代表B类地区即实验组)和time政策实施前后(0代表实施前, 1代表实施后))数据只能包括数字0或者1,并且有对应的被解释变量Y,至于控制变量可有可无,由实际研究情况而定。
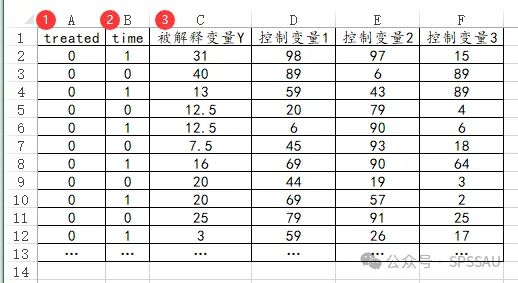
如果是多期DID数据,treated只能为数字0或1,数字0标识‘控制组’,数字1标识‘实验组’;time只能为数字0或1,数字0标识‘before’(实验前),数字1标识‘after(实验后)。Treate*time即为交互项,可使用SPSSAU数据处理->生成变量->乘积得到,格式类似如下图:

2、倾向得分匹配
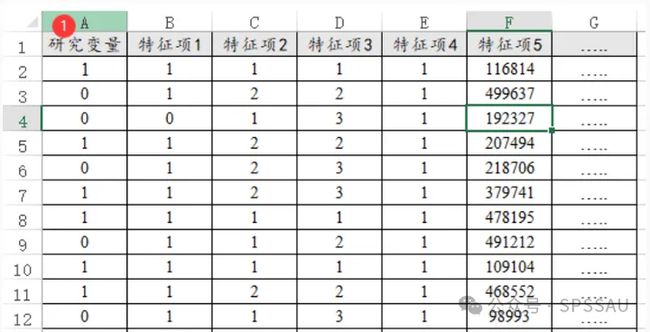
倾向得分匹配时,研究变量一定只能包括数字0和1,特征项的数据特征并无特别要求,类似数据格式如下图:
除以上分析方法外,还有下面这些分析方法的数据格式也需要注意:

以上分析方法可以在SPSSAU常见研究方法数据格式说明的帮助手册进行查询:https://spssau.com/helps/otherd