HDFS入门基础
HDFS总结
在现代的企业环境中,海量数据超过单台物理计算机的存储能力,分布式文件系统应运而生,对数据分区存储于若干物理主机,管理网络中跨多台计算机存储的文件系统。
HDFS只是分布式文件管理系统中的一种。
HDFS命令
基础语法:【hadoop fs 具体命令 、hdfs dfs 具体命令】
两个是完全相同的。
显示文件列表
# hdfs dfs -ls URL
创建目录
# hdfs dfs -mkdir [-p] URL
使用-p参数可以递归创建目录
上传文件(到文件系统)
# hdfs dfs -put <本地路径> <服务器路径>
案例:put将当前/etc/passwd文件上传到文件系统中/usr/hdfs中
# hdfs dfs -put /etc/passwd /usr/hdfs
# hdfs dfs -moveFromLocal <本地路径> <服务器路径>
案例:将当前a.txt文件上传到文件系统中/user/hdfs中
# hdfs dfs -moveFromLocal a.txt /user/hdfs
区别:moveFromLocal和put命令类似,但是源文件【本地文件】拷贝之后自身被删除。
下载文件(从文件系统)
# hdfs dfs -get <文件系统中指定文件> <本地路径>
案例:将/user/hdfs/a.txt文件拷贝到本地
# hdfs dfs -get /user/hdfs/a.txt .
移动文件(该命令不能跨文件系统)
# hdfs dfs -mv <文件系统中源路径> <文件系统中目的路径>
案例:将/user/hdfs/a.txt文件移动到/input目录中
# hdfs dfs -mv /user/hdfs/a.txt /input
删除文件/非空目录
# hdfs dfs -rm [-r] p [目标路径]
使用-r参数将当前目录下的所有文件及目录都删除
将文件/目录拷贝到目标路径
# hdfs dfs -cp <文件路径/目录路径> <目标路径>
将文件内容输出到控制台
# hdfs dfs -cat <文件路径>
HDFS的API
获取FileSystem
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://172.16.0.4:9000");
FileSystem fs = FileSystem.get(conf);
创建目录
Path p = new Path("/user/nucty");
fs.mkdir(p);
删除目录或文件
参数解读:【参数一:要删除的路径;参数二:是否递归参数】
文件没必要递归,空目录也没必要递归,在删除非空目录时需要递归删除。
Path p = new Path("/user/nucty");
fs.delete(p, true); // 需要递归则true,反之。
文件上传
参数解读:【第一个参数:源地址;文件第二个参数:目标位置文件】
Path p = new Path("/user/nucty.txt");
fs.copyFromLocalFile(new Path("/a.txt"), p);
文件下载
参数解读:【参数一:是否在下载后删除源文件;参数二:源文件的路径(HDFS);参数三:目标地址路径(Win);参数四:否是开启本地校验true -> 不开启校验】
若开启本地校验会多出现一个 crc文件,crc循环冗余校验文件用于校验文件是否正确完整。
Path hdfsPath = new Path("/user/nucty.txt");
fs.copyToLocalFile(false, hdfsPath, new Path("d://"), true); //下载到D盘
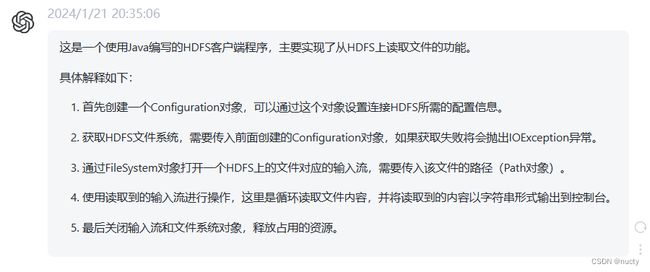
读取文件(课上代码)
package zb.hdfs.chap01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class Test1 {
public static void main(String[] args) {
// 1、获取配置信息对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.222.132:9000");
try {
// 2、获取hdfs文件系统
FileSystem fs = FileSystem.get(configuration);
// 3、使用文件系统获取hdfs上的某个文件对应的流
Path path = new Path("/data/ihad.txt");
FSDataInputStream open = fs.open(path);
// 使用流进行操作
byte[] bytes = new byte[1024];
int num = 0;
while ((num =open.read(bytes)) != -1) {
System.out.println(new String(bytes));
}
// 关闭资源
open.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package zb.hdfs.chap01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 使用hadoop的打包方式执行,给代码传参数
*/
public class Test2 extends Configured implements Tool {
public static void main(String[] args) {
try {
ToolRunner.run(new Test2(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public int run(String[] strings) throws Exception {
// 获取配置对象
Configuration conf = getConf();
// 获得文件系统
FileSystem fs = FileSystem.get(conf);
String inpath = conf.get("inpath");
// 构建path对象
Path path = new Path(inpath);
// 获取流对象
FSDataInputStream open = fs.open(path);
byte[] bytes = new byte[1024];
int num = 0;
while ((num =open.read(bytes)) != -1) {
System.out.println(new String(bytes));
}
// 关闭资源
open.close();
fs.close();
return 0;
}
}

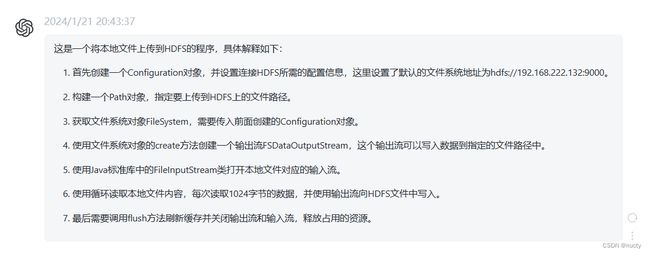
写入数据(课上代码)
package zb.hdfs.chap01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.IOException;
public class Test3 {
public static void main(String[] args) {
// 1、获取配置信息对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://192.168.222.132:9000");
Path path = new Path("/data/course.txt");
try {
FileSystem fs = FileSystem.get(configuration);
FSDataOutputStream fos = fs.create(path);
// 读取本地文件
FileInputStream fis = new FileInputStream("data/course.txt");
int count = 0;
byte[] b = new byte[1024];
while ((count = fis.read(b)) != -1) {
fos.write(b);
}
fos.flush();
fos.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
列出块信息和元数据
package zb.hdfs.chap01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hdfs.client.HdfsDataInputStream;
import org.apache.hadoop.hdfs.protocol.ExtendedBlock;
import org.apache.hadoop.hdfs.protocol.LocatedBlock;
import java.io.IOException;
import java.util.List;
public class Test4 {
public static void main(String[] args) {
// 1、获取配置信息对象
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.222.132:9000");
try {
FileSystem fs = FileSystem.get(configuration);
FileSystem fileSystem = FileSystem.newInstance(configuration);
Path path = new Path("/data/ihad.txt");
FSDataInputStream open = fs.open(path);
HdfsDataInputStream dis = (HdfsDataInputStream)open;
List<LocatedBlock> allBlocks = dis.getAllBlocks();
for (LocatedBlock b : allBlocks) {
ExtendedBlock block = b.getBlock();
System.out.println("id:" + block.getBlockId());
System.out.println("name:" + block.getBlockName());
System.out.println("num:" + block.getNumBytes());
}
// 获取文件的元信息
FileStatus[] status = fs.listStatus(path);
for (FileStatus f : status) {
System.out.println(f.isDirectory());
System.out.println(f.getPath());
System.out.println(f.getAccessTime());
System.out.println(f.getOwner());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
序列化
Hadoop使用自己的序列化格式: Writable类型。
将数据写入到文件中的程序
package zb.hdfs.chap02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SequenceTest extends Configured implements Tool {
public static void main(String[] args) {
try {
ToolRunner.run(new SequenceTest(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public int run(String[] strings) throws Exception {
Configuration conf = getConf();
// 获取输出路径
Path path = new Path(conf.get("outpath"));
SequenceFile.Writer.Option file = SequenceFile.Writer.file(path);
SequenceFile.Writer.Option key = SequenceFile.Writer.keyClass(IntWritable.class);
SequenceFile.Writer.Option value = SequenceFile.Writer.valueClass(Text.class);
// 获取序列化文件对象
SequenceFile.Writer writer = SequenceFile.createWriter(conf, file, key, value);
for (int i = 0; i <= 100; i ++ ) {
if (i % 5 == 0) writer.sync();
writer.append(new IntWritable(i), new Text("briup-" + i));
}
return 0;
}
}

读取文件
package zb.hdfs.chap02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SequenceTest2 extends Configured implements Tool {
public static void main(String[] args) {
try {
ToolRunner.run(new SequenceTest2(), args);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public int run(String[] strings) throws Exception {
Configuration conf = getConf();
// 获取输出路径
Path path = new Path(conf.get("inpath"));
SequenceFile.Reader.Option file = SequenceFile.Reader.file(path);
SequenceFile.Reader reader = new SequenceFile.Reader(conf, file);
Writable key = (Writable)reader.getKeyClass().newInstance();
Writable value = (Writable) reader.getValueClass().newInstance();
/**
* 读取下一个记录recode,把记录中的key值放到IntWritable对象中
* value值放入到Text对象中,next方法返回true表示有值,sync(字节)
* syncSeen()跳过标号字节
*/
reader.sync(700);
while (reader.next(key, value)) {
// 获取同步标记
boolean flag = reader.syncSeen();
if (flag) System.out.println("******************");
long position = reader.getPosition();
System.out.println(position+":"+key+"-"+value);
}
return 0;
}
}
